
1.索引基础
索引是对数据库表中的一列或多列的值进行排序的一种数据结构,mysql索引的建立对mysql的高效运行说很重要的,索引可以大大提高mysql的检索速度。
简单类比,数据库如同书籍,索引如同书籍目录,假如我们需要从书籍查找与XX相关的内容,我们可以直接从目录中查找,定位到XX内容所在的页面,如果目录中没有xx相关字符或者没有设置目录(索引),那么就只能逐字逐页阅读文本查找,效率很低
2.索引的优缺点
2.1 优点
- 大大减少了服务器需要扫描的数据量,从而大大加快了数据的检索速度
- 可以帮助服务器避免排序
- 可以将随机IO变成顺序IO
- 在使用分组和排序子句进行数据检索时,同样可以现在减少查询中分组和排序的时间
2.2缺点
- 创建和维护索引要耗费时间,这种时间随着时间量的增加而增加
- 索引需要占用物理空间,除了数据表需要占用数据空间之外,每个索引还要占用一定的物理空间,如果建立聚簇索引,占用的空间会更大
- 对表中的数据进行增,删,改的时候,索引也需要动态维护,这就降低了整体的维护速度
- 对于非常小的表,大部分情况下检查的全表扫描更高效
3.创建索引准则
3.1应该创建索引的列
- 经常需要搜索的列上,可以加快搜索的速度
- 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构
- 在经常需要排序(order by)的列上建立索引,因为索引已经排序,占用查询可以利于索引的排序,加快查询时间
- 在经常需要根据范围(<,<=,=,>,>+,between,in)进行搜索的列上建立索引,因为索引已经排好序,其指定的范围是有序的
- 在经常使用where子句中的列上面创建索引,加快条件的判断速度
3.2不应该创建索引的列
- 在查询中很少使用的列
- 只有很少数据值或者重复值多的列(例如性别,因为结果集的数据行占了表中数据行的很大比例,需要在表中搜索的数据行比例很大,增加索引并不能明显加快检索速度)
- 定义为text,image,bit数据类型的列不应该增加索引(这些列要么数据量相当大,要么取值很少)
- 当该列的修改性能要求远高于检索性能时,不应该创建索引。
4.索引结构
常用的有hash,b-tree,b+tree
4.1 hash

-
哈希索引就是采用一定的哈希算法,把键值换成新的哈希值,检索时不需要类似B+树那样从根结点到叶子结点逐级查找,只需要一次哈希算法即可以立刻定位到相应的位置,速度非常快。
-
由于存储的索引不是有序的,不能使用范围查询。
-
innodb里面当某些索引值用得特别频繁的时候,会使用**“自适应哈希索引”**来提高查找效率。
4.2 B-TREE
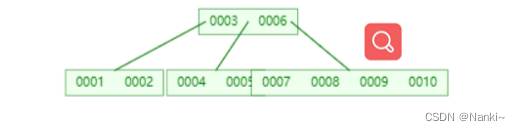
特征:
-
关键字集合分组在整棵树中
-
搜索有可能在非叶子结点结束
-
任何一个关键字出现且只出现在一个结点中
4.3 B+TREE

特征:
- 每一个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的范围遍历
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储数据的数据层
- 不可能在非叶子结点命中
- 所有关键字都出现在叶子结点的链表(稠密索引)中,且链表中的关键字都是有序的
- 更适合文件索引系统;
补充:索引存储在文件系统中
索引是占据物理空间的,在不同的存储引擎中,索引存在的文件也不同。存储引擎是基于表的,以下分别使用MyISAM和InnoDB存储引擎建立两张表。
存储引擎为MyISAM:
*.frm:与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等
*.MYD:MyISAM DATA,用于存储MyISAM表的数据
*.MYI:MyISAM INDEX,用于存储MyISAM表的索引相关信息
存储引擎为InnoDB:
*.frm:与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等
*.ibd:InnoDB DATA,表数据和索引的文件。该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据
5.索引分类
5.1 逻辑分类
有多种逻辑划分的方式,比如按功能划分,按组成索引的列数划分等
**5.1.1.按功能划分
- 主键索引:一张表只能有一个主键索引,不允许重复、不允许为 NULL;
alter table tablename add primary key(column_list);
-
唯一索引:数据列不允许重复,允许为 NULL 值,一张表可有多个唯一索引,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
create unique index indexName on 'tableName'() 或者 alter table tableName add unique (colum_list) -
普通索引:一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入;
create index indexName on 'tableName'() 或者 alter table tableName add index(colum_list) -
全文索引:它查找的是文本中的关键词,主要用于全文检索。(篇幅较长,下文有独立主题说明)
5.1.2 按列数划分
- 单例索引:一个索引只包含一个列,一个表可以有多个单例索引。
- 组合索引:一个组合索引包含两个或两个以上的列。查询的时候遵循 mysql 组合索引的 “最左前缀”原则,即使用 where 时条件要按照建立索引的时候字段的排列方式放置索引才会生效。
5.2 物理分类
分为聚簇索引和非聚簇索引(有时也称辅助索引或二级索引)
聚簇是为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚簇码)上具有相同值的元组集中存放在连续的物理块。
- 聚簇索引(clustered index)不是单独的一种索引类型,而是一种数据存储方式。这种存储方式是依靠B+树来实现的,根据表的主键构造一棵B+树且B+树叶子节点存放的都是表的行记录数据时,方可称该主键索引为聚簇索引。聚簇索引也可理解为将数据存储与索引放到了一块,找到索引也就找到了数据。
-非聚簇索引:数据和索引是分开的,B+树叶子节点存放的不是数据表的行记录。
虽然InnoDB和MyISAM存储引擎都默认使用B+树结构存储索引,但是只有InnoDB的主键索引才是聚簇索引,InnoDB中的辅助索引以及MyISAM使用的都是非聚簇索引。每张表最多只能拥有一个聚簇索引。
拓展:聚簇索引优缺点
优点:
- 数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
- 聚簇索引对于主键的排序查找和范围查找速度非常快
缺点:
-
插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键(主键列不要选没有意义的自增列,选经常查询的条件列才好,不然无法体现其主键索引性能)
-
更新主键的代价很高,因为将会导致被更新的行移动**。因此,对于InnoDB表,我们一般定义主键为不可更新。
-
二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/189661.html

