
文章目录
1. saved_model 模型保存与载入
# 基于GRU的预测
inputX = tf.placeholder(tf.float32, shape=[None, seq_len, num_nodes], name='inputXX') # 输入数据
y_pred, _, _ = traffic_prediction(inputX, weight_out, bias_out) # y_pred.name = 'ypred'
# saved_model 开始,定义 signature_key
signature_key = 'traffic_predict'
# 构建两个字典,inputs 和 outputs,把要存入的变量放入其中
inputs = {'input_XX': tf.saved_model.utils.build_tensor_info(inputX)} # 输入数据 inputX
outputs = {'pred_YY': tf.saved_model.utils.build_tensor_info(y_pred)} # 预测结果 y_pred
# 构建 Signature
signature = tf.saved_model.signature_def_utils.build_signature_def(
inputs=inputs,
outputs=outputs,
# method_name=signature_key # method_name='traffic_predict'
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME # method_name='tensorflow/serving/predict'
)
# 建立SavedModelBuilder存储模型,并以signature的形式添加要存储的变量
builder = tf.saved_model.builder.SavedModelBuilder(saved_model_path)
builder.add_meta_graph_and_variables(
sess=sess,
tags=[tf.saved_model.tag_constants.SERVING], # 预定义值 SERVING
signature_def_map={signature_key: signature}, # signature_def_map={'traffic_predict':signature},
clear_devices=True
)
# 将 MetaGraphDef 写入磁盘
builder.save()
通过saved_model 将模型固化保存下来, 在模型输出路径可以看到以下文件

2. 部署自己的模型
2.1 创建自己的模型目录
Tensorflow Serving 的样例, 如各种版本的 half_plus_two, 均在通过 git clone https://github.com/tensorflow/serving 拉取到的目录下.
/xxx/serving/tensorflow_serving/servables/tensorflow/testdata
- 在和saved_model_half_plus_two_cpu模型同级的目录下,创建了自己的模型文件夹,如 traffic_prediction_gru
- 在traffic_prediction_gru下, 再新建一个版本文件夹, 如果版本为v1, 则可以 000001
- 打开目录 000001, 并将通过 saved_model 保存固化下来 variables 和 saved_model.pb 放进文件夹中


2.2 模型发布
启动 docker 服务
sudo service docker start
将模型发布到8501端口
docker run -p 8501:8501 \
--mount type=bind,source=/home/xxx/docker/serving/tensorflow_serving/servables/tensorflow/testdata/traffic_prediction_gru,target=/models/traffic_prediction_gru \
-e MODEL_NAME=traffic_prediction_gru \
-t tensorflow/serving &
若发布成功, 则可以在终端看到如下提示
Successfully reserved resources to load servable {name: traffic_prediction_gru version: 1}
Successfully loaded servable version {name: traffic_prediction_gru version: 1}
Running gRPC ModelServer at 0.0.0.0:8500 ...
Exporting HTTP/REST API at:localhost:8501 ...
2.3 查看模型情况
本地浏览器打开如下网址, 可以JSON的形式查看模型的基本运行及 metadata 情况.
(1) 查看模型概况
http://xxx.xxx.xxx.xxx:8501/v1/models/traffic_prediction_gru

{
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": ""
}
}
]
}
(2) 查看模型metadata 数据情况:
http://xxx.xxx.xxx.xxx:8501/v1/models/traffic_prediction_gru/metadata

{
"model_spec":{
"name": "traffic_prediction_gru",
"signature_name": "",
"version": "1"
}
,
"metadata": {"signature_def": {
"signature_def": {
"traffic_predict": {
"inputs": {
"input_XX": {
"dtype": "DT_FLOAT",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "12",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "inputXX:0"
}
},
"outputs": {
"pred_YY": {
"dtype": "DT_FLOAT",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "ypred:0"
}
},
"method_name": "tensorflow/serving/predict"
}
}
}
}
}
[补充说明] :
(1) 关于 signature_def (signature_name)
signature_key = 'traffic_predict'
builder.add_meta_graph_and_variables(
......,
tags=[tf.saved_model.tag_constants.SERVING], # 预定义值 SERVING
signature_def_map={signature_key: signature}, # signature_def_map={'traffic_predict':signature},
......
)
在 signature_def_map 中, 我们定义的 signature 名称为 ‘traffic_predict’.
也就是后面在调用接口API时, signature_name = ‘traffic_predict’
(2) 关于 method_name
前面我们定义了
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME
# method_name = 'tensorflow/serving/predict'
故此处的 method_name 为 ‘tensorflow/serving/predict’ .
如果我们自定义
method_name=signature_key # method_name = 'traffic_predict'
则此处的 method_name 为 ‘traffic_predict’
3. 调用API接口进行测试
3.1 通过curl命令进行预测
可以通过curl命令发送预测样本给已经部署好的docker服务
$curl -d '{"instances":[{"input_XX": [[227.9],[216.8],[207.9],[200.5],[190.0],[185.0],[178.1],[172.0],[168.7],[166.2],[166.0],[163.5]]}' \
-X POST http://xxx.xxx.xxx.xxx:8501/v1/models/traffic_prediction_gru:predict
3.2 通过 postman 调用接口进行预测
按照在 saved_model 固化模型阶段中, 定义的 signature_name 和 输入数据 input_XX 的 name 和 size 定义好请求报文, 通过POST的方式发送请求, 并得到预测结果.
(1) 发送请求报文

此处, shape(input_XX) = (-1, 12, 1), 构造的样例请求报文如下:
{
"signature_name": "traffic_predict",
"instances":[
{
"input_XX": [[227.9],[216.8],[207.9],[200.5],[190.0],[185.0],[178.1],[172.0],[168.7],[166.2],[166.0],[163.5]]
}
]
}
instances 包含一个list,list中每个元素是一个待预测实例,每个实例里面是所有参数的值, 所以参数按照这种方式构造就可以。
这里如果输入数据实例有多个, 就给在 “instances” 里给多个实例, 实例之间用逗号分隔。如 :
{
"signature_name": "traffic_predict",
"instances":[
{
"input_1": [1],
"input_2": [2],
"input_3": [3]
}
]
}
如果使用 restful 形式的去请求服务,请求的body是一个json字符串,body有两种模式,行模式(instances模式)和列模式。
(2) 返回预测结果

4. 部署多个模型
模型结构:
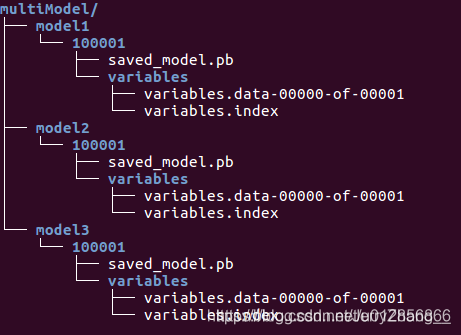
(1) 在multiModel文件夹下新建一个配置文件model.config
文件内容为:
model_config_list:{
config:{
name:"model1",
base_path:"/models/multiModel/model1",
model_platform:"tensorflow"
},
config:{
name:"model2",
base_path:"/models/multiModel/model2",
model_platform:"tensorflow"
},
config:{
name:"model3",
base_path:"/models/multiModel/model3",
model_platform:"tensorflow"
}
}
(2) 配置文件定义了模型的名称和模型在容器内的路径,现在运行tfserving容器 :
docker run -p 8501:8501 \
--mount type=bind,source=/home/tensorflow/serving/tensorflow_serving/servables/tensorflow/testdata/multiModel/,target=/models/multiModel \
-t tensorflow/serving --model_config_file=/models/multiModel/models.config
(3) 查看模型情况
http://xx.xx.xx.xx:8501/v1/models/model1
http://xx.xx.xx.xx:8501/v1/models/model1/metadata
注: 访问网址为 models/model1, 地址中不包含 multiModel .
(3) 接口请求地址
http://xx.xx.xx.xx:8501/v1/models/model1:predict
http://xx.xx.xx.xx:8501/v1/models/model2:predict
(4) 请求接口进行预测
import requests
import numpy as np
SERVER_URL = 'http://localhost:8501/v1/models/model3:predict'
#注意SERVER_URL中的‘model3’是config文件中定义的模型name,不是文件夹名称
def prediction():
predict_request='{"instances":%s}' % str([[[10]*7]*7])
print(predict_request)
response = requests.post(SERVER_URL, data=predict_request)
print(response)
prediction = response.json()['predictions'][0]
print(prediction)
if __name__ == "__main__":
prediction()
[参考博客]: tensorflow tfserving 部署多个模型、使用不同版本的模型
5. 部署模型的多个版本
如果一个模型有多个版本,并在预测的时候希望指定模型的版本,可以通过以下方式实现。
修改model.config文件,增加model_version_policy:
model_config_list:{
config:{
name:"model1",
base_path:"/models/multiModel/model1",
model_platform:"tensorflow",
model_version_policy:{
all:{}
}
},
config:{
name:"model2",
base_path:"/models/multiModel/model2",
model_platform:"tensorflow"
},
config:{
name:"model3",
base_path:"/models/multiModel/model3",
model_platform:"tensorflow"
}
}
请求预测的时候,如果要使用版本为100001的模型,只要修改SERVER_URL为:
SERVER_URL = 'http://localhost:8501/v1/models/model1/versions/100001:predict'
5. TensorFlow Serving 热部署
5.1 同一个模型新增version
- tensorflow Serving支持热更新,每次默认选取版本version最大的版本号进行部署。如下所示, 我们原有的服务基于 version 1,新增一个 version = 2 的模型。

5.2 多模型部署,新增模型
-
服务未启动
对于tensorflow serving的多模型部署,那如果想上线新模型,只需要修改模型配置model.config文件,增加model_version_policy,然后同时把新模型的模型文件放到对应路径下,再启动相应的服务就可以。 -
服务已启动
在已有模型的服务已启动的情况下,想要在不停止原服务的情况下新增一个模型,可以通过配置模型配置文件定期检查时间,来支持热部署。
docker run -p 8501:8501 \
--mount type=bind,source=/home/tensorflow/serving/tensorflow_serving/servables/tensorflow/testdata/multiModel/,target=/models/multiModel \
-t tensorflow/serving \
--model_config_file=/models/multiModel/models.config \
--model_config_file_poll_wait_seconds=60
这里,–model_config_file_poll_wait_seconds=60
将模型配置文件定期检查时间设置为60s
完整的配置选项参考: Tensorflow Serving Configuration
6. TensorFlow Serving性能提升
关于TensorFlow Serving的性能提升可以参考: 如何将TensorFlow Serving的性能提高超过70%?
参考文章:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/162874.html

