
索引搜索案例
create table T(
-> ID int primary key,
-> k int not null default 0,
-> s varchar(16) not null default '',
-> index k(k))
-> engine = InnoDb;
INSERT INTO T VALUES(100,1,'aa'),(200,2,'bb'),(300,3,'cc'),(400,4,'dd'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
执行以下SQL语句:
select * from T where k between 3 and 5;
这个语句的执行流程:
- 在k索引树找到K=3的行,取得主键ID=300
- 到主键索引树找到ID=300的R3(数据行)
- 到ID索引树取出下一个值k=5,取得主键ID=500
- 到主键索引树找到ID=500的R5(数据行)
- 在k索引树去下一个值k=6,不满足条件,循环结束
回表
从普通索引树上找到主键ID值,再通过主键ID值回到主键索引树进行搜索的过程
覆盖索引
select Id from t where k between 3 and 5;
原理:在K索引树上直接拿到了ID的值,在普通索引上扫描就可以拿到想要得到的值
注意点: 在引擎内部使用索引K读了三条记录,但在Server层,只找引擎拿了两条记录
联合索引(要考虑索引失效)
联合索引的每一个key就是索引字段的一个类似于数组的组合
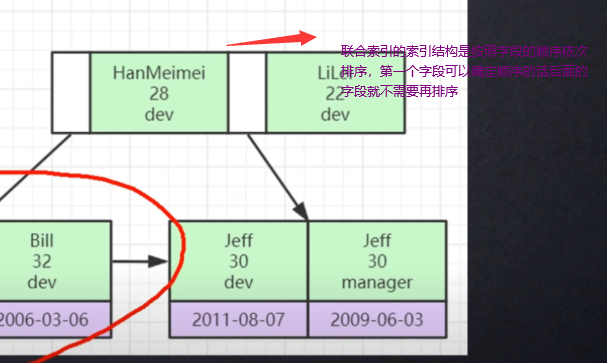
最左前缀原则(联合索引优化)
B+树这种数据结构,可以用索引的最左前缀来定位记录
在建立联合索引时,如何安排索引的字段顺序:
- 通过索引的复用能力(比如说存在字符串),因为有了(a,b)这个联合索引后,一般就不需要单独在A上建立索引了
- 如果通过调整联合索引的顺序,就可以少维护一个索引,那么这个顺序往往是要优先考虑的
索引下推
A: 在mysql5.6之前,只能从满足条件的第一个值开始一个个回表,到主键索引上找出数据行,再对比字段值
B: 而MYSQL5.6引入的索引下推优化,可以在索引遍历过程中,对索引包含的字段先做判断,直接过滤掉不
满足条件的记录,减少回表次数
重建表的命令
alter table T engine = InnoDB
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/202559.html

