
目录
一.下载镜像文件
Docker安装elasticsearch(存储与检索数据)
[root@VM-12-8-centos ~]# docker pull elasticsearch:7.5.0Docker安装kibana(可视化检索数据)
[root@VM-12-8-centos ~]# docker pull kibana:7.5.0查看下载的镜像
[root@VM-12-8-centos ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
redis latest 7614ae9453d1 9 months ago 113MB
mysql 5.7 c20987f18b13 9 months ago 448MB
grafana/grafana latest 9b957e098315 9 months ago 275MB
kibana 7.5.0 a674d23325b0 4 years ago 388MB
elasticsearch 7.5.0 5acf0e8da90b 4 years ago 486MB
注意:elasticsearch与kibana版本要统一
二.创建实例
2.1 创建elasticsearch实例
2.1.1.提前创建好elasticsearch所需要挂载的data、config及插件的数据卷
[root@VM-12-8-centos ~]# mkdir -p /mydata/elasticsearch/config
[root@VM-12-8-centos ~]# mkdir -p /mydata/elasticsearch/data
[root@VM-12-8-centos ~]# mkdir -p /mydata/elasticsearch/plugins2.1.2 配置允许所有ip可访问elasticsearch
[root@VM-12-8-centos ~]# echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml2.1.3 保证权限
[root@VM-12-8-centos ~]# chmod -R 777 /mydata/elasticsearch/
2.1.4 启动elasticsearch
docker run --name elasticsearch -p 9200:9200 -p 9300:9300
-e "discovery.type=single-node"
-e ES_JAVA_OPTS="-Xms64m -Xmx512m"
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins
-d elasticsearch:7.5.0其中:–name:指定实例名称
-p 9200:9200:将宿主机与容器端口映射,我们向es发送http请求或使用Rest Api与es通信将访问9200端口。
-p 9300:9300:在es集群节点中通讯端口默认为9300
-e “discovery.type=single-node”:以单节点模式运行
-e ES_JAVA_OPTS=”-Xms64m -Xmx512m”:由于测试,设置初始占用内存为64m,最大占用内存为512
[root@VM-12-8-centos ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c8156b7a8987 elasticsearch:latest "/docker-entrypoint.…" 15 seconds ago Up 14 seconds 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
注意:在防火墙打开对应的端口!!
访问9200端口:


2.2 创建Kibana实例
2.2.1 创建kibana实例需要挂载的配置文件数据卷
[root@VM-12-8-centos ~]# mkdir /mydata/kibana/config
[root@VM-12-8-centos config]# touch kibana.yml
在kibana.yml中加入一下配置:
server.port: 9891 #修改端口
server.host: “0.0.0.0” # 修改任意主机访问
2.2.3 启动Kibana
[root@VM-12-8-centos config]# docker run --name kibana -e ELASTICSEARCH_HOSTS=http://xxx.xx.xx.x/:9200 -p 5601:5601 -v /mydata/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml -d kibana:7.5.0注意:-e ELASTICSEARCH_HOSTS 后面的参数为es容器内部地址与端口!!
通过以下可查询容器内容ip
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' container_name_or_id
可通过一下查看容器日志(启动未成功,查看日志)
docker logs container_name_or_id2.2.4 访问Kibana
我们通过服务器ip:5601访问kibana,看到以下则说明kibana启动成功。
三.es初步索引
1、_cat
| GET /_cat/nodes | 查看所有节点 |
| GET /_cat/health | 查看 es健康状况 |
| GET /_cat/master | 查看主节点 |
| GET /_cat/indices | 查看所有索引 相对于mysql中的show databases; |
2、索引一个文档(保存)
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
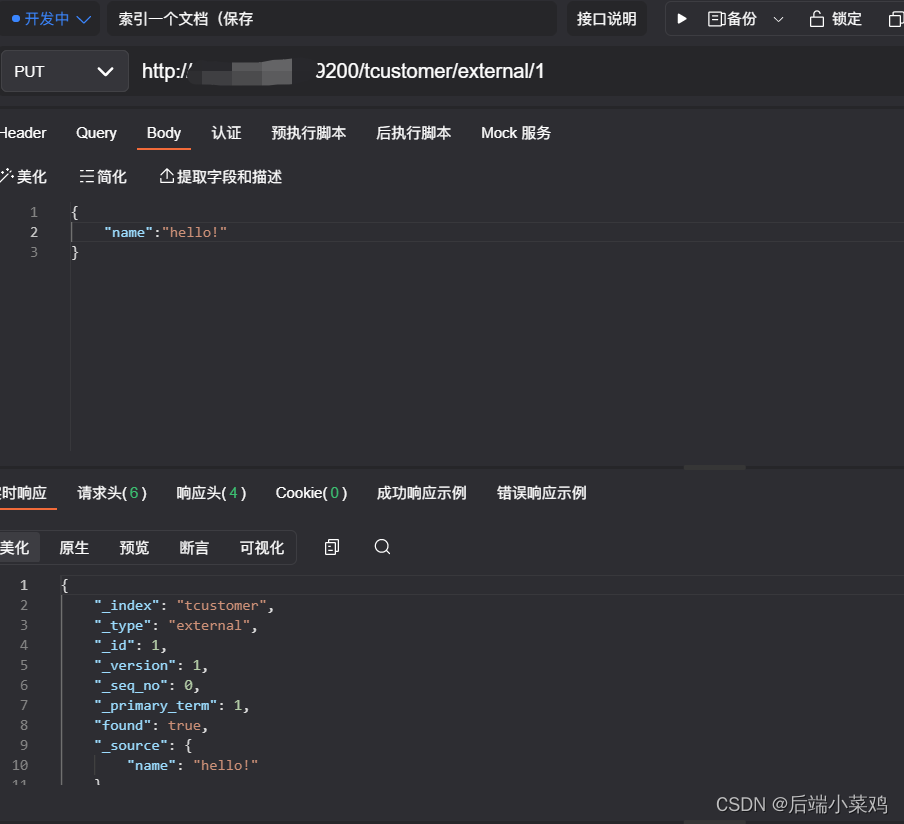
示例:PUT customer/external/1
在 customer 索引下的 external 类型下保存 1 号数据为
{ “name”: “John Doe” }
PUT 和 POST 操作都可以, POST 新增。如果不指定 id,会自动生成 id。指定 id 就会修改这个数据,并新增版本号 PUT 可以新增可以修改。PUT 必须指定 id;由于 PUT 需要指定 id,我们一般都用来做修改 操作,不指定 id 会报错。
3、查询文档
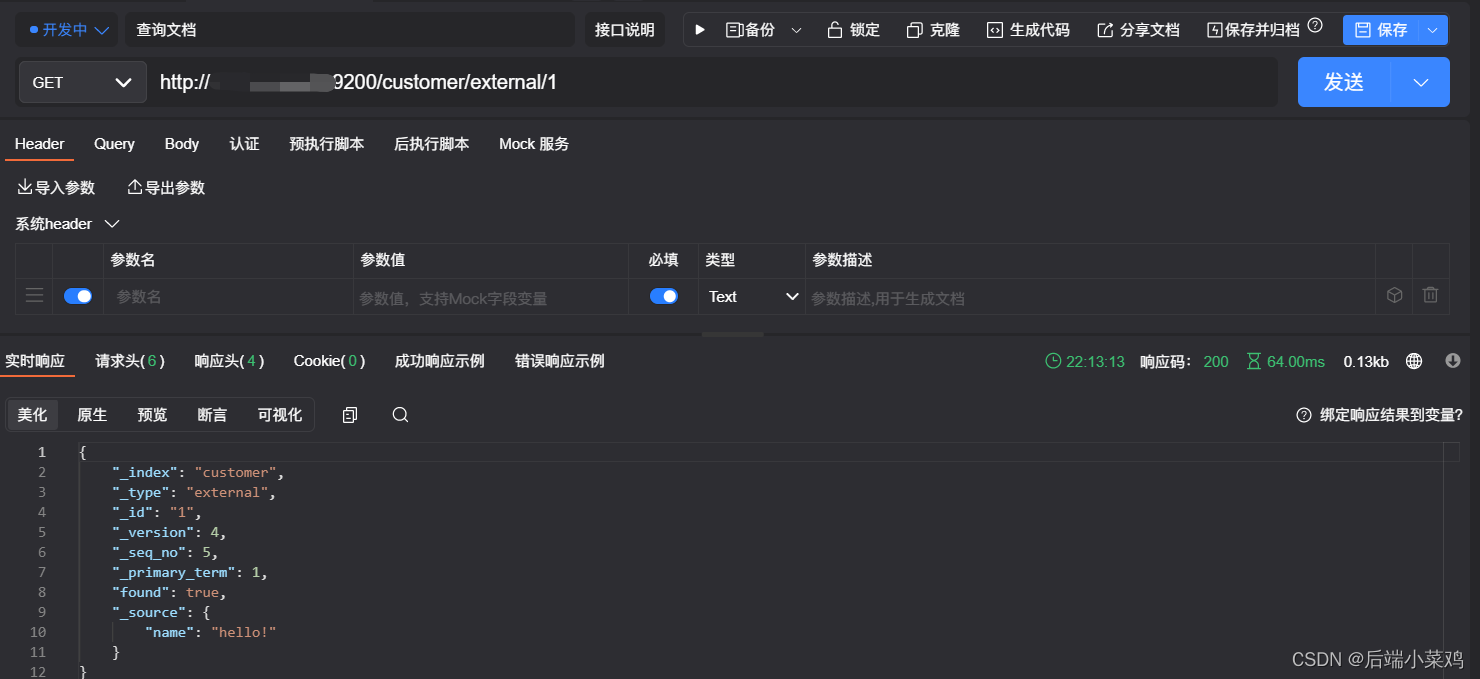
1、GET customer/external/1
 结果:
结果:
{ "_index": "customer", //在哪个索引
"_type": "external", //在哪个类型
"_id": "1", //记录 id
"_version": 2, //版本号
"_seq_no": 1, //并发控制字段,每次更新就会+1,用来做乐观锁
"_primary_term": 1, //同上,主分片重新分配,如重启,就会变化
"found": true, "_source": { //真正的内容
"name": "John Doe"
}
}2、乐观锁的使用
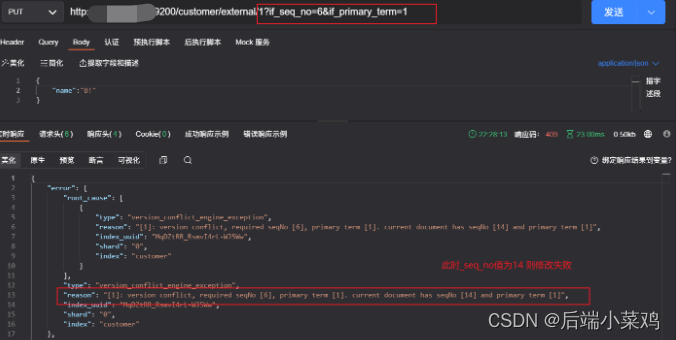
请求参数后追加?if_seq_no=1&if_primary_term=1
源数据name为hello
A:修改name从 “hello” 到 ”A“
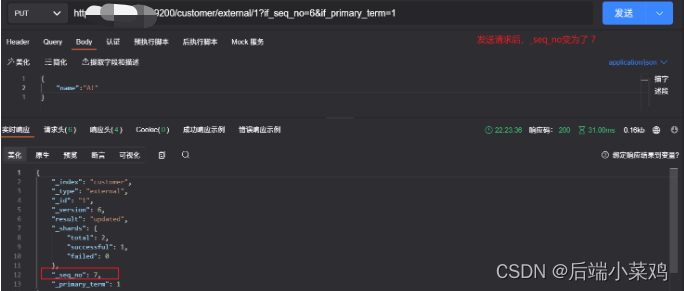
B:修改name从 “A” 到 ”B“
4.更新文档
POST customer/external/1/_update
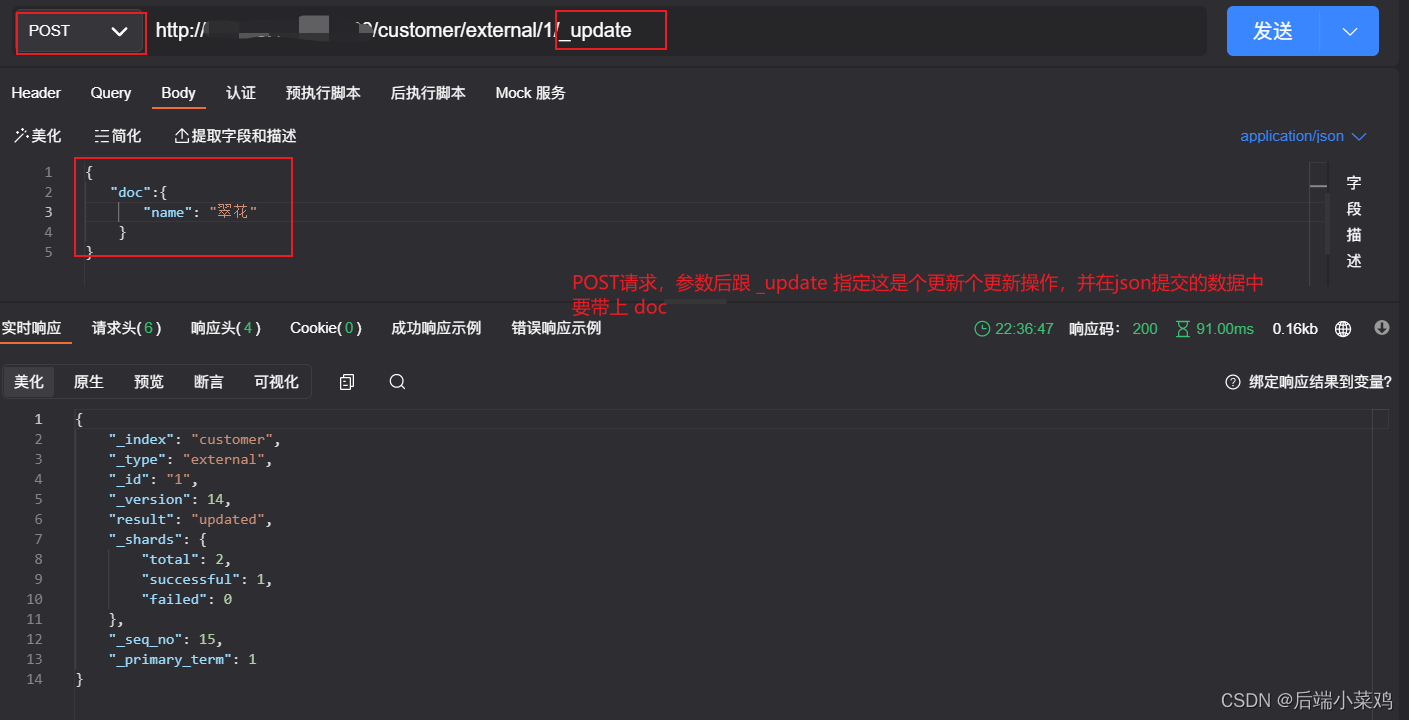
post请求,且地址栏带上_update 则指定这是个更新操作。
携带的json数据必须名为【doc】
更新时会对比源文档数据,如果相同不会有什么操作,文档 version 不增加
也可追加属性
post请求,且地址栏不带上_update,json也不携带【doc】
则直接更新文档,文档 version 增加
PUT customer/external/1
与 POST customer/external/1 无异,即直接更新文档,增加文档version
5.删除文档&索引
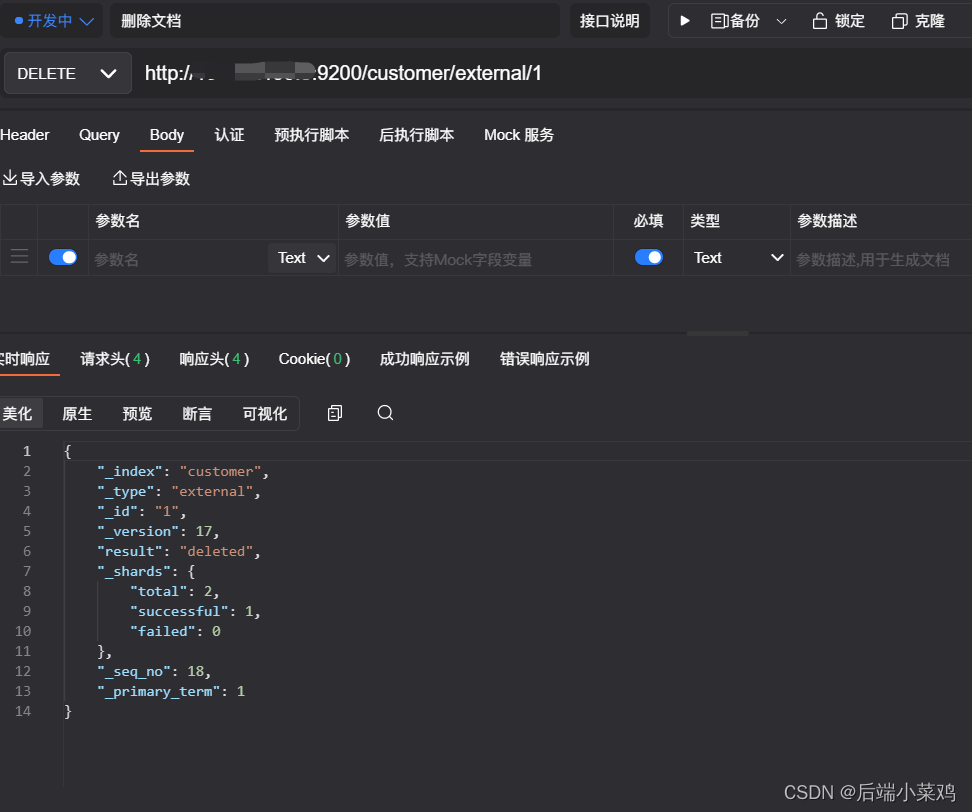
DELETE customer/external/1 删除文档
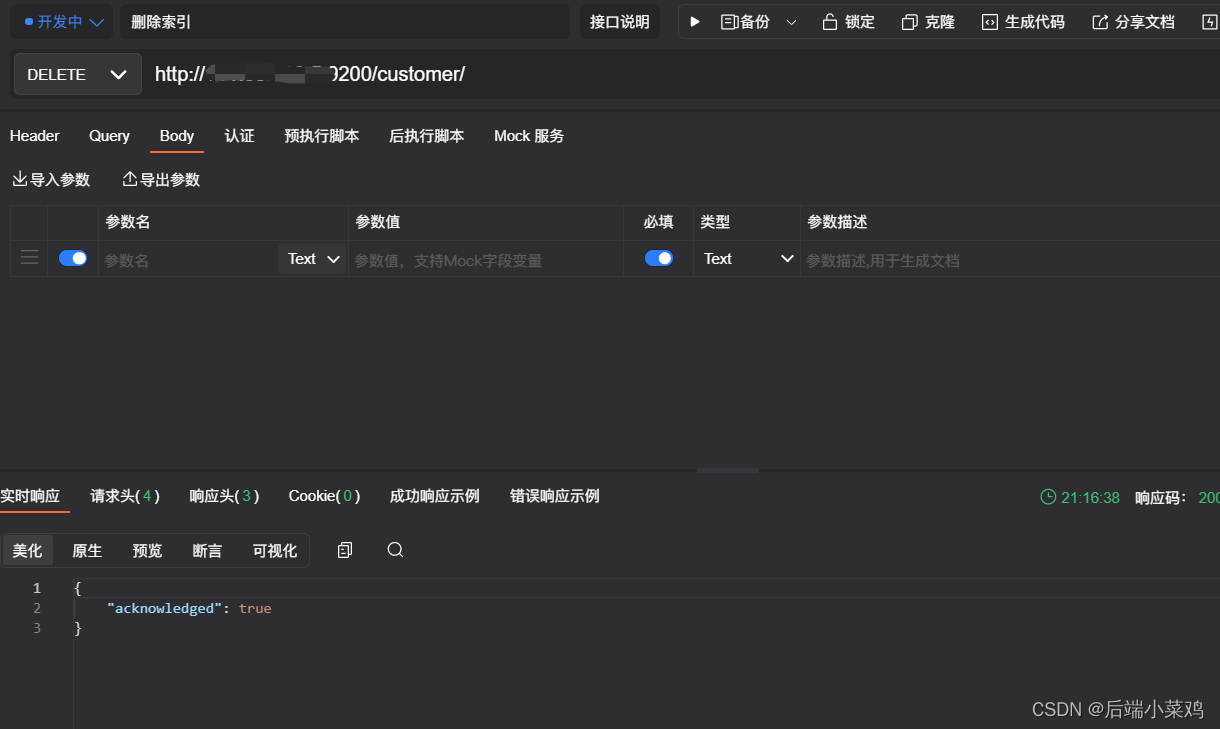
DELETE customer/ 删除索引
6.bulk 批量 API
POST customer/external/_bulk
语法格式:
{ action: { metadata }} \n 可指定要操作的索引、类型、id
{ request body } \n
{ action: { metadata }} \n
{ request body } \n
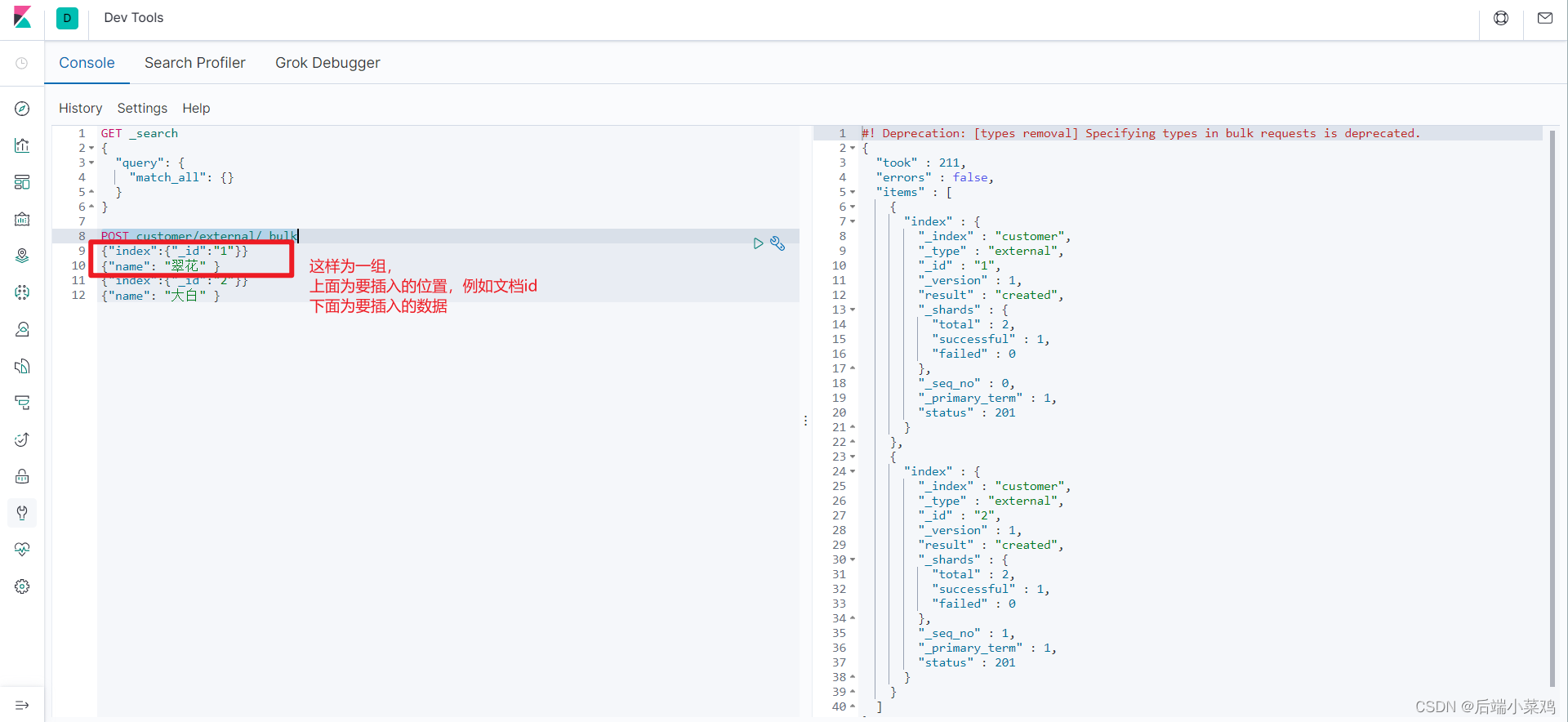
bulk API 以此按顺序执行所有的 action(动作)。如果一个单个的动作因任何原因而失败, 它将继续处理它后面剩余的动作。当 bulk API 返回时,它将提供每个动作的状态(与发送 的顺序相同),所以您可以检查是否一个指定的动作是不是失败了。
复杂实例:
POST /_bulk
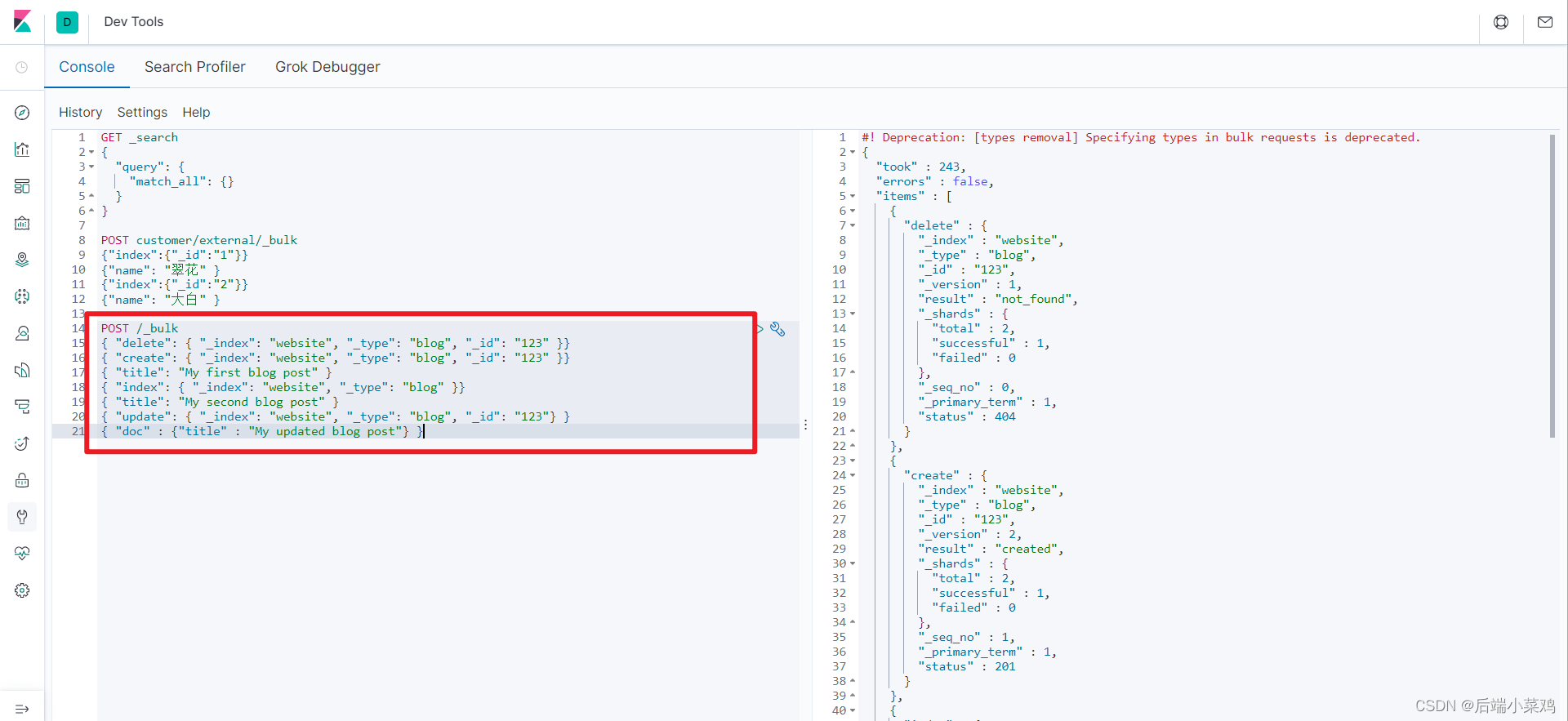
四.进阶检索
1、SearchAPI
ES 支持两种基本方式检索 :
一个是通过使用 REST request URI 发送搜索参数(uri+检索参数)
另一个是通过使用 REST request body 来发送它们(uri+请求体)
1)、检索信息
一切检索从_search 开始
| GET bank/_search | 检索 bank 下所有信息,包括 type 和 docs |
| GET bank/_search?q=*&sort=account_number:asc | 请求参数方式检索 |
使用uri+检索参数:
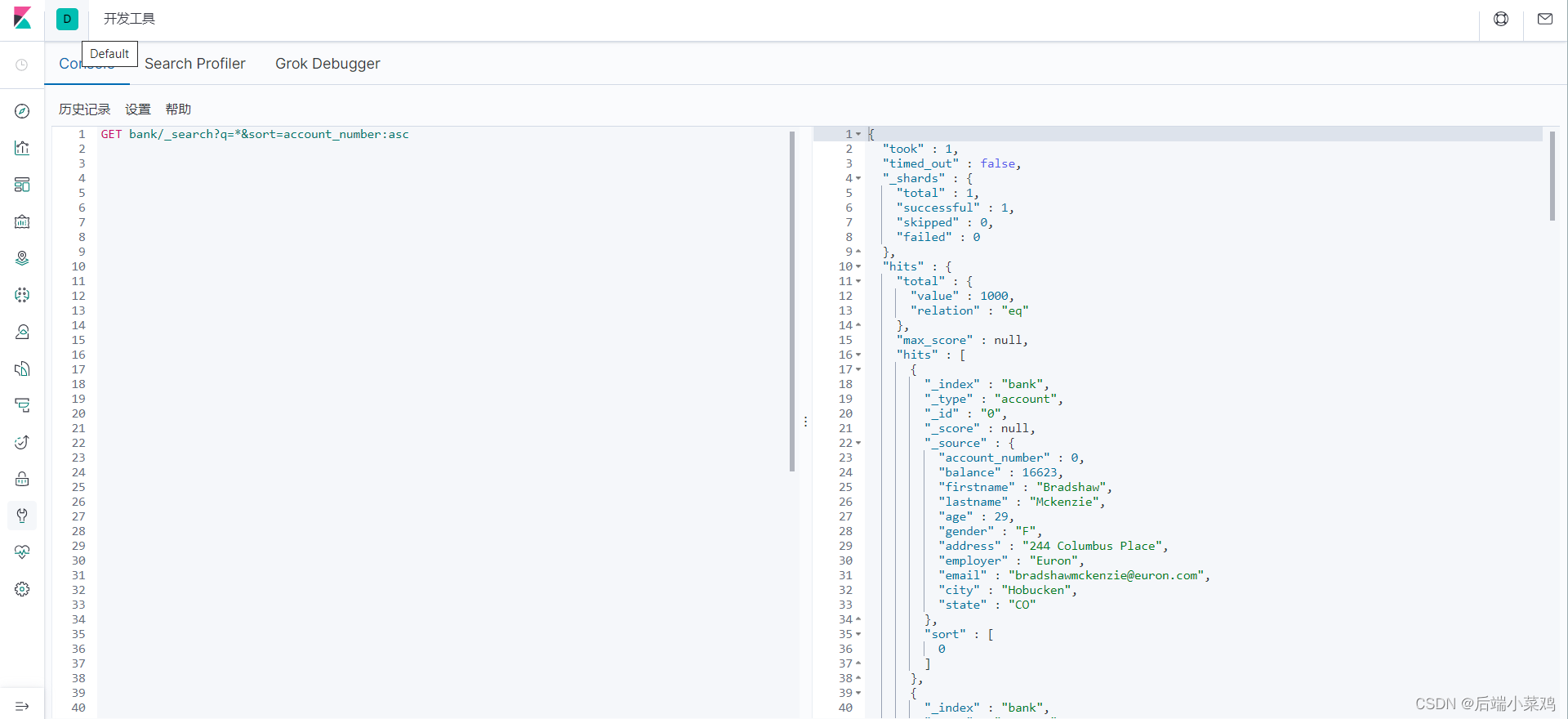
响应结果解释:
took – Elasticsearch 执行搜索的时间(毫秒)
time_out – 告诉我们搜索是否超时
_shards – 告诉我们多少个分片被搜索了,以及统计了成功/失败的搜索分片
hits – 搜索结果
hits.total – 搜索结果
hits.hits – 实际的搜索结果数组(默认为前 10 的文档)
sort – 结果的排序 key(键)(没有则按 score 排序)
score 和 max_score –相关性得分和最高得分(全文检索用)
使用uri+请求体:
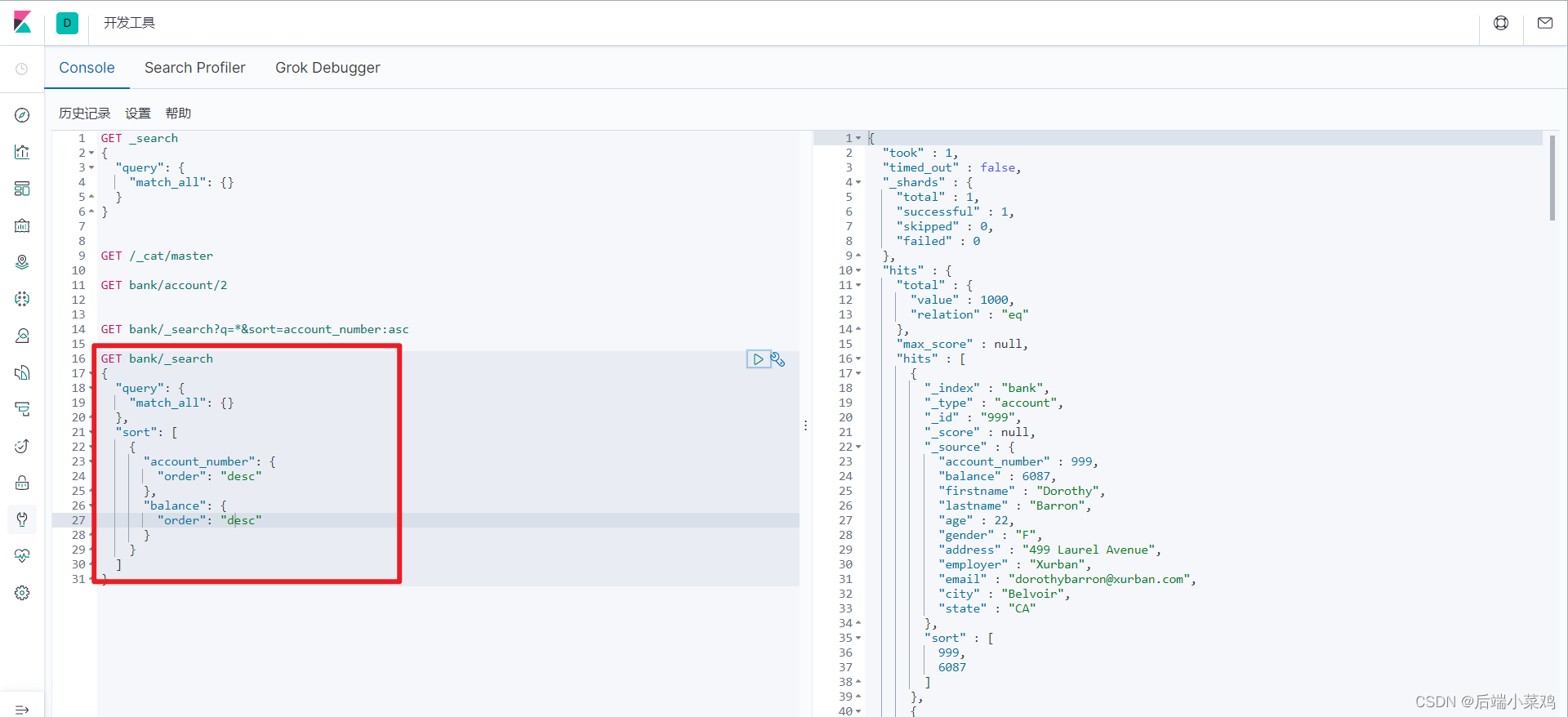
2、Query DSL
1)、基本语法格式 Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL(domain-specific language 领域特 定语言)。这个被称为 Query DSL。该查询语言非常全面,并且刚开始的时候感觉有点复杂, 真正学好它的方法是从一些基础的示例开始的。
GET /bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance": {
"order": "desc"
}
}
],
"from": 10,
"size": 5,
"_source": ["account_number","balance"]
}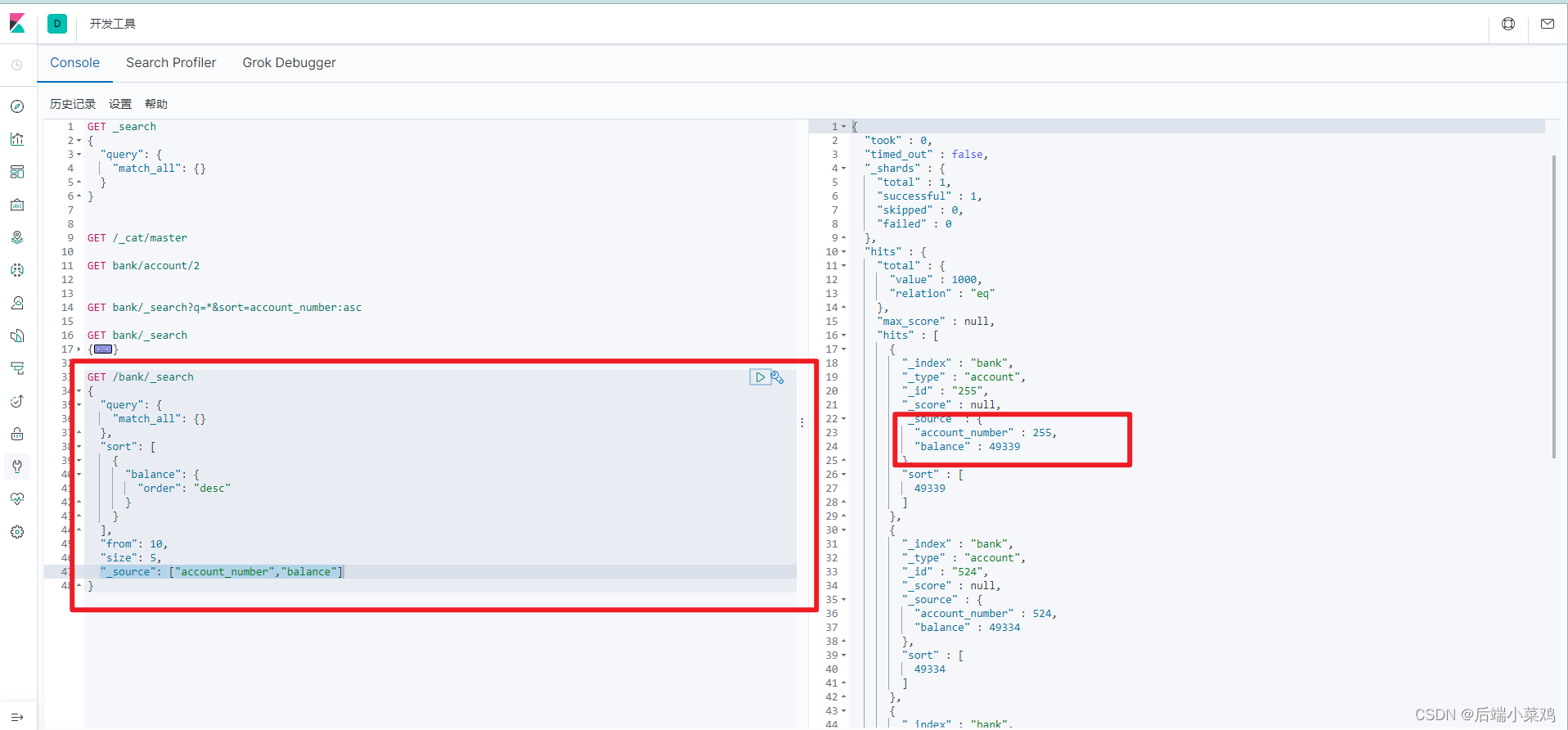
query 定义如何查询。
match_all 查询类型【代表查询所有的所有】,es 中可以在 query 中组合非常多的查 询类型完成复杂查询。
除了 query 参数之外,我们也可以传递其它的参数以改变查询结果。如 sort,size。
from+size限定,完成分页功能。
sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准。
_source返回部分字段
2)、match【匹配查询】 (分词)
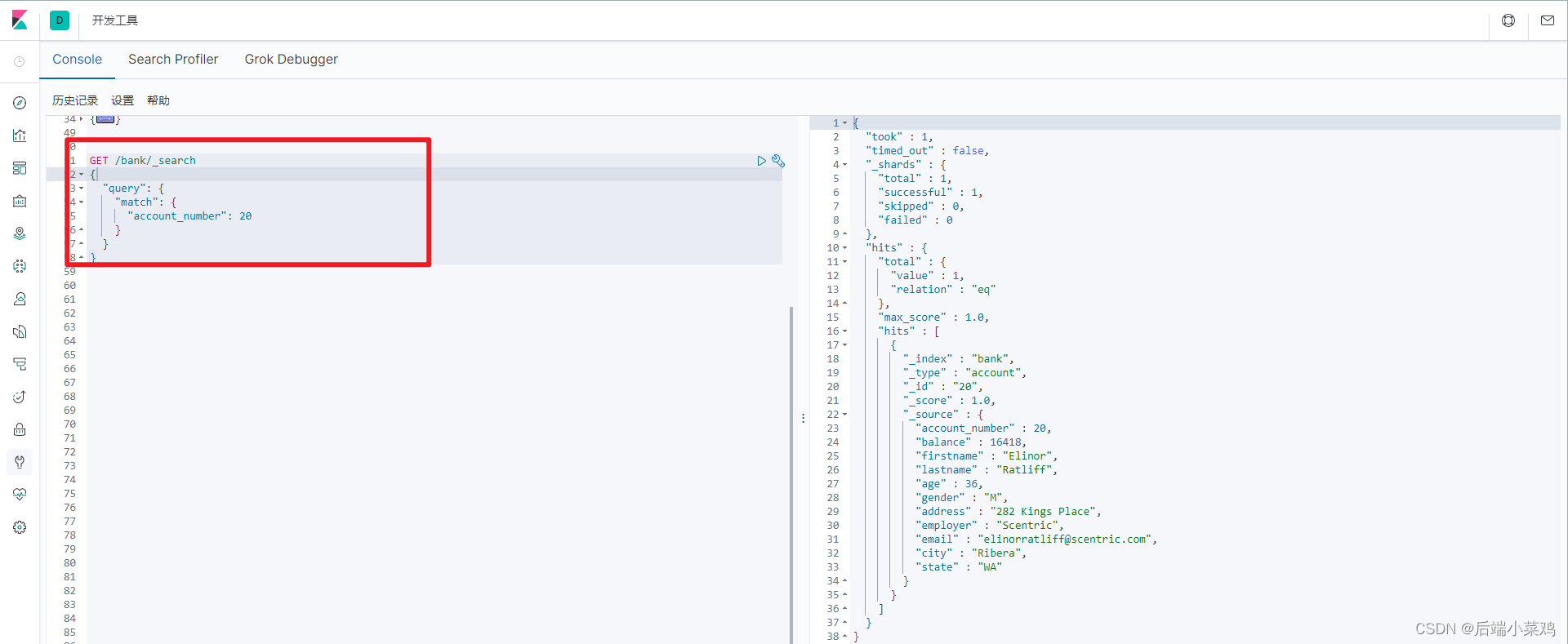
1、匹配account_number为20的数据
GET /bank/_search
{
"query": {
"match": {
"account_number": 20
}
}
}
2、全文匹配 address 中带有kings的数据 (相当与Mysql中的like查询)
GET /bank/_search
{
"query": {
"match": {
"address": "Kings"
}
}
}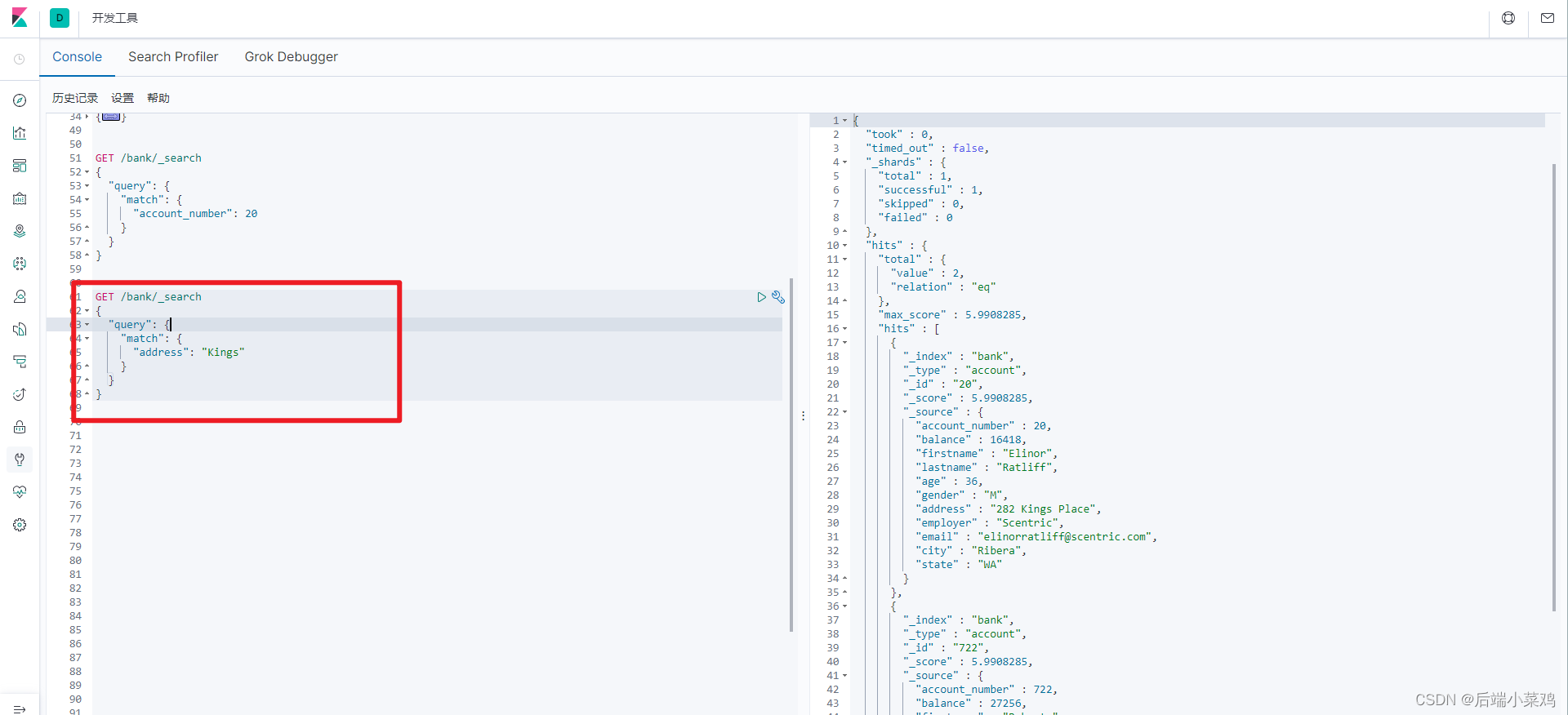
match匹配查询会将关键字进行分词匹配,只要能匹配到的关键字都会被检索出来,最终以检索的匹配度(即得分)进行排序返回。
3)、match_phrase【短语匹配】
将需要匹配的值当成一个整体单词(不分词)进行检索
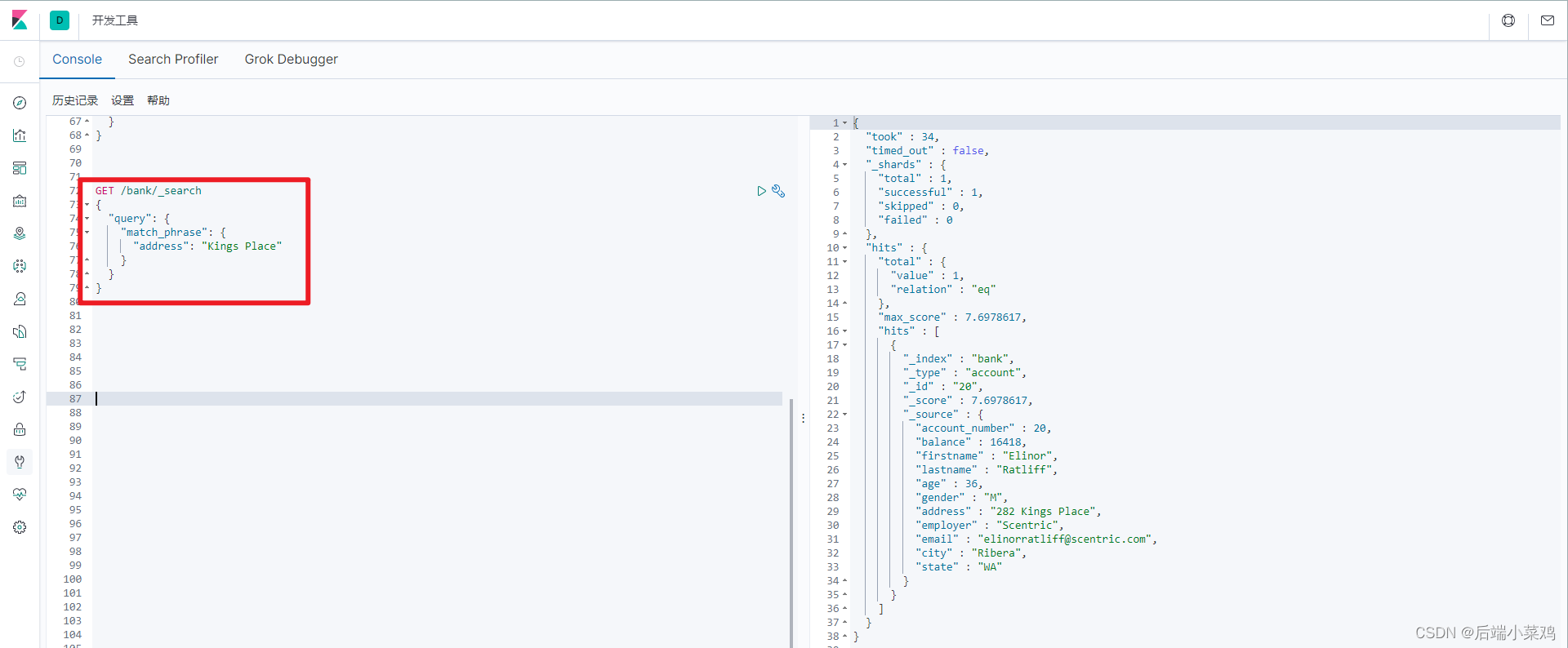
查出 address 中包含 Kings Place 的所有记录,并给出相关性得分
4)、multi_match【多字段分词匹配】
GET /bank/_search
{
"query": {
"multi_match": {
"query": "Kings Ribera",
"fields": ["city","address"]
}
}
}
即: 匹配address与city包含Kings或Ribera的数据 (会进行分词匹配)
相当于mysql中:where (address like %Kings% or address like %Ribera%)
or
(city like %Kings% or city like %Ribera%)
5)、bool【复合查询】
bool 用来做复合查询: 复合语句可以合并 任何 其它查询语句,包括复合语句,了解这一点是很重要的。这就意味 着,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender":"M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{
"match": {
"age":"20"
}
}
],
"should": [
{
"match": {
"firstname": "Forbes"
}
}
]
}
}
}- must:必须达到 must 列举的所有条件
- must_not : 必须不是指定的情况
- should:应该达到 should 列举的条件,如果达到会增加相关文档的评分,并不会改变 查询的结果。如果 query 中只有 should 且只有一种匹配规则,那么 should 的条件就会 被作为默认匹配条件而去改变查询结果
所以以上的查询条件为:gender必须为M,address必须为mill,age不能为20,firstname应该为Forbes。
6)、filter【结果过滤 】
假如我们想查询年龄在18-30之间
1、在must使用range:
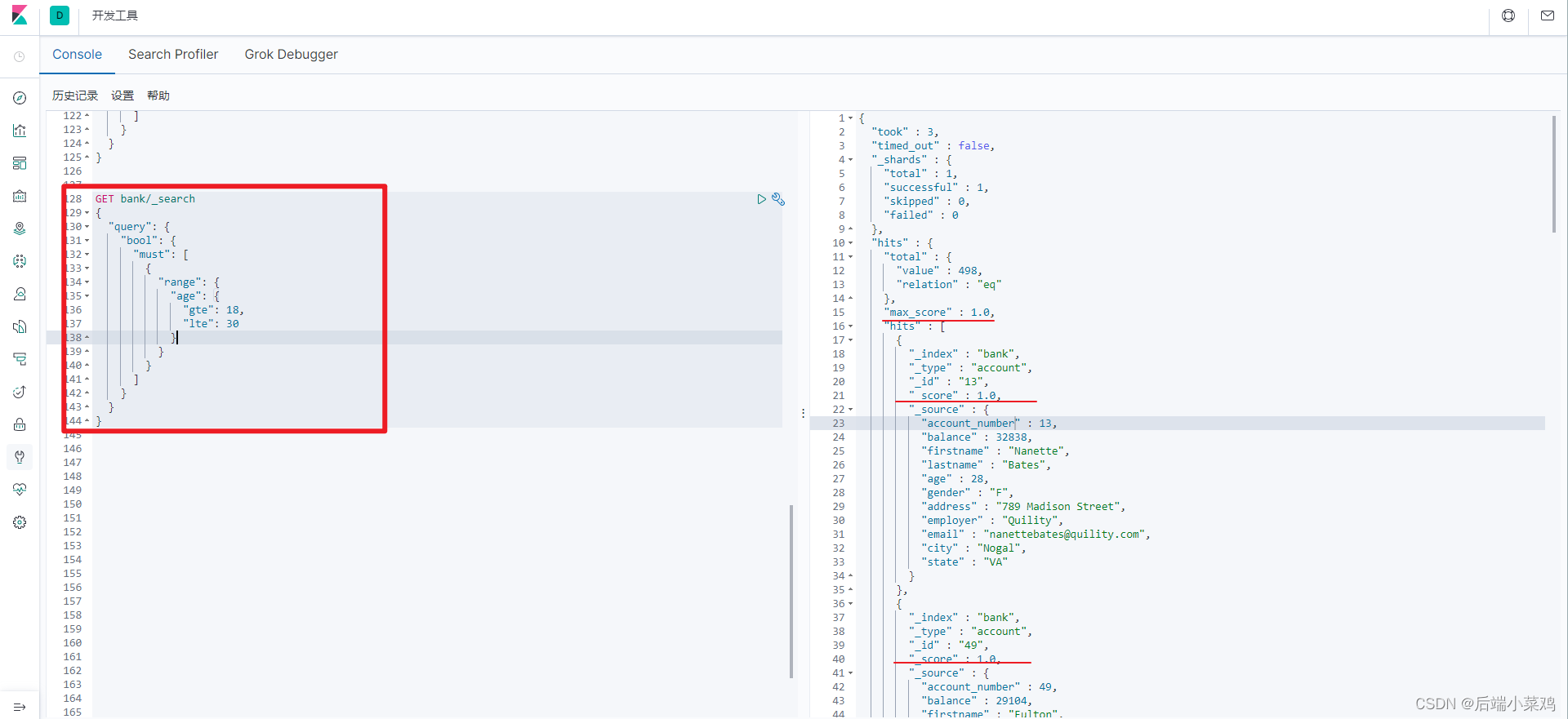
会看到有贡献相关性得分
2、使用filter过滤
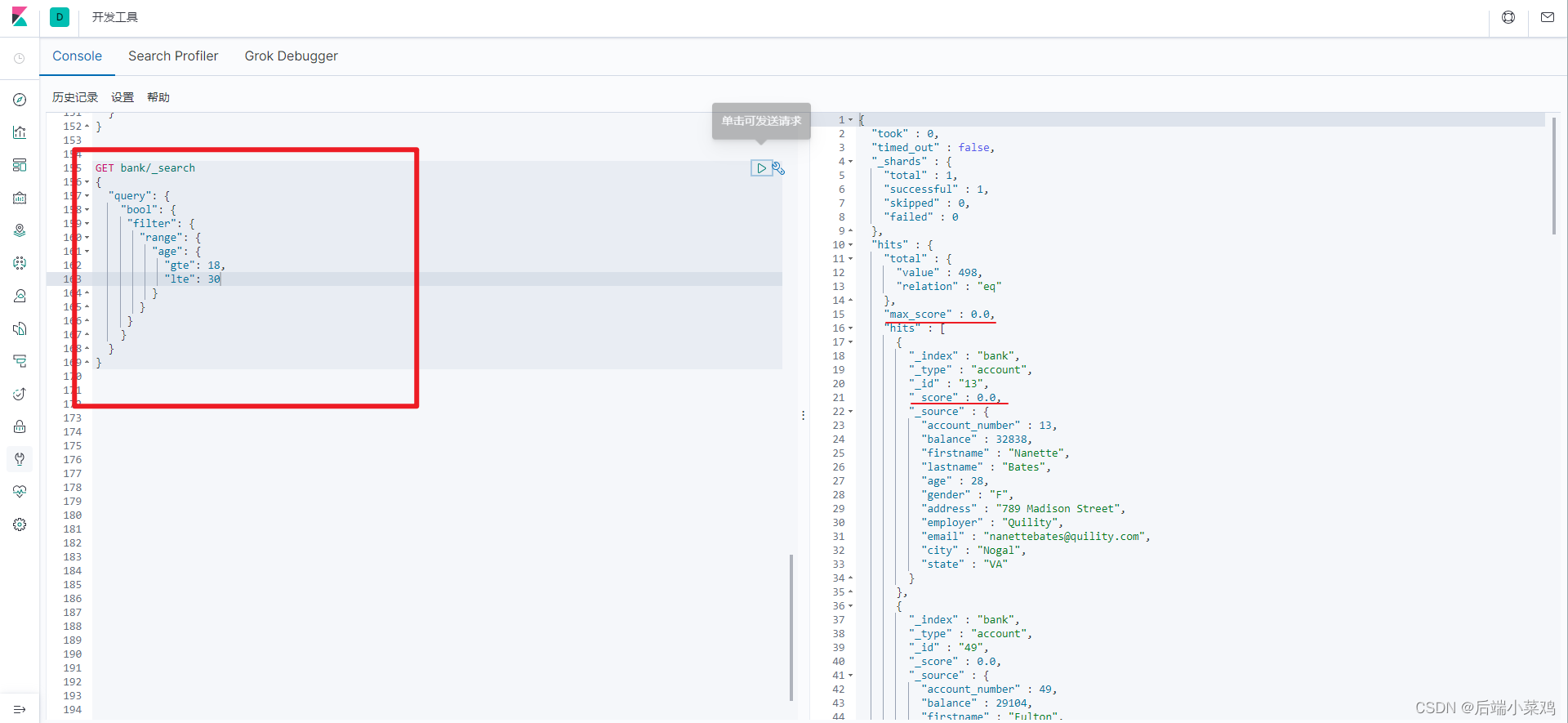
会看到 filter并不会有相关性得分
7)、term【精确匹配】
和 match 一样。匹配某个属性的值。全文检索字段用 match,其他非 text 字段匹配用 term。
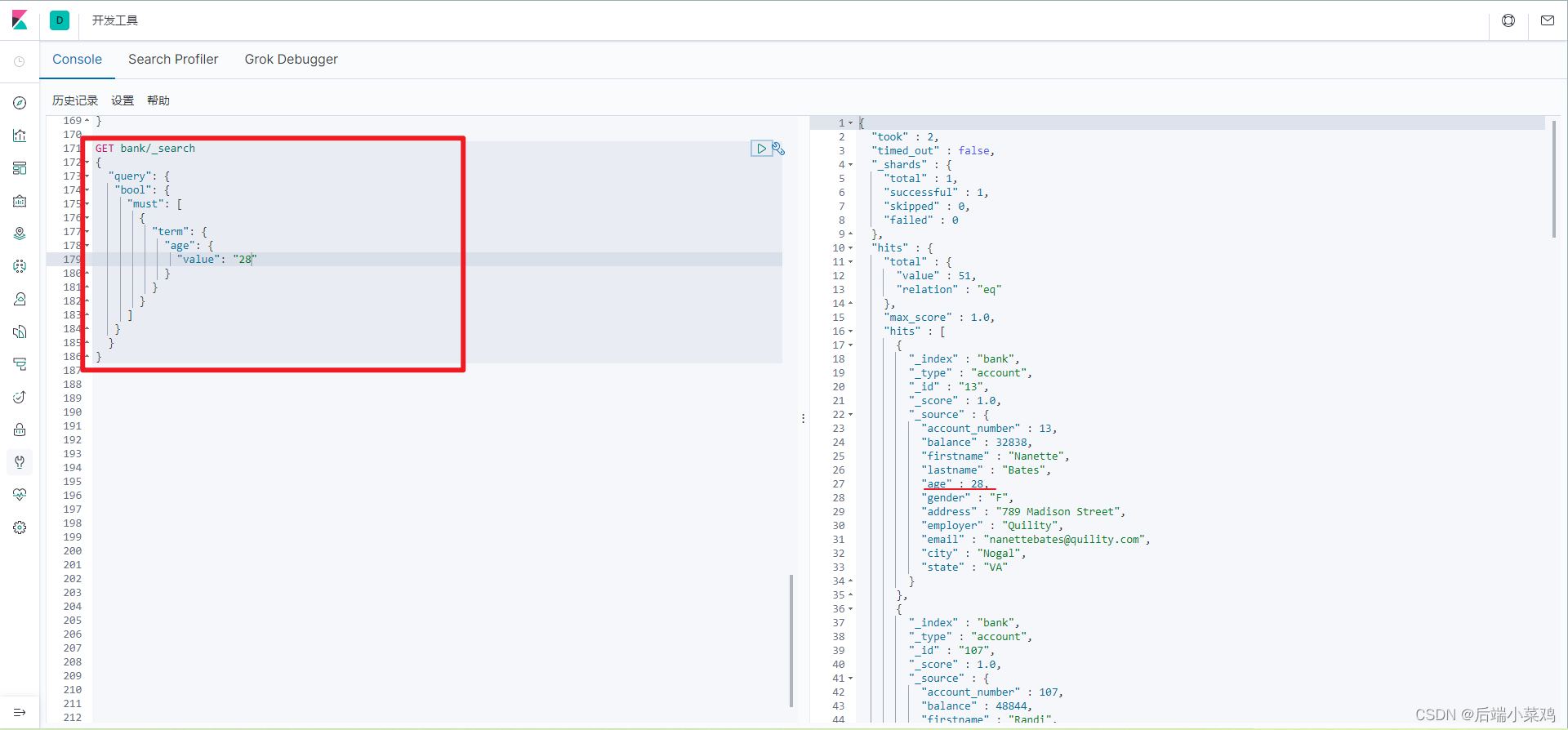
8)、aggregations(执行聚合)
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL GROUP BY 和 SQL 聚合函数。在 Elasticsearch 中,您有执行搜索返回 hits(命中结果),并且同时返 回聚合结果,把一个响应中的所有 hits(命中结果)分隔开的能力。这是非常强大且有效的, 您可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用 一次简洁和简化的 API 来避免网络往返。
1、搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情:
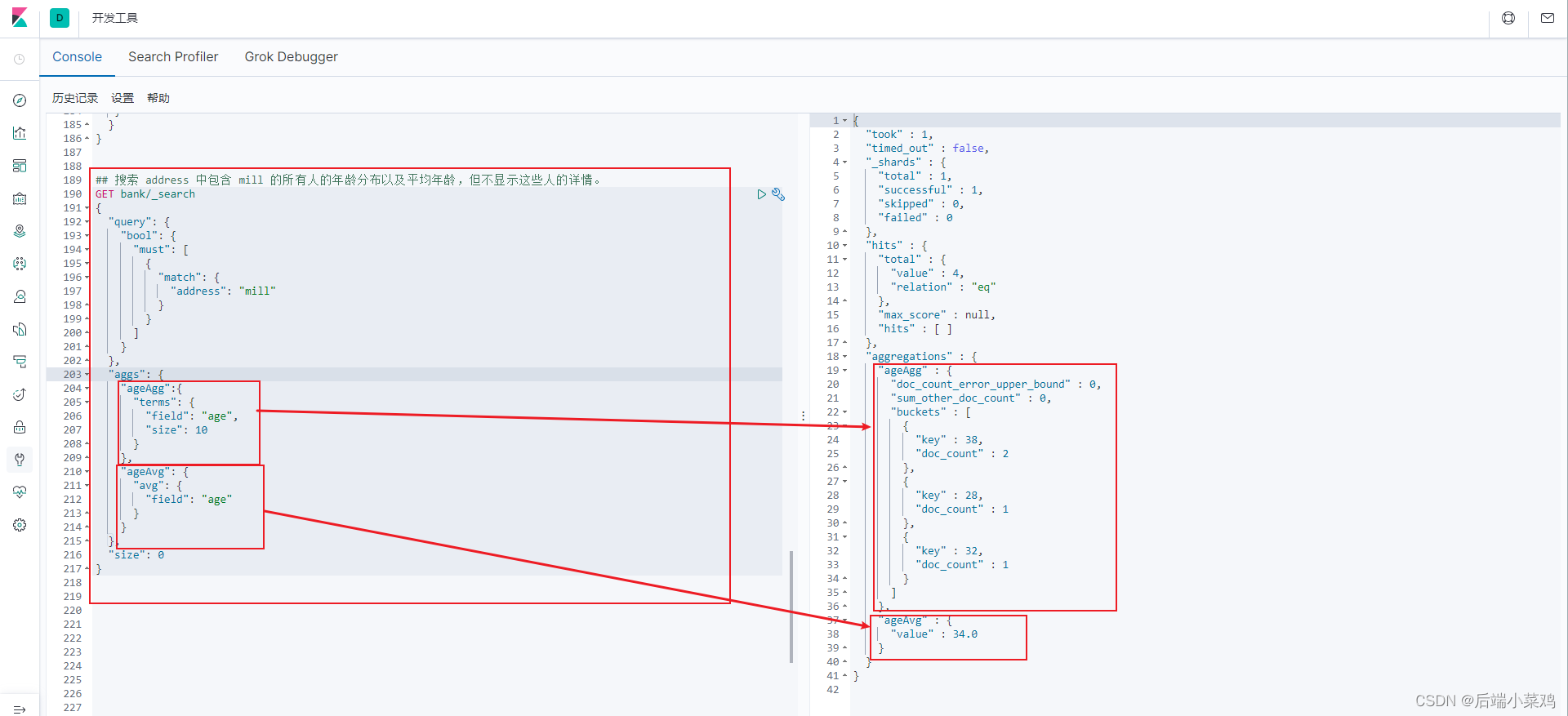
size:0 则不返回命中结果
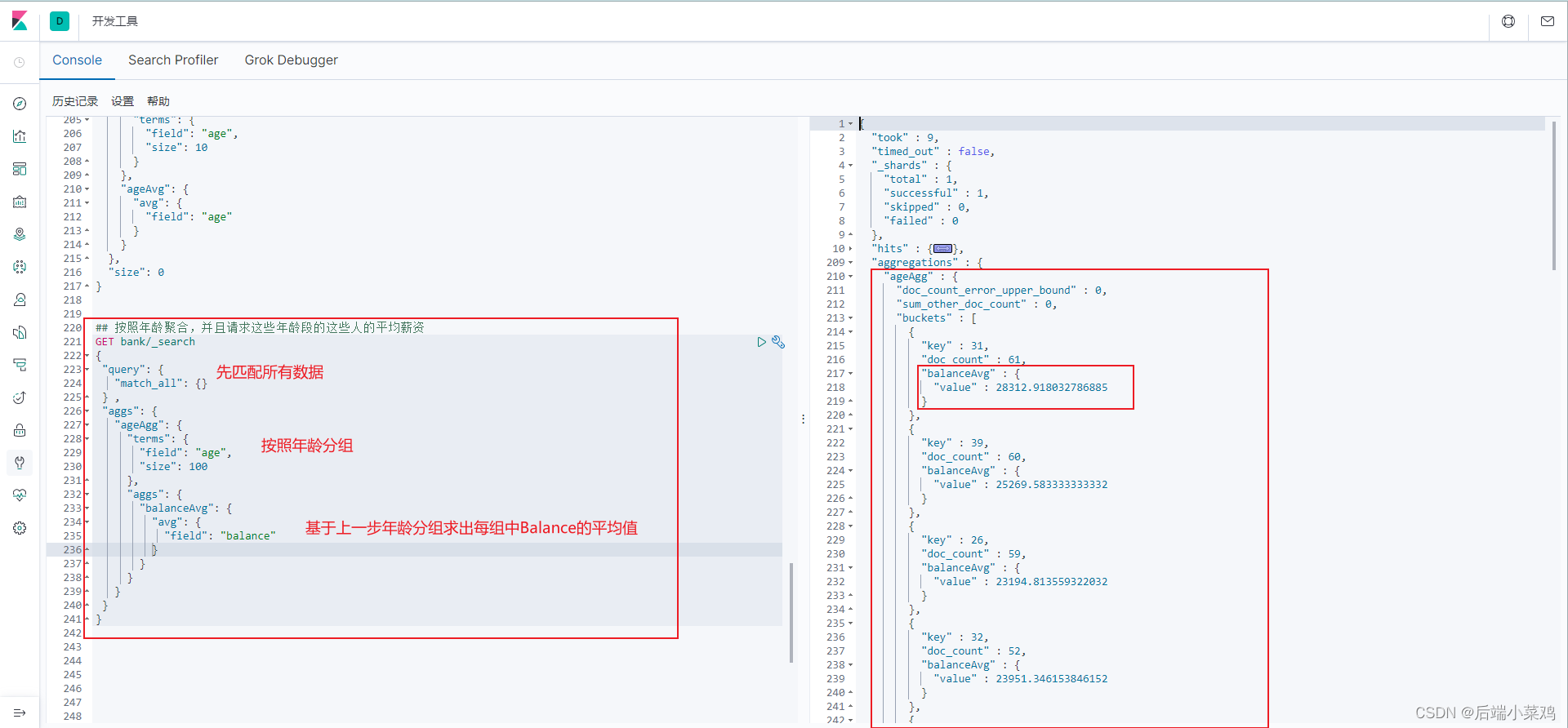
2、按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
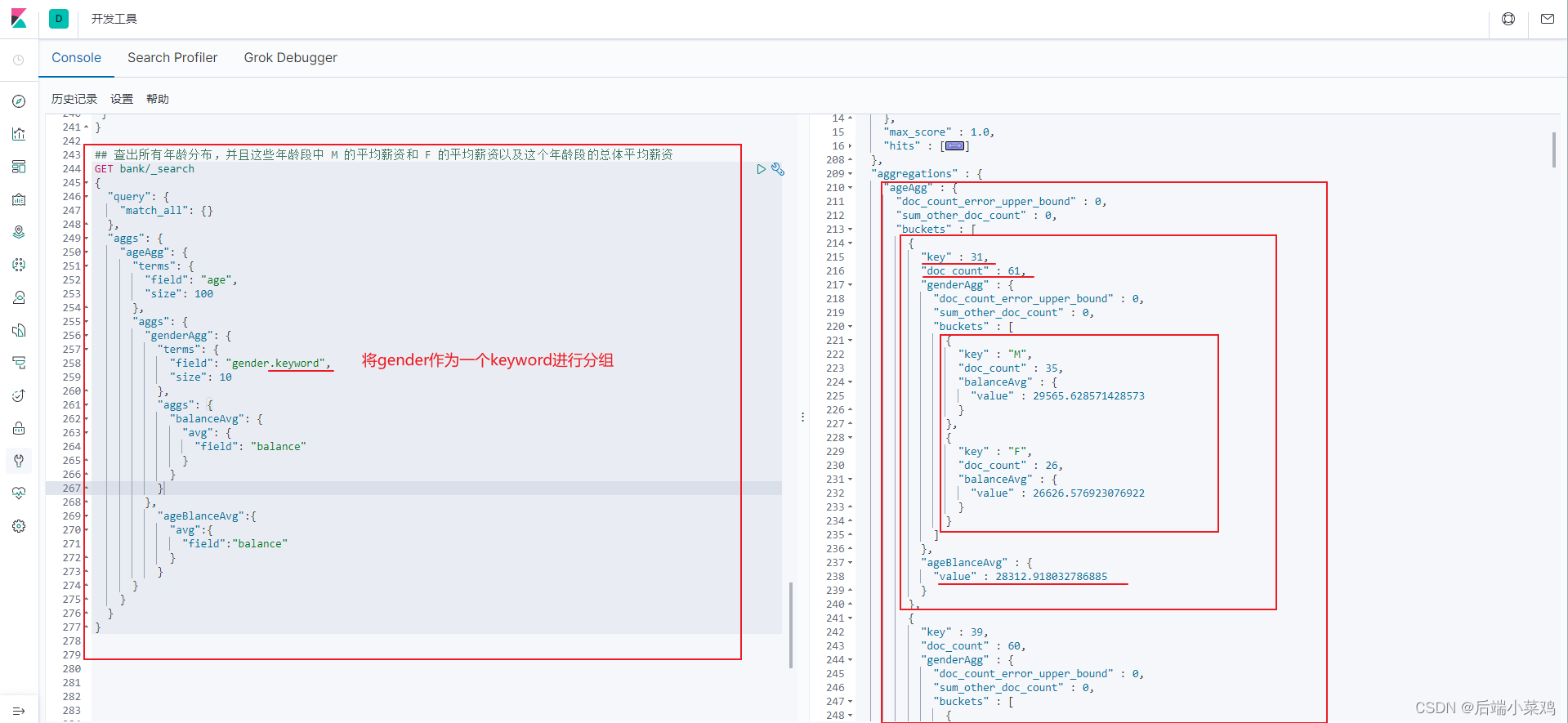
3、查出所有年龄分布,并且这些年龄段中 M 的平均薪资和 F 的平均薪资以及这个年龄段的总体平均薪资
 3、Mapping
3、Mapping
1)、字段类型

2)、映射
Mapping(映射) Mapping 是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和 索引的。比如,使用 mapping 来定义:
- 哪些字符串属性应该被看做全文本属性(full text fields)。
- 哪些属性包含数字,日期或者地理位置。
- 文档中的所有属性是否都能被索引(_all 配置)。
- 日期的格式。
- 自定义映射规则来执行动态添加属性。
- 查看 mapping 信息:
GET bank/_mapping
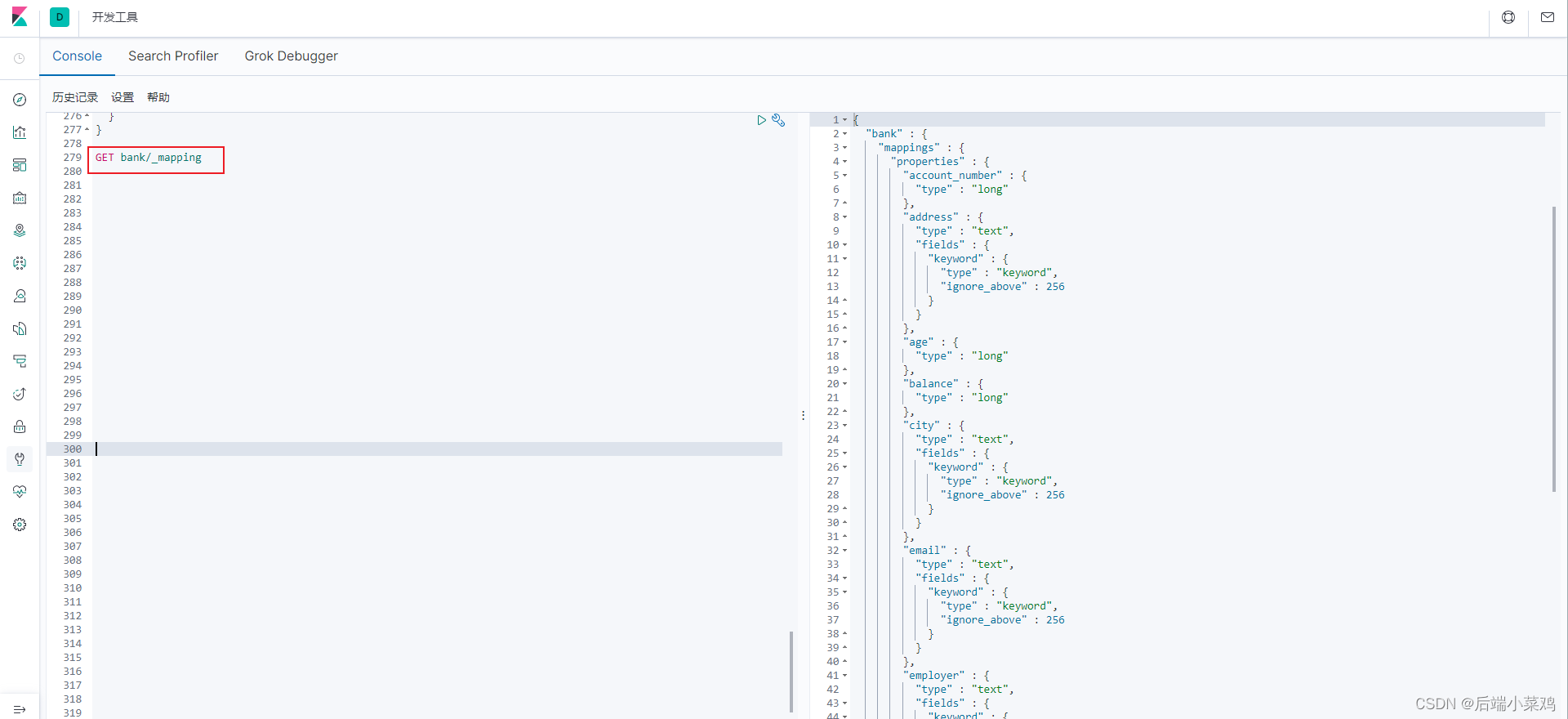 在创建文档时,es会根据数据自动猜测字段的数据类型。
在创建文档时,es会根据数据自动猜测字段的数据类型。
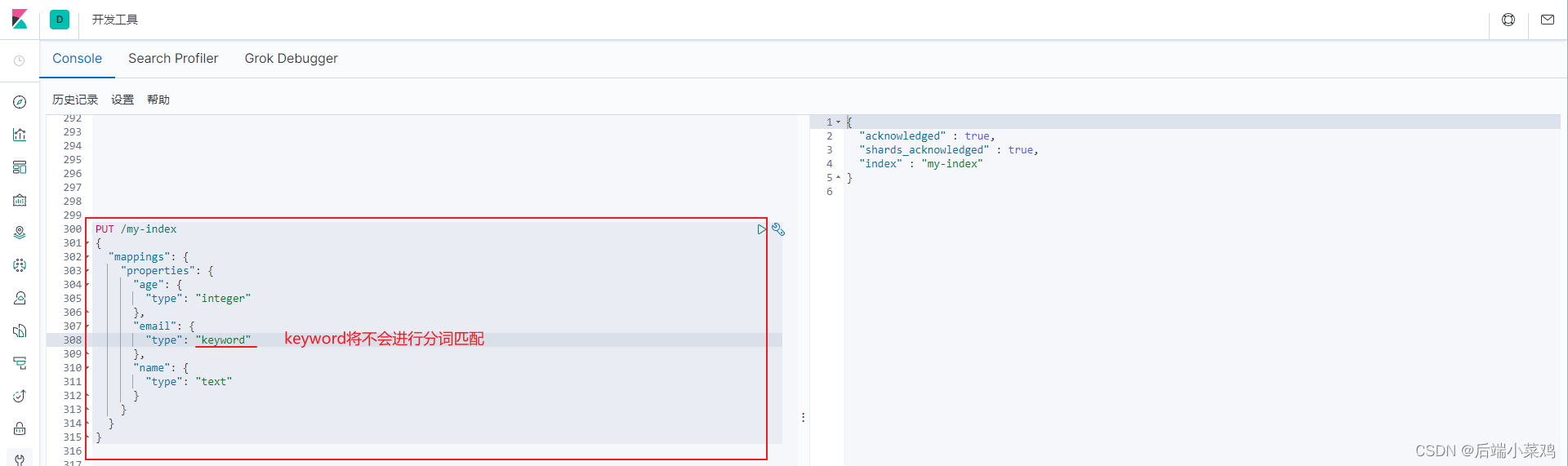
1、创建索引时指定映射
2、添加新的字段映射
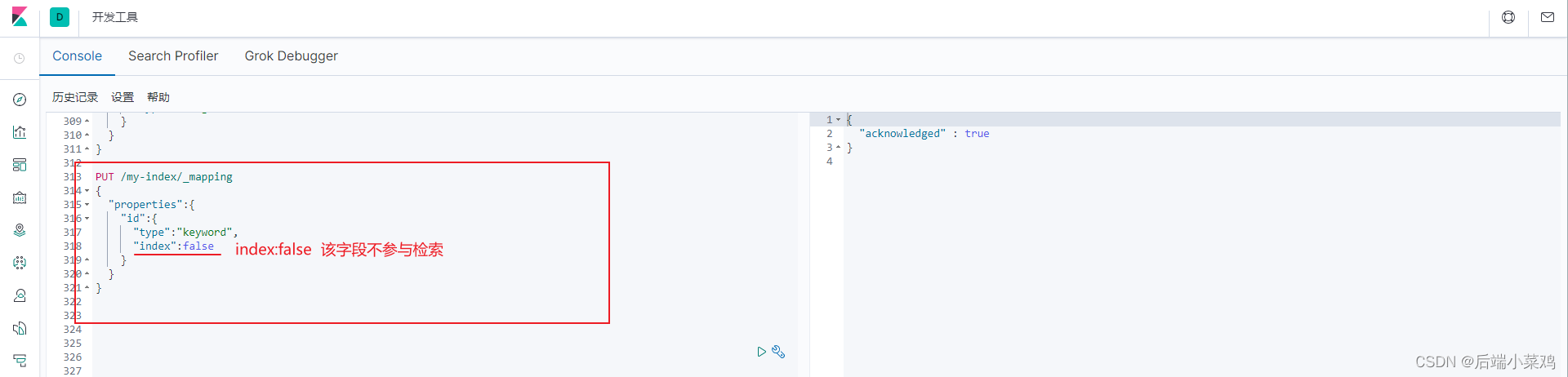
3、更新映射
对于已经存在的映射字段,我们不能更新。更新必须创建新的索引进行数据迁移
4、数据迁移
先创建出新索引的正确映射。然后使用如下方式进行数据迁移
POST _reindex [固定写法]
{
“source”: {
“index”: “twitter”
},
“dest”: {
“index”: “new_twitter”
}
}
## 将旧索引的 type 下的数据进行迁移
POST _reindex
{
“source”: {
“index”: “twitter”,
“type”: “tweet”
},
“dest”: {
“index”: “tweets”
}
}
1、创建新索引并正确指定映射
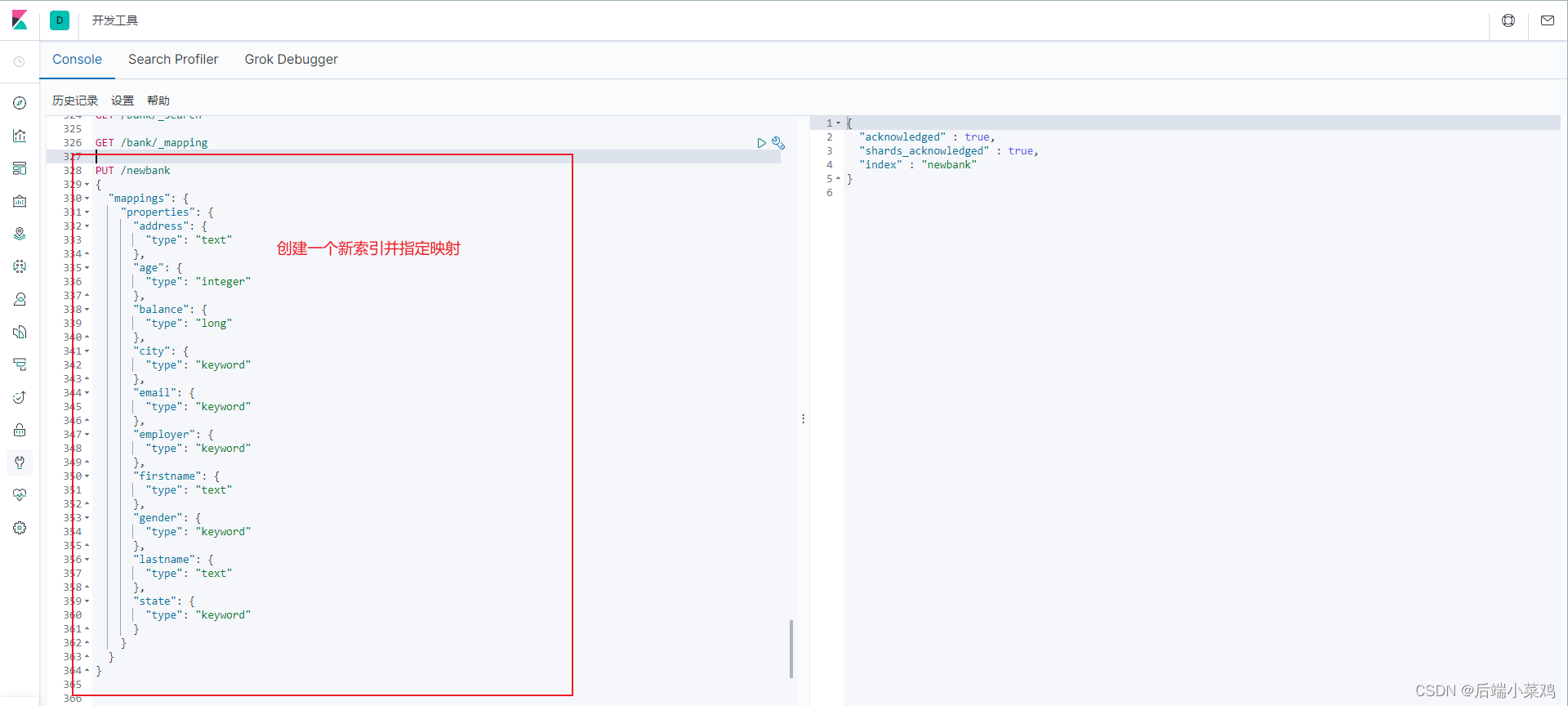
2、数据迁移
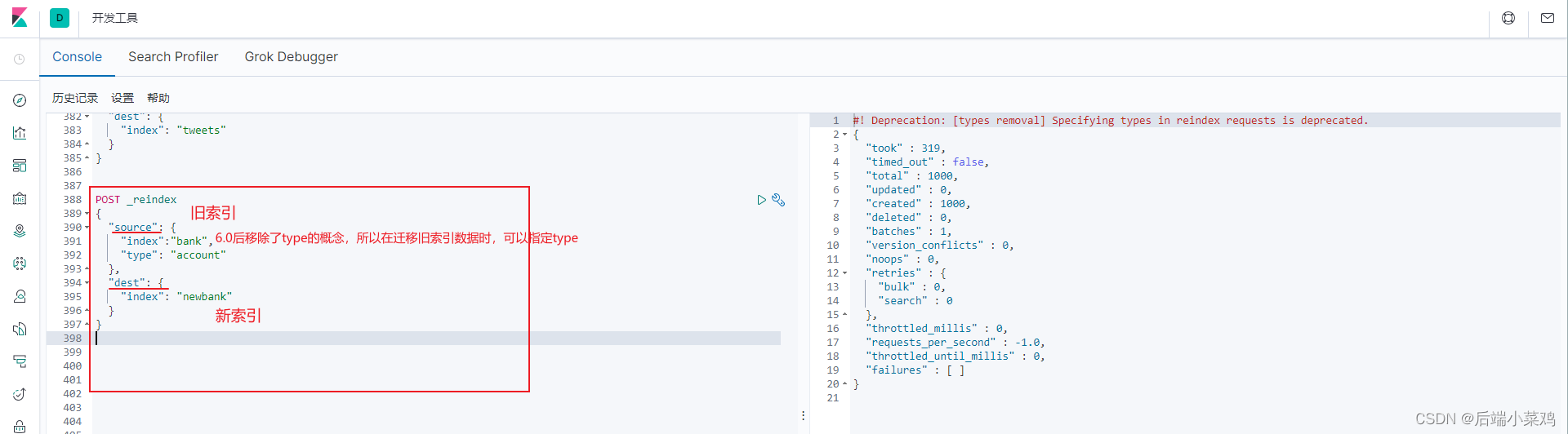
4.分词
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立 的单词),然后输出 tokens 流。 例如,whitespace tokenizer 遇到空白字符时分割文本。它会将文本 “Quick brown fox!” 分割 为 [Quick, brown, fox!]。 该 tokenizer(分词器)还负责记录各个 term(词条)的顺序或 position 位置(用于 phrase 短 语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的 start (起始)和 end(结束)的 character offsets(字符偏移量)(用于高亮显示搜索的内容)。 Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)。
测试分词
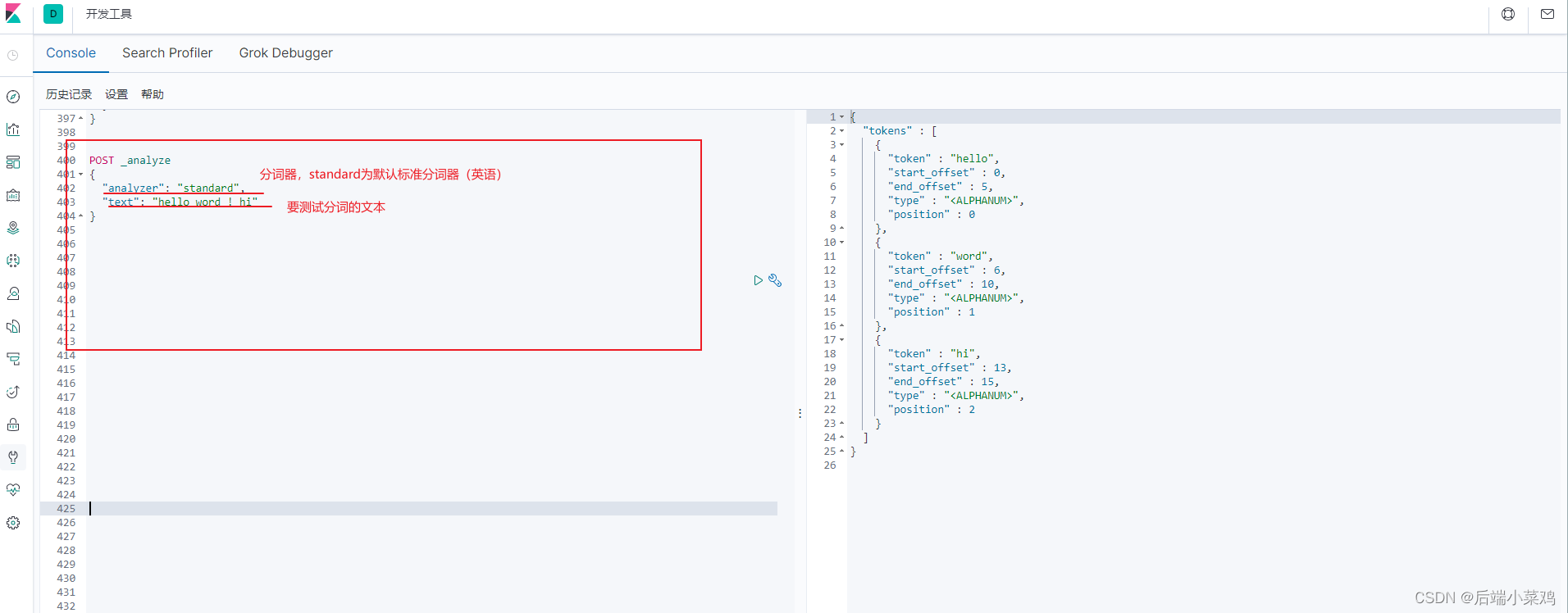
默认的标准分词器为英文分词,对于中文分词不友好,会将中文的每个字作为一个词元。
1)、安装 ik 分词
下载es对应版本的ik分词器
Release v7.5.0 · medcl/elasticsearch-analysis-ik · GitHub
进入es容器挂载的plugins文件夹,将下载好的ik分词器上传到该文件夹
使用unset 解压。
可以确认是否安装好了分词器 进入es容器内部,cd ../bin elasticsearch plugin list:即可列出系统的分词器
2)、测试分词器
1、使用默认的分词器
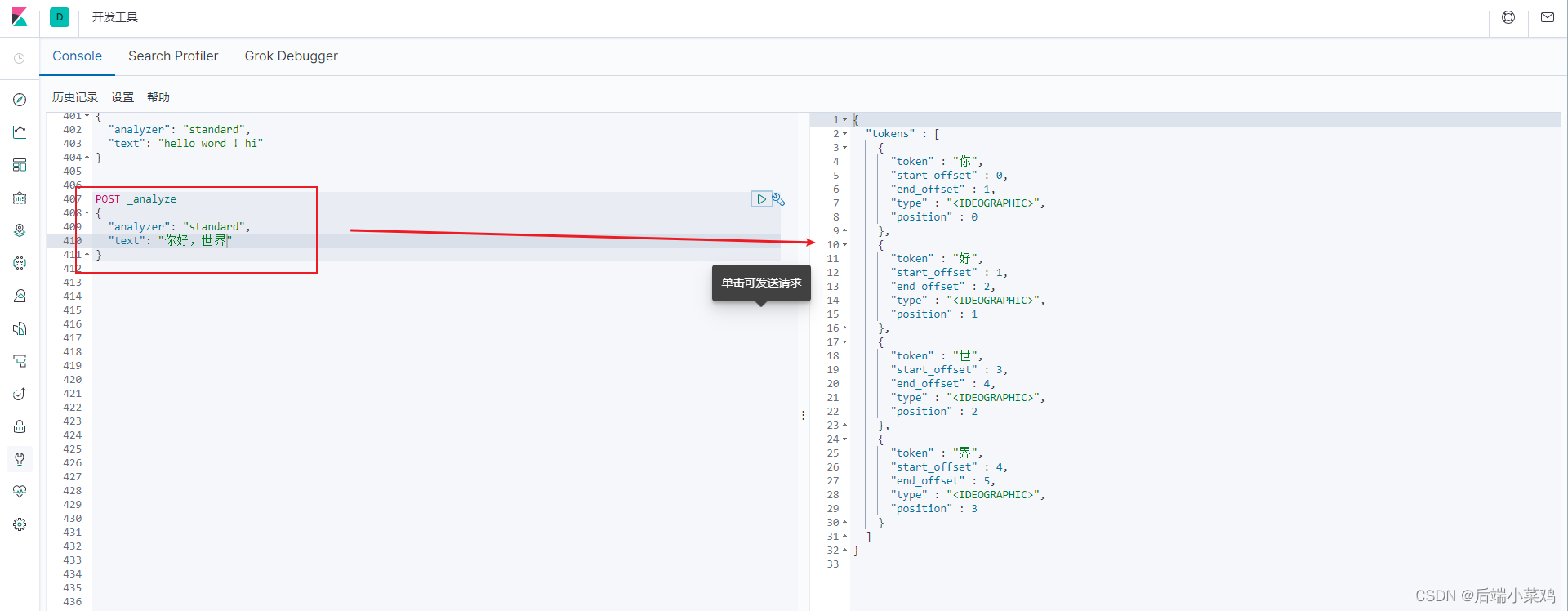
2、使用ik_smart
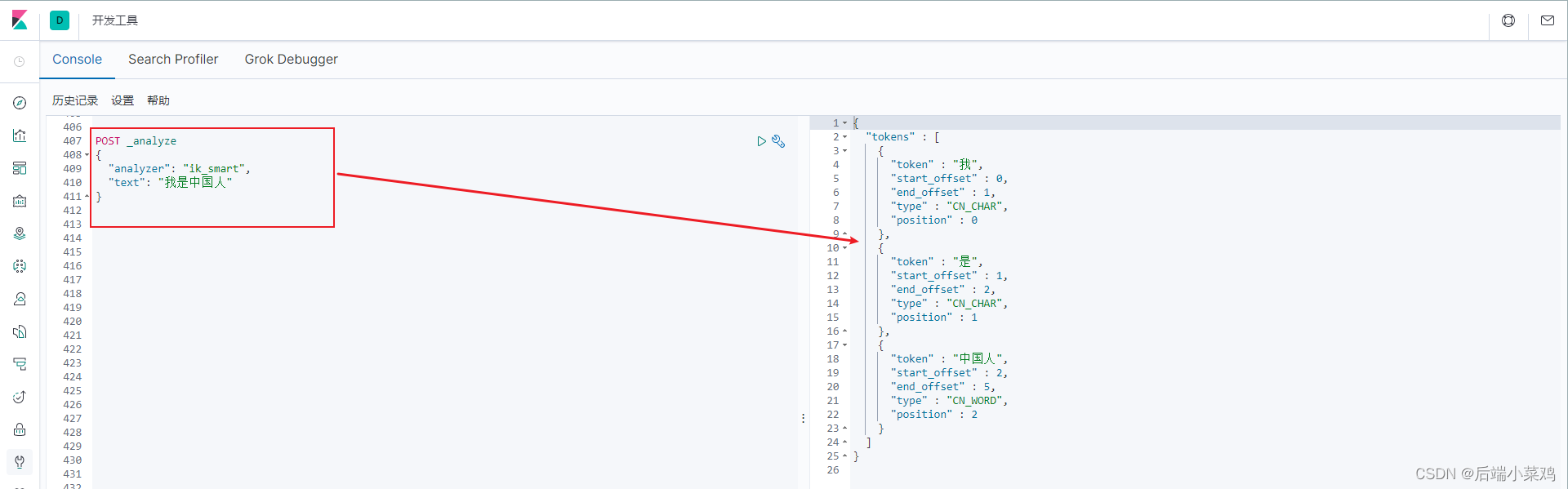 3、使用ik_max_word(最细粒度)
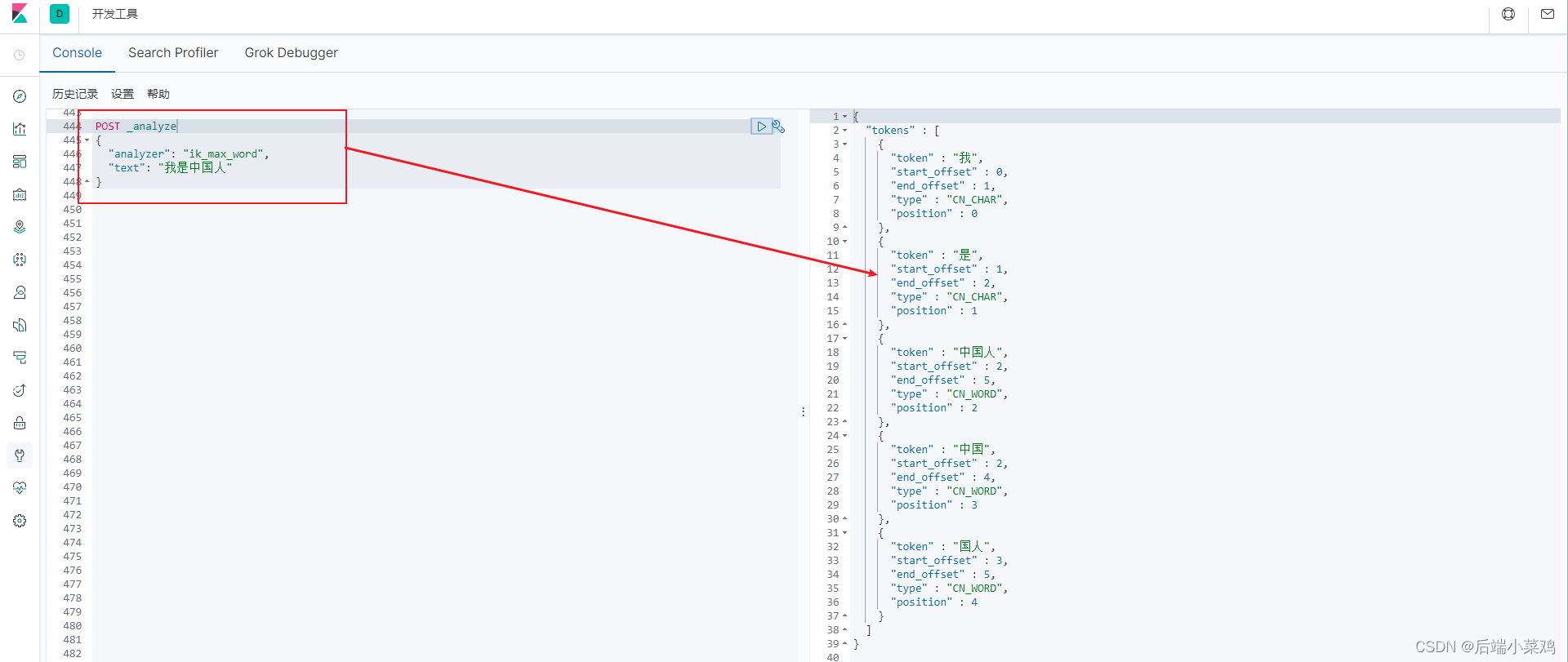
3、使用ik_max_word(最细粒度)
 3)、自定义词库
3)、自定义词库
1.安装nginx
- 随便启动一个 nginx 实例,只是为了复制出配置
docker run -p 80:80 --name nginx:1.10 # 没有这个镜像将会自动下载镜像- 将容器内的配置文件拷贝到当前目录:
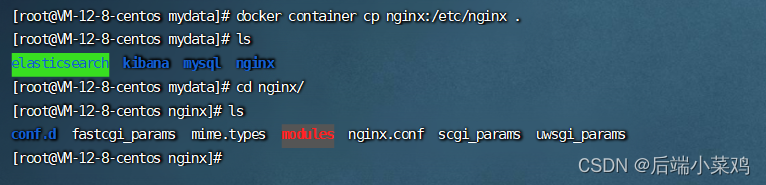
- 将刚刚拿到的配置文件放到 mydata/ngxin/conf 中
- 终止原容器:docker stop nginx
- 执行命令删除原容器:docker rm $ContainerId
- 创建新的 nginx;执行以下命令
docker run -p 80:80 --name nginx -v /mydata/nginx/html:/usr/share/nginx/html -v /mydata/nginx/logs:/var/log/nginx -v /mydata/nginx/conf:/etc/nginx -d nginx:1.10- 进入mydata/ngxin/html中新建es文件夹,在es文件夹中新建一个fengci.txt,并用Vi命令在里面添加一些词语。
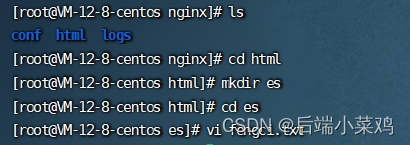

2.修改/usr/share/elasticsearch/plugins/ik/config/中的 IKAnalyzer.cfg.xml
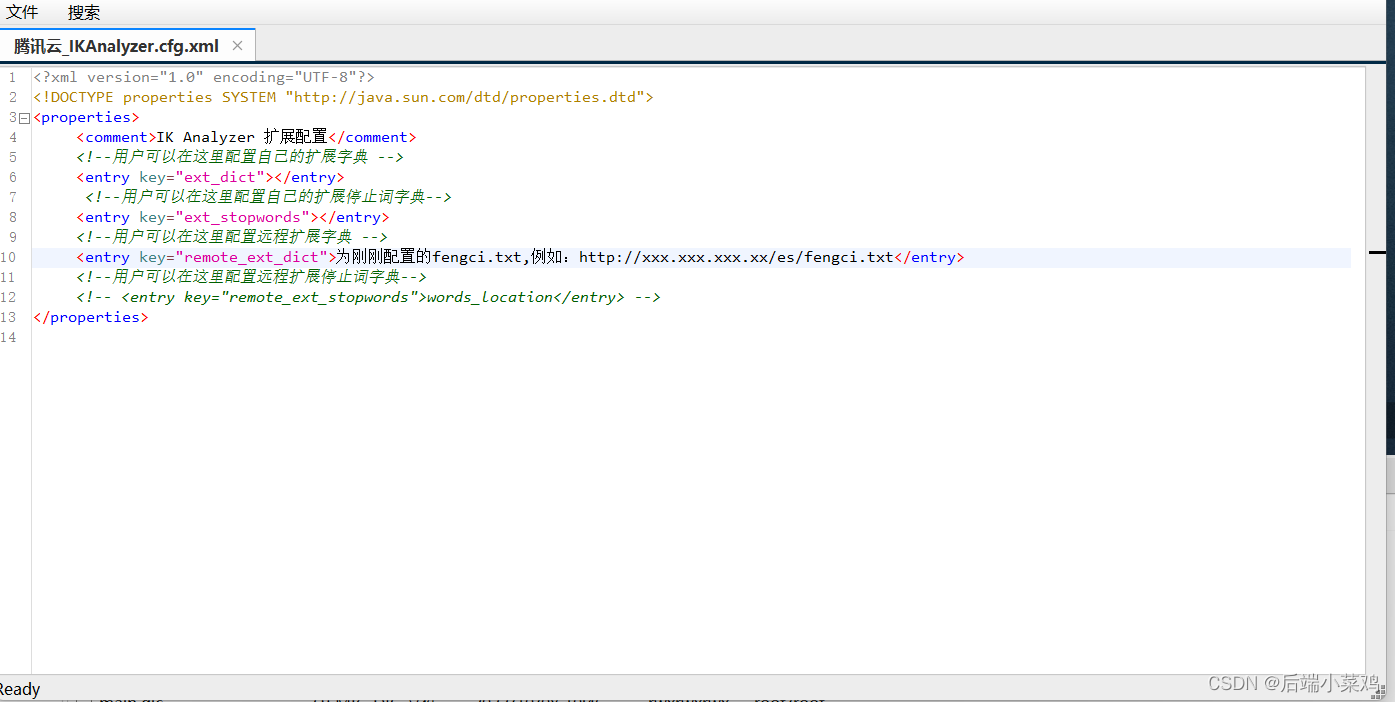
注意:这里的nginx地址要为nginx在容器中的地址:查询在容器中的ip
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' container_name_or_id
3.重启es
4.测试
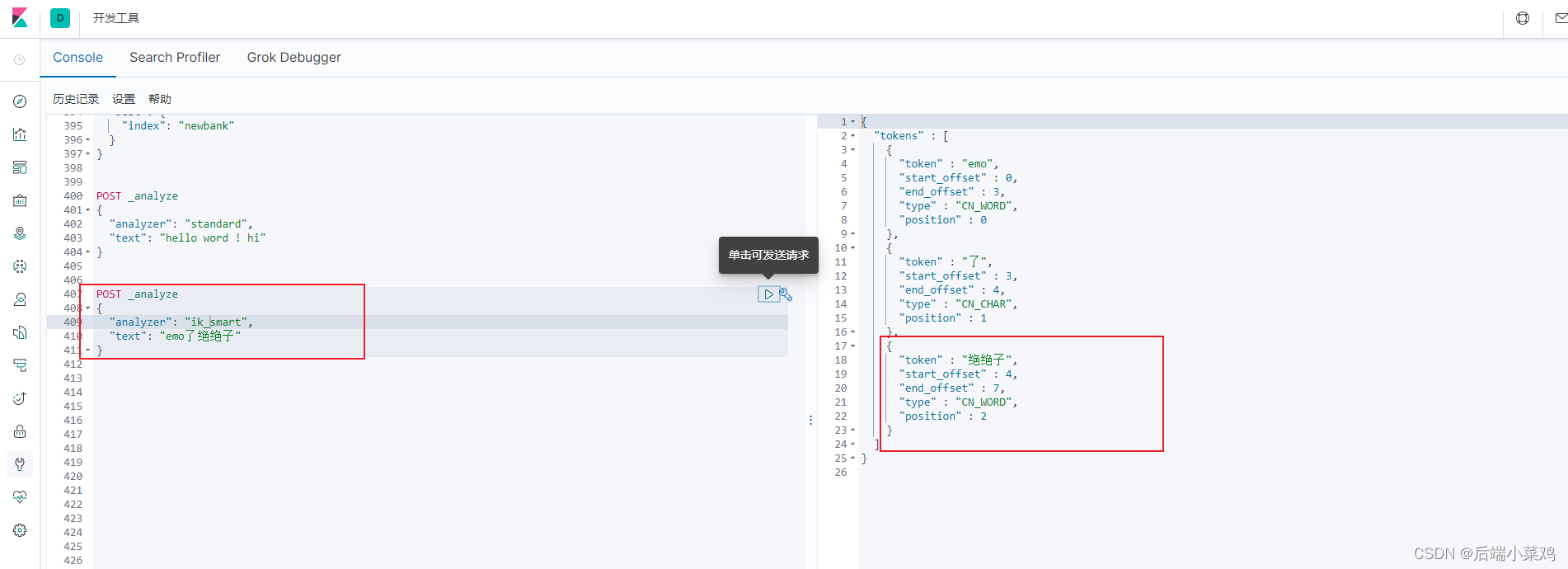
五、Elasticsearch-Rest-Client
1、SpringBoot 整合
1.导入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.5.0</version>
</dependency>2.新建配置类
package com.xxx.gulimall.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Configuration;
@Configuration
public class GulimallElasticsearchConfig {
public RestHighLevelClient esRestClient(){
RestClientBuilder builder = null;
builder = RestClient.builder(new HttpHost("xxx.xxx.xx.xx",9200,"http"));
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
}
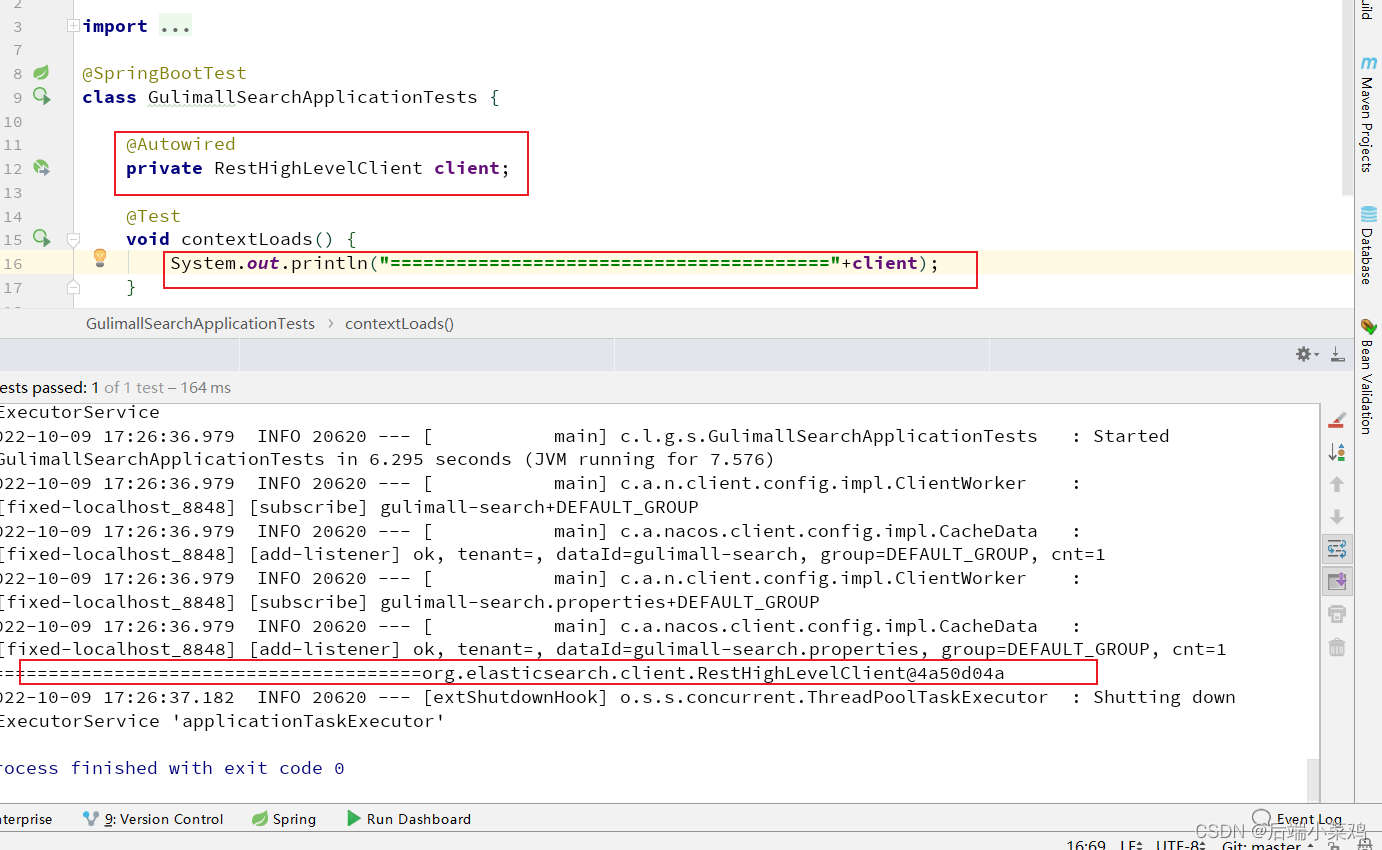
3.测试
4.测试保存索引至es
1.设置请求设置项
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class GulimallElasticsearchConfig {
// 设置请求设置项
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization", "Bearer " + TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient esRestClient(){
RestClientBuilder builder = null;
builder = RestClient.builder(new HttpHost("xxx.xxx.xx.xx",9200,"http"));
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
}2.测试代码
package com.liucan.gulimall.search;
import com.alibaba.fastjson.JSON;
import com.liucan.gulimall.search.config.GulimallElasticsearchConfig;
import lombok.Data;
import org.apache.catalina.User;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class GulimallSearchApplicationTests {
@Autowired
private RestHighLevelClient client;
@Test
void indexData() throws IOException {
IndexRequest indexRequest = new IndexRequest("users");
indexRequest.id("1"); //数据的id
// indexRequest.source("userName","zhangsan","age",18,"gender","男");
User user = new User();
user.setUserName("zhangsan");
user.setAge(18);
user.setGender("男");
String jsonString = JSON.toJSONString(user);
indexRequest.source(jsonString, XContentType.JSON); //要保存的内容
//执行操作
IndexResponse index = client.index(indexRequest, GulimallElasticsearchConfig.COMMON_OPTIONS);
//提取有用的响应数据
System.out.println(index);
}
@Data
class User{
private String userName;
private String gender;
private Integer age;
}
@Test
void contextLoads() {
System.out.println("========================================"+client);
}
}
响应:
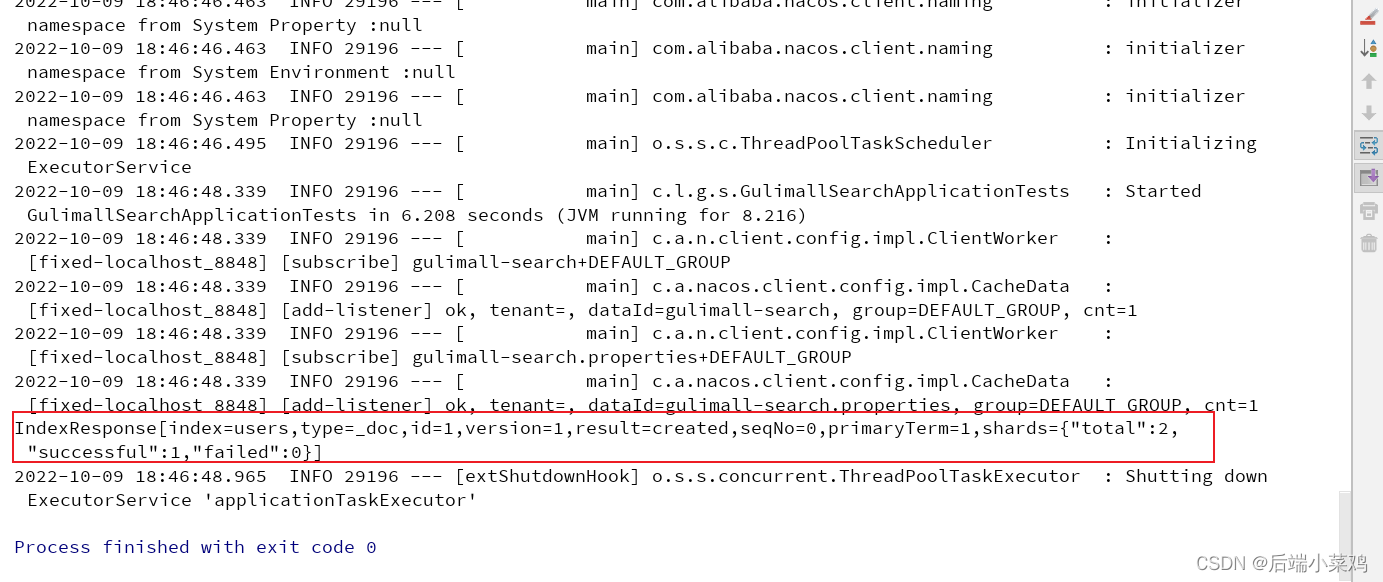
在kibana中查看:
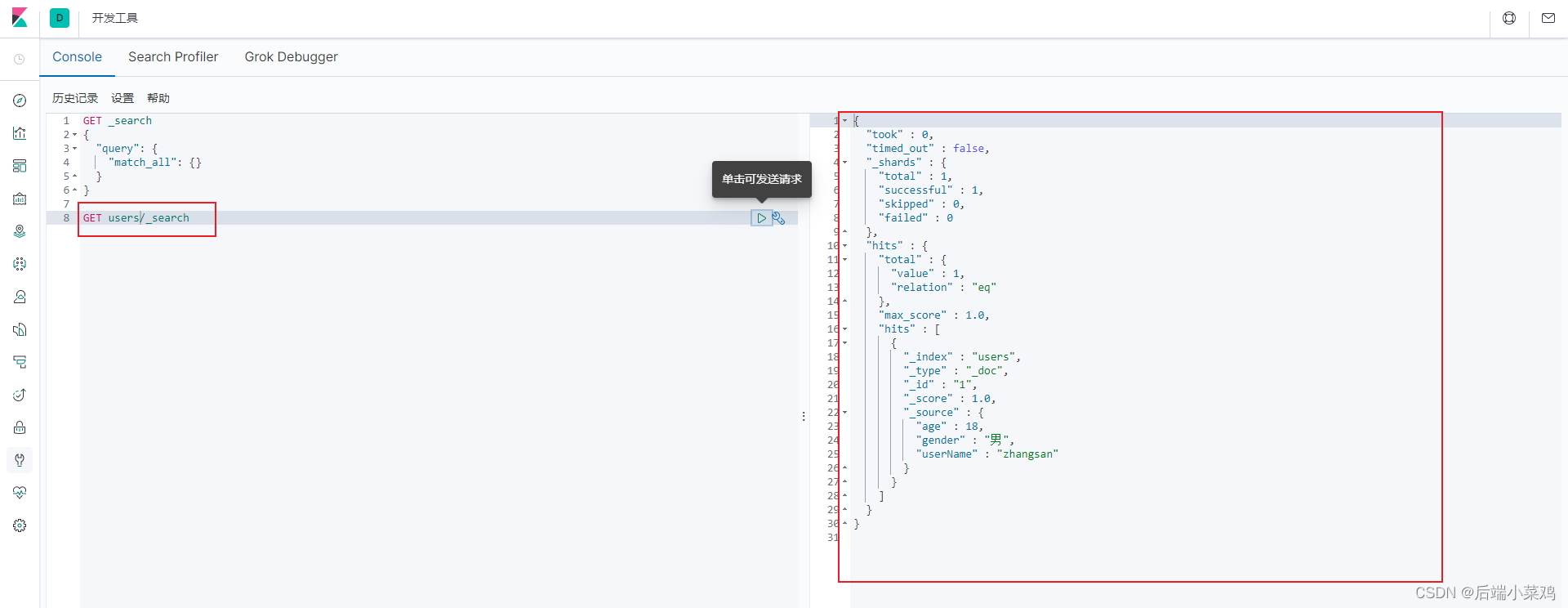 5.复杂检索
5.复杂检索
/**
* 复杂检索
* @throws IOException
*/
@Test
void searchData() throws IOException {
// 1、创建检索请求
SearchRequest request = new SearchRequest();
// 指定索引
request.indices("bank");
// 指定DSL 检索条件
SearchSourceBuilder builder = new SearchSourceBuilder();
// 1.1 构造检索条件
builder.query(QueryBuilders.matchQuery("address","mill"));
// 1.2按照年龄值分布进行聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
builder.aggregation(ageAgg);
// 1.3 balance平均值
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");
builder.aggregation(balanceAvg);
request.source(builder);
// 2、执行检索请求
SearchResponse search = client.search(request, GulimallElasticsearchConfig.COMMON_OPTIONS);
// 3、分析结果 search
System.out.println(search);
// 3.1 获取查询到的数据
SearchHits hits = search.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
String sourceAsString = hit.getSourceAsString();
Account account = JSON.parseObject(sourceAsString, Account.class);
System.out.println(account);
}
// 获取检索到的聚合信息
Aggregations aggregations = search.getAggregations();
Terms ageAgg1 = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageAgg1.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
System.out.println("年龄:"+keyAsString+"=====>"+bucket.getDocCount());
}
Avg balanceAvg1 = aggregations.get("balanceAvg");
double value = balanceAvg1.getValue();
System.out.println("balance平均值:"+value);
}结果:

六. 关于 nested 类型
- Object 数据类型的数组会被扁平化处理为一个简单的键与值的列表,即对象的相同属性会放到同一个数组中,在检索时会出现错误。参考官网:How arrays of objects are flattened
- 对于 Object 类型的数组,要使用 nested 字段类型。参考官网:Using nested fields for arrays of objects
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/154451.html

