
整理下事务相关的知识点:
一、事务
先复习下数据库中学到的事务:
MySQL事务
一个事务即一个完整的业务逻辑,如A账户向B账户转10000,则A-10000,B+10000,以上操作是一个最小的工作单元,要么同时成功,要么同时失败。两个update同成功或同失败,才能保证业务的正确性。
- 只有DML语句(insert、delete、update)才有事务一说,其余SQL与事务无关
- 整个业务只需一条SQL完成时,事务机制也就没必要了
- 事务,本质就是多条DML语句同成功或同失败,这多条DML对应一个业务
事务的实现
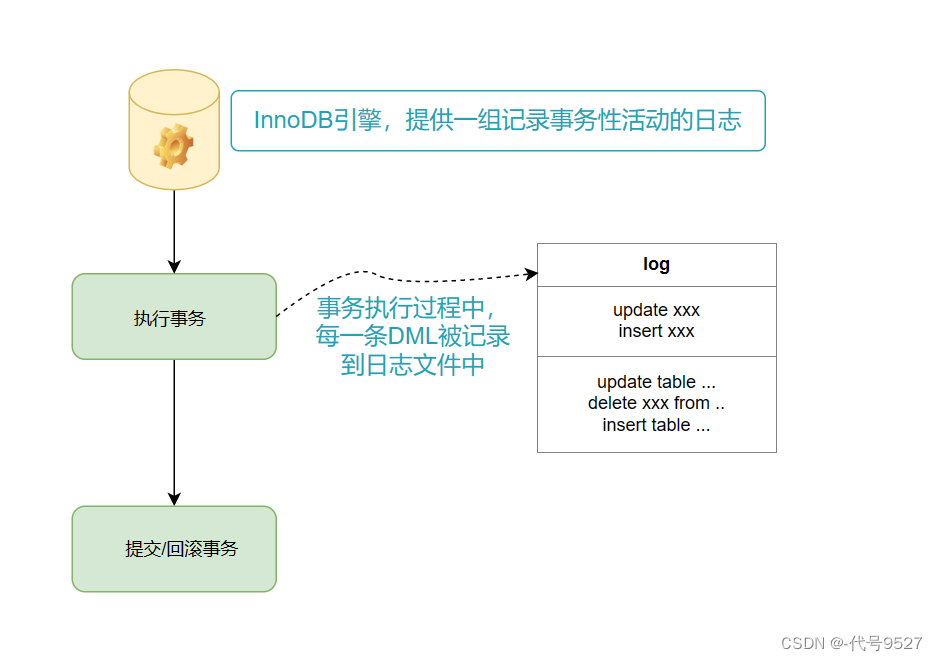

提交事务commit:
- 清空对应事务性活动的日志文件,将数据全部持久化到数据库表中
- 事务提交标志着事务的结束,且是一种全部成功的结束
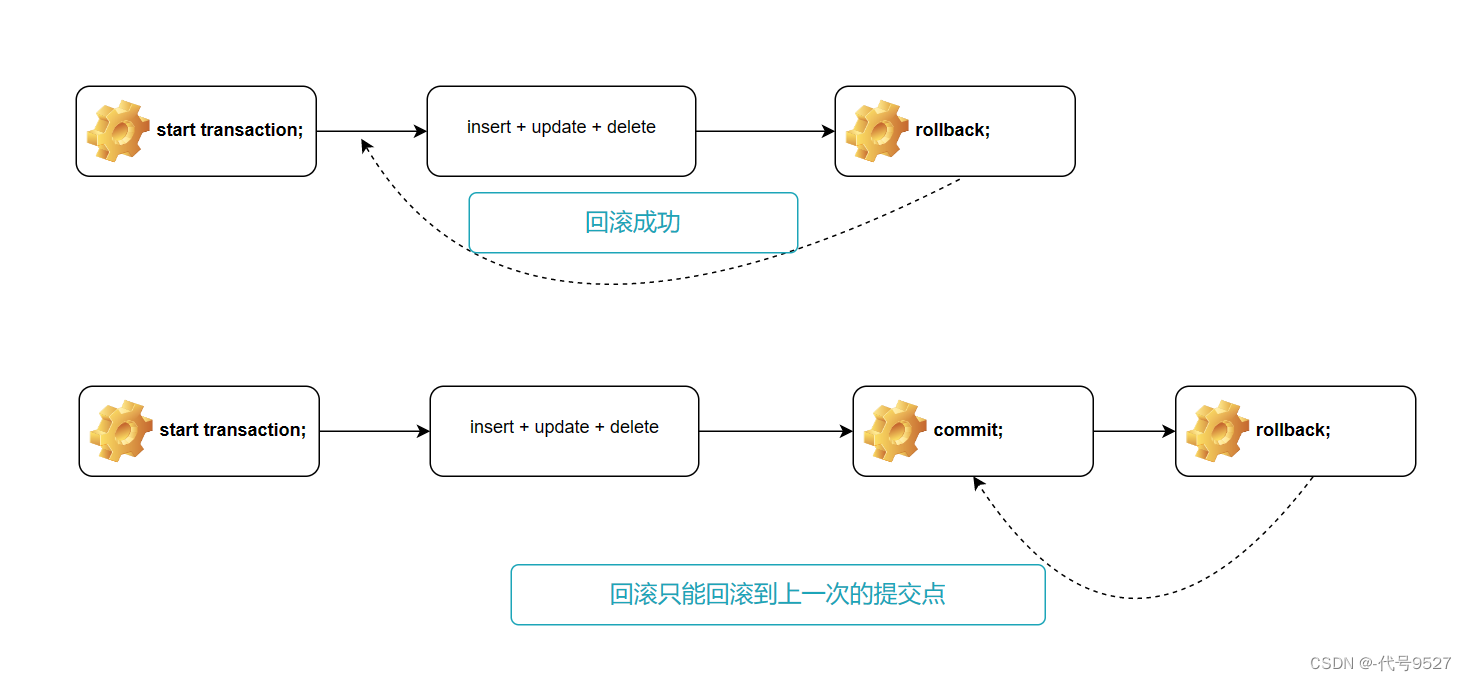
回滚事务rollback:
- 将之前所有的DML操作全部撤销,然后清空事务性活动的日志文件
- 回滚事务标志着事务的结束,且是一种全部失败的结束
MySQL默认自动提交事务,即每执行一条DML,就提交一次,此时无法回滚。start transaction;即开启事务(也就是关闭自动提交)
事务的ACID特性
- A:原子性,说明事务是最小的工作单元,不可再分
- C:一致性,在统一事务中,所有操作要么同成功、要么同失败
- I:隔离性,A事务和B事务之间具有一定的隔离(具体往下看),A事务在操作一张表的时候,B事务也可以操作这张表
- D:持久性,事务提交,就相当于将没有保存到硬盘上的数据存到了磁盘
事务的隔离级别
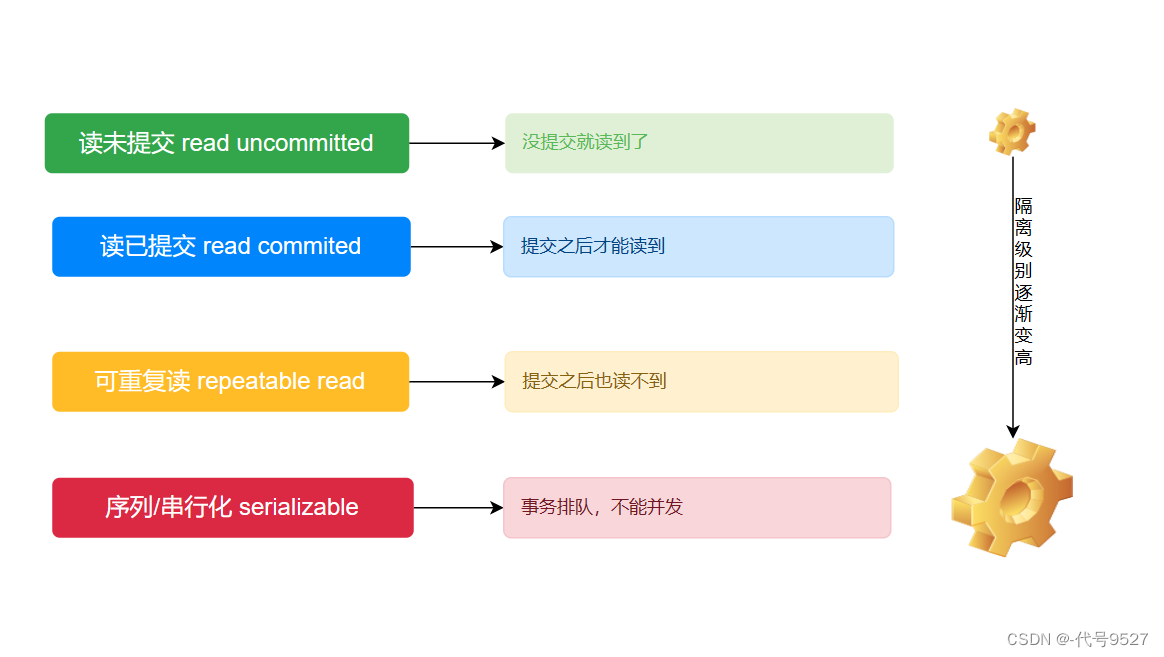
当事务A和事务B同时操作表table:
-
读未提交:
事务A可以读到事务B未提交的数据,隔离级别最低,存在脏读现象(Dirty Read),即读到了脏数据 -
读已提交:
事务A只能读到事务B提交后的数据,这解决了脏读问题,但有新问题就是不可重复读取数据。如事务开启后,第一次读到3条数据,一会儿后,当前事务还未结束,并且又读了一遍,可能读到4条,两次不一致即不可重复读取。这是Oracle默认的级别。 -
可重复读
事务A开启后,不管过多久,每一次在事务A中读到的数据中都是一致的,即使在操作同一张表的事务B将表中的数据修改并且提交,A读到的数据还是刚开始的数据。这个级别解决了不可重复读取的问题,但出现幻影读,即每次读到的数据都是幻想,不一定真实,永远读取的都是刚开启事务时的数据(对开启事务时的数据做了备份或快照,然后读备份),这是Mysql的默认级别。 -
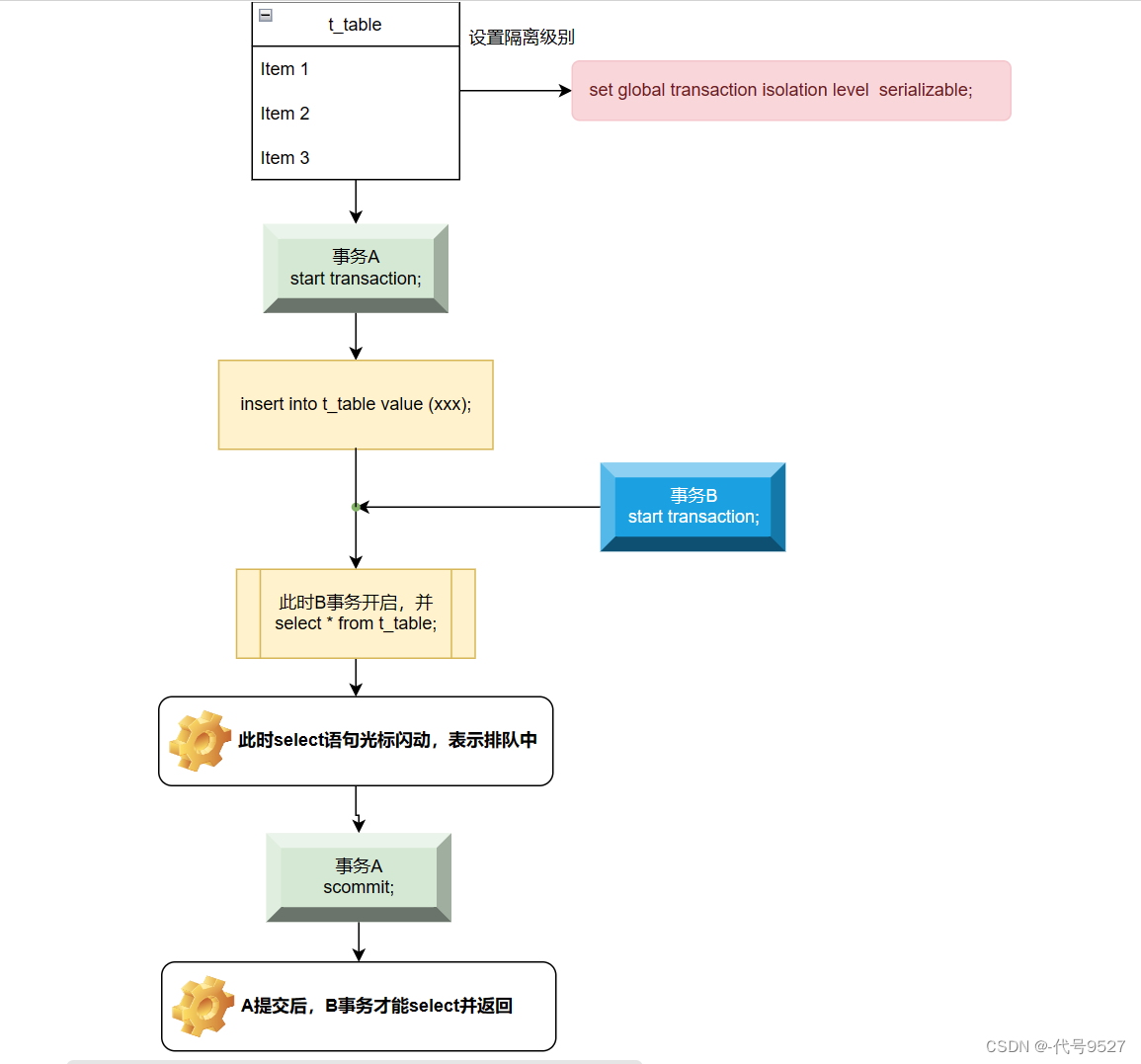
序列化/串行:
最高级别,事务排队,不能并发,每一次读到的数据都是最真实的,但效率最低。图示:
- 查看隔离级别
select @@transaction_isolation;
select @@tx_isolation;
show variables like 'transaction_isolation';
- 设置隔离级别为读未提交
set global transaction isolation level read uncommitted;
二、本地事务
整个服务操作只能涉及一个单一的数据库资源,这类基于单个服务单一数据库资源访问的事务,被称为本地事务

三、分布式事务
认识分布式事务
本地事务的情况下,所有数据都会落到同一个DB中,但是,在分布式的情况下,就会出现数据可能要落到多个DB,或者还会落到Redis,落到MQ等中。
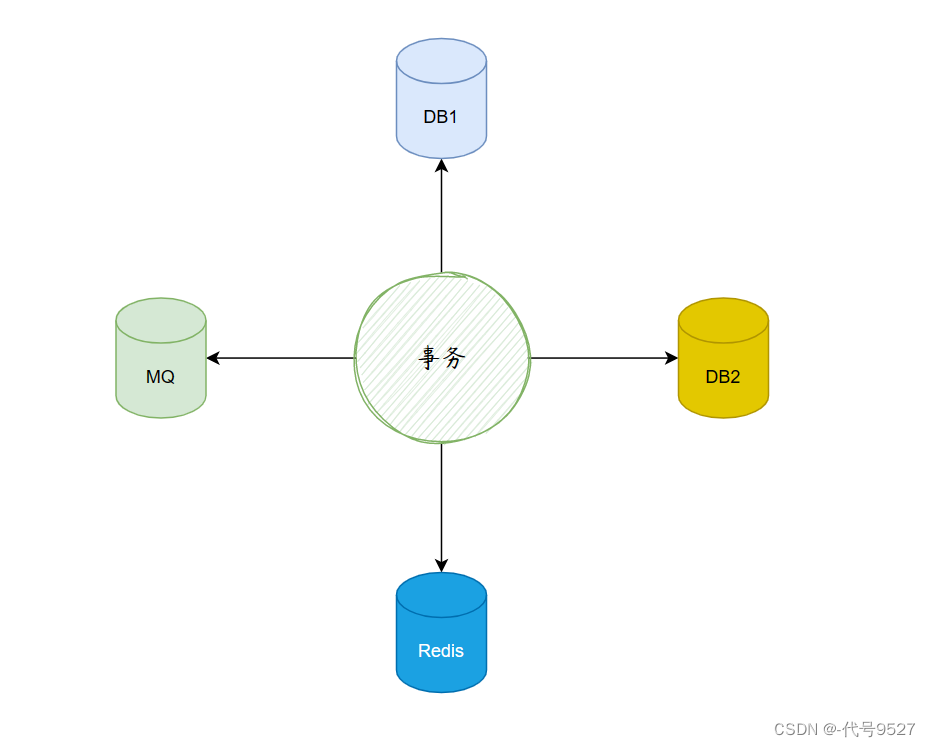
分布式事务,即一个事务的完成需要多个服务的协调与网络通信,此时要保证不同数据库的数据一致性(同失败或同失败)。
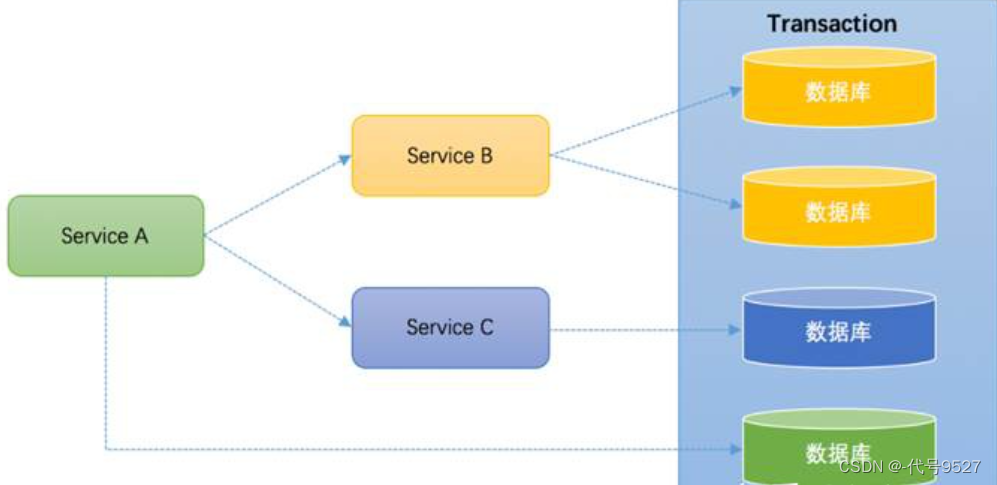
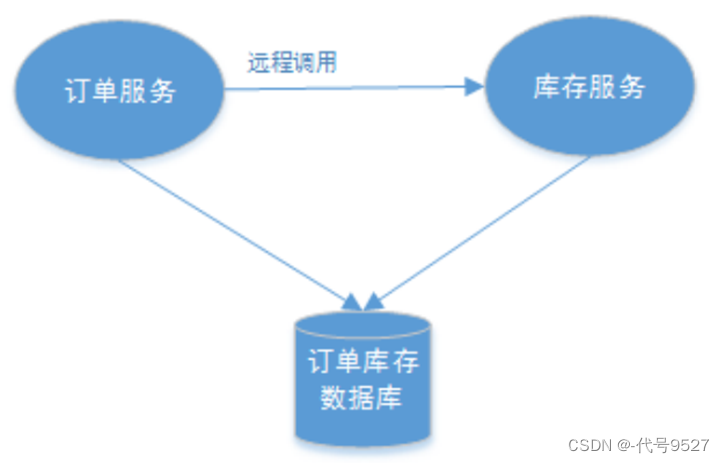
细分举例:
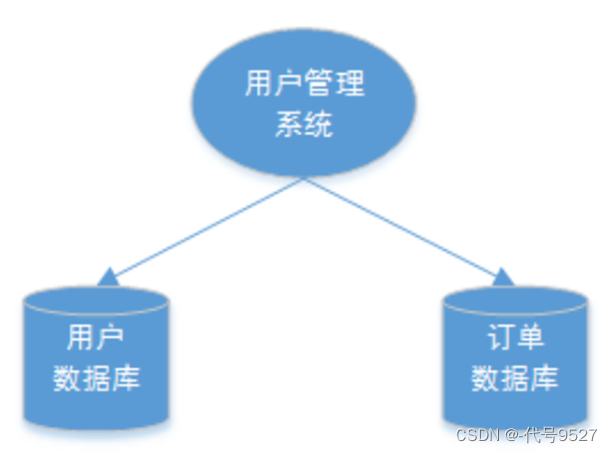
-
单服务多数据库
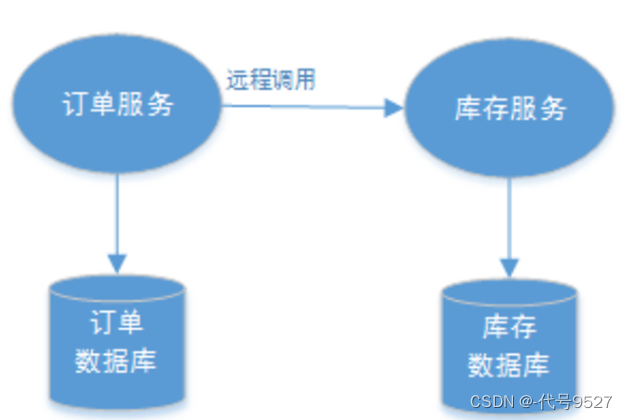
-
一个服务操作需要调用另外一个服务
CAP理论
相比于数据库事务或本地事务中的ACID,分布式事务有CAP理论:
- C:Consistency,一致性
- A:Availability,可用性
- P:Partition tolerance,分区容忍性
使用下图中的简单分布式系统结构来阐述C、A、P:客户端经过网关访问用户服务的两个结点(对应有两个库)
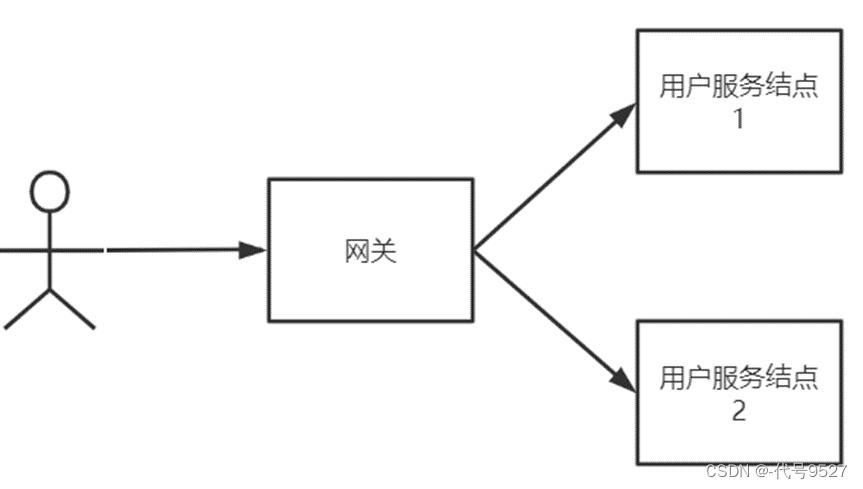
- 一致性:用户不管访问哪一个结点拿到的数据都是最新的
- 可用性:指任何时候查询用户信息都可以查询到结果,但不保证查询到最新的数据
- 分区容忍性:也叫分区容错性,当系统采用分布式架构时由于网络通信异常导致请求中断、消息丢失,系统依然能对外提供服务
CAP理论即在分布式系统中C、A、P三点不可能全部满足。
比如:添加用户小明的信息,信息先添加到节点1,再同步到节点2:
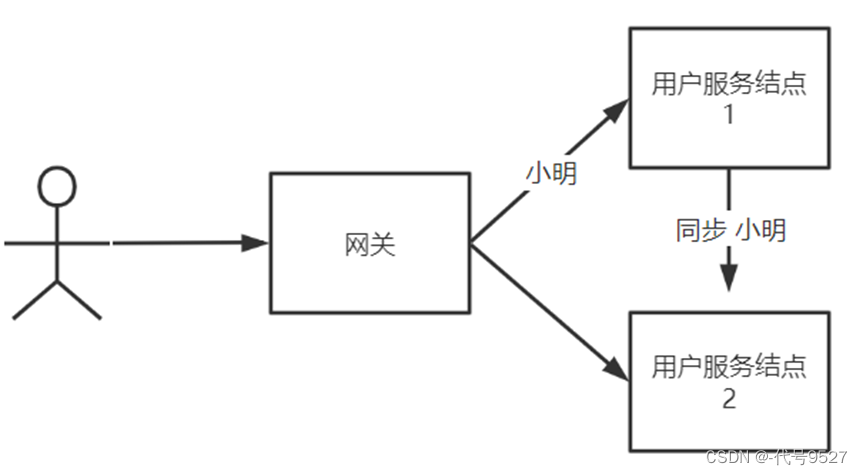
- 为满足C一致性,就要等小明的信息同步到节点2,此时可用性没了
- 要可用性A,此时不用等小明的信息同步到节点2,但一致性就没了
所以在分布式系统中进行分布式事务控制,要么保证CP、要么保证AP。要根据你的实际需求来确定选CP还是AP,然后再根据选择来进行技术选型。
CP场景:(追求数据一致性,舍弃A)
跨行转账:一次转账请求要等待双方银行系统都完成整个事务才算完成,只要其中一个失败另一方执行回滚操作。此时应该追求一致性。
AP场景:(强调可用性,舍弃C)
订单退款:今日退款成功(先告诉你成功了),明日账户到账(数据后续完成一致性),只要用户可以接受在一定时间内到账即可
AC:放弃分区容错性的话,则放弃了分布式,失去初衷了就,不做考虑
BASE理论
上面的AP,虽说舍弃C,但并不是不要求数据一致性,数据最终也会一致,只是不要求立即一致,实际上最终数据还是达到了一致。因此出现BASE理论:
- Basically Available(基本可用):当系统无法满足全部可用时保证核心服务可用即可
- Soft state(软状态):是指可以存在中间状态,比如:打印自己的社保统计情况,该操作不会立即出现结果,而是提示你打印中,请在XXX时间后查收
- Eventually consistent (
最终一致性):退款操作后没有及时到账,经过一定的时间后账户到账,舍弃强一致性,满足最终一致性
在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证最终一致性。
关于AP的实现思路,可以采用 本地消息表+任务调度机制完成分布式事务最终数据一致性的控制。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/146055.html

