
HTTP介绍
-
HTTP:Hyper Text Transfer Protocol。超文本传输协议。
-
HTML:Hyper Text Markup Language. 超文本标记语言。
html谁发明的,Tim bernes lee。
HTML最初是为了科研、阅读最新的研究成果而被发明。
90年代如何取了解其他人的研究成果,期刊杂志,肯定不是电子版的。局域网互联还是可以的。论文、研究成果写出来。格式要求的 html。
http创立之初就是为了传输html的。
超文本:超越了普通的文本,不仅仅只有文本,还可以有音频、视频、图像等
传输:通讯的双方
协议:指的是通讯双方遵循的一个格式。
比如双方传输学生的信息
tom年龄是23岁,他来自于美国纽约,学习的专业方向是物理学
kate年龄是25岁,。。。。。。。。。。。。。。。。。。。。
但是如果我按照下面这种格式来传输数据
tom 23 美国纽约 物理学
kate 25 美国芝加哥 计算机学
网络模型:
HTTP是一个网络协议。底层相关的实现。
HTTP请求报文
请求行
分为三个部分组成,请求方法、请求资源、请求版本协议
请求方法:
GET、POST
最主要的区别在于语义上的区别。
Get:获取资源。获取某个资源
Post:提交资源。登录
get请求方式和post请求方式他们之间的区别不是通过看请
比如最常见的text/html;image/png;image/jpg;
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip
Accept-Language: 浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。 可以在浏览器中进行设置。
Host:初始URL中的主机和端口
Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面 (防盗链)
如果一个请求是直接访问http://localhost/app/2.html
还有另外一个请求时通过先访问http://localhost/app/1.html,接下来里面有一个form表单跳转http://localhost/app/2.html,报文上面有没有区别呢?
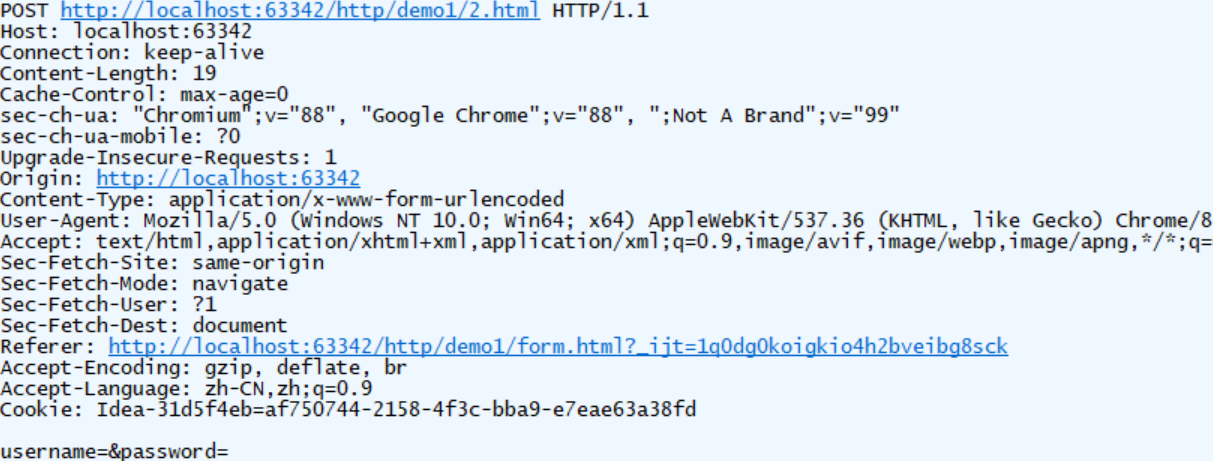

可以看到如上的差异,referer请求头。
有什么实际用处呢?
qq空间里面的图片,如果空间设置了权限,那么有些图片再外部页面打不开。
Content-Type:内容类型
If-Modified-Since: Wed, 02 Feb 2011 12:04:56 GMT 服务器利用这个头与服务器的文件进行比对,如果一致,则告诉浏览器从缓存中直接读取文件。
User-Agent:浏览器类型.
Content-Length:表示请求消息正文的长度
Connection:表示是否需要持久连接。如果服务器看到这里的值为“Keep -Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接
Cookie:这是最重要的请求头信息之一
Date:Date: Mon, 22 Aug 2011 01:55:39 GMT请求时间GMT
HTTP响应报文
响应行
记住常用的状态码即可
200、301、302、307、304、404、500
响应头
HTTPS
Secure。安全的。
HTTPS = http + secure
1.通讯过程完全是透明的,不加密
2.不验证通讯另一方的身份(卖茶叶的)
3.还没有完整性的校验,比如请求报文或者响应报文被修改,也不会发现。
针对上面出现这三点,HTTPS分别有一个对策
HTTPS采用加密算法来加密
加密算法:
对称加密:加密和解密使用的是同一把密钥。加密解密速度比较快
非对称加密:公钥进行加密,但是加密之后只可以用私钥来进行解密。速度比较慢
实际上,在真实的HTTPS通讯过程中,使用的是混合加密。
HTTPS会验证通讯方的身份信息
—- 采用的是证书。
HTTPS会进行完整性校验
JavaWeb服务器
服务器,两种说法;硬件,性能比较好的一台计算机;软件,服务器软件。
服务器软件,作用是什么?
将本地硬盘上面的文件共享给网络上面的其他用户。
服务器的本质,用户输入一个网络路径,服务器需要解析出对应该文件在硬盘上面的一个硬盘路径,然后呢根据不同的结果做出对应的响应,比如文件存在,那么将文件内容响应给客户端;如果文件不存在,那么将返回一个404的HTTP响应状态码。
http://localhost/app/1.html
http://localhost/app/2.html
实现一个最简易的静态Web资源服务器
服务器,监听着某一端口号;
监听客户端的请求———HTTP请求
识别出客户端的请求资源信息
根据资源存在与否做出对应的响应(如果请求的资源存在,那么应当将文件的内容返回给客户端,如果文件不存在,那么应当返回一个404)——HTTP响应
将客户端发送过来的网络路径,解析转换成本地的硬盘路径。
在硬盘上面去找某个文件,应该使用哪一套API?
File、FileInputStream、FileOutputStream
大家比较熟悉的IO流的方式应该FileInputStream和FileOutputStream,但是呢,如果是其他类型的xxxxInputStream或者其他类型的xxxOutputStream,那么使用方式其实和之前学习的是一样的。

import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
public class WebServer {
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(8090);
//持续去监听着8090端口号
while (true){
//这里面的client其实就是连接过来的每一个客户端
//这一步是阻塞的,如果没有客户端连接过来,会一致卡在这个地方,程序无法继续往下执行
Socket client = serverSocket.accept();
new Thread(new Runnable() {
@Override
public void run() {
//就是对于请求信息的封装,客户端发送过来的信息都在这里面
try {
//对于响应信息的封装,只需要往这里面写入数据,最终就可以把数据返回给客户端
OutputStream outputStream = client.getOutputStream();
//如何把inputStream里面的内容解析成为一个字符串呢?
//根据面向对象的思想,将请求响应设置为两个对象 request、response
Request request = new Request(client);
//请求的资源,请求意图 /1.html
String requestURI = request.getRequestURI();
//看这个文件是否存在,如果存在,则返回给客户端;如果不存在,则返回404 HTTP响应状态码
//这一步的目的是为了将请求资源前面的/去掉,如果有/,那么file找不到的
File file = new File(requestURI.substring(1));
StringBuffer buffer = new StringBuffer();
if(file.exists() && file.isFile()){
//如何拿到文件的输入流
FileInputStream inputStream = new FileInputStream(file);
byte[] bytes = new byte[1024];
int length = 0;
buffer.append("HTTP/1.1 200 OK\r\n");
buffer.append("Content-Type:text/html;charset=utf-8\r\n");
buffer.append("\r\n");
outputStream.write(buffer.toString().getBytes("utf-8"));
while ((length = inputStream.read(bytes)) != -1){
outputStream.write(bytes, 0, length);
}
}else {
buffer.append("HTTP/1.1 404 Not Found\r\n");
buffer.append("Content-Type:text/html;charset=utf-8\r\n");
buffer.append("\r\n");
buffer.append("<div style='color:red'>File Not Found</div>");
outputStream.write(buffer.toString().getBytes("utf-8"));
}
outputStream.flush();
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
import java.io.IOException;
import java.io.InputStream;
import java.net.Socket;
import java.util.HashMap;
import java.util.Map;
public class Request {
private Socket client;
private String requestString;
private String method;
private String requestURI;
private String protocol;
private Map<String, String> requestHeaders;
public Request(Socket client) {
this.client = client;
this.requestHeaders = new HashMap<>();
parseRequest();
if(!StringUtils.isEmpty(requestString)){
//解析HTTP请求报文
parseRequestLine();
parseRequestHeaders();
}
}
private void parseRequestHeaders() {
int begin = requestString.indexOf("\r\n");
int end = requestString.indexOf("\r\n\r\n");
String substring = requestString.substring(begin + 2, end);
String[] parts = substring.split("\r\n");
for (String part : parts) {
int i = part.indexOf(":");
String key = part.substring(0, i);
String value = part.substring(i + 1);
this.requestHeaders.put(key.trim(), value.trim());
}
}
//先解析HTTP请求报文的请求行 每一行结束都有一个\r\n
//空行这块本身也是一个\r\n
//利用\r\n可以把请求行分割出来
//利用\r\n和\r\n\r\n可以把请求头部分分割出来
private void parseRequestLine() {
int i = requestString.indexOf("\r\n");
String requestLine = requestString.substring(0, i);
//利用空格来进行分割
String[] parts = requestLine.split(" ");
this.method = parts[0];
this.requestURI = parts[1];
this.protocol = parts[2];
//还需要考虑到一点,如果在地址栏里面附带了请求参数呢?
int i1 = requestURI.indexOf("?");
if(i1 != -1){
this.requestURI = requestURI.substring(0, i1);
}
}
//处理请求信息
private void parseRequest() {
InputStream inputStream = null;
try {
inputStream = client.getInputStream();
byte[] bytes = new byte[1024];
int read = inputStream.read(bytes);
if(read != -1){
this.requestString = new String(bytes, 0, read);
System.out.println(requestString);
}
} catch (IOException e) {
e.printStackTrace();
}
}
public String getMethod() {
return method;
}
public String getRequestURI() {
return requestURI;
}
public String getProtocol() {
return protocol;
}
public String getHeader(String headerName){
return requestHeaders.get(headerName);
}
}
//工具类:这些代码在很多地方可能需要频繁使用到
public class StringUtils {
public static boolean isEmpty(String content){
if(content == null || content.isEmpty()){
return true;
}
return false;
}
}
Tomcat
安装:
不需要进行安装,直接解压缩即可。放置于某个盘符根目录(建议),不建议放置于目录层级很深、或者由中文的目录下。
启动:
windows平台:直接运行startup.bat文件
Mac平台:需要在bin目录下唤出shell,执行./startup.sh
还有另外一种方式:
先到达tomcat的bin目录下面,唤出cmd,然后执行startup
如果启动过程一闪而过,那么绝大多数情况下,原因在于没有正确配置JAVA_HOME
停止:
windows平台:点击关闭。运行shutdown.bat
Mac平台:需要在bin目录下唤出shell,执行./shutdown.sh
先到达tomcat的bin目录下面,唤出cmd,然后执行shutdown
tomcat发布应用资源 (非常重要)
tomcat作为一个服务器,最为核心的功能就是发布资源供外界来访问。发布资源的方式可以通过如下两种
tomcat部署资源必须以一个一个应用为最小单位,如果你希望部署一个资源文件,那么必须要将资源文件放置于某个应用呢。
什么叫一个应用呢?
tomcat里面的一个最小单位,应用里面可以存放很多的资源文件
如何去新建一个应用呢?
操作非常简单,只需要在webapps目录下新建一个目录,那么该目录就是一个应用,同时呢,目录的名称就是应用的名称。
一种是直接部署
直接部署,顾名思义就是直接将你所需要部署的资源放置于tomcat里面,其实也就是webapps目录下。
如何去访问呢?
web服务器的本质,其实就是将本地硬盘上面的某个文件的绝对路径给拿到。
当你输入http://localhost:8080,相当于此时tomcat已经定位到了webapps目录下,那么接下来,如何访问某个静态资源,只需要去写出该静态资源和webapps的相对路径关系即可。
部署资源文件可以通过部署这种开放式目录的形式,也可以部署一个war包(类似于windows里面的压缩包,tomcat回自动将其解压缩为一个开放式目录)
另外一种是虚拟映射
虚拟映射的概念:
正常情况下,如果我们需要部署一个资源文件,我们是将该文件放置于tomcat的webapps目录下的,但是如果希望将资源文件放置于tomcat目录之外的其他地方,也可以访问到该资源文件,那么就需要通过虚拟映射的方式来部署,将该文件虚拟映射到webapps目录下。
虚拟映射实现方式由如下两种:
1.在conf/Catalina/localhost目录下去配置 ,新增一个xml文件
比如设置了一个app2.xml 里面 < Context docBase=“D:/app”/>
在tomcat里面,最小的功能单位必须要求是应用,所以虚拟映射也需要有一个应用,tomcat会在启动的时候读取该xml文件,然后形成一个应用,应用的名称就是xml文件的名称。
当输入http://localhost:8080/app2,实际上此时已经定位到了硬盘的绝对路径为D:/app目录,那么接下来如何去访问到某一个静态资源文件,只需要写出相对路径关系。
2.conf/server.xml文件中去配置
也是需要去配置一个Context节点,不过此时需要在server.xml文件中去配置
需要在Host节点下配置一个Context节点
< Context path=”” docBase=””/>
其中docBase很好理解,但是path为什么要设置呢?
因为在tomcat里面必须要有一个应用,应用必须要有应用名,所以我们此时用path属性来当作它的应用名。
tomcat的组成结构以及请求执行流程
Server、Service、Connector、Engine、Host、Context
还是以访问Http://localhost:8080/app/1.html为例,阐述一下完整的请求执行流程
1.浏览器内输入对应的网址,首先进行域名解析,tcp三次握手,浏览器会帮助我们去生成一个HTTP请求报文
2.HTTP请求报文到达目标服务器之后,被监听着8080端口号的Connector接收到,将请求报文解析成为request对象,同时还会生成一个response对象
3.将这两个对象传给engine
4.engine的职责也比较简单,如果由很多个host,那么就挑选一个合适的host;如果没有,则交给缺省的host
5.host的职责就是去挑选一个合适的Context,然后将请求、响应对象进行进一步下发
(tomcat完全可以生成一个应用名—–应用的映射关系,根据/app找到对应的应用,找到应用以后就可以找到docBase)
6.Context的职责就是根据应用的docBase + 最终的请求的i资源,然后拼成一个绝对路径, new File.exitsts表示该文件存在,可不可以将文件的流写入到response中,如果不存在,可以往response里面写入一个不存在的状态码
7.Connector读取response里面的内容,按照HTTP响应报文的要求,重新组装生成响应报文,发送出去
tomcat设置
1.设置端口号
默认情况下,tomcat下载完之后,默认监听8080端口号,如果希望修改端口号,那么去修改对应的Connector。有一个需要特别说明的,前1024端口号建议不要去设置,因为很有可能操作系统会用,但是有一个例外。这个就是80端口号,80端口号实际上时http协议的默认端口号,如果你使用http协议,并且没有写端口号,哪实际上使用的就是80端口号,比如http://localhost/app/1.html.没有端口号不是说没有使用端口号,而是使用的当前协议的默认端口号,当前使用的时http协议,所以其实端口号时80
2.设置缺省应用
ROOT其实就是缺省应用,http://localhost/app7/1.html,此时你的tomcat中并没有去配置一个/app7的应用,这个时候这个请求你打算怎么办?所以此时它会交给缺省ROOT应用来处理。保底。访问ROOT应用下面的资源时,直接把应用名去掉即可。
http://localhost/index.jsp
3.设置默认访问页面
如果请求中没有指明具体的访问页面,那实际上访问的时默认页面,缺省页面。这个时在tomcat的web.xml中进行配置的
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
实际上如果请求的url并没有指明访问的具体资源,那么就会在当前应用下去寻找这些welcome-file,如果找到,则加载,如果找不到则返回404.
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/181123.html

