


1、引入
参考上一节string中的存储,若将信息以json格式存储,以后频繁更新数据将会显得很笨重,将其拆分成多条数据后,又很冗余,如下图示意。
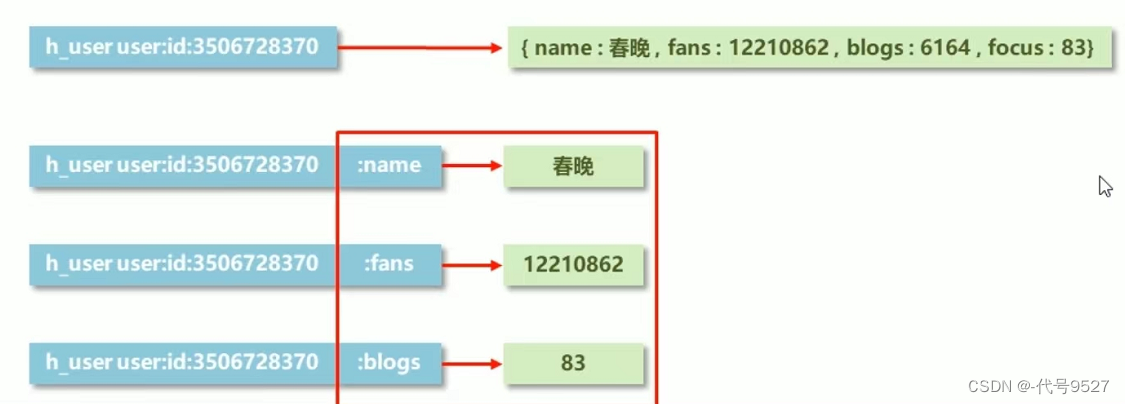
由此,考虑将右边的主键合一,右边将每个属性对上它的值。这样一个key不再对应一个单独数据,而是一堆数据。其中:属性name、fans、blogs称为field,右边这个结构就成为哈希。简言之一个redis中还有多个redis。
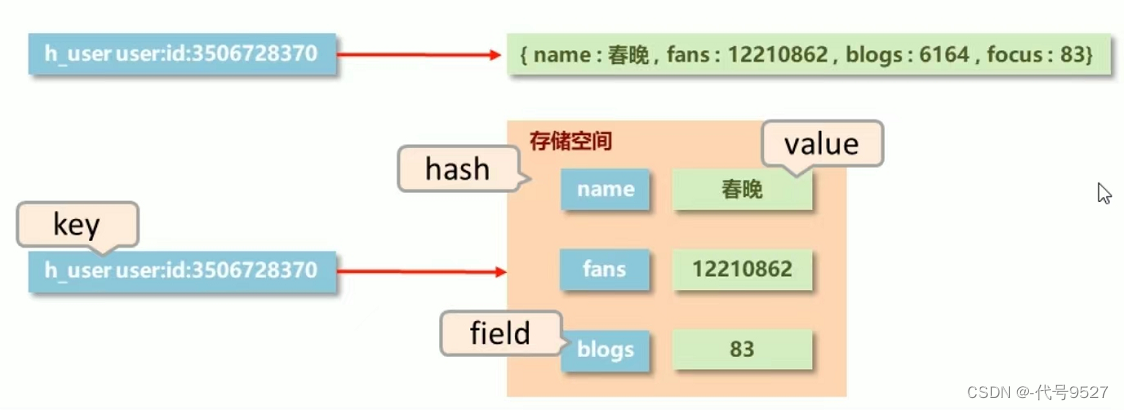
2、hash类型
- 一个存储空间保存多个键值对数据,典型应用于存储对象信息。
- hash类型底层使用哈希表结构来存储数据
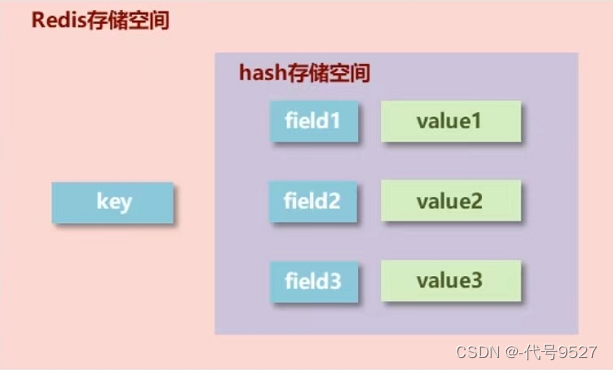
此外,hash存储结构优化:
如果field数量较少,存储结构优化为类数组结构。
如果field数量较多,存储结构使用HashMap结构。
3、hash 类型数据的基本操作
- 添加/修改数据
hset key field value- 只有在字段 field 不存在时,设置哈希表字段的值
hsetnx key field value- 获取数据
hget key field
hgetall key- 删除数据
hdel key field1 [field2]
类比string,hash类型可批量操作:
- 添加/修改多个数据
hmset key field1 value1 field2 value2 ……- 获取多个数据
hmget key field1 field2 ……- 获取哈希表中字段的数量,即field的数量
hlen key- 获取哈希表中是否存在指定的字段
hexists key field
举例:
127.0.0.1:6379> hset user name llg
(integer) 1
127.0.0.1:6379> hset user age 22
(integer) 1
127.0.0.1:6379> hset user sex man
(integer) 1
127.0.0.1:6379> hlen user
(integer) 3
127.0.0.1:6379> hexists user name
(integer) 1
4、hash 类型数据扩展操作
- 获取哈希表中所有的字段名或字段值
hkeys key
hvals key- 设置values增加指定大小
hincrby key field increment
hincrby key field increment
举例:
127.0.0.1:6379> hkeys user
1) "name"
2) "sex"
3) "age"
127.0.0.1:6379> hincrby user age 1
(integer) 23
注***
- hash类型下的values只能存储字符串,不存在嵌套现象或者其他数据类型。
- 每个hash最多存储 2^23 -1个键值对。
- hgetall可以获取全部属性,但当field过多时,遍历整体数据效率就很会低,反而与redis的初衷相悖。
5、hash类型的应用场景
场景一:电商购物车设计:
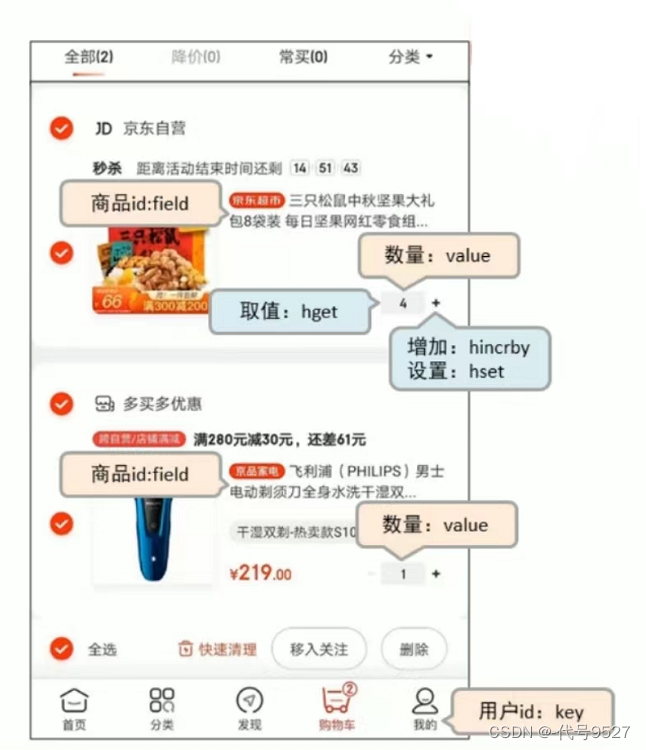
如上图,以用户id为key,每位客户创建一个hash存储其购物车信息,各商品id为field,数量为value。但这样其余商品信息(文字描述、图片、商家等等)需要二次查询数据库,所以将商品保存成两条field,field1保存数量,value存数字,field2存其余商品信息,value为一个json
127.0.0.1:6379> hmset User01 product1:num 4 product1:info {server:JingDong,desc:book,price:99$}
OK
127.0.0.1:6379> hgetall User01
1) "product1:num"
2) "4"
3) "product1:info"
4) "{server:JingDong,desc:book,price:99$}"
当User02也将product1加入购物车以后,关于产品信息的filed则是大量的重复数据
将商品信息抽离成一个独立的hash。
场景二:商品抢购
以商家id为key,参与抢购的商品id为field,抢购的商品数量做为value,使用hincrby和-1控制剩余产品数量
127.0.0.1:6379> hmset PDD proudcut01 1000 product02 2000 product03 1500
OK
127.0.0.1:6379> hincrby PDD product02 -100
(integer) 1900
至此:
相比string存储对象和hash存储对象,string读更便利,频繁该数据则不便;hash因为引入了属性field,改数据则更加方便。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/146174.html

