
数据库(DB = DataBase)
数据库是什么?
数据库就是存储管理数据的仓库。那我们之前学过的文件的方式也能存储数据,那为什么不用这些文件存储呢?例如properties,txt
因为这个格式不方便我们去操作与管理数据库
类似于我们生活中的excel,可以帮助我们很简单的去操作和管理数据库,可以帮助我们去做更多的操作,例如求和,求数量等等
数据库的分类
关系型数据库


两个或者多个表之间可以存在着一定的关系,这种数据库就叫做关系型数据库
关系型数据库不仅可以存放数据,还可以表示数据与数据之间的关系
- Oracle ,这个数据库是目前使用最广泛的数据库,是国内的政府机关以及金融机构使用的最多的一个数据库
- Mysql,现在这个数据库也有社区版和收费版,现在也是属于Oracle旗下的产品,是国内中小企业使用的最多的一个数据库
- Sql Server 是微软开发的一个数据库
- MariaDB,也是由Mysql的作者来开发的一个开源数据库,当然目前在国内使用的不多
- DB2,这个是IBM开发出来的产品
- SQLite,是一个微型的数据库,一般用在手机的操作系统中,用来存储手机中的通讯录、短信之类的内容
关系型数据库存储数据在磁盘上
非关系型数据库(缓存中间件)
NoSQL:Not only sql,作为关系型数据库的一个良好的补充,存放数据的位置:内存中
-
Redis
-
Memcached
-
Hbase(大数据领域中的一个数据库)
-
MongoDB
如何去操作关系型数据库
牵涉到我们的sql语法规范
SQL标准委员会制定一套标准,帮助我们去操作管理关系型数据库,这套标准就是我们的SQL
SQL就像我们的普通话一样,每个地方还有方言。那我们的Mysql,Oracle也有方言,他们自己也有一点与众不同的地方,这些是我们以后接触到了不同的数据库需要学习的。
数据库的结构

数据库的安装
- 安装Mysql
安装可视化工具:如Navicat
需要注意的是,最好你的电脑的用户名,不要是中文。
安装完了以后,还需要配置环境变量。
-
安装可视化工具
Navicat
数据库的使用(SQL)
如何使用数据库,也就是去学习sql语法
注意:SQL是不区分大小写的,但是并不是代表我们的整个数据库不区分大小写,只是表示我们SQL里面的关键字不区分大小写
数据库的操作
新增数据库
# 创建数据库
create database db_name;
# 创建数据库的时候,可以指定字符集
create database sql2 character set utf8;
# 创建数据库的时候,可以指定校对规则
# 什么是校对规则呢?简单点来说,就是Mysql里面的数据需不需要区分大小写
# 校对规则什么时候有用呢?在我们对数据进行排序的时候很有用
#utf8_bin 区分大小写
create database sql3 character set utf8 collate utf8_bin
# utf8_general_ci 不区分大小写
create database sql3 character set utf8 collate utf8_general_ci
说明:有些字符集不支持中文,典型的Latin1字符集就不支持
假如不支持中文,在插入中文数据的时候,就会报错
如何去解决呢?修改数据库对应的字符集就可以了
修改数据库
alter database sql4 character set utf8 collate utf8_bin;
查看数据库
# 查看当前Mysql服务中有哪些数据库
show databases;
# 查看数据库的建库语句
show create database db_name;

删除数据库
drop database if exists db_name
表的操作
新增表
# 新增表
# 选择数据库
use sql2;
create table user(
id int,
name varchar(20)
);
# 设计到钱之类的数据的时候,我们需要使用decimal这种数据结构,在Java中对应了BigDecimal这种数据结构
# 创建表
create table table1(
t1 tinyint,
t2 int
);
# 新增数据
insert into table1 values (10,100);
# 这个数据在插入的时候,会报错,因为t1数据的长度太长了,插入不进去
insert into table1 values (1000,100);
- 浮点类型
create table flaot_test (
t1 float(4,2),
t2 double(6,2),
t3 decimal(4,2)
);
# 我们发现呢,flaot 和double是固定长度,会进行四舍五入,decimal是可变长度
INSERT INTO flaot_test values (10.888,10000.22,100.223);
INSERT INTO flaot_test values (10.888,1000.22,100.223);
INSERT INTO flaot_test values (10.888,1000.22,10.223);
INSERT INTO flaot_test values (10.888,1000.22,100.223);
select * from flaot_test;
-
时间类型
# 时间相关 use sql2; create table time_test ( t1 year, t2 time, t3 date, t4 datetime, t5 TIMESTAMP ); insert into time_test values(2021,'14:35:56','2021-03-05','2021-03-05 14:35:56','2021-03-05 14:35:56'); select * from time_test; # now() 函数,表示当前的时间 insert into time_test values (now(),now(),now(),now(),now()); set time_zone='+10:00'; # 修改了时区以后,我们发现datetime没有变化,但是呢timestamp变了,增加了两个小时 # 有什么作用呢?在我们以后开发一些国际化业务的时候有用,工作中TIMESTAMP更加常用 -
字符类型
# 字符类型 create table string_test( name char(2), gender varchar(20) ); insert into string_test values ("a","female"); # 枚举类型 只能取一个 create table t_enum ( name enum('bob','ali','tony') ); insert into t_enum values ('bob'); insert into t_enum values ('jack'); select * from t_enum; # 集合类型,可以取一个或者多个 create table t_set ( name set('bob','ali','jack') ); insert into t_set values ('bob'); insert into t_set values ('bob,ali'); insert into t_set values ('bob,tony'); select * from t_set; -
二进制类型(一般不用)
练习:创建一个员工表

# 创建一个员工表
create table employee(
id int(11),
name varchar(20),
gender varchar(10),
birthday date,
entry_time date,
job varchar(10),
salary decimal(10,2),
resume text
);
# 插入两条数据
insert into employee values (1001,"888","male","1990-10-20","2018-11-20","打工人",1000,"很饿");
insert into employee values (1002,"666","male","1985-10-20","2015-11-20","boss",1000,"很帅");
select * from employee;
修改表
# 修改表
create table user (
id int,
name varchar(20),
gender varchar(10)
)
desc user;
# 增加年龄字段
alter table user add age int;
# 修改字段名字和长度
alter table user change gender sex varchar(5);
# 修改长度
alter table user modify sex varchar(10);
# 删除一列
alter table user drop age;
# 修改表名
rename table user to user2;
# 修改字符集
alter table user2 character set utf8mb4 collate utf8mb4_general_ci;
删除表
drop table user2;
# 查看所有的表
show tables;
查看表
# 查看表里面有哪些字段
desc employee;
describe employee;
# 查看建表的SQL语句
show create table employee;
补充 :
show create table table1;
# 因为有些数据可能和我们的关键字冲突,所以我们需要有 ` 这个符号
create table `table` (
id int,
`create` varchar(20)
)

数据的操作
这个是我们学习的重点,也是以后工作中最常用的一块内容
增
# 数据的操作
create table user (
id int,
name varchar(20),
age int,
weight int
);
insert into user values (1001,"8",35,210);
insert into user values (1002,"6",18,100),(1003,"9",30,200);
select * from user;
# 设定字段的规则
# 主键代表这个字段是唯一的,不可以重复,还有关于查询效率的问题
#auto_increment这个字段表示主键是自增的,如果我们插入的时候值为null,那么他就会自动生成一个自增的值
# NOT NULL 表示这个字段插入的时候不能为空
create table user2(
id int PRIMARY KEY auto_increment,
name varchar(20) NOT nuLL
);
insert into user2 values (null,"bob");
insert into user2 values (null,"tony");
insert into user2 values (null,"alice");
# 主键不能重复
insert into user2 values (1,"jack");
select * from user2;
删
# 删除
delete from employee where id = 1001;
# 清空表中数据的一个命令
truncate employee;
# where 字段后面有很多匹配条件,看查询中
改
# 这种方式会修改表里面所有的数据
update employee set salary = 99;
# 所以这个时候我们需要加上一些限制条件 where
# 通过名称是‘子’的去匹配
update employee set salary = 50 where name = '子';
# 通过id是1002的去匹配
update employee set salary = 40 where id = 1002;
# 通过性别去匹配,假如需要把女性的工资加上10
update employee set salary = salary + 10 where gender = 'female';
查
# 1. 查询所有的信息 , *代表通配
select * from t_students;
# 2. 查询指定列的信息 [name] 就是指定列,可以是多列,以 , 隔开
select name from t_students;
# 3. 条件匹配 and 和 or 关键字
# 查询语文,数学,外语总成绩大于180的同学
select * from t_students where chinese + english + math > 180;
# 查询数学成绩在80~90之间的学生的姓名 and关键字表示并列条件
select name from t_students where math >= 80 and math <= 90;
# 查询各科都及格的同学的信息
select * from t_students where chinese>=60 and english >= 60 and math >= 60;
# 查询一班和二班的同学的信息
select * from t_students where class = '一班' or class = '二班';
# 4. is null
select * from t_students where math is null;
# 5. is not null
select * from t_students where math is not null;
# 6. between and
select * from t_students where math between 80 and 90;
# 表示在一个列表内 查询一班和二班的学生的信息(一班,二班)
select * from t_students where class in ("一班","二班");
# 7. not in 表示筛选结果不在列表内
select * from t_students where class not in ("一班","二班");
# 8. like
# 模糊查询 查询姓黄的用户的信息 %: 表示通配 _:表示占位
select * from t_students where name like "%黄";
select * from t_students where name like "黄__";
条件匹配的关键字: where , and , or, is null, not is null, in , not in, between ··· and ··· , like
聚合函数:
count:统计数量,计数
sum:求和
avg:求平均值
max:求最大值
min:求最小值
# 计数
select count(*) from t_students ;
select count(name) from t_students;
select count(id) from t_students;
select count(1) from t_students;
select count(*) from t_students where name like "黄__";
# 求和 sum
select sum(chinese) from t_students;
select sum(chinese),sum(english),sum(math) from t_students
# 求平均值
select avg(chinese) from t_students;
# 不能这么写
select avg(math) from t_students where math >= 60;
# 求最大值、最小值
select max(math) from t_students;
select min(math) from t_students;
过滤、排序、限制结果
# 过滤相同的条件
select distinct(class) from t_students;
#限制结果
select * from t_students limit 0,2;
# 假如页面为pageIndex, 页面大小为pigeSize ,要查询当前页的数据
# 分页查询的方法(需要大家记住并理解)
select * from t_students limit (pageIndex -1) *pigeSize ,pageSize;
# 排序 order by asc 表示升序,desc 表示降序
select * from t_students order by math asc;
select * from t_students order by math desc;
# 分组 GROUP BY
select class from t_students GROUP BY class;
select GROUP_CONCAT(name),class,GROUP_CONCAT(chinese),avg(chinese) from t_students GROUP BY class;
- 排序
# 对单列排序
# 如:对数学单科成绩从低到高进行排序。
select * from t_students order by english desc;
#对多列排序
# 如:对语数外三科成绩进行排序。
select * from t_students order by (chinese + english + math) desc;
#指定排序方向(ASC, DESC)
#如:对语文降序,数学升序,外语降序排序。
# 这个多条件排序的原则是:优先满足第一个条件,然后加入第一个条件一样的话再去满足第二个条件,以此类推
select * from t_students order by chinese desc , math asc , english desc ;
#练习:
#查询总成绩前三名同学的信息。
select * from t_students order by (chinese + english + math) desc LIMIT 3;
select (chinese+english+math) as sum, name,id,class from t_students order by sum desc LIMIT 3;
- 别名
# 别名 给列值起别名
select id as uid ,name as username ,class as className from t_students;
# 给表起别名 在我们后续使用多表查询的时候,很有作用
select * from t_students as s;
select * from t_students as s ,name_table as c where t_students.id;
- 分组
# 如:查询人数大于2的班级
# 首先,我们应该对class字段进行分组
select class,count(name) as num,GROUP_CONCAT(name) from t_students GROUP BY class having num > 1;
SQL执行的顺序
(5) SELECT column_name, ...
(1) FROM table_name, ...
(2) [WHERE ...]
(3) [GROUP BY ...]
(4) [HAVING ...]
(6) [ORDER BY ...];
数据完整性
实体完整性
实体完整性其实就是指的主键。
域完整性
- not null
- unique
# unique 唯一
create table stu (
id int primary KEY auto_increment,
name varchar(20),
gender varchar(10),
no int unique comment "学号id"
);
drop table stu;
desc stu;
insert into stu values (null,"武二哥","male",9527);
select * from stu;
insert into stu values (null,"武大哥","male",9527);
insert into stu values (null,"武大哥","male",null);
update stu set id = null where id = 3;
# unique 和主键的区别:主键不可以为null, unique可以为null
insert into stu values (null,"嫂子","female",9999);
insert into stu values (null,"妹妹","female",8888);
参照完整性
外键

create table province (
id int PRIMARY key,
name varchar(20) not null
);
insert into province values (1,"湖北");
insert into province values (2,"安徽");
insert into province values (3,"江苏");
insert into province values (4,"河南");
select * from province;
drop table if exists city;
select * from city;
create table city (
id int primary key,
name varchar(20) not null,
province_id int,
constraint province_city_FK foreign key(province_id) references province(id)
);
insert into city values (1,"武汉",5);
# 当我们插入外键的值的时候,那么他就会去关联外键的表里面去找有没有该值,假如有,就插入,假如没有,就不让插入,报错
insert into city values (1,"南京",3);
insert into city values (2,"合肥",2);
insert into city values (3,"武汉",1);
insert into city values (4,"郑州",4);
insert into city values (5,"黄冈",1);
insert into city values (6,"长沙",10);
# 当我们删除外键的值的时候,也会有问题
delete from city where id = 1;
delete from province where id = 1;
delete from city where province_id = 1;
# 外键好吗?当我们要求数据具有参照完整性的时候,性能会很差
# 所以在工作中,一般不使用外键(甚至有的公司要求,不能使用外键)
多表设计
一对一
这个很简单,例如学生对应学号,订单对应订单详情,商品对应商品详情,这种可以把它们合并,放到一个表里面去
但是有的时候需要进行拆分,最典型的例子:商品对应库存,一般我们去做的时候,都会把商品表和库存表拆分开
为什么会拆分开呢?
主要是从性能上去考虑的(查询和修改)
一对多
这个也不难,关系维护在多的一方
有哪些模型是一对多的关系呢?
班级和学生,订单和商品,省份和城市,分类和商品
多对多
学生和课程、用户和商品
数据库设计三大范式
第一范式:每列保持原子性
第二范式 记录唯一性
我们在设计数据库的表的时候,应该尽量的保证每一个表只讲述一件事情,应该尽量的减少数据的冗余(减少数据的重复出现)
第三范式
是指数据不要冗余
但是我们在设计表的时候,经常要进行反范式化操作;
是因为可以给我们带来查询性能上的巨大提升
连接查询
笛卡尔积

-
交叉连接
select * from tableA cross join tableB;
结果是笛卡尔积
实际意义不大,在工作中用的很少
-
内连接,适用于我们以后工作中80%的场景

# 连接查询、显示
select * from customer inner join orders on orders.customer_id = customer.id where customer.name = '郭靖';
select o.*, c.name from customer as c inner join orders as o on o.customer_id = c.id where c.name = '郭靖';
# 隐式内连接
select * from customer as c,orders as o where c.id = o.customer_id and c.name = '郭靖';
-
外连接
-
左外连接
-
# 左外连接 select * from customer as c left outer join orders as o on c.id = o.customer_id;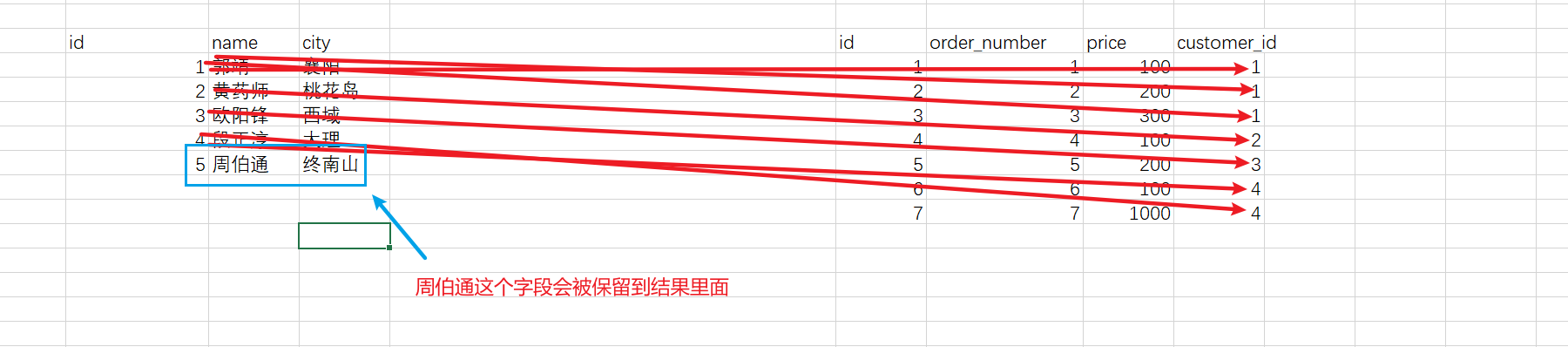
-
右外连接
# 左外连接 select * from customer as c left join orders as o on c.id = o.customer_id; insert into customer values (6,"杨过","大雕"); select * from customer; # 右外连接 select * from orders as o right JOIN customer as c on c.id = o.customer_id;
-
-
子查询
# 查出所有郭靖的订单 # 子查询 select * from orders where customer_id = (select id from customer where name = '郭靖'); # 查询出所有的姓郭的人的订单 select * from customer where name like '郭%'; select * from orders where customer_id in (1,2); select * from orders where customer_id in (select id from customer where name like '郭%'); -
联合查询
select * from t_students where chinese > 80 union select * from t_students where class = '二班';联合查询就是求两个集合的并集,他会帮助我们自动去除重复的数据。
数据的备份与恢复
# 不要使用powershell
# 数据备份
mysqldump -u root -p database_name sql.sql
# 数据恢复
source [sql文件全路径]
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/181126.html

