
文章目录
数据分析—数据处理工具pandas(六)
十、分组转换及一般性“拆分-应用-合并”
1.数据分组转换,transform
df = pd.DataFrame({'data1':np.random.rand(5),
'data2':np.random.rand(5),
'key1':list('aabba'),
'key2':['one','two','one','two','one']})
print(df)
# 如果要将df分组后求其平均数,并添加到末尾,有以下两种方法 ---通过分组、合并,得到一个包含均值的Dataframe
# 1. 常规方法
df_mean = df.groupby('key1').mean()
print(df_mean)
print(pd.merge(df, df_mean, how='inner', left_on='key1', right_index=True))
# 2.用transform
a = df.groupby('key1').transform(np.mean).add_prefix('mean_')
print(a)
print(df.join(a, how='inner'))
# 结果:
data1 data2 key1 key2
0 0.164857 0.086483 a one
1 0.635920 0.812287 a two
2 0.658663 0.578853 b one
3 0.100171 0.112047 b two
4 0.480083 0.492155 a one
data1 data2
key1
a 0.426953 0.463642
b 0.379417 0.345450
data1_x data2_x key1 key2 data1_y data2_y
0 0.164857 0.086483 a one 0.426953 0.463642
1 0.635920 0.812287 a two 0.426953 0.463642
4 0.480083 0.492155 a one 0.426953 0.463642
2 0.658663 0.578853 b one 0.379417 0.345450
3 0.100171 0.112047 b two 0.379417 0.345450
mean_data1 mean_data2
0 0.426953 0.463642
1 0.426953 0.463642
2 0.379417 0.345450
3 0.379417 0.345450
4 0.426953 0.463642
data1 data2 key1 key2 mean_data1 mean_data2
0 0.164857 0.086483 a one 0.426953 0.463642
1 0.635920 0.812287 a two 0.426953 0.463642
2 0.658663 0.578853 b one 0.379417 0.345450
3 0.100171 0.112047 b two 0.379417 0.345450
4 0.480083 0.492155 a one 0.426953 0.463642
2.一般化Groupby方法:apply
用apply()方法可以调用自定义函数
df = pd.DataFrame({'data1':np.random.rand(5),
'data2':np.random.rand(5),
'key1':list('aabba'),
'key2':['one','two','one','two','one']})
print(df.groupby('key1').apply(lambda x: x.describe()))
# apply直接运行其中的函数
# 这里为匿名函数,直接描述分组后的统计量
def f_df1(d,n): # d是DataFrame
return(d.sort_index()[:n])
def f_df2(d,k1): # d是DataFrame
return(d[k1])
print(df.groupby('key1').apply(f_df1,2),'\n') # apply调用的函数,该函数的第一个参数必须是DataFrame
print(df.groupby('key1').apply(f_df2,'data2'))
print(type(df.groupby('key1').apply(f_df2,'data2')))
# f_df1函数:返回排序后的前n行数据
# f_df2函数:返回分组后表的k1列,结果为Series,层次化索引
# 直接运行f_df函数
# 参数直接写在后面,也可以为.apply(f_df,n = 2))
# 结果:
data1 data2
key1
a count 3.000000 3.000000
mean 0.693046 0.608697
std 0.257070 0.522231
min 0.396401 0.011814
25% 0.614231 0.422315
50% 0.832060 0.832817
75% 0.841368 0.907138
max 0.850676 0.981459
b count 2.000000 2.000000
mean 0.352287 0.482039
std 0.343271 0.675147
min 0.109558 0.004638
25% 0.230922 0.243339
50% 0.352287 0.482039
75% 0.473651 0.720740
max 0.595016 0.959441
data1 data2 key1 key2
key1
a 0 0.850676 0.832817 a one
1 0.396401 0.011814 a two
b 2 0.109558 0.004638 b one
3 0.595016 0.959441 b two
key1
a 0 0.832817
1 0.011814
4 0.981459
b 2 0.004638
3 0.959441
Name: data2, dtype: float64
<class 'pandas.core.series.Series'>
举一个应用的例子:求一个DataFrame的每列缺失值数量
df = pd.DataFrame({
'key1':np.arange(5),
'key2':[2, 4, 6, np.nan, np.nan]
})
print(df)
print(df.apply(lambda x:np.sum(x.isnull())))
ar = np.array([True, False, True, True])
print(ar)
print(np.sum(ar))
# 结果:
key1 key2
0 0 2.0
1 1 4.0
2 2 6.0
3 3 NaN
4 4 NaN
key1 0
key2 2
dtype: int64
[ True False True True]
3
十一、用pandas读取文件/数据库
1.read_table 与 read_csv
(1)read_table 与 read_csv读取方式即参数都差不多,下面介绍read_table方法
# 介绍几个常用的参数
pd.read_table(
filepath_or_buffer, # 文件路径
sep=False, # 原数据集中各个字段(字段就是列标签)之间的分隔符
delimiter=None, # 原数据集中各个字段(字段就是列标签)之间的分隔符
header='infer', # 赋值行号,做为表头,默认为第一行做为表头
names=None, # 如果原数据没有字段,可以用该参数添加表头 ge:names=['key1', 'key2', 'key3']
index_col=None, # 将原数据集中的某些列作为行标签,也就是把选中的列做为行标签
skiprows=None, # 读取文件时,开头跳过多少行
skipfooter=0, # 读取文件时,末尾跳过多少行
nrows=None, # 读取指定的行的数据
na_values=None, # 指定原数据中哪些值作为缺失值
skip_blank_lines=True, # 是否读取空行
parse_dates=False, # 如果参数为True,则尝试解析数据框(即DataFrame)中的行索引;
# 如果为列表,则解析对应的日期列;
# 如果参数为嵌套列表,则将某些列合并为日期列;
# 如果参数为字典,则解析对应的列(字典中的value),生成新的字段名(字典中的键)
thousands=None, # 指定原数据集中的千分位符号
comment=None, # 指定注释符,在读取数据时,如果碰到首行指定的注释符,则跳过该行
encoding=None # 指定字符编码
)
(2)应用:读取下列文件的信息
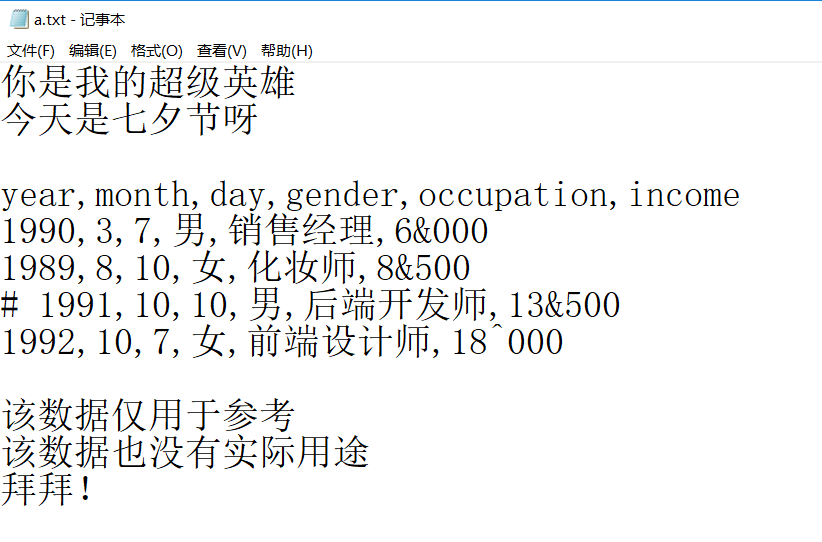
import pandas as pd
import numpy as np
df = pd.read_table(r'D:/小萌萌/a.txt', sep=',', skiprows=2, skipfooter=3, thousands='&', comment='#', parse_dates={'birthday':[0,1,2]})
print(df)
# 结果:
birthday gender occupation income
0 1990-03-07 男 销售经理 6000
1 1989-08-10 女 化妆师 8500
2 1992-10-07 女 前端设计师 18^000
2.read_excel 用来读.xlsx的excel
(1)read_excel()方法的主要参数介绍:
pd.read_excel(
io, # 文件路径
sheet_name=0, # 指定excel中的第几个sgeet,即可以传名称,也可以传下标
header=0, # 默认将第一行作为表头,不需要可以设置为None
names=None, # 自定义设置表头
index_col=None, # 将原数据集中的某些列作为行标签,也就是把选中的列做为行标签
parse_cols=None, #
skiprows=None, # 读取文件时,开头跳过多少行
skipfooter=0, # 读取文件时,末尾跳过多少行
nrows=None, # 读取指定的行的数据
na_values=None, # 指定原数据中哪些值作为缺失值
parse_dates=False,
thousands=None, # 指定原数据集中的千分位符号
comment=None, # 指定注释符,在读取数据时,如果碰到首行指定的注释符,则跳过该行
skip_footer=0,
convert_float=True, # 将所有的数值类型转为浮点型
converters # 通过字典的形式,指定某些列需要转换的形式
)
(2)应用:读取下面excel文件信息
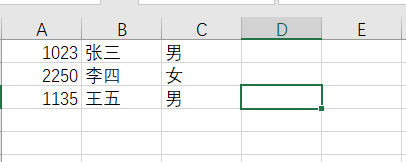
df = pd.read_excel(r'D:/小萌萌/b.xlsx', header=None, names=['id', 'name', 'sex'], converters={0:str}, sheet_name=0)
print(df)
# 结果:
id name sex
0 1023 张三 男
1 2250 李四 女
2 1135 王五 男
3.read_sql—用pandas读取mysql数据库
读取下面student数据库中stu表中的所有数据
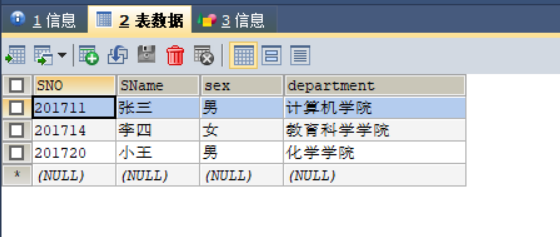
import pymysql,pandas
connect = pymysql.connect(host='127.0.0.1', user='root', passwd='wanghao211', db='student')
sql = 'select * from stu;'
students = pd.read_sql(sql, connect)
print(students)
# 结果:
SNO SName sex department
0 201711 张三 男 计算机学院
1 201714 李四 女 教育科学学院
2 201720 小王 男 化学学院
十二、将数据写入文件中
df = pd.DataFrame({
'key1':np.arange(5),
'key2':np.arange(10, 15)
})
print(df)
df.to_csv(r'D:\\a.csv', index=False, header=False) # 还可以 index='key2' header=['a', 'b'] 等等
# 结果:
key1 key2
0 0 10
1 1 11
2 2 12
3 3 13
4 4 14
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84768.html

