
一、集合概述
集合实际可理解成是一个容器,可以用来容纳其他类型的数据,数组其实就是一个集合。
集合做为一个载体,在实际开发中,将从数据库中查询到的多条数据封装成多个对象,并将他们通过集合传到前端,然后遍历集合,展现数据。
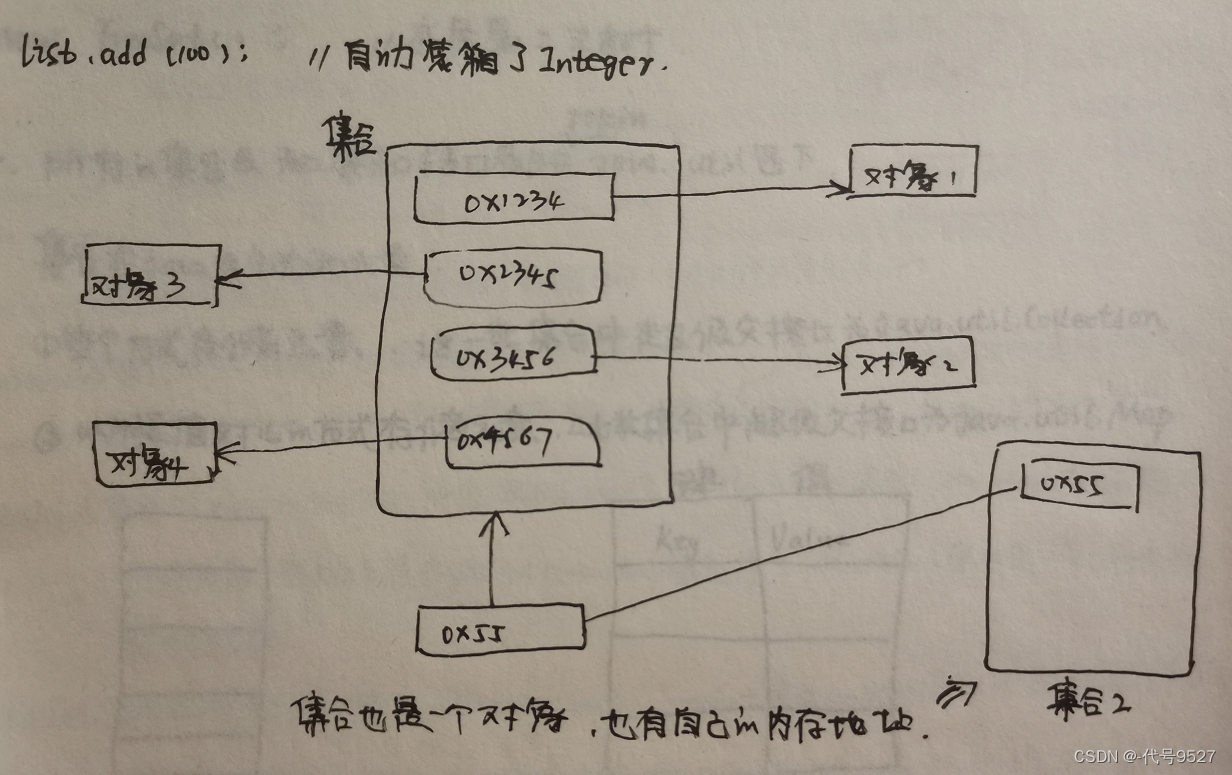
集合不能直接存储基本数据类型,也不能直接存储Java对象,集合当中存储的都是Java对象的内存地址(引用)。
1、集合与数据结构
不同的集合对应不同的数据结构,在Java中,每一个不同类型的集合,底层会对应不同的数据结构,往不同的集合中存储元素,等于将数据放到了不同的数据结构当中。
这里的数据结构,即数据存储的结构,不同的数据结构,数据存储方式不同。如:
- 数组
- 二叉树
- 链表
- 哈希表
- 图
new不同的集合对象,底层使用不同的数据结构:
//该集合底层为数组
new ArrayList();
//该集合对象底层是链表
new LinkedList();
//该集合对象底层是二叉树
new TreeSet();
2、集合的分类
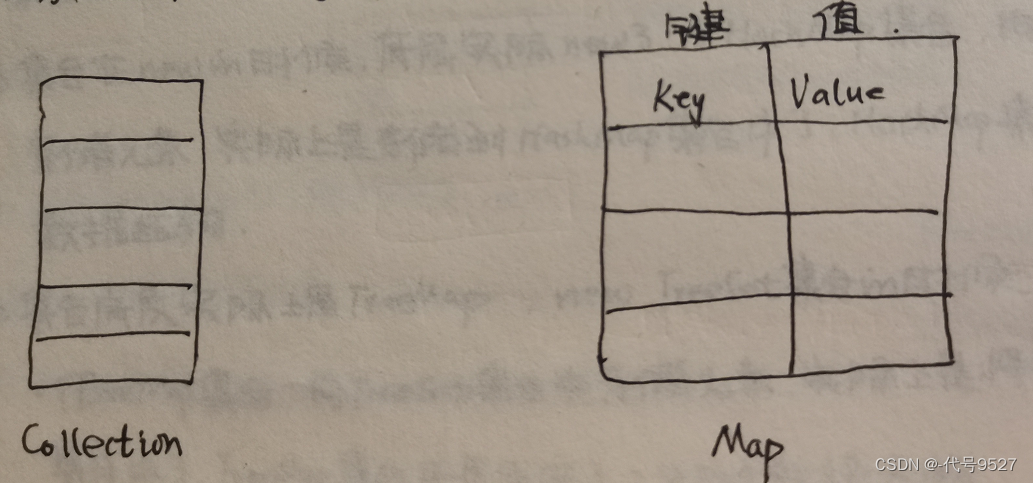
所有的集合类和集合接口都在JDK的java.util包下。集合在Java中分为两大类:
- 单方式存储元素,这一类集合中的超级父类接口为java.util.Collection
- 以键值对的方式存储元素,此类集合中超级父类接口为java.util.Map
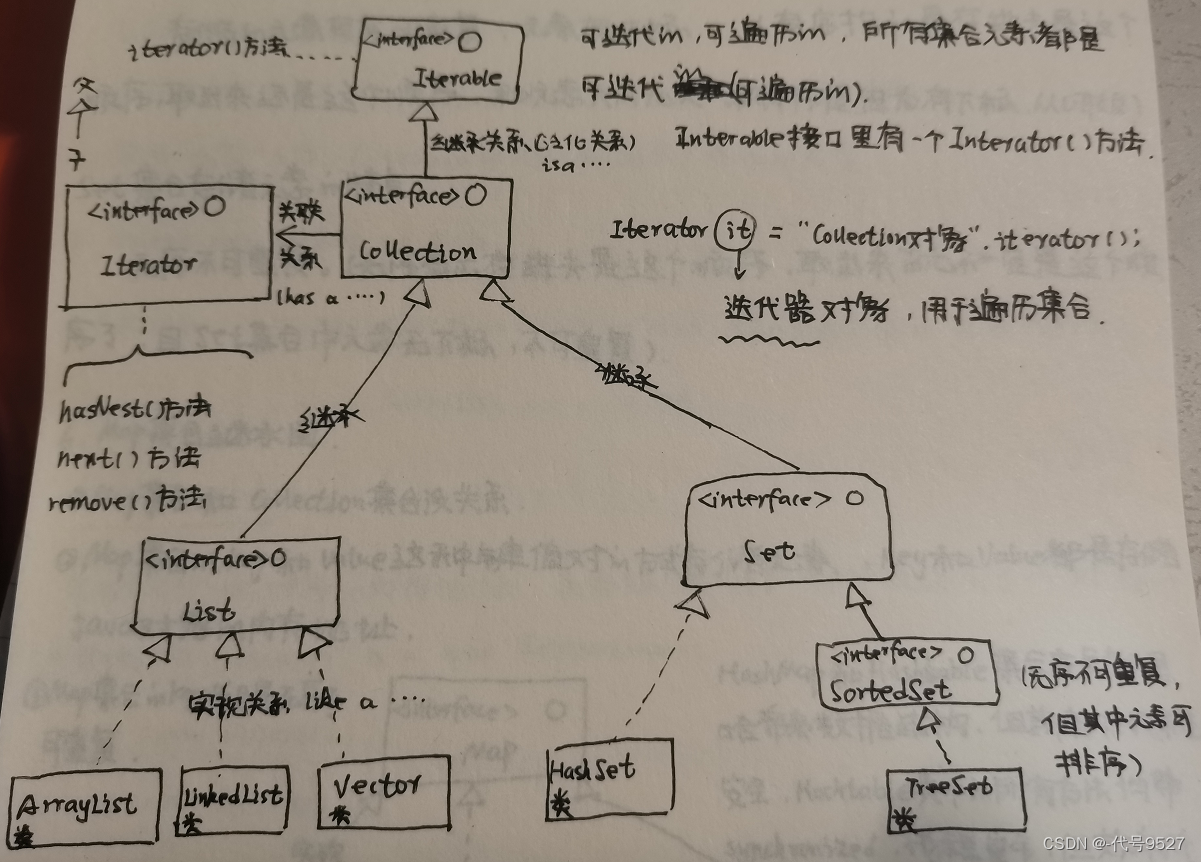
3、Collection集合继承结构图(接口)
Collection之List集合的特点:
- List集合存储的元素有序可重复,元素有下标,下标从0开始
- 有序指的是存进去是这个顺序,取出来还是这个顺序,和元素大小无关。
Collection之Set集合的特点:
- Set集合存储的元素无序不可重复,且无下标
- 无序指的是存进去是这个顺序,取出来就不一定是这个顺序了。
- ArrayList集合底层采用了数组的数据结构(非线程安全)
- LinkedList集合底层采用了双向链表的数据结构
- Vector集合采用了数组的数据结构,且有synchronized关键字修饰,是线程安全的,但Vector的效率较低
- HashSet集合在new的时候,底层实际new了一个HashMap集合,向HashSet集合中存储元素,实际是存储到了HashMap集合中了。HashMap集合是一个哈希表数据结构
- TreeSet集合底层实际是TreeMap,new TreeSet集合的时候,底层实际new了一个TreeMap集合。向TreeSet集合中存储元素,实际是将数据放到TreeMap集合中了,TreeMap集合底层采用了二叉树的数据结构。
4、Map集合继承结构图
- Map集合和Collection集合没关系
- Map集合以key和value这种键值对的方式存储元素,key和value都是存储Java对象的内存地址
- Map集合的key都是无序不可重复
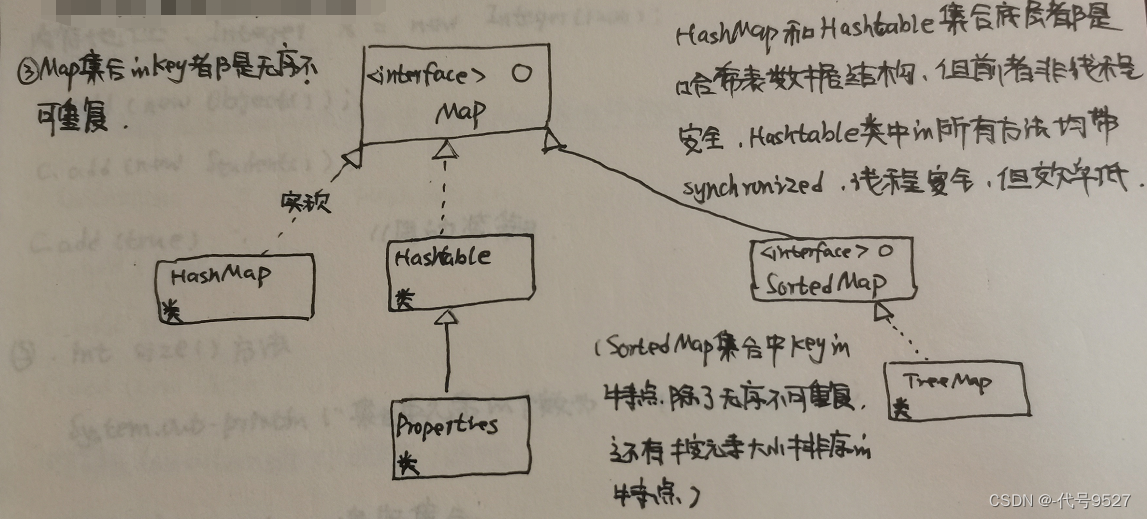
HashMap和Hashtable集合底层都是哈希表数据结构,但前者非线程安全。Hashtable类中的所有方法均带synchronized,线程安全,但效率低。
- Properties继承Hashtable,线程安全,以key-value的形式存储元素(Map集合的特点),且key和value只支持String类型。Properties被称为属性类。
- TreeMap集合底层的数据结构是二叉树
5、Collection接口中的方法
Collection中能存放什么元素?
--------
没有使用泛型之前,可存储Object的所有子类型
使用泛型之后,只能存储某个具体的类型
1)😉 boolean add (Object e)方法
//Collection是一个接口,无法实例化
Collection c = new Collection();
//多态
Collection c = new ArrayList();
//集合中只存Java对象的内存地址,此处是自动装箱后放进去了对象的内存地址。
c.add(1200);
c.add(new Object());
//自动装箱
c.add(true);
2)😉 int size()方法
System.out.println("集合中的元素个数是:"+c.size());
3)😉 void clear()方法
c.clear();
4)😉 boolean remove(Object o)方法
//删除某个元素
c.remove(true);
5)😉 boolean contains(Object o)方法
//判断当前集合中是否包含元素o
boolean query = c.contains("hello");
6)😉 boolean isEmpty()方法
//判断集合中元素个数是否为0
System.out.println( c.isEmpty() );
7)😉 Object[] toArray()方法
//集合转数组
Object[] objs = c.toArray();
6、Collection集合的迭代
注意是Collection集合的迭代,在Map集合中不能用。
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Collection1 {
public static void main(String[] args) {
Collection c = new ArrayList();
c.add(1200);
c.add(new Object());
c.add(true);
c.add("code-9527");
System.out.println("集合中的元素个数是:"+c.size());
Iterator it = c.iterator();
//当有下一个元素的时候
while(it.hasNext()){
//取出下一个元素
Object obj = it.next();
System.out.println(obj);
}
}
}
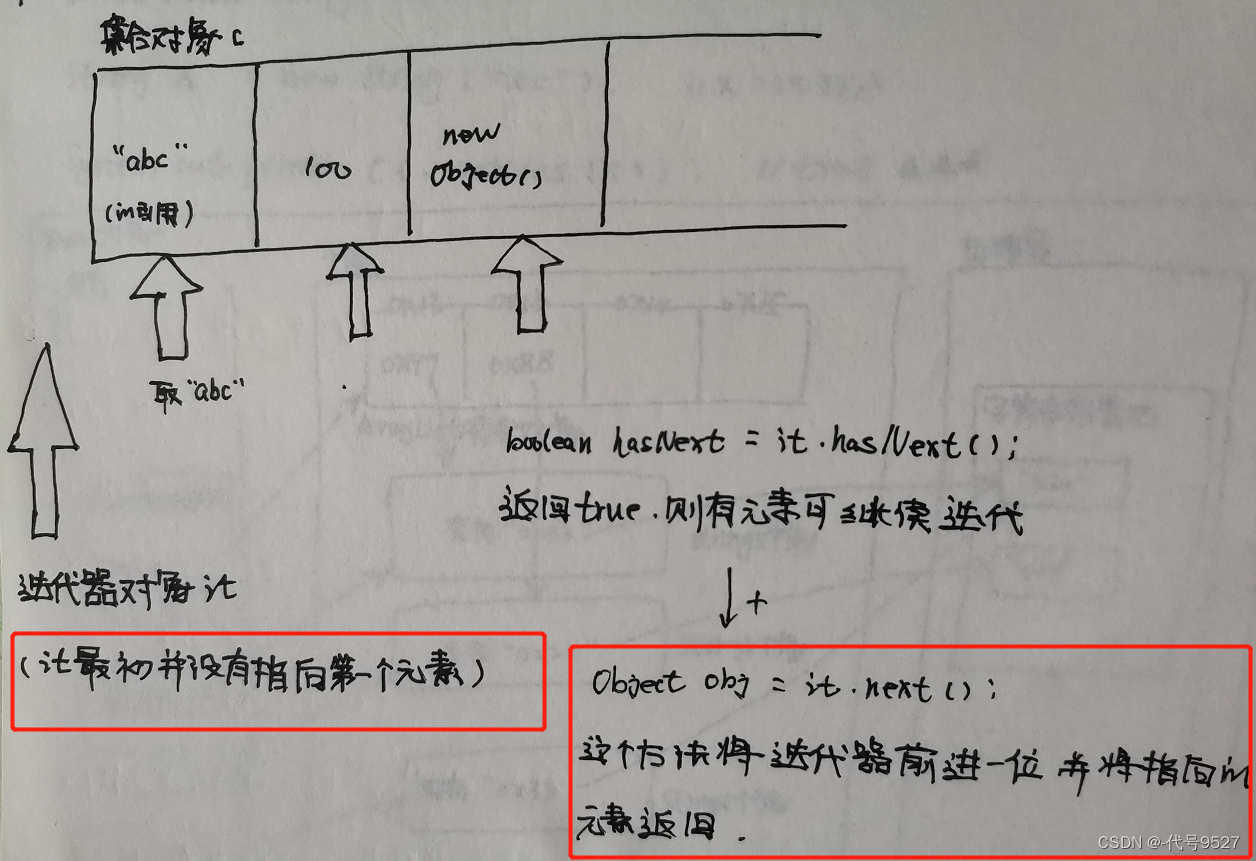
步骤:
- 获取集合对象的迭代器对象
Iterator it = c.iterator();
- 通过迭代器对象开始遍历集合
//迭代器对象可以调用两个方法:
boolean hasNext()
如果仍有元素可以迭代,则返回true
Object next()
返回迭代的下一个元素
二、Collection的工具类
1、contains方法深入
Collection c = new ArrayList();
String s1 = new String("abc");
c.add(s1);
c.add(new String("def"));
String s2 = new String("abc");
//true
System.out.println(c.contains(s2));
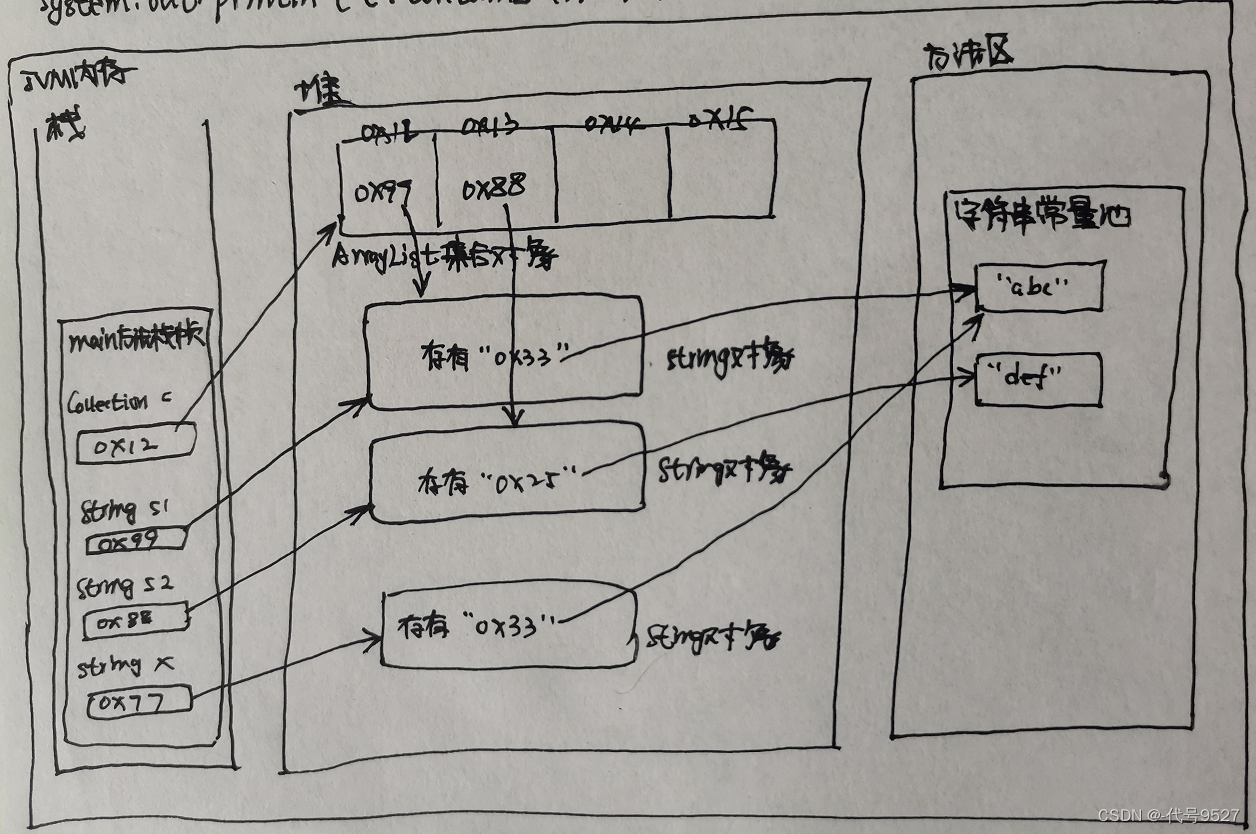
结果分析:
contains方法底层源码中调用了equals,而String类的equals是重写成了比较对象的内容。这时候的contains就像在中国找小明,不管你是住河北的小明,还是住河南的小明。即不管内存地址是啥,String对象内容相同就当是包含。
2、remove方法深入
Collection c = new ArrayList();
String s1 = new String("code-9527");
c.add(s1);
String s2 = new String("code-9527");
c.remove(s2);
//0
System.out.println(c.size());
remove方法底层也调用了equals方法,而String类的equals方法已经重写成了比较对象内容,所以传入s2可以将内容相同的s1去除。(若不是String类,是另一个没有重写equals的类,则没有这个效果)
3、集合结构只要发生改变,迭代器必须重新获取
Collection c = new ArrayList();
Iterator it = c.iterator();
//获取迭代器对象后,集合结构发生变更
c.add(1);//Integer
c.add(2);
while(it.hasNext()){
//next()方法的返回值类型必须是Object(不考虑泛型)
Object obj = it.next();
System.out.println(obj);
}
运行报错:
当集合结构发生变化,迭代器对象没有获取最新的时候,调用next()方法报错java.util.ConcurrentModificationException
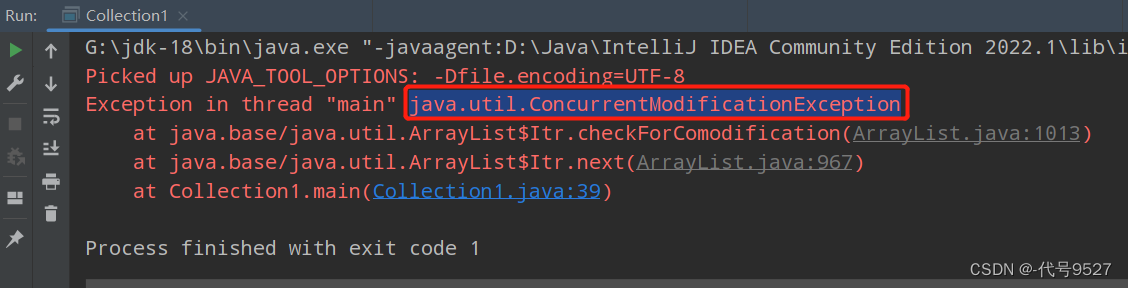
Iterator it = c.iterator();获取迭代器对象,相当于给当前集合的状态打了一个快照,当底层代码运行时,会将快照与实际的集合状态进行对比
而用迭代器.remove() 删除元素,迭代器和集合中的元素都会放生变化,二者保持一致,就不会有java.util.ConcurrentModificationException错误。用集合.remove() 只是删除了集合中的元素。
Collection c = new ArrayList();
Iterator iterator = c.iterator();
while(iterator.hasNext()){
Object o = iterator.next();
//集合.remove()
//c.remove(o);
//改为迭代器.remove
iterator.remove();
System.out.println(o);
}
三、List接口特有的方法
上面是Collection类中的一些方法,List接口除了从父接口collection中继承的方法,还有其特有的方法,和Set接口没关系。
1、List接口特有方法
List集合存储元素的特点是:
有序可重复,即List集合中的元素有下标,从0开始
- 😉 void add(int index ,Object element)方法
//new LinkedList()
//new Vector()
List myList = new ArrayList();
myList.add("a");
myList.add("b");
myList.add(1,"code-9527");
- 😉 Object get(int index)方法
除了Collection公共的迭代器遍历,List有其特有的下标遍历
//根据下标取元素
for(int i=0;i<myList.size();i++){
System.out.println(myList.get(i));
}
- 😉 int indexOf(Object o)方法
//获取指定对象第一次出现处的索引
//相对应的获取最后一次出现的索引:
//int lastIndexOf(Object o)
return myList.indexOf("aaa");
- 😉 Object remove(int index)方法
//根据下标删除元素
myList.remove(0);
- 😉 Object set (int index, Object newElement)方法
//修改指定位置的元素
myList.set(2,"new");
2、List—ArrayList集合
- ArrayList集合初始化容量是10(底层先是建立一个长为0的数组,当添加第一个元素的时候,初始化容量为10)
//默认,容量为10
List list1 = new ArrayList();
//选择ArrayList的有参构造方法
//指定初始化容量为20
List list2 = new ArrayList(20);
//注意,size方法获取的是元素个数,不是集合容量
list1.size();
- ArrayList集合底层是一个Object[] 数组,每次扩容为原来的1.5倍容量。给定一个合理的初始化大小,可以减少ArrayList集合的扩容次数
- ArrayList的特殊构造方法
Collection c = new HashSet();
c.add("9527");
//通过这个构造方法,将HashSet转成ArrayList
List list = new ArrayList(c);
总结:
ArrayList集合用的最多,虽然随机增删元素效率较低,但常在末尾,效率不受影响,且查找效率高。最后,ArrayList集合是非线程安全的。
位运算符复习:

3、List—LinkedList集合
😉 对于链表数据结构来说,基本单元是节点Node,对于单向链表来说,任何一个节点都有两个属性,一个是存储数据,一个是存储下一个节点的内存地址。
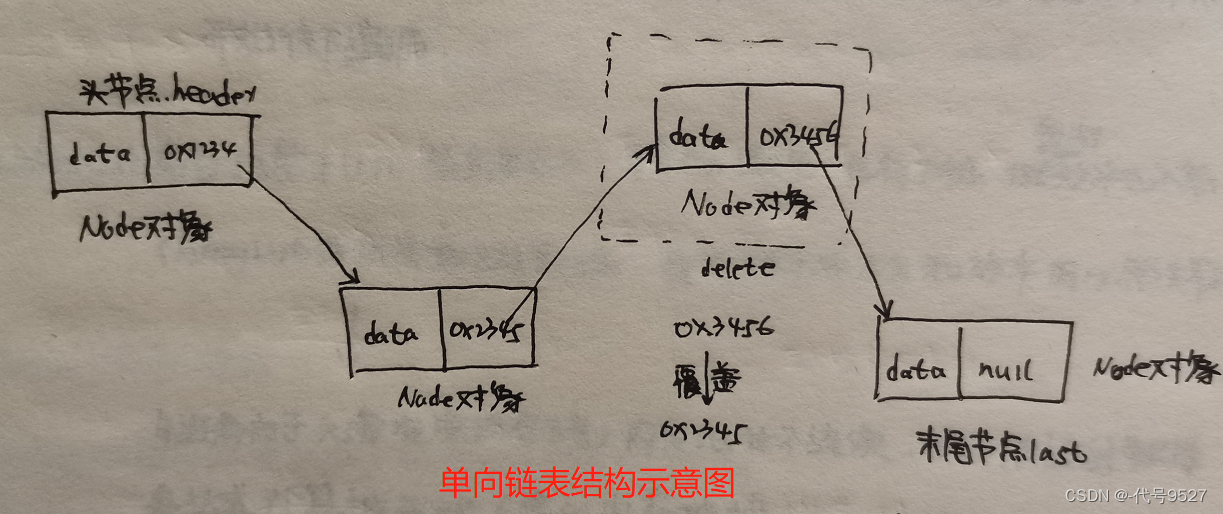
public class Node{
//存储的数据
Object data;
//下一个节点的内存地址
Node next;
public Node(){
}
...
由图,链表的优点是:随机增删元素效率较高(不涉及大量元素的位移)。缺点是:查询效率较低,每一次查找某个元素的时候都需要从头节点开始往下遍历
😉 LinkedList集合属于List集合,也是有下标的,可以下标遍历,但是查询效率不高(ArrayList是底层是个数组的原因,有无下标和查询效率没有必然的联系),这是因为链表中的元素在空间存储上内存地址不连续,不能通过简单的数学表达式就计算出被查找元素的内存地址。
ArrayList把检索发挥到了极致,LinkedList把随机增删发挥到了极致
//递归查找末尾节点
//一个几点的next为空,则为末尾节点
private Node findLast(Node node){
if(node.next == null){
return node;
}
return findLast(node.next);
😉 双向链表
双向链表的基本单元还是节点Node
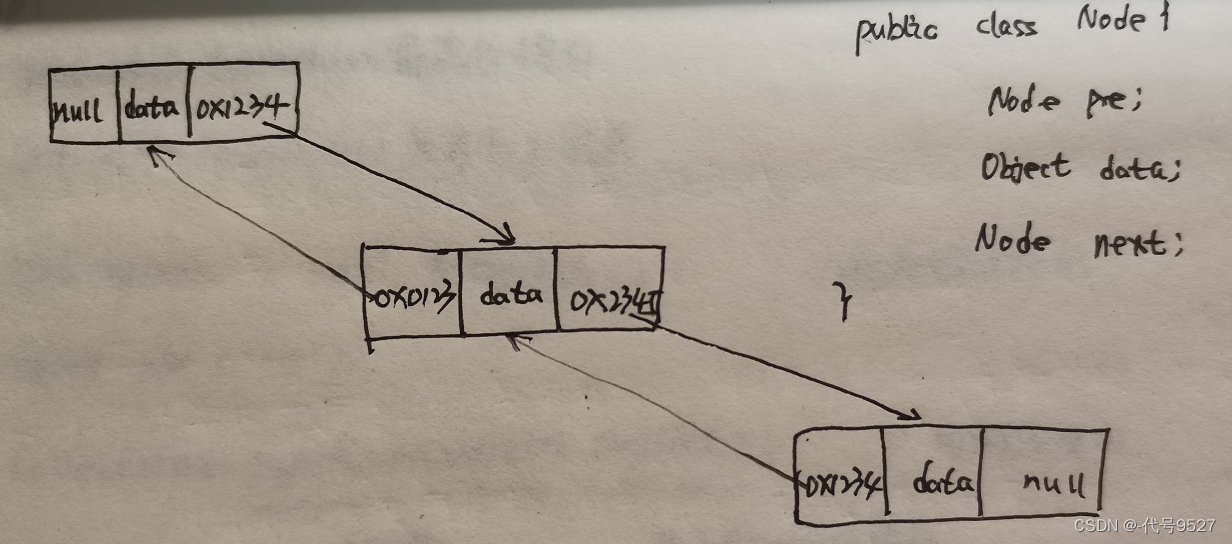
LinkedList集合总结:
- LinkedList集合底层采用了双向链表的数据结构
- LinkedList集合随机增删效率较高,检索效率较低
- LinkedList集合中的元素,在空间存储上内存地址不连续
4、List—Vector集合
Vector vector = new Vector();
List vector = new Vector();
- Vector集合底层也是一个数组,初始化容量为10
- 集合满了以后扩容,每次为原容量的2倍,10、20、40、80…
- Vector中的所有方法都是线程同步的,都带有synchronized关键字,是线程安全的,效率低,使用较少。
- 使用集合工具类,将一个线程不安全的ArrayList集合转换成线程安全的
//非线程安全的
List myList = new ArrayList();
myList.add(1);
//调用synchronizedList方法,变成线程安全的
Collections.synchronizedList(myList);
注意:
java.util.Collection 是集合接口
java.util.Collections 是集合工具类
四、泛型机制
1、泛型
- 在JDK5.0之后的新特性–泛型 <E>
- 泛型这种语法机制,只在程序编译阶段起作用,只是给编译器参考的,运行阶段泛型没用
- 泛型的优点是:集合中存储的元素类型统一,从集合中取出的元素类型是泛型指定的类型,不需要进行大量的向下转型
- 泛型的缺点是:导致集合中存储的元素缺乏多样性,但日常开发中类型统一,所以泛型应用较多)
2、泛型使用举例
//素材
class Animal{
public void move(){
System.out.println("动物在移动");
}
}
class Cat extends Animal{
public void move(){
System.out.println("猫抓老鼠");
}
}
class Birds extends Animal{
public void move(){
System.out.println("鸟在飞");
}
}
不使用泛型:
List myList = new ArrayList();
Animal c = new Cat();
Animal b = new Birds();
myList.add(c);
myList.add(b);
Iterator iterator = myList.iterator();
while(iterator.hasNext()){
//没使用泛型前,这里返回类型只能是Object
Object obj = iterator.next();
//但Object类中没有move方法
//obj.move();报错
//需要频繁进行向下转型
if(obj instanceof Animal){
Animal animal = (Animal)obj;
animal.move();
}
}
使用泛型之后:(用泛型来指定集合中存储元素的类型)
//使用泛型List<Animal>即表示这个List集合中只允许存储Animal类型的数据
List<Animal> myList = new ArrayList<Animal>();
//myList.add("abc");传入String类型此时就error
Cat c = new Cat();
Birds b = new Birds();
myList.add(c);
myList.add(b);
//即迭代器类型是Animal类型
Iterator<Animal> iterator = myList.iterator();
while(iterator.hasNext()){
//此时next()方法的返回值类型就是Animal
Animal obj = iterator.next();
//这里也就不用向下转型了
obj.move();
}
但这里如果要继续调用Animal子类的特有方法,也得向下转型:
Iterator<Animal> iterator = myList.iterator();
while(iterator.hasNext()){
Animal obj = iterator.next();
obj.move();
//访问子类特有的方法
if(obj instanceof Cat){
Cat cat = (Cat)obj;
cat.catchMouse();
}
if(obj instanceof Birds){
Birds birds = (Birds)obj;
birds.fly();
}
}
3、自动类型推断机制(又称钻石表达式,JDK8之后)
List<Animal> myList = new ArrayList<Animal>();
使用自动类型推断机制后,可写成:
List<Animal> myList = new ArrayList<>();
4、自定义泛型
//这里的<T>中的T是标识符,随便写,但<E>和<T>常用些
public class GenericTest<T>{
public void doSome(T x){
System.out.println(x);
}
public static void main(String[] args) {
GenericTest<String> g1 = new GenericTest<>();
g1.doSome("code");
GenericTest<Integer> g2 = new GenericTest<>();
g2.doSome(9527);
//写了泛型而不用,那就是Object类型
GenericTest g3 = new GenericTest();
//这里传参是Object类型
g3.doSome();
}
}
5、增强for循环—foreach
增强for循环不涉及下标,对无下标场景的遍历很实用
语法:
for(元素类型 变量名:数组或者集合){
....
}
举例:
int[] array = {96,97,98,99};
//普通股for循环遍历
for(int i=0;i<array.length;i++){
System.out.println(array[i]);
}
//增强for循环
for(int data:array){
System.out.println(data);
}
List集合的三种遍历:
List<String> myList = new ArrayList<>();
myList.add("code");
myList.add("-9529");
myList.add("Fight!");
//迭代器遍历
Iterator<String> iterator = myList.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
//下标遍历
for(int i=0;i<myList.size();i++){
System.out.println(myList.get(i));
}
//增强for循环遍历
for(String s:myList){
System.out.println(s);
}
五、Set接口
1、HashSet集合
特点:
- 无序:存储时和取出来时的顺序不同
- 不可重复
- 放到HashSet集合种的元素实际时放到HashMap集合的key部分了
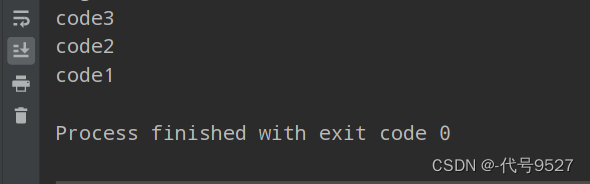
Set<String> mySet = new HashSet<>();
mySet.add("code1");
mySet.add("code2");
mySet.add("code3");
mySet.add("code1");
mySet.add("code1");
for(String str:mySet){
System.out.println(str);
}
运行结果:
2、TreeSet集合
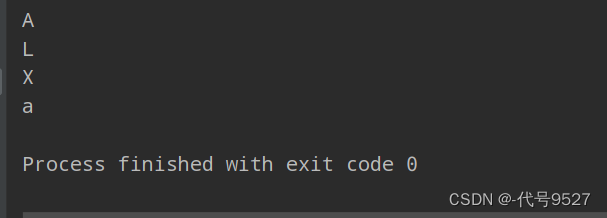
- 无序不可重复,但是存储的元素可以自动按照大小顺序排序,称为可排序集合
- 无序指的是存进去和取出来的顺序不同,并且没有下标
myTreeSet.add("A");
myTreeSet.add("X");
myTreeSet.add("a");
myTreeSet.add("L");
for(String s:myTreeSet){
System.out.println(s);
}
运行结果:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/146100.html

