
一、Stream简介
1、什么是Stream?
Java8 中,Collection 新增了两个流方法,分别是 Stream() 和 parallelStream()
Java8 中添加了一个新的接口类 Stream,相当于高级版的 Iterator,它可以通过 Lambda 表达式对集合进行大批量数据操作,或 者各种非常便利、高效的聚合数据操作。
2、为什么要使用Stream?
在 Java8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据,又或者通过重新定义 Collections.sorts 的 Comparator 方法来实现,这两种方式对于大数据量系统来说,效率并不是很理想。Stream 的聚合操作与数据库 SQL 的聚合操作 sorted、filter、map 等类似。我们在应用层就可以高效地实现类似数据库 SQL 的 聚合操作了,而在数据操作方面,Stream 不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据 的处理效率。
二、Stream使用
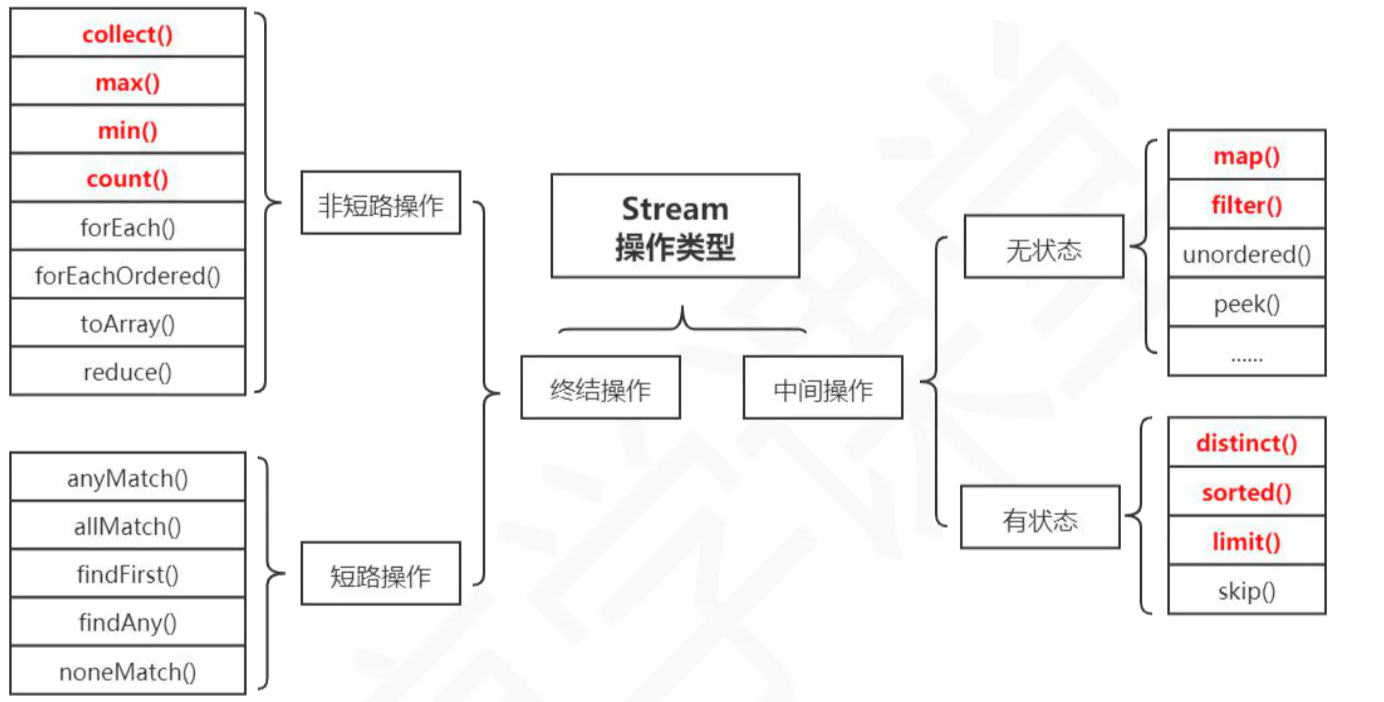
1、Stream操作分类
官方将 Stream 中的操作分为两大类:终结操作(Terminal operations)和中间操作(Intermediate operations)。
中间操作会返回一个新的流,一个流可以后面跟随零个或多个中间操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后会返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。而是在终结操作开始的时候才真正开始执行。
中间操作又可以分为无状态(Stateless)与有状态(Stateful)操作:
- 无状态是指元素的处理不受之前元素的影响;
- 有状态是指该操作只有拿到所有元素之后才能继续下去。
终结操作是指返回最终的结果。一个流只能有一个终结操作,当这个操作执行后,这个流就被使用“光”了,无法再被操作。所以这必定这个流的最后一个操作。终结操作的执行才会真正开始流的遍历,并且会生成一个结果。
终结操作又可以分为短路(Short-circuiting)与非短路(Unshort-circuiting)操作,
- 短路是指遇到某些符合条件的元素就可以得到最终结果,
- 非短路是指必须处理完所有元素才能得到最终结果。操作分类详情如下图所示:
2、Stream流的常用方法
①count方法:
long count (); 统计流中的元素,返回long类型数据
@Test
public void TestStream(){
List<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("赵六");
list.add("刘七七");
list.add("张八八");
long count = list.stream().count();
System.out.println("集合中的元素个数是:" + count);
}
- 输出结果:
集合中的元素个数是:6
②filter方法:
Stream filter(Predicate<? super ?> predicate); 过滤出满足条件的元素
参数Predicate:函数式接口,抽象方法:boolean test (T t)
Predicate接口:是一个判断接口
// 获取stream流
Stream<String> stream = Stream.of("张三","李四","王五","赵六","刘七七","张八八");
// 需求:过去出姓张的元素
stream.filter((String name)->{
return name.startsWith("张");
}).forEach((String name)->{
System.out.println("流中的元素" + name);
});
- 输出结果:
流中的元素张三
流中的元素张八八
③forEach方法:
void forEach(Consumer<? super T> action):逐一处理流中的元素
参数 Consumer<? super T> action:函数式接口,只有一个抽象方法:void accept(T t);
注意:
- 此方法并不保证元素的逐一消费动作在流中是有序进行的(元素可能丢失)
- Consumer是一个消费接口(可以获取流中的元素进行遍历操作,输出出去),可以使用Lambda表达式
List<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("赵六");
list.add("刘七七");
list.add("张八八");
list.stream().forEach((String name)->{
System.out.println(name);
});
使用Lambda表达式
list.stream().forEach(System.out::println);
- 输出结果:
张三
李四
王五
赵六
刘七七
张八八
④limit方法:
Stream limit(long maxSize); 取用前几个元素
注意:
参数是一个long 类型,如果流的长度大于参数,则进行截取;否则不进行操作
// 获取流的长度
Stream<String> stream1 = Stream.of("张三","李四","王五","赵六","刘七七","张八八");
// 需求:保留前三个元素
stream1.limit(3).forEach((String name)->{
System.out.println("流中的前三个元素是:" + name);
});
- 输出结果:
流中的前三个元素是:张三
流中的前三个元素是:李四
流中的前三个元素是:王五
⑤map方法:
Stream map(Function<? super T,? exception R> mapper;
参数Function<T,R>:函数式接口,抽象方法:R apply(T t);
Function<T,R>:其实就是一个类型转换接口(T和R的类型可以一致,也可以不一致)
// 获取Stream流
Stream<String> stream2 = Stream.of("111","222","333","444","555");
// 需求:把stream1流中的元素转换为int类型
stream2.map((String s)->{
return Integer.parseInt(s); // 将String类型的s进行转换为Integer类型的元素,并返回
}).forEach((Integer i)->{
System.out.println(i); // 将转换后的int类型的元素逐一输出
});
使用Lambda表达式
stream2.map(Integer::parseInt).forEach(System.out::println);
- 输出结果:
111
222
333
444
555
⑥skip方法:
Stream skip(long n); 跳过前几个元素
注意:
如果流的当前长度大于n,则跳过前n个,否则将会得到一个长度为0的空流
Stream<String> stream3 = Stream.of("张三","李四","王五","赵六","刘七七","张八八");
stream3.skip(3).forEach((String name)->{
System.out.println("跳过前三个,打印剩下的" + name);
});
- 输出结果:
跳过前三个,打印剩下的赵六
跳过前三个,打印剩下的刘七七
跳过前三个,打印剩下的张八八
⑦concat方法:
public static Stream concat(Stream<? extends T> a, Stream<? extends T> b)
–> 合并两个流
Stream<String> stream4 = Stream.of("111","222","333","444","555");
Stream<String> stream5 = Stream.of("张三","李四","王五","赵六","刘七七","张八八");
// 需求:合并两个流
Stream<String> stream6 = Stream.concat(stream4,stream5);
stream6.forEach((String name)->{
System.out.print(name);
});
使用Lambda表达式
stream6.forEach(System.out::print);
- 输出结果:
111222333444555张三李四王五赵六刘七七张八八
三、收集Stream流
List<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("赵六");
list.add("刘七七");
list.add("张八八");
List<String> userList = list.stream().filter((String name)->{
return name.startsWith("张");
}).filter((String name)->{
return name.length() == 3;
}).collect(Collectors.toList());
System.out.println(userList);
Set<String> userSet = list.stream().filter((String name)->{
return name.startsWith("李");
}).filter((String name)->{
return name.length() == 2;
}).collect(Collectors.toSet());
System.out.println(userSet);
- 输出结果:
[张八八]
[李四]
三、Stream性能
1、性能分析
- 在少数据量的处理场景中(size <= 1000)
stream 的处理效率是不如传统的 iterator 外部迭代器处理速度快的,但是实际上这些处理任务本身运行时间都低于毫秒,这点效率的差距对普通业务几乎没有影响,反而 stream 可以使得代码更加简洁;
- 在大量数据(size > 10000)
stream 的处理效率会高于 iterator,特别是使用了并行流,在 cpu 恰好将线程分配到多个核心的条件下(当然 parallel stream 底层使用的是 JVM 的 ForkJoinPool,这东西分配线程本身就很玄学),可以达到一个很高的运行效率,然而实际普通业务一般不会有需要迭代高于 10000 次的计算;
- Parallel Stream (并行流)
Parallel Stream 受引 CPU 环境影响很大,当没分配到多个 cpu 核心时,加上引用 forkJoinPool 的开销,运行效率可能还不如普通的 Stream;
2、使用建议
-
简单的迭代逻辑,可以直接使用 iterator,对于有多步处理的迭代逻辑,可以使用 stream,损失一点几乎没有的效率,换来代码的高可读性是值得的;
-
单核 cpu 环境,不推荐使用 parallel stream,在多核 cpu 且有大数据量的条件下,推荐使用 paralle stream;
-
stream 中含有装箱类型,在进行中间操作之前,最好转成对应的数值流,减少由于频繁的拆箱、装箱造成的性能损失。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/122959.html

