
目录
MySQL命名规则
- 数据库名、表名不得超过30个字符、变量名限制为29个字符。
- 必须只能包含A-Z,a-z,0-9和 _ 共63个字符。
- 数据库名,表名,字段名等对象名中间不要包含空格。
- 同一个MySQL软件中,数据库不能同名,同一库中表不能同名,表中字段不能同名。
- 必须保证你的字段没有和保留字,数据库系统或常用方法冲突。如果一定要使用,需要使用着重号“引起来。
数据库操作
创建数据库的方式
#数据库的创建方式
#方式1:
CREATE DATABASE mydb1;
SHOW CREATE DATABASE mydb1;#查看数据库的创建信息
#方式2:创建的同时指定字符集
CREATE DATABASE mydb2 CHARACTER SET 'gbk';
SHOW CREATE DATABASE mydb2;
#创建方式3(推荐):添加判断,如果存在则不创建
CREATE DATABASE IF NOT EXISTS mydb3;
#说明:创建好的数据库最好不要改名,因为底层改名方式为:将旧库中所有表复制到新表,再改名,浪费资源。数据库的管理
#数据库的管理
#1.查看所有的数据库
SHOW DATABASES;
#2.查看当前正在使用的数据库 (使用mysql中的全局函数)
SELECT DATABASE();
#3.查看当前数据库下的所有表
SHOW TABLES;
#查看指定数据库下所有的表
SHOW TABLES FROM mydb2;
#4.查看数据库的创建信息
SHOW CREATE DATABASE mydb1;
SHOW CREATE DATABASE mydb1\G; #此方式在命令行下可读性更好
#5.使用切换数据库
USE mysb3;修改数据库
#修改数据库
#1.修改字符集
ALTER DATABASE mydb2 CHARACTER SET 'utf8';
SHOW CREATE DATABASE mydb2;
#2.删除数据库
DROP DATABASE IF EXISTS mydb3;#加判断,如果存在就删除。
SHOW DATABASES;数据表操作
数据表的创建
方式1
— 数据表创建格式
CREATE TABLE [IF NOT EXISTS] 表名(
字段1 数据类型 [约束][默认值],
字段2 数据类型 [约束][默认值],
字段n 数据类型 [约束][默认值],
……..
)
#创建数据表
#展示当前数据库下所有的表
SHOW TABLES;
#创建方式1
CREATE TABLE IF NOT EXISTS mytable1 (
id INT,
uname VARCHAR (10),
hire_date DATE
);
#查询数据表结构
SHOW CREATE TABLE mytable1;
#查询数据表内数据字段类型内容
DESC mytable1; 方式2
— 创建方式2格式
CREATE TABLE IF NOT EXISTS 表名
AS
查询语句
#创建方式2:从别的表中获取字段创建新表(包括数据)--->复制操作
CREATE TABLE IF NOT EXISTS mytable2 #如果不存在就创建
AS
SELECT employee_id,salary
FROM employees;#查询出的结果存入刚创建的表中。
#利用方式2创建新的数据表,不包括被复制表的'数据'
#此方式相当于是获取查询表的字段名。
CREATE TABLE mytable3
AS
SELECT *
FROM employees
WHERE 1=2; #过滤条件过滤掉所有数据。表字段的添加
#管理数据表
#.添加表字段
#默认在表最后加上字段
ALTER TABLE mytable4
ADD email VARCHAR (45);
#在表最前面加上字段
ALTER TABLE mytable4
ADD phone VARCHAR (11) FIRST;
#在指定位置后添加字段
ALTER TABLE mytable4
ADD addHome VARCHAR (50) AFTER id; 修字段的改表
modify:修改字段长度,类型和默认值。
ALTER 修改字段长度,数据类型,默认值等。
格式:
ALTER TABLE 表名
MODIFY 字段名 类型 [默认值]
#修改字段长度
ALTER TABLE mytable1
MODIFY uname VARCHAR (15);
#修改字段长度和数据类型,默认值
ALTER TABLE mytable1
MODIFY hire_date DATE DEFAULT ('2022-9-20')change:重命名表字段
格式:
ALTER TABLE mytable1
CHANGE 原字段名 修改后字段名 数据类型;
#重命名表字段
ALTER TABLE mytable1
CHANGE id uid INT;
#重命名同时修改长度及默认值
ALTER TABLE mytable1
CHANGE uname `name` VARCHAR (10) DEFAULT ('Tom'); drop:删除表字段
#删除表字段
ALTER TABLE mytable1
DROP COLUMN hire_date; #删除字段hire_date重命名表
方式1格式:
RENAME TABLE 原表名 TO 改后表名 ;
方式2格式:
ALTER TABLE 原表名
RENAME [TO] 改后表名
#重命名表
#方式1:
RENAME TABLE mytable1 TO mytable1_1;
SHOW TABLES;
#重命名方式2:
ALTER TABLE mytable1_1
RENAME mytable1; 删除表和清空表
#删除表(删除表结构和表数据)
DROP TABLE IF EXISTS mytable3;
#说明:DROP TABLE语句不能回滚;(DDL操作都是自动commit的)
#清空表(不删除表结构,删除表数据)
#方式1
TRUNCATE TABLE mytable2;
#方式2
DELETE FROM mytable [where ...];可以有过滤条件。
关于数据回滚说明
commit和rollback
commit:提交数据。一旦执行commit,则数据就被永久的保存在了数据库中,意味着数据不可回滚(类似撤销操作)。
rollback:回滚数据。一旦执行rollback,则可以实现数据的回滚。回滚到最近一次commit操作之后。
truncate和delete from区别
相同点:都可以实现对表中所有数据的删除(清空表),同时保留表结构。
不同点:
truncate table:一旦执行此操作,表数据全部清空。同时,数据不可回滚。
delete from:一旦执行此操作,表数据全部清空(不带where),同时,数据可以实现rollback回滚。
DDL和DML中关于数据回滚的说明
1.DDL的操作一旦执行,就不可回滚。指令SET autocommit = FALSE对DDL操作不生效。
2.DML的操作默认情况,一旦执行,也是不可回滚的。但是,如果在执行DML之前,执行了SET autocommit = FALSE,则执行的DML操作就可以实现回滚。
DDL的原子化说明
在MySQL8.0版本中,InnoDB表的DDL支持事务完整性,既DDL操作要么成功要么回滚。
视图操作
视图概述
视图一方面可以帮助我们使用表的一部分而不是表的全部,另一方面 也可以针对不同用户指定不同的查询视图。例如:
员工薪资是敏感字段,那么只给某个级别以上的人员开放,其他人的查询视图则不提供这个字段。
对视图的理解
1.视图是一种虚拟表,本身是不具有数据的,占用很少的内存空间。
2.视图创建在已有表的基础上,视图依赖已创建的表称为基表。
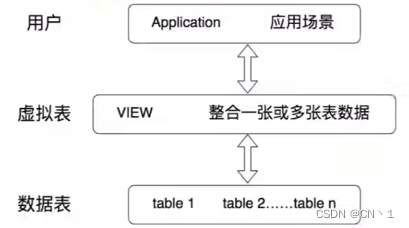

3.视图的创建和删除不影响基表。但是对视图中数据进行增删改操作,基表数据会发生变化,反之亦然。
4.向视图中提供数据内容方式为使用SELECT语句,可以将视图理解为存储起来的SELECT语句。
视图的创建
通用格式:
CREATE
[
OR REPLACE
][
ALGORITHM
= {UNDEFINED | MERGE | TEMPTABLE}]VIEW
视图名称
[(
字段列表
)]AS
查询语句[
WITH
[
CASCADED
|
LOCAL
]
CHECK OPTION
]
基本格式:CREATE VIEW
视图名称AS
查询语句
#视图的创建create view
#方式1:
CREATE VIEW vu_emp1
AS
SELECT employee_id id ,salary
FROM t_emp;
SELECT * FROM vu_emp1;
#方式2:
CREATE VIEW vu_emp2(emp_id , monthly)
AS
SELECT employee_id,salary
FROM t_emp;
SELECT * FROM vu_emp2;利用视图格式化数据
#利用视图格式化数据 效果:id(salary)
CREATE VIEW vu_emp3
AS
SELECT CONCAT(employee_id,' ( ' ,salary,' ) ') AS id_salary
FROM t_emp;
SELECT * FROM vu_emp3;效果
![]()
![]()
查看视图信息
#查看视图
#语法1:查看当前数据库下所有表和视图对象
SHOW TABLES;
#语法2:查看视图结构 describe:描述
DESC vu_emp1;
#查看视图属性信息
SHOW TABLE STATUS LIKE 'vu_emp1';
#查看视图的详细定义信息
SHOW CREATE VIEW vu_emp1;更新视图数据
#更新视图中的数据update
SELECT * FROM vu_emp1;
SELECT * FROM t_emp;
#更新后,基表的数据也会改变
UPDATE vu_emp1
SET salary = 18000
WHERE id = 101;
#同理:更改基表,对应视图数据也会改变
UPDATE t_emp
SET salary = 17000
WHERE employee_id = 101;视图不可更新的情况
“ALGORITHM = TEMPTABLE”
,视图将不支持
INSERT
和
DELETE
操作;
INSERT
操作;
SELECT
语句中使用了
JOIN
联合查询
,视图将不支持
INSERT
和
DELETE
操作;
SELECT
语句后的字段列表中使用了
数学表达式
或
子查询
,视图将不支持
INSERT
,也 不支持UPDATE
使用了数学表达式、子查询的字段值;
SELECT
语句后的字段列表中使用
DISTINCT
、
聚合函数
、
GROUP BY
、
HAVING
、
UNION
等,视图将不支持
INSERT
、
UPDATE
、
DELETE
;
SELECT
语句中包含了子查询,而子查询中引用了
FROM
后面的表,视图将不支持
、
UPDATE
、
DELETE
;
不可更新视图
;
总结:虽然可以更新视图数据,但总的来说,视图作为
虚拟表
,主要用于
方便查询
,不建议更新视图的数据。
对视图数据的更改,都是通过对实际数据表里数据的操作来完成的。
修改视图
#修改视图 CREATE OR REPLACE VIEW
CREATE OR REPLACE VIEW vu_emp1 (e_id,e_salary)
AS
SELECT employee_id,salary
FROM atguigudb.employees
WHERE salary < 8000;
SELECT * FROM vu_emp1;删除视图
删除视图只是删除视图的定义,并不会删除基表的数据。视图的主从关系:例如基于视图
a
、
b
创建了新的视图
c
,如果将视图
a
或者视图
b
删除,会导致视图
c
的查询失败。这样的视图c
需要手动删除或修改,否则影响使用。
视图的优点和缺点
视图优点
1.操作简单
对于经常使用的查询操作定义为视图,在使用时可以不关心内部结构,直接查询视图名称即可。
2.减少数据冗余
视图为虚拟表,存储的是查询语句而非数据。
3.数据安全性
访问限制
在某些数据的
结果集
上,而这些数据的结果集可以使用视图来实现。用户不必直接查询或操作数据表。这也可以理解为视图具有
隔离性
。视图相当于在用户和实际的数据表之间加了一层虚拟表。
视图存在的不足
存储过程和存储函数
存储过程 PROCEDURE创建
概述
存储过程(store procedure):是一组经过 预先编译 的 SQL 语句的封装。
类似于其他语言的方法或函数,简化操作,需要时调用,提高sql语句复用性。
执行过程
存储在 MySQL 服务器上
,需要执行的时候,客户端只需要向服务器端发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL
语句全部执行。
存储过程分类
存储过程的参数类型可以是
IN
、
OUT
和
INOUT
。
、没有参数(无参数无返回)
、仅仅带
IN
类型(有参数无返回)
、仅仅带
OUT
类型(无参数有返 回)
、既带
IN
又带
OUT
(有参数有返回)
、带
INOUT
(有参数有返回)
创建存储过程
格式:
DELIMITER // 更改分隔符。
CREATE PROCEDURE 存储过程名( IN |OUT |INOUT.. )
[characteristics..]\\约束
BEGIN
存储过程体
END//DELIMITER ; 还原分隔符
characteristics
表示创建存储过程时指定的对存储过程的约束条件;
MySQL
默认的语句结束符号为分号
‘;’
。为了避免与存储过程中
SQL
语句结束符相冲突,需要使用DELIMITER改变存储过程的结束符。设置的符号只要不冲突就可以。如$ ,\\等等
使用案例(空参,IN,OUT,INOUT)
创建存储过程avg_emp_salary(),返回所有员工的平均工资。(
无参数)
DELIMITER $
CREATE PROCEDURE avg_emp_salary()
BEGIN
SELECT AVG(salary) FROM t_emp;
END $
DELIMITER ;
#调用函数
CALL avg_emp_salary();创建存储过程show_min_salary ,查看表t_emp中的最低工资,并将最低工资通过OUT参数“ms”输出。(参数为OUT)
DELIMITER $
CREATE PROCEDURE show_min_salary(OUT ms DOUBLE) #此类型需要和表中一致
BEGIN
SELECT MIN(salary) INTO ms
FROM t_emp;
END $
DELIMITER;
#调用 传入个变量接收返回值
CALL show_min_salary(@ms);
#查看变量值
SELECT @ms;创建过程show_somenoe_salary,查询传入id的该员工的工资。(
参数为IN)
DELIMITER $
CREATE PROCEDURE show_someone_salary(IN id INT)
BEGIN
SELECT salary FROM t_emp
WHERE employee_id = id;
END$
DELIMITER;
-- 调用方式一:直接输入INT类型数据
CALL show_someone_salary(102);
-- 调用方式二:先声明变量,后传入参数
SET @num = 102;
CALL show_someone_salary(@num);传入员工姓名,输出员工领导姓名。(INOUT类型)
DELIMITER $
CREATE PROCEDURE show_mgr_name(INOUT empname VARCHAR(25))
BEGIN
SELECT last_name INTO empname
FROM t_empall
WHERE employee_id = (
SELECT manager_id
FROM t_empall
WHERE last_name = empname
);
END $
DELIMITER ;
#调用,传入INT值
SET @empname = 'Abel';
CALL show_mgr_name(@empname);
#查看OUT值
SELECT @empname;存储函数FUNCTION 创建
在
MySQL
中,存储函数的使用方法与
MySQL
内部函数的使用方法是一样的。换言之,用户自己定义的存储函数与MySQL
内部函数是一个性质的。区别在于,存储函数是
用户自己定义
的,而内部函数是
MySQL的
开发者定义
的。
存储函数和存储过程区别
存储函数和存储过程的区别:存储函数一定具有返回值 return。
创建存储函数
格式:
DELIMITER $
CREATE FUNCTION 函数名(参数 参数类型)
RETURNS 返回值类型
[characteristics…] //约束
BEGIN
函数体
END$DELIMITER ;
使用案例
存储函数需要声明约束,如果不想声明约束,可以使用命令更改全局(global)变量。
#更改命令为:
SET GLOBAL log_bin_trust_function_creators = 1;
1:关闭约束检查 0:开启
(案例默认关闭了约束的检查)
创建存储函数,名为email_by_name(),参数定义为空。
查询’Abel’的email,并返回。
DELIMITER$
CREATE FUNCTION email_by_name()
RETURNS VARCHAR(25)
BEGIN
RETURN(SELECT email FROM t_empall WHERE last_name = 'Abel');
END$
DELIMITER;
#调用
SELECT email_by_name();存储过程和存储函数的对比
1.存储过程可以有0个或多个返回值,存储函数有且只有1个。
2..存储过程一般用于更新,存储函数一般用于查询为一个值的返回值。
3.存储函数可以放在SELECT查询语句中,存储过程则不行。
4.存储过程的功能更为强大,操作限制少一些。
存储过程和存储函数的查看,修改和删除
查看
#查看 一般show后添加\G 在命令行中查看 \G:以行的形式展示
#1.查看创建信息
SHOW CREATE PROCEDURE avg_emp_salary;
SHOW CREATE FUNCTION email_by_name;
#2.查看状态信息 SHOW STATUS 可以使用模糊查询'LIKE'
SHOW PROCEDURE STATUS LIKE 'avg%';
SHOW FUNCTION STATUS LIKE 'email%';
#3.从information_schema.Routines查看信息
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME = 'avg_emp_salary' AND ROUTINE_TYPE = 'PROCEDURE';
#上方AND 后可以选择不写。修改
函数,存储过程的修改 ALTER
说明:此修改只是修改相关特性,如约束条件,不影响函数或存储过程的功能。语法 ALTER PROCEDURE avg_emp_salary [约束条件]
删除
删除函数或存储过程 DROP
#语法 {PROCEDURE | FUNCTION } [IF EXISTS] 存储函数或存储过程名例如:
DROP PROCEDURE IF EXISTS max_emp_salary;
存储过程的使用存在的争议
优点
1.存储过程可以一次编译多次使用,减少冗余,提高效率。
2.可以减少开发工作量,将常用的代码封装起来,需要时调用即可。
3.安全性强,可以设置对用户的使用权限。
4.减少网络传输。
缺点
1.可移植性差,存储过程不可跨数据库传输。
2.不易调试。
3.存储过程的版本管理困难。
4.不适合高并发场景。
触发器
概述
从
5.0.2
版本开始支持触发器。
MySQL
的触发器和存储过程一样,都是嵌入到
MySQL
服务器的一 段程序。
事件来触发
某个操作,这些事件包括
INSERT
、
UPDATE
、
DELETE
事件。当事件触发时,就会
自动
激发触发器执行相应的操作。
触发器的创建和使用
创建格式:
CREATE TRIGGER 触发器名称
{BEFORE|AFTER} {INSERT|UPDATE|DELETE} ON 表名
FOR EACH ROW
触发器执行语句表名:触发对象
BEFORE|AFTER :触发时间
INSERT | UPDATE | DELETE :触发事件
触发器的测试使用:
创建一个源表和一个目标表,源表用于增删改操作,增删改操作为事件,当事件触发时,就会对目标表自动的进行日志的添加。如下:
#创建事件源表
CREATE TABLE source(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(25)
)
#创建触发目标表
CREATE TABLE target(
id INT PRIMARY KEY AUTO_INCREMENT,
log VARCHAR(255)
)
SELECT * FROM source;
SELECT * FROM target; #两个表现在为空
#创建触发器
DELIMITER$
CREATE TRIGGER before_insert #触发器名
BEFORE INSERT ON source #源表 添加前触发
FOR EACH ROW
BEGIN
INSERT INTO target(log) #触发体
VALUES('log_'); #触发事件后添加一条数据
END$
DELIMITER;
INSERT INTO source(`name`) VALUES('Tom'); #向源表添加数据,触发事件
SELECT * FROM source;
SELECT * FROM target;
#两表均有数据,target表为触发器自动添加查看和删除触发器
#查看和删除触发器
-- 查看触发器
#查看当前数据库所有定义的触发器
SHOW TRIGGERS;
#查看当前数据库指定名称的触发器
SHOW CREATE TRIGGER 触发器名称;
#从系统库information_schema的TRIGGERS表中查询“salary_check_trigger”触发器的信息。
SELECT * FROM information_schema.TRIGGERS;
-- 删除触发器
DROP TRIGGER IF EXISTS 触发器名称;版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/154578.html

