
在前几篇关于Spring的文章中主要讲解的是个大概整体流程以及一些Bean创建前的准备工作,带入到代码中差不多就是refresh()中的这么几个方法:
prepareRefresh();
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
prepareBeanFactory(beanFactory);
postProcessBeanFactory(beanFactory);
StartupStep beanPostProcess = this.applicationStartup.start(“spring.context.beans.post-process”);
invokeBeanFactoryPostProcessors(beanFactory);
registerBeanPostProcessors(beanFactory);
beanPostProcess.end();
initMessageSource();
initApplicationEventMulticaster();
onRefresh();
registerListeners();
当上述的这些方法执行完以后,粗略的可以理解为Spring对于创建Bean前的准备工作已经完成的7788,接下来就开始真正要对Bean进行一个创建,也就是这个方法:
finishBeanFactoryInitialization(beanFactory);
那么接下来的内容,就针对这个方法,结合源码深入讲解一下Spring中的Bean创建流程。
其实之前在大致讲流程的时候,到这个方法的时候有稍微提到过,这个方法中的步骤基本是:
getBean –> doGetBean –> createBean –> doCreateBean,好那么根据这个思路,F7进入到finishBeanFactoryInitialization(beanFactory);方法中:
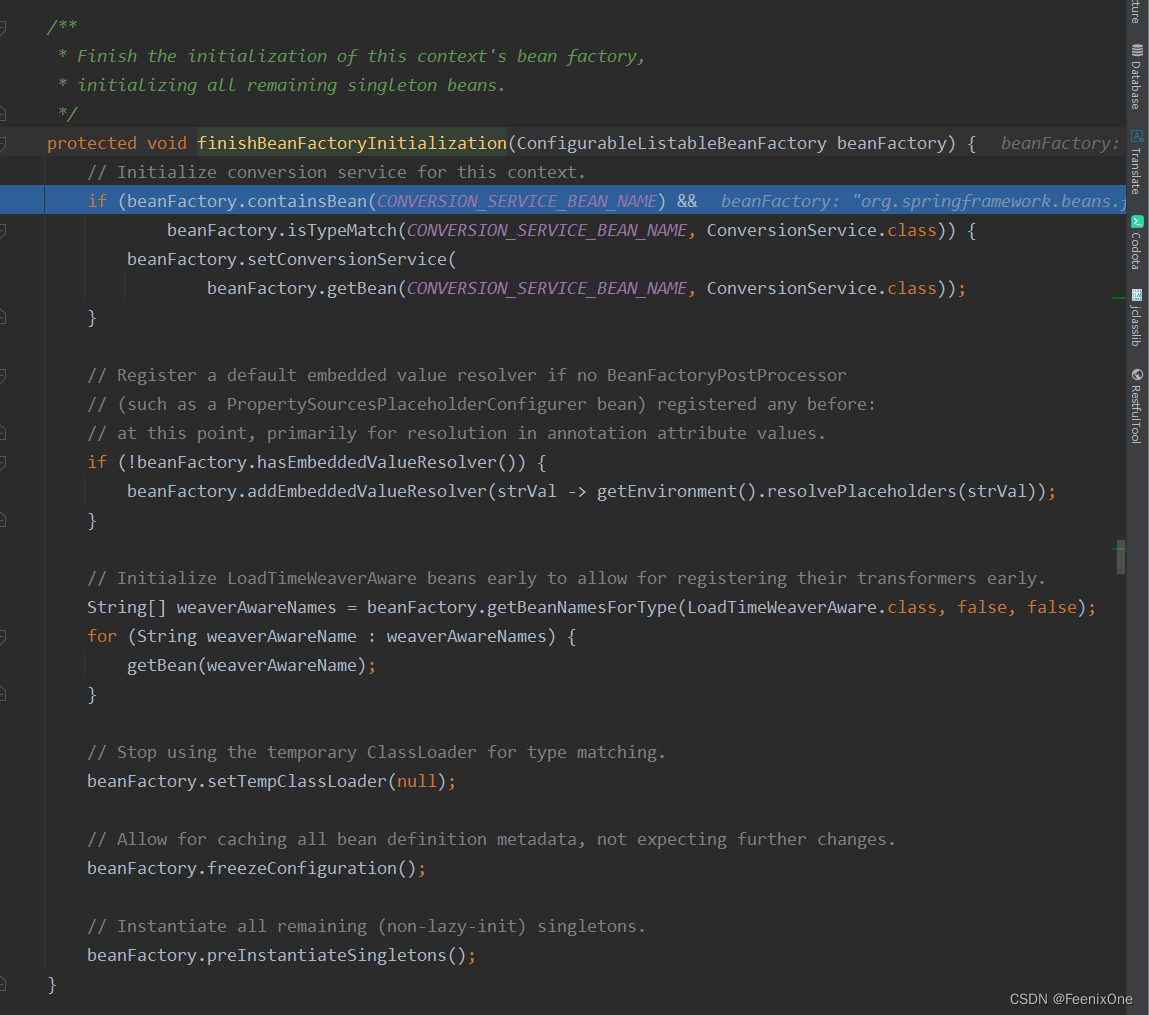

方法整体算不上长,一开始也是进行Bean创建前的准备工作:
为上下文初始化类型转换器
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
ConversionService用来往里面添加转换器,这个转换器一般情况下是不需要自定义的。这里也只是进行转换器的设置而不进行具体的执行,相当于只是提前准备好,当后面具体的Bean被实例化出来以后再来调用。
如果Beanfactory之前没有注册嵌入值解析器,则注册默认的嵌入值解析器,主要用于注解属性值的解析
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
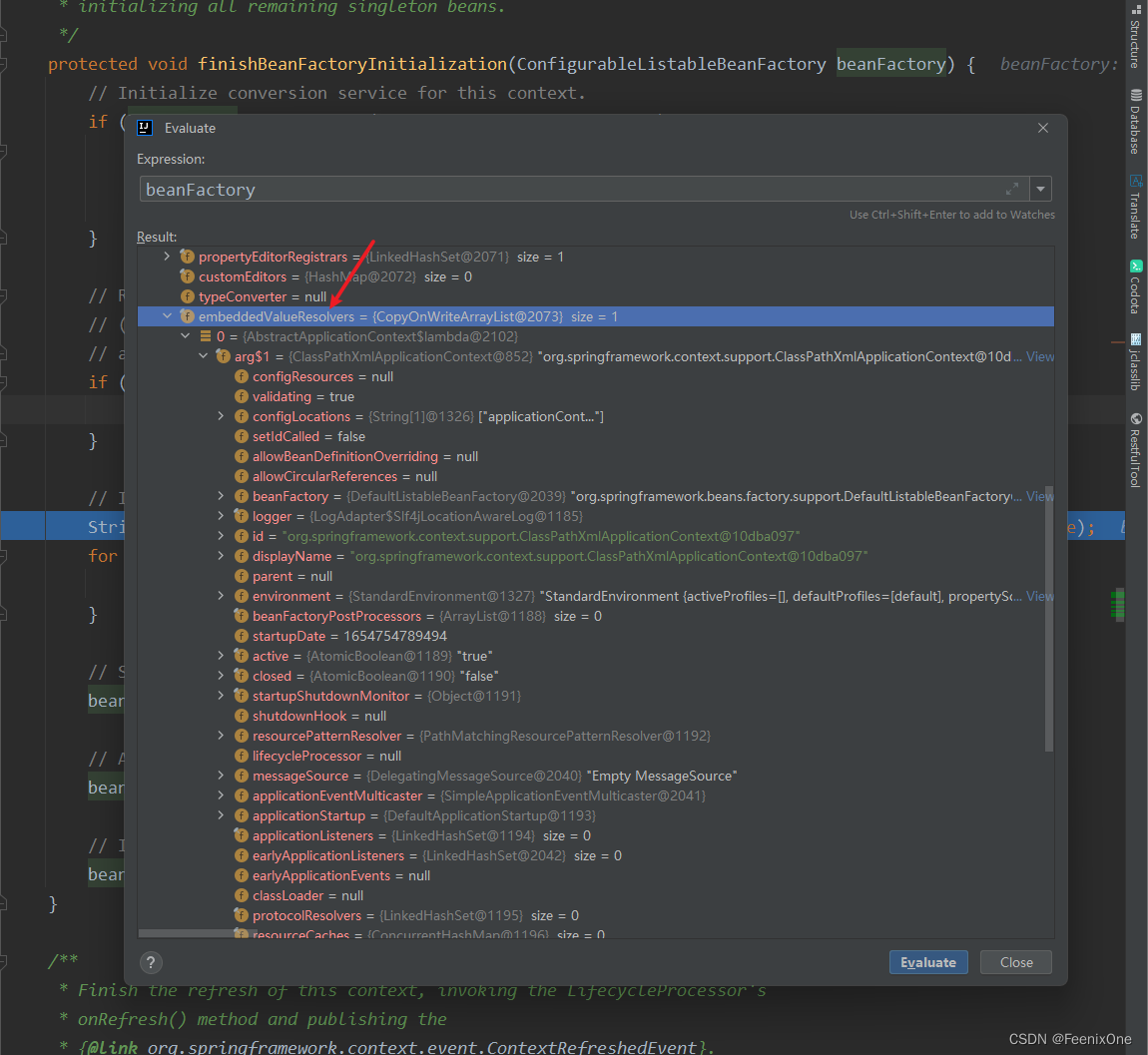
这一句结束之后,可以看到已经将嵌入值解析器设置进去,其实就是通过占位符的处理工作设置进去。
尽早初始化LoadTimeWeaverAware这个Bean,以便尽早注册它们的转换器
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
这一块主要是针对AOP的问题,后面说到AOP的时候再详细讲解。
禁止使用临时类加载器进行类型匹配
beanFactory.setTempClassLoader(null);
冻结所有的Bean定义,说明注册的Bean将不被修改或任何进一步的处理
beanFactory.freezeConfiguration();
这个方法F7进入以后,看到首先将configurationFrozen属性设为true,又将一个字符串转为数组用来设置frozenBeanDefinitionNames属性的值。因为下一步就要开始真正的实例化操作,在此最后一步的时候要确保BeanDefinition不可更改,将这些Bean的封装信息全部缓存起来,也就不允许再修改了。后面进行相关实例化的时候,就按照缓存中的指定去完成实例化。
实例化剩下的单例对象
beanFactory.preInstantiateSingletons();
前面的都是准备,准备再准备,经过freezeConfiguration()将这些准备信息全部确定下来以后,开始preInstantiateSingletons()进行真正的实例化操作。而需要实例化的对象,就在beandefinitionMap中
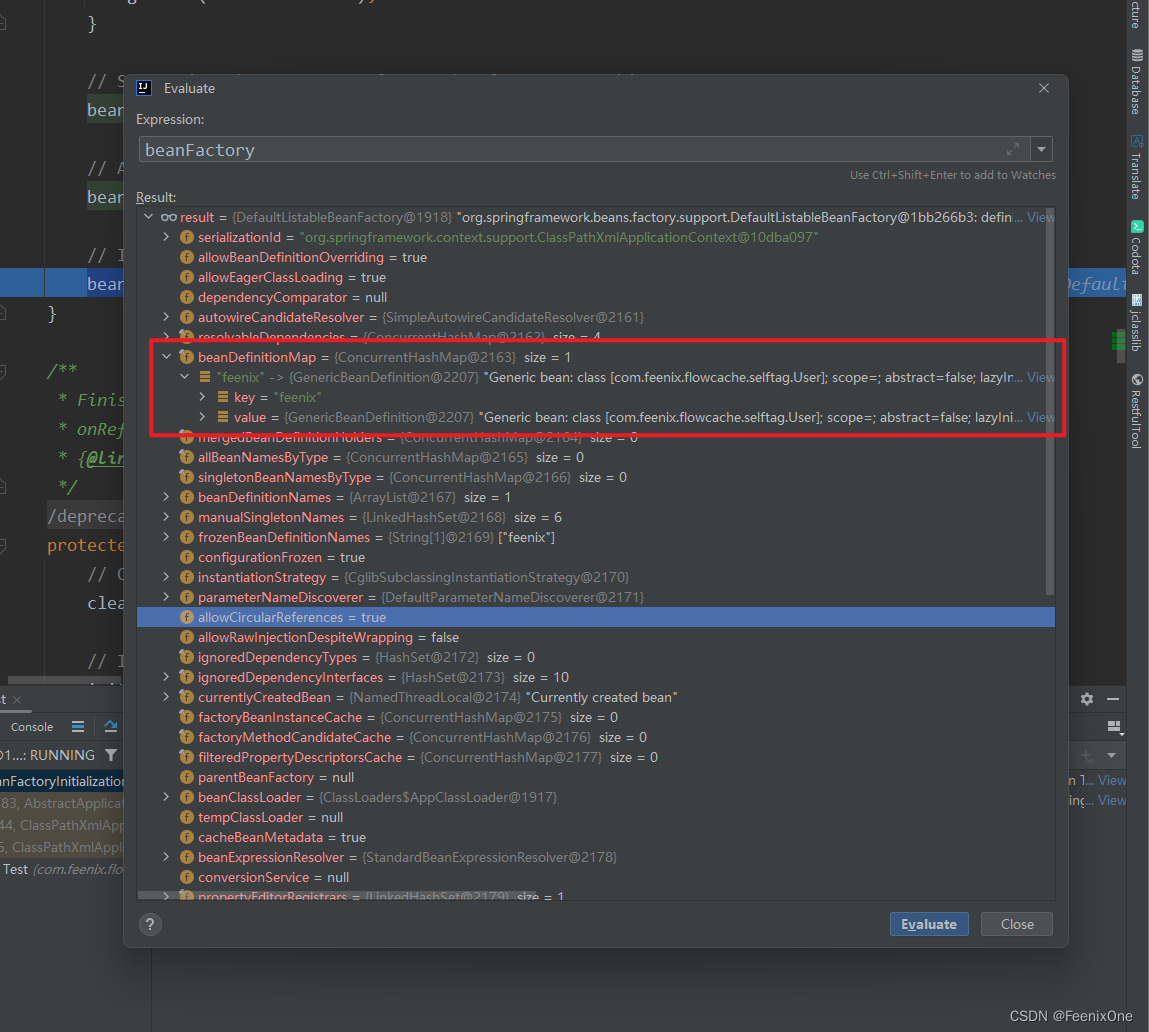
F7进入到方法总来查看具体的实例化步骤:
将所有的BeanDefinition的名字创建一个集合,后面会循环遍历一个一个创建
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
合并父类BeanDefinition
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
这一步会检查beanName对应的mergeBeanDefinitions是否存在于缓存中,此缓存是在beanFactoryPostProcessor中添加的。如果存在缓存中则直接返回,如果不存在缓存中,根据beanName和BeanDefinition获取mergeBeandefinitions。因为在实例化之前,要把所有的beanDefinition对象转换成RootBeandefinition对象进行缓存,后续在需要马上实例化的时候,直接获取定义信息,而定义信息中如果包含了父类,必须要先创建父类才能有子类。
条件判断:抽象、单例、懒加载
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {…..}
判断是否实现FactoryBean接口
if (isFactoryBean(beanName)) {…..}
为什么要进行这个条件的判断,因为在Spring中有2个至关重要的父接口:BeanFactory接口和FactoryBean接口。这两个接口本质上都是用来创建对象使用,如果使用BeanFactory接口,那么必须严格遵守SpringBean的生命周期,从实例化到初始化再到invokeAwareMethod.invokeInitMehod、before、after等,此流程非常的复杂且麻烦;为了能够以一种更加便捷的方式创建,所以有了FactoryBean接口,不需要遵循此创建顺序。那是如何可以做到不需要遵循创建顺序的呢?使用3个方法:
isSingleton –> 判断对象是否单例
getObject –> 直接返回对象
getObjectType –> 返回对象类型
而当使用FactoryBean接口来创建对象的时候,一共创建了几个对象?
创建的第1个对象是实现了FactoryBean接口子类的对象;
创建的第2个对象是通过getObject方法返回的对象;
而这两个对象由谁来管理,显然都交给Spring来管理。但是存放对象的缓存集合不同,实现了FactoryBean接口的对象在一级缓存中,但是调用getObject方法获取的对象在FactoryBeanObjectCache中。如果不是单例对象的话,那么每次需要调用的时候重新创建,缓存中不会保存当前对象。
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
FACTORY_BEAN_PREFIX其实就是取地址符”&”,使用取地址符&加上beanName作为key,取到对应的value就是真正的对象
if (isEagerInit) {…..}
判断是否希望急切的初始化,如果需要,则通过beanName获取bean实例。
接下来再往下走,进入到doGetBean方法中,有一个核心方法getObjectForBeanInstance()
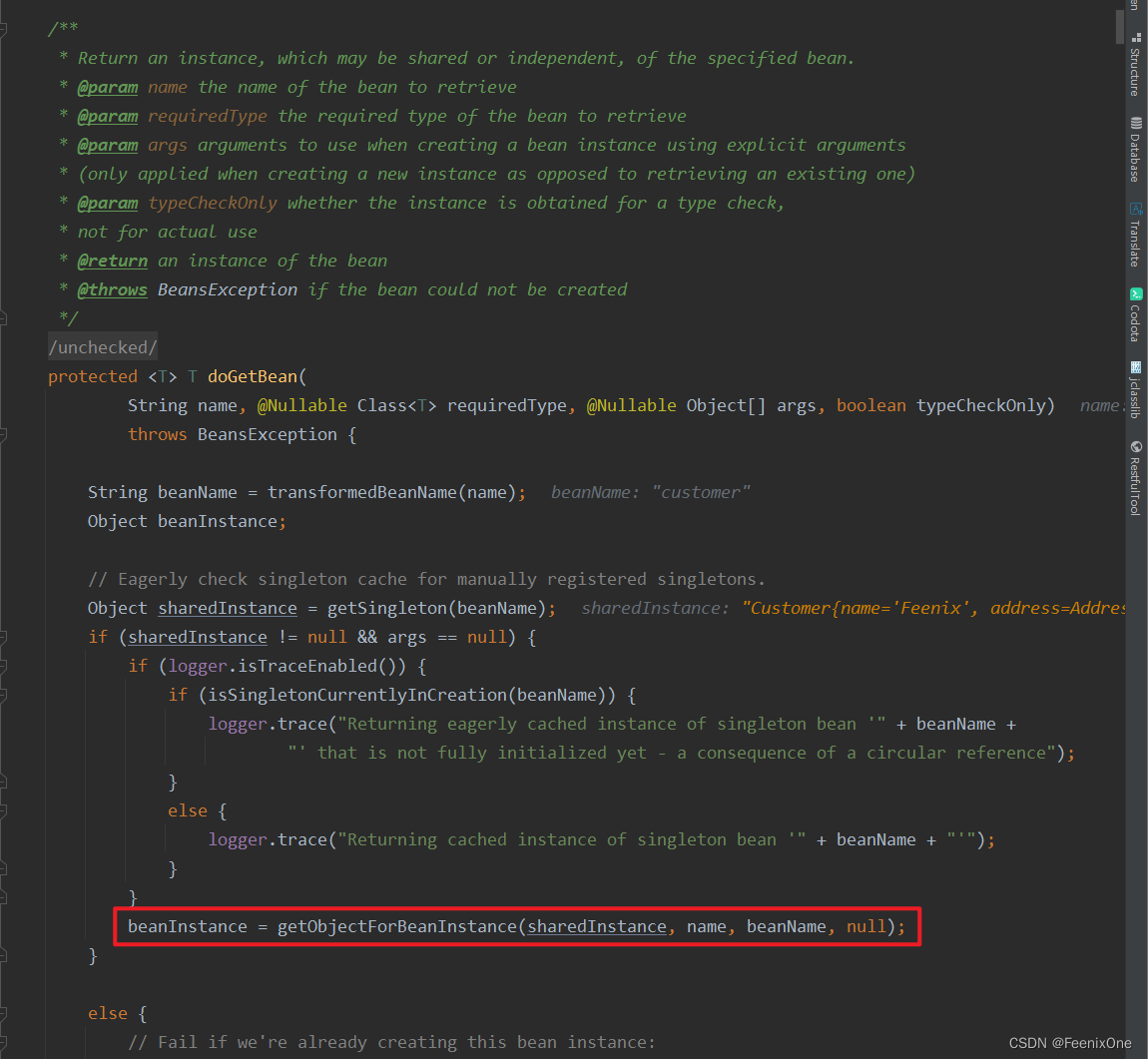 上面说到,一个对象使用FactoryBean接口,那么在整个Spring的生命周期就会创建2个对象,第1个对象是实现了FactoryBean接口子类的对象,第2个对象是通过getObject方法返回的对象,而这个通过getObject方法返回的对象就是由getObjectForBeanInstance()方法调用实现的。
上面说到,一个对象使用FactoryBean接口,那么在整个Spring的生命周期就会创建2个对象,第1个对象是实现了FactoryBean接口子类的对象,第2个对象是通过getObject方法返回的对象,而这个通过getObject方法返回的对象就是由getObjectForBeanInstance()方法调用实现的。
if (isPrototypeCurrentlyInCreation(beanName)) {…..}
这个就是循环依赖的一个检测,在原型模式下如果存在循环依赖的情况,那么直接抛出异常
BeanFactory parentBeanFactory = getParentBeanFactory();
获取父类容器。
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {…..}
如果beanDefinitionMap中,也就是在所有已经加载的类中不包含beanName,那么就尝试从父容器中获取。在这个判断中,出现很多goGetBean和getBean方法,核心逻辑其实就是父子容器的概念,如果子里面没有就从父中去获取。
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
这个判断是对已经创建的Bean和未创建的Bean进行标记,两种不同的Bean添加到不同的集合中。在真正对未创建的Bean进行创建的时候,会有一个clearMergedBeanDefinition(beanName)方法对Bean进行重新合并,以防止一些元数据被修改。
 RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
根据beanName获取这个Bean完整的描述信息,在这个方法里面可以看到检查beanName对应的mergedBeanDefinitions是否存在于缓存中,此缓存是在beanFactoryPostProcessor中添加的。虽然每次操作的时候可以根据beanName获取新的RootBeanDefinition,但是从缓存中去拿效率更快,所以在整个Spring的源码中总是可以看到各种各样的缓存。如果不在缓存中,再调用getMergedBeanDefinition(beanName, getBeanDefinition(beanName))方法去创建mergedBeanDefinitions
String[] dependsOn = mbd.getDependsOn();
这个其实就是配置文件中<bean></bean>标签中的depends-on属性,这个依赖指的是当前Bean创建前需要依赖别的Bean先创建好
if (dependsOn != null) {…..}
如果存在依赖Bean,则优先实例化依赖的Bean
if (mbd.isSingleton()) {…..}
判断bean是不是单例对象,如果是单例对象的话,会调用getSingleton来获取。getSingleton方法内部会加锁以保证全局变量的同步,首先会检查一级缓存中是否存在对应的Bean,如果对象不存在,才需要进行Bean的实例化。在Bean的实例化过程中,会记录当前对象的加载状态,可理解为一些检查工作,会记录下这个对象当前是不是正在被创建。
再往下,真正进入到createBean方法中,在这个方法中,其实也还是以一些判断和准备为主:
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
锁定class,根据设置的class属性或者根据className来解析class。具体怎么解析呢,进入方法内可以看到会判断mbd的定义信息中是否包含beanClass,并且是Class类型的,如果是直接返回,否则的话进行更详细的解析。下一步判断是否有安全管理器(安全管理器的作用是用来赋权限用的,会判断当前的这个操作是否是安全的,具体怎么判断不必深究,因为进入方法以后会看到根本不是Java写的),如果没有的话,调用doResolveBeanClass进行详细的处理解析过程。
在doResolveBeanClass这个方法中,首先会获取Bean的类加载器,然后判断typesToMatch是否为空,如果不为空那么使用临时加载器进行加载。然后获取bean的className,使用这个className和classLoader调用ClassUtils.forName(className, classLoader)处理解析,就是利用反射来操作啦。
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
条件筛选,重新赋值RootBeanDefinition,并设置BeanClass属性
 mbdToUse.prepareMethodOverrides();
mbdToUse.prepareMethodOverrides();
如果配置文件中有使用到lookup-method标签的话,这个方法会对lookup-method标签进行解析,在Spring中默认的对象都是单例的,Spring会在一级缓存中持有该对象方便下次直接获取。如果是原型作用域的话,会创建一个新对象。如果想在一个单例模式的Bean下引用一个原型模式的Bean该怎么办?此时需要引用lookup-method标签来解决这个问题:通过拦截器的方式每次需要的时候再去创建最新的对象,而不会把原型对象缓存起来。
 Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
给BeanPostProcessor一个机会返回代理来替代真正的实例,应用实例化前的前置处理器。一般在用户没有自定义BeanPostProcessor生成代理对象的情况下,是不会进行执行处理的。
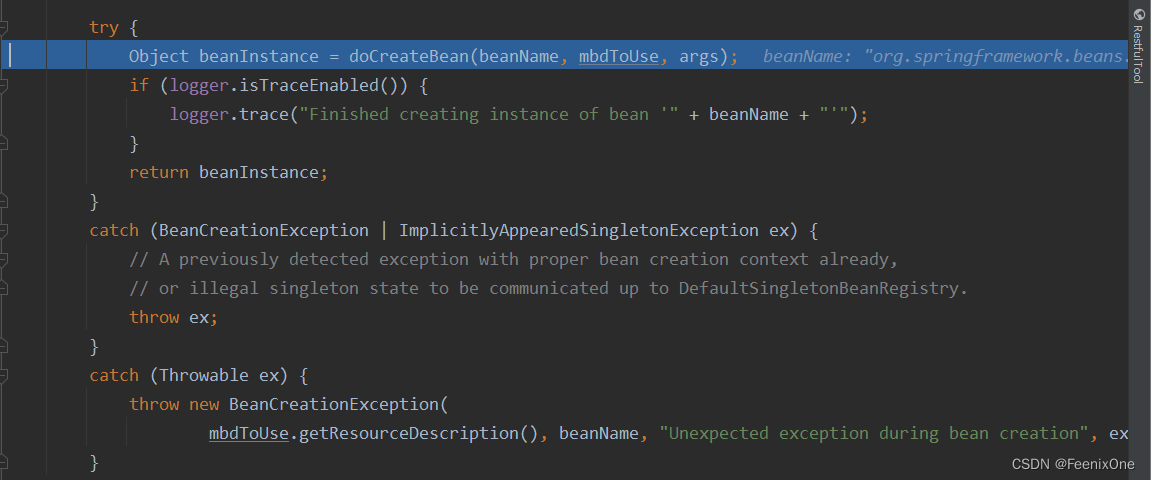 Object beanInstance = doCreateBean(beanName, mbdToUse, args);
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
实际创建Bean。在Spring中创建对象有多种方式:
1、自定义BeanPostProcessor,生成代理对象InstantiationAwareBeanPostProcessor;
2、通过反射创建对象(最常见最频繁的使用方式);
3、通过FactoryMethod创建对象(这个基本没有什么应用场景);
4、通过FactoryBean创建对象(是一个接口规范的实现);
5、通过Supplier创建对象(是BeanDefinition的一个属性值);
而FactoryMethod和FactoryBean一样,都是<bean></bean>标签中的属性之一。
进入到doCreateBean方法中:
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
先判断mbd是否单例,如果是单例,则从FactoryBean实例缓存中移除当前Bean的定义信息
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
在createBeanInstance这个方法中会执行的逻辑:
确认需要创建的Bean实例的类可以实例化;
确保Class不为空,并且访问权限是public,否则抛出对应的异常;
判断当前BeanDefinition中是否包含实例供应器,此处相当于一个回调方法,利用回调方法来创建Bean:
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
可以看到FactoryBean是抽象出一个接口规范,所有的对象必须通过getObject方法获取;而Supplier可以随便定义创建对象的方法,不仅仅局限于getObject。
对于使用FactoryMethod方法实例化的流程如下图,这也正是instantiateUsingFactoryMethod方法的详细流程:
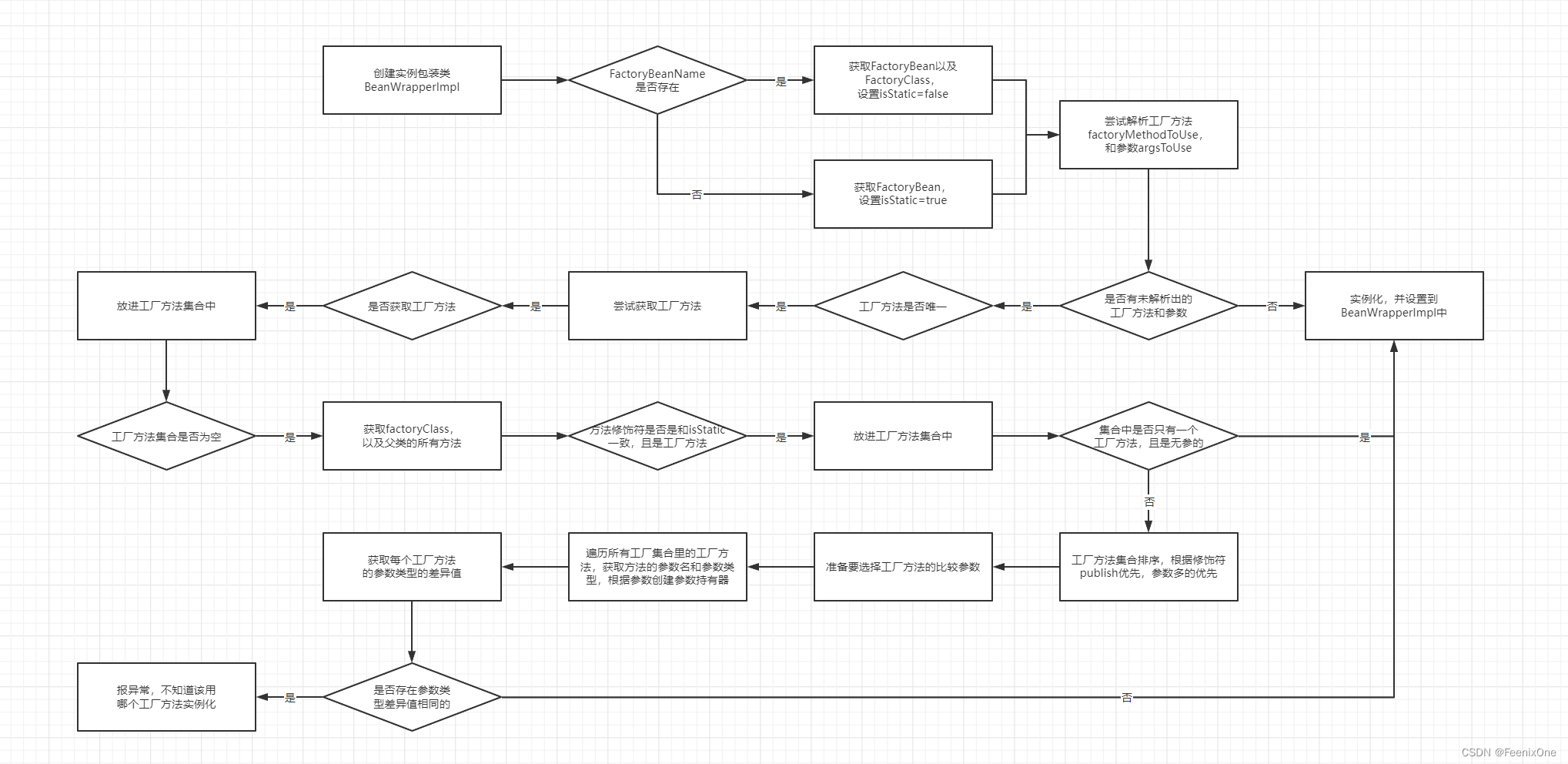
instantiateUsingFactoryMethod这个方法在整个Spring体系里面算是比较长且复杂的方法,这个方法头头尾尾写了三百多行,对于工厂实例和工厂类型的判断本身就是非常复杂的。
继续代码往下执行,来到这一步:
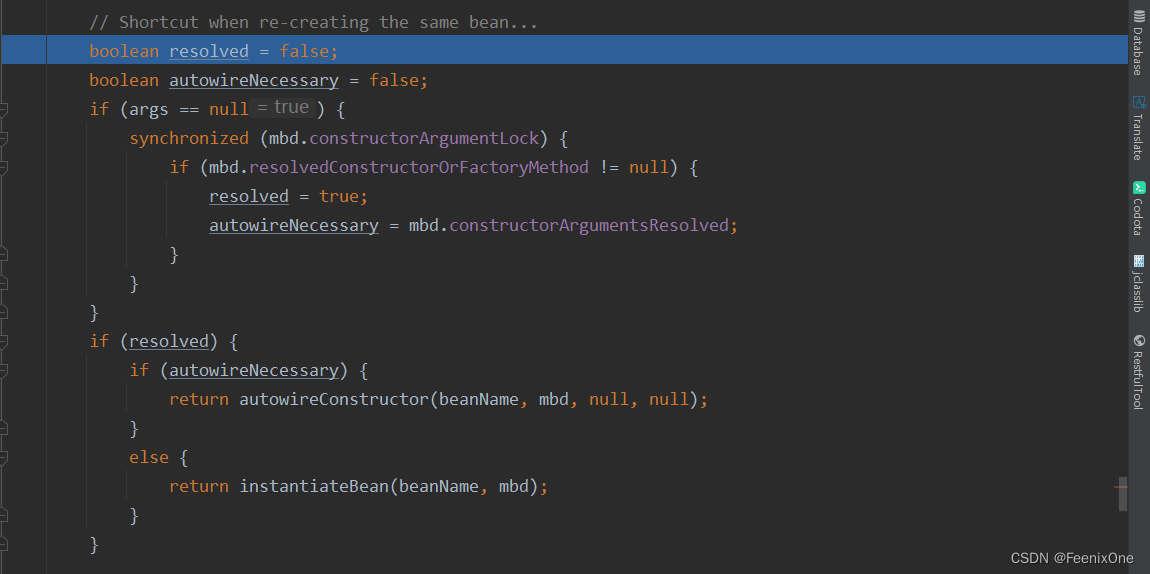
boolean resolved = false;
标记下,防止重复创建同一个Bean
boolean autowireNecessary = false;
是否需要自动装配
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
// 因为一个类可能有多个构造函数,所以需要根据配置文件中配置的参数
// 或传入的参数来确定最终调用的构造函数
// 因为判断过程会比较,所以Spring会将解析确定好的构造函数缓存到
// BeanDefinition中的resolvedConstructorOrFactoryMethod字段中
// 在下次创建时直接从RootBeanDefinition中的属性
// resolvedConstructorOrFactoryMethod缓存的值获取从而不需要多次解析
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
也就是说第一次创建对象的时候,肯定是进不到判断的方法中
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
从Bean后置处理器中为自动装配寻找构造方法,有且只有一个有参构造或者有且只有@Autowired注解构造
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
有几种情况可进入判断中:
1、存在可选构造方法
2、自动装配模型为构造函数自动装配
3、给Beandefinition中设置了构造参数值
4、有参与构造函数参数列表的参数
ctors = mbd.getPreferredConstructors();
if (ctors != null) {
return autowireConstructor(beanName, mbd, ctors, null);
}
找出最合适的默认构造方法,构造函数自动注入
return instantiateBean(beanName, mbd);
使用默认无参构造函数创建对象,如果没有无参构造且存在多个有参构造方法且没有@AutoWired注解构造,则会报错。
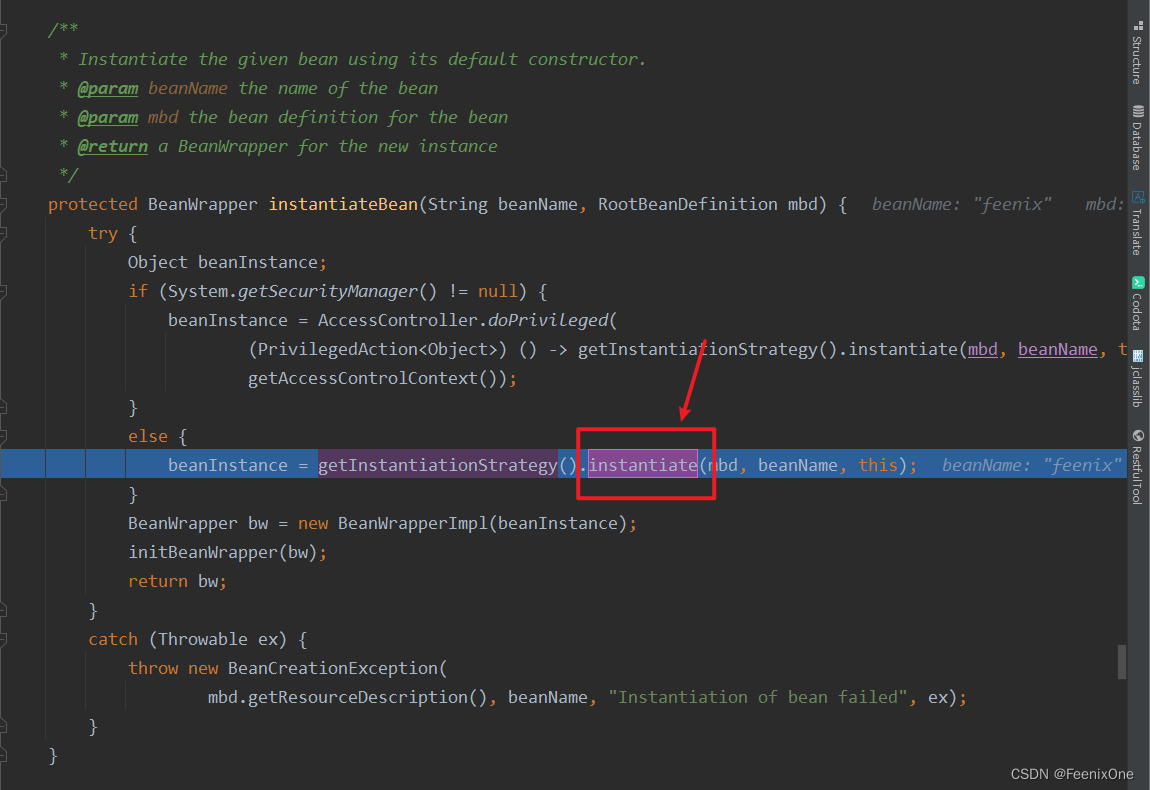
实例化策略 -> Simple实例化策略 -> Cglib实例化策略 -> 动态代理对象 -> 无参构造
-> 无参构造实例化 -> 有参构造
-> 有参构造实例化
-> 工厂方法实例化
获取实例化策略并进行实例化操作,进入instantiateBean方法的instantiate方法中
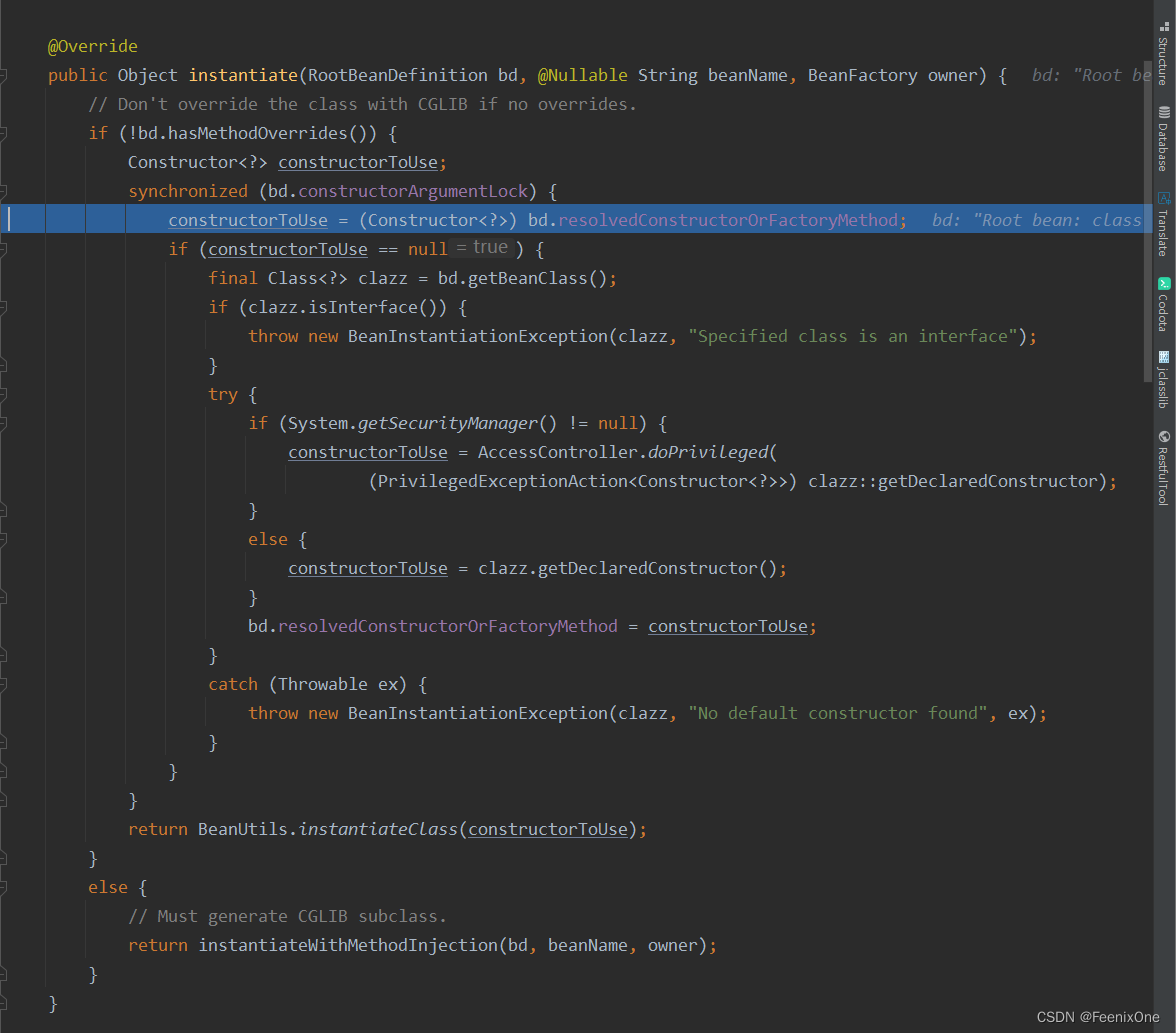
constructorToUse = (Constructor<?>) bd.resolvedConstructorOrFactoryMethod;
查看bd对象里是否含有构造方法
final Class<?> clazz = bd.getBeanClass();
如果没有,则从bd中获取beanClass
constructorToUse = clazz.getDeclaredConstructor();
获取默认的无参构造器
bd.resolvedConstructorOrFactoryMethod = constructorToUse;
获取到构造器之后将构造器赋值给bd中的属性
return BeanUtils.instantiateClass(constructorToUse);
通过反射生成具体的实例化对象
创建完成对象以后,返回代码到BeanWrapper bw = new BeanWrapperImpl(beanInstance);

将生成的Bean包装成BeanWrapper对象,BeanWrapper继承ConfigurablePropertyAccessor,ConfigurablePropertyAccessor又继承PropertyAccessor, PropertyEditorRegistry, TypeConverter,可对对象中的属性值进行相关的编辑和转换,之后需要的时候可在包装类中直接执行。
那么到这一步为止,可以理解为实例化工作已经完成,实例化完成后,下一步就要开始进行初始化工作,进行属性的填充。代码继续执行,回到doCreateBean方法中,来到
Object bean = instanceWrapper.getWrappedInstance();
从包装类中获取原始Bean
Class<?> beanType = instanceWrapper.getWrappedClass();
获取具体的Bean对象的Class属性
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
“Post-processing of merged bean definition failed”, ex);
}
mbd.postProcessed = true;
}
}
允许beanPostProcessor修改合并好的beanDefinition。这个看起来好像很迷惑,在上面的内容中说到在实例化对象的时候有一个方法是beanFactory.freezeConfiguration(),也就是将beanDefinition给冰冻起来。其实并不冲突,冰冻的是在实例化之前不做任何的修改,现在是已经完成实例化,对象已经创建完成了自然可以修改,可以往beanDefinition中加入一些描述信息来方便后续的一些结果调用。
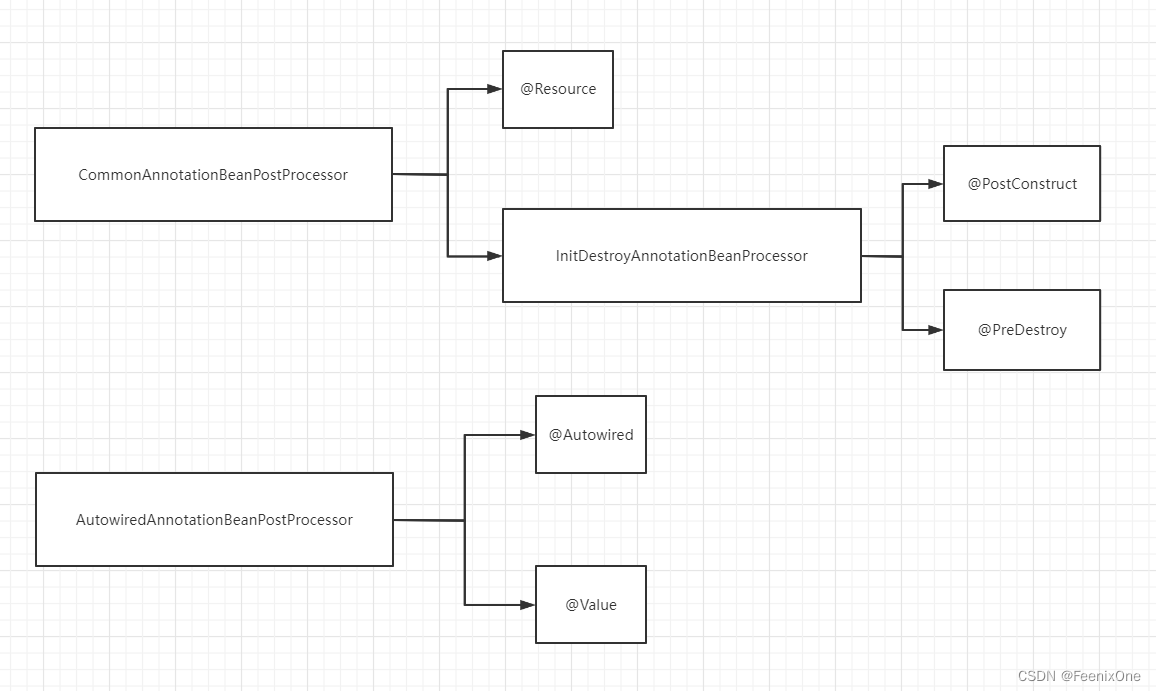
在MergedBeanDefinitionPostProcessor这个接口中定义两个方法:
postProcessMergedBeanDefinition -> Spring通过这个方法找到所有需要注入的字段,同时做缓存
resetBeanDefinition -> 用于在BeanDefinition被修改后,清除容器中的缓存
postProcessMergedBeanDefinition这个方法所有的底层实现最终要的目的是用来进行相关注解的解析和处理。例如AutoWiredAnnotation…、CommonAnnotation…..、InitDestoryAnnotation…..等等,比如InitDestoryAnnotationBeanPostProcessor中对postProcessMergedBeanDefinition的实现就是:
调用方法获取生命周期元数据并保存:LifeCycleMetadata metadata = findLifeCycleMetadata(beanType);
验证相关方法:metadata.checkConfigMembers(beanDefinition);
加载注解的相关解析配置类
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
判断当前Bean是否需要提前曝光:单例&&允许循环依赖&&当前Bean正在创建中,检测循环依赖
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace(“Eagerly caching bean ‘” + beanName +
“‘ to allow for resolving potential circular references”);
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
为避免后期循环依赖,可以在Bean初始化完成前将创建实例的ObjectFactory加入工厂
}
当实例化完成之后,要开始进行初始化赋值操作,但是赋值的时候,值的类型可能是引用类型,需要从Spring容器中获取具体的某个对象来完成赋值的操作。而此时,需要引用的对象可能被创建了,也可能没被创建。如果被创建了,可以直接获取;如果没有创建,在整个过程中就会涉及到对象的创建过程。而内部对象的创建过程中又会有其它的依赖,其它的依赖中可能包含有当前对象,而此时当前对象还没有创建完成,这就是著名的循环依赖问题。
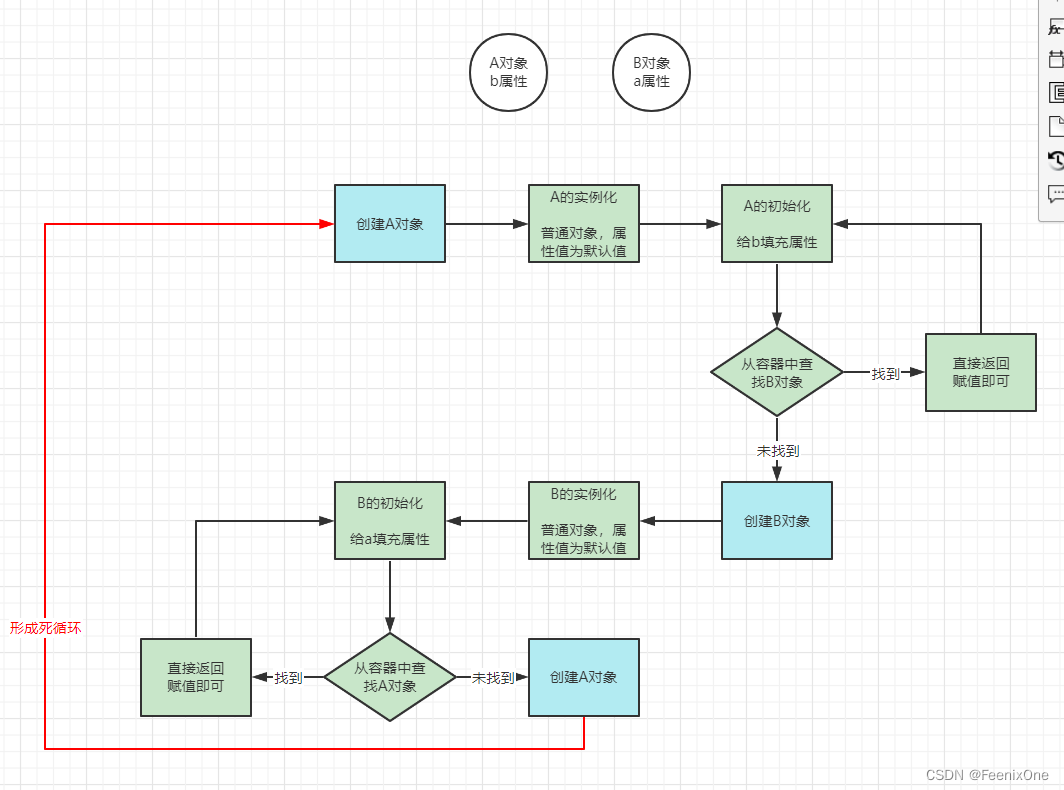
在获取完整对象的时候,分为实例化和初始化两个步骤。在初始化环节的填充属性阶段,有没有可能会改变当前对象的地址空间?不会改变对象的地址空间
但是得考虑另外一种情况,Spring在使用的时候会配置AOP,需要生成具体的代理对象。
1、那么在生成代理对象之前,要不要生成普通对象?要
2、能否确定什么时候会调用具体的对象(无论是普通对象还是代理对象)?不能
3、有没有可能在Spring中同时存在一个beanName的普通对象和代理对象?有可能
4、在调用的时候是根据beanName来获取对象,此时要获取到哪个对象?取决于分层分块存储,可以创建两个缓存,分别存储普通对象和代理对象
5、那这两种缓存应该优先获取哪一个?优先获取的是代理对象,然后才是普通对象,代理对象中应该包含了普通对象的所有功能。如果一个对象需要被代理了,那么此时普通对象就可以不用存在,只需要代理对象即可。也就是说在后续创建代理对象之后,就可以使用代理对象来覆盖普通对象,普通对象就可以彻底不需要了。
回到问题2中,什么时候要调用对象?
在调用对象的时候,如果检测到当前对象被代理,那么直接创建代理对象覆盖即可。怎么能够在随时需要的时候创建代理对象呢?
类似于观察者,但本质上并不是。传递进入一个生成代理对象的匿名内部类,当需要调用的时候,直接调用匿名内部类(lambda)来生成代理对象,类似于回调机制。
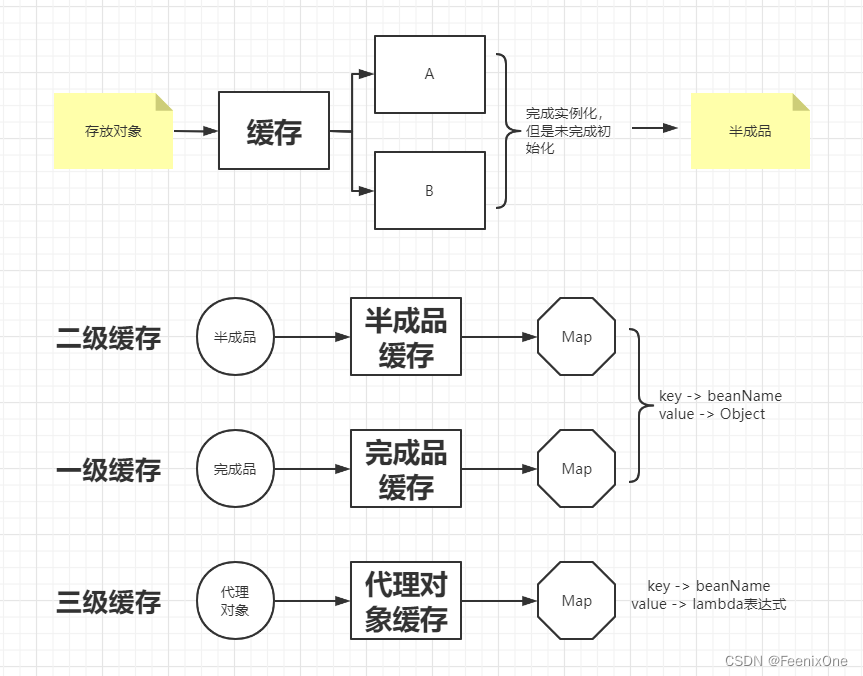
说到这里对于Spring中的缓存机制大概有一个清晰的认识了,所谓的半成品缓存就是Spring中的二级缓存;完成品缓存就是Spring中的一级缓存;代理对象缓存就是Spring中的三级缓存。
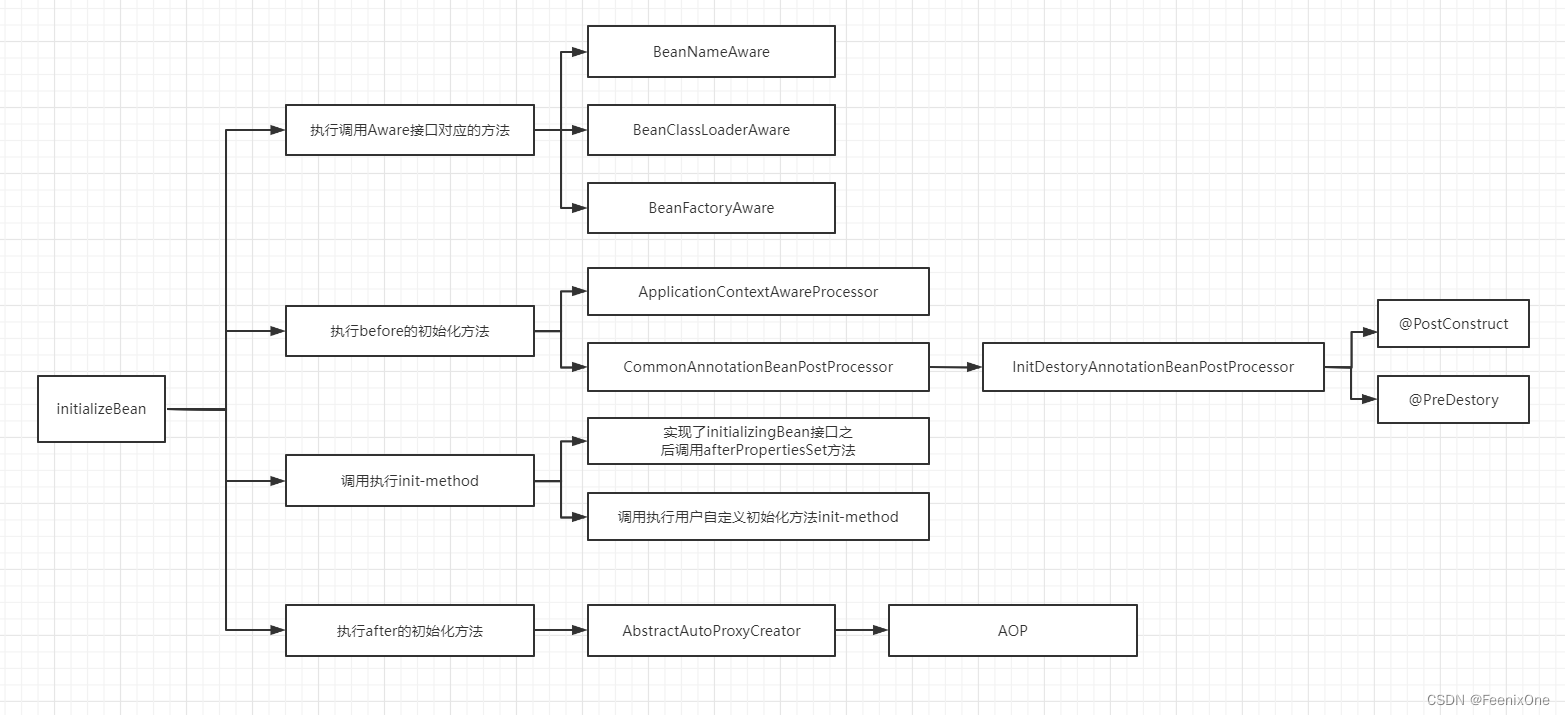
6、那么初始化包含了哪些环节?
1)填充属性
2)执行Aware接口所对应的方法
3)执行beanPostProcessor中的before方法
4)执行init-method
5)执行beanPostProcessor中的after方法
上述步骤执行完成之后,是为了获取到一个完整的成品对象。但是在初始化前能确定哪一个对象需要生成代理对象吗?很显然并不能。而且三级缓存只是一个回调机制,所以能否把所有的bean所需的创建代理对象的lambda表达式都放到三级缓存中?是可以的,可以将所有bean对象需要的创建代理对象的lambda表达式放到三级缓存中,后续如果需要调用,直接从三级缓存中调用执行即可。如果明确不需要,在生成完整对象之后可以把三级缓存中lambda表达式清除掉——向一级缓存中放成品对象的时候就可以清除。
7、在什么时候生成具体的代理对象呢?
1)在进行属性注入的时候,调用该对象生成的时候检测是否需要被代理。如果需要,直接创建代理对象;
2)在整个过程中,没有其他的对象有对当前对象的依赖,那么在生成最终的完整对象之前生成代理对象即可——BeanPostProcessor中的after方法;
8、上面说到,二级缓存中放的是完成实例化但未完成初始化的半成品对象;一级缓存中放的是成品对象,这个成品对象中包含哪些?既包含普通不需要代理的对象,也包含代理对象。
9、在之前的讲解中经常说到Spring解决循环依赖的方式叫提前暴露,到底这个提前暴露是个什么意思?其实指的就是二级缓存,只实例化但未初始化对象。
10、三个层级的缓存在进行对象查找时候的顺序是怎样的?1 -> 2 -> 3
11、有没有可能从三级缓存直接到一级缓存?是可以的。
如果说单纯为了解决循环依赖问题,那么使用二级缓存已经足够。三级缓存存在的意义是为了代理对象的创建和生成过程,如果没有代理对象,二级缓存足以解决问题。
所以,解决循环依赖最本质的点在于,将对象创建的实例化和初始化时分开处理的,当完成实例化之后,就可以让其它对象引用当前对象了,只不过当前对象不是一个完整对象而已,后续还是需要完成此对象的剩余步骤。换句话说,就是直接获取对象的引用地址,保证对象能够被找到,而对象在堆空间中属性是否有设置过并不重要。
好了,花了这么大篇幅讲解了Spring解决循环依赖的思路,接下来继续回到源码
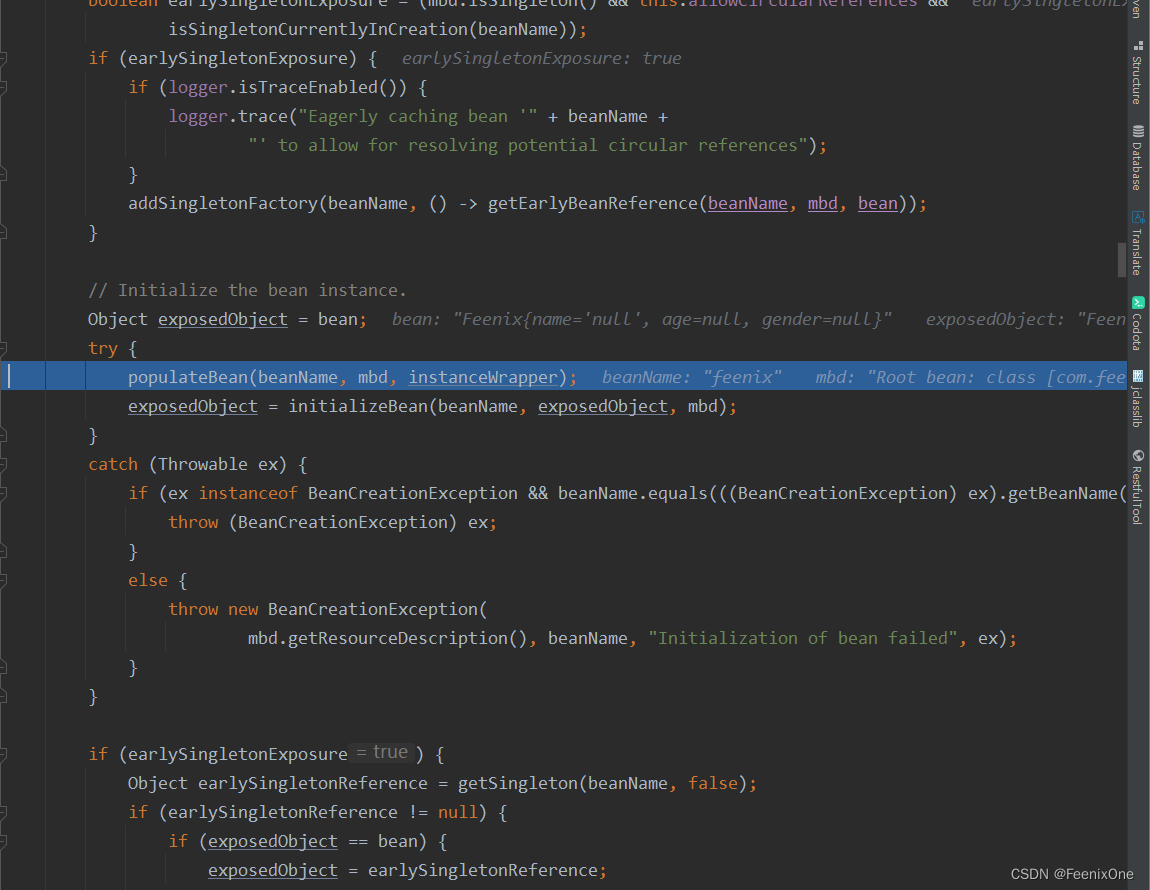
Object exposedObject = bean; // 初始化Bean实例
try {
populateBean(beanName, mbd, instanceWrapper);
对Bean的属性进行填充,将各个属性值注入。可能存在依赖其它Bean的属性,则会递归初始化依赖的Bean
exposedObject = initializeBean(beanName, exposedObject, mbd);
执行初始化逻辑
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, “Initialization of bean failed”, ex);
}
}
在上述的讲解中一直提到”填充属性”这个概念,到底要怎么理解?简单来讲,填充属性就是给属性赋值。这个说起来比较简单,但是要知道属性分为基本数据类型和引用类型。这两种类型的处理方式完全不一样,原因在于整个Spring的生命周期里面,所有的对象都必须是单例的。如果是引用类型的话,则必须要引用出一个具体的对象。
进入到populateBean方法中:
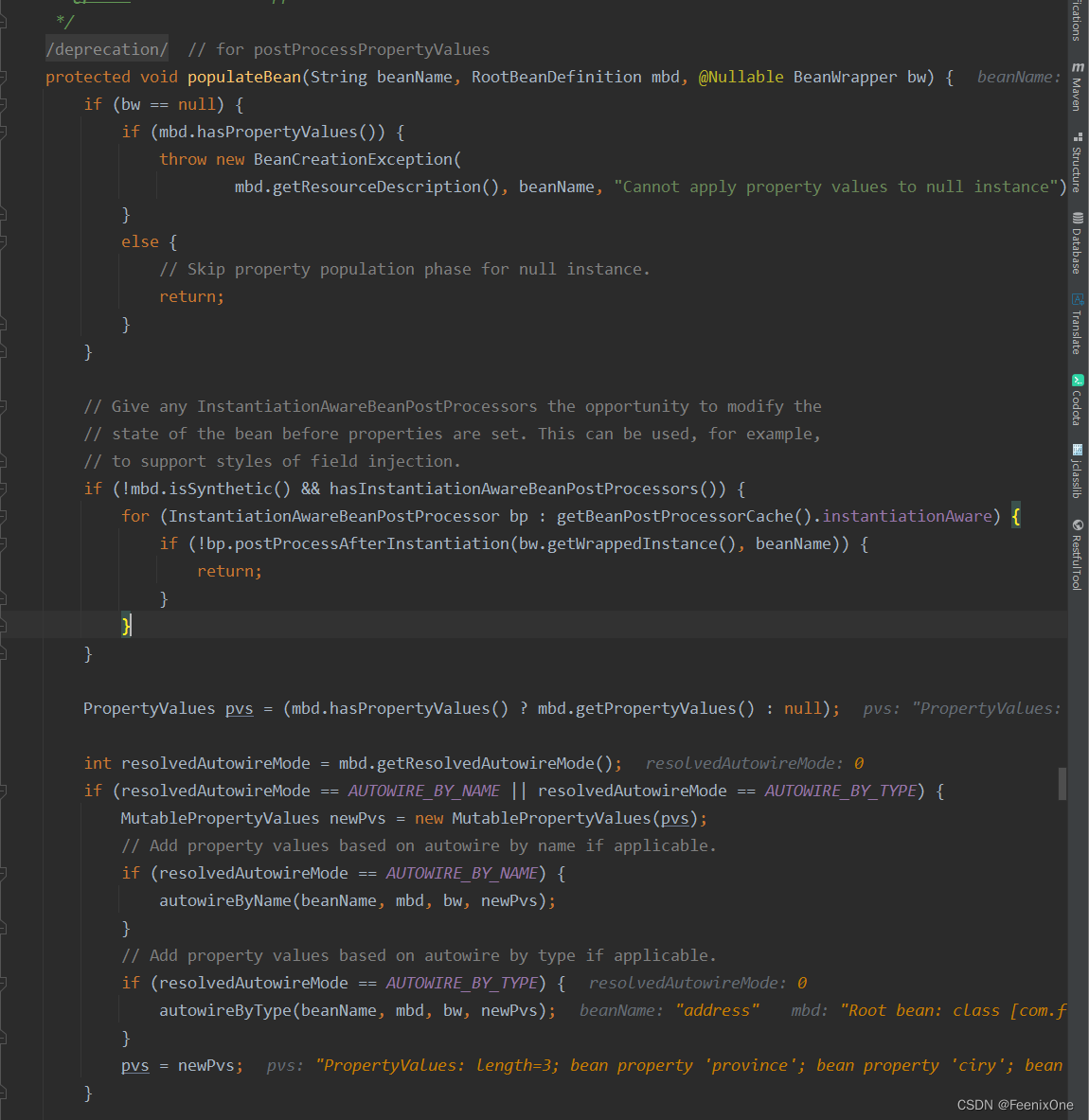
一般只有AOP相关的prointCut配置或者Advice配置才会将isSynthetic设为true
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
if (!bp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
PropertyValues:包含一个或多个PropertyValue对象的容器,通常包括针对特定目标Bean的一次更新
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
获取mbd的自动装配模式,是byName啊,还是byType啊
如果自动装配模式是按名称或者按类型自动装配Bean属性
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
根据autowire的名称添加属性值
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
通过bw的PropertyDescriptor属性名,查找出对应的Bean对象,将其添加到newPvs中
autowireByName(beanName, mbd, bw, newPvs);
}
根据autowire的类型添加属性值
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
通过bw的PropertyDescriptor属性类型,查找出对应的Bean对象,将其添加到newPvs中
utowireByType(beanName, mbd, bw, newPvs);
}
让pvs重新引用newPvs,newPvs此时已经包含了pvs的属性值以及通过AUTOWIRE_BY_NAME、
AUTOWIRE_BY_TYPE自动装配所得到的属性值
pvs = newPvs;
}
xml文件中Bean的属性autowire=”byName”、autowire=”byType”在此进行判断和注入
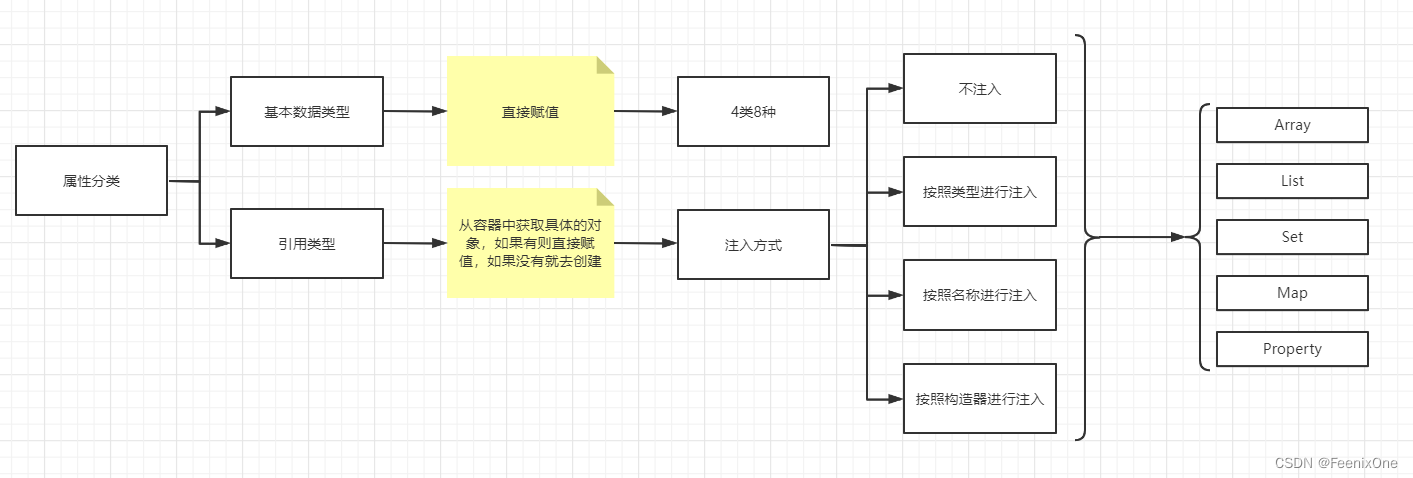
populateBean方法中填充属性的不同方式
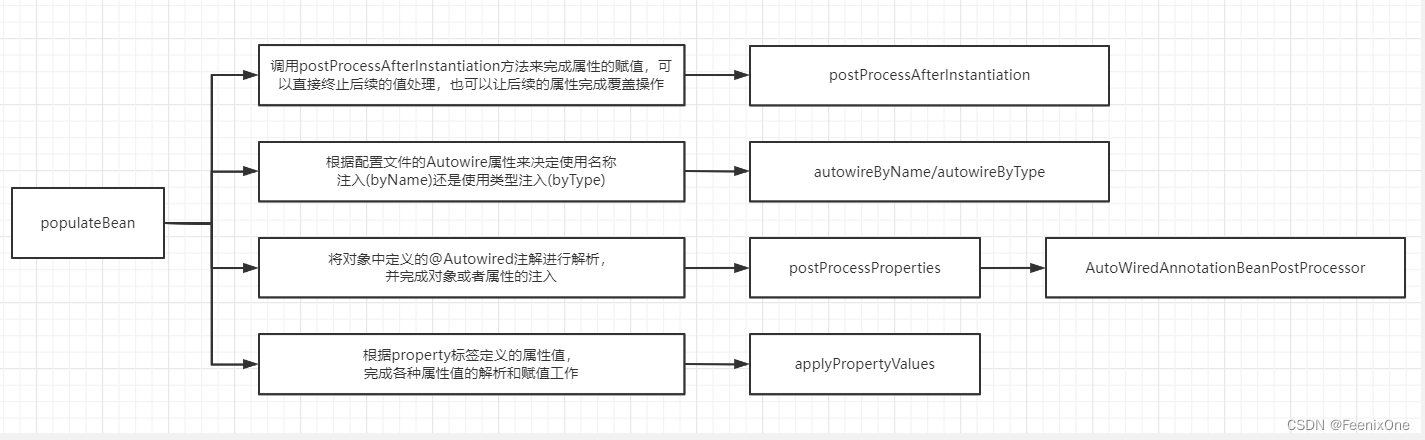
exposedObject = initializeBean(beanName, exposedObject, mbd);
属性填充完以后开始具体的初始化操作,里面的大致流程如下图
代码继续往下走
Object earlySingletonReference = getSingleton(beanName, false);
从缓存中获取具体的对象
earlySingletonReference只有在检测到循环依赖的情况下才不为空
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
因为bean创建后所依赖的bean一定是已经创建的
actualDependentBeans不为空则表示当前bean创建后其依赖
的bean没有全部创建完成,也就是说存在循环依赖问题
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
“Bean with name ‘” + beanName + “‘ has been injected into other beans [” +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
“] in its raw version as part of a circular reference, but has eventually been ” +
“wrapped. This means that said other beans do not use the final version of the ” +
“bean. This is often the result of over-eager type matching – consider using ” +
“‘getBeanNamesForType’ with the ‘allowEagerInit’ flag turned off, for example.”);
}
}
}
registerDisposableBeanIfNecessary(beanName, bean, mbd);
注册bean对象,方便后续在容器销毁的时候销毁对象
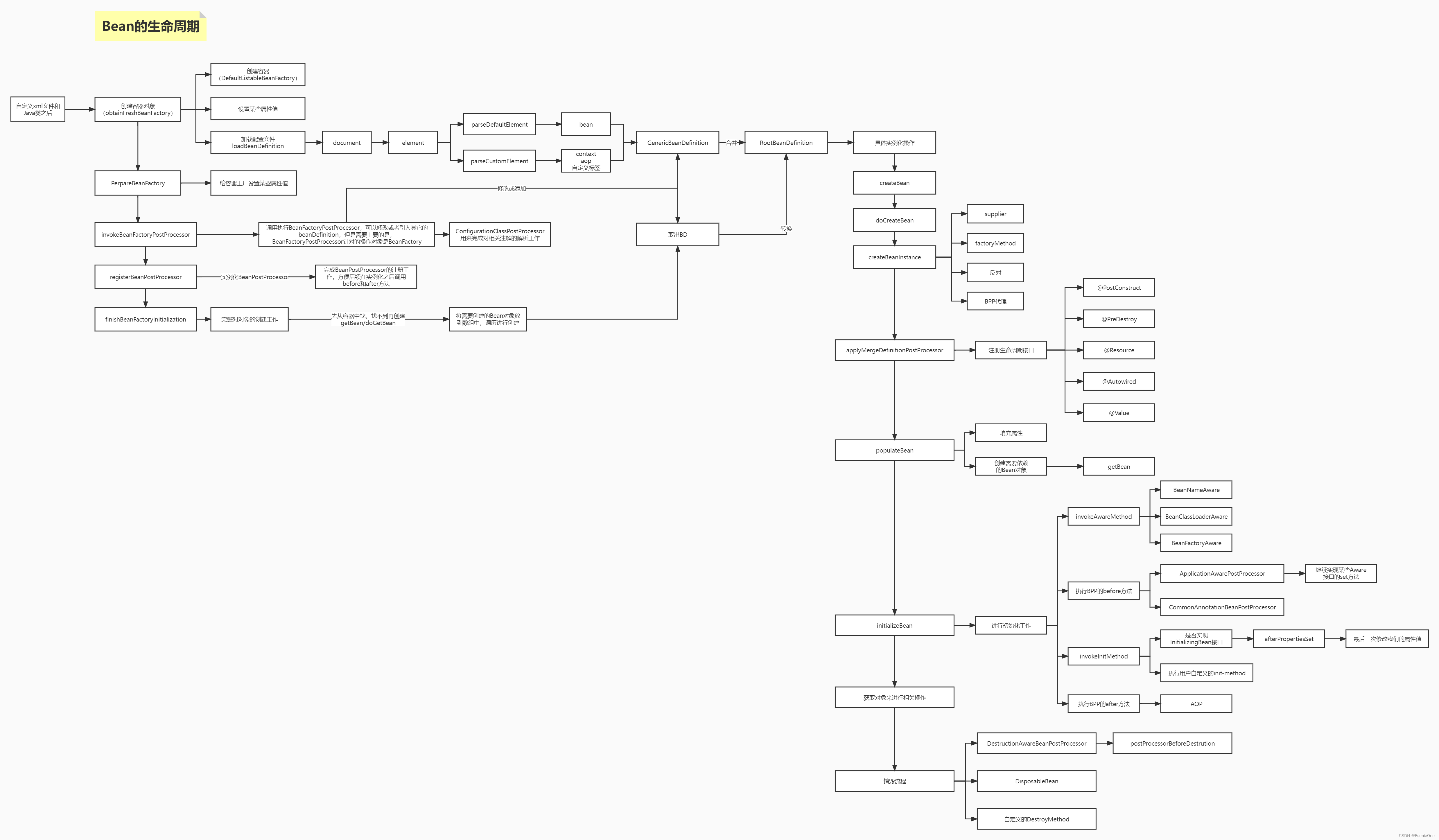
那么至此基本上整个Bean创建的过程就详细的看了一遍,综上可以得出Bean的完整生命周期如图中所示:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/111915.html

