
何谓算法分析
首先,算法的本质就是解决问题的方案。算法通过程序来实现。程序存在优劣之分,算法分析关心的是基于所使用的计算资源比较算法。
计算资源指什么?
- 空间与内存
- 执行时间
产生一个问题
- 在描述算法的执行时间,指标是实际时间,但这个时间依赖于计算机、程序、时间、编辑器、编辑语言等众多因素,所以我们需要找到一个独立于程序或计算机的指标。===》大O记法
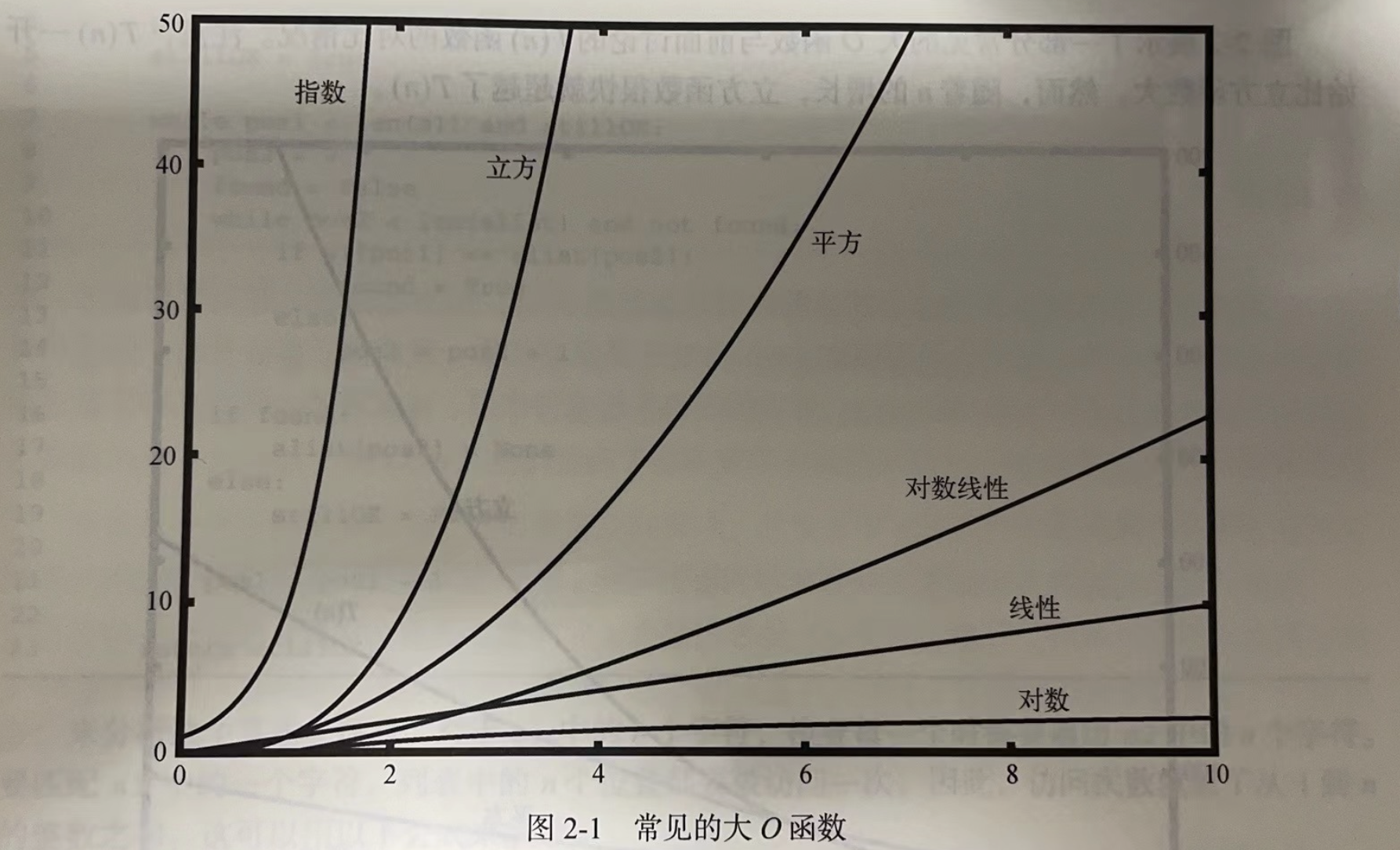
大O记法
量化算法的操作或步骤。
引入
对于累加算法,计算总和所用的赋值语句的数目就是一个很好的基本计算单位def my_sum(n): num = 0 for i in range(1, n + 1): num += i return num print(my_sum(6)) # 21这里对该算法进行抽象T(n) = n + 1,其中n为问题规模,规模越大1,对T(n)的影响就越小。
大O记法
- 随着n问题规模越来越大,T(n)中n的增长速度最快,所以将1舍弃,直接说执行时间是O(n),大O记法就是指数量级(这里的O是order)
- 再举个例子:T(x) = 5x^2+27x+1024 随着x的的增大,x^2越来越重要,所以说O(x^2)
异序词检测示例
问题:编写一个布尔函数,接受两个字符串,判断他们是否是异序词。
- 异序词:一个字符串重排了另一个字符串的字符,比如earth与heart就是一对异序词。
清点法
- 每走一个s1字符,s2列表都会遍历n下,因此访问就成了1到n求和。最后时间复杂度为O(n^2)
def func(s1, s2):
alist = list(s2)
pos1 = 0
stileOK = True
while pos1 < len(s1) and stileOK:
pos2 = 0
found = False
while pos2 < len(alist) and not found:
if s1[pos1] == alist[pos2]:
found = True
else:
pos2 += 1
if found:
alist[pos2] = None
else:
stileOK = False
pos1 += 1
return stileOK
print(func("abc", "cba")) print(func("abc", "acdb"))
排序法
- 排序法就是先将s1、s2转化为两个列表,在通过sort内置方法排序,再依次比较两个列表相同索引对应的值。
- 关注的点,并不是表面上遍历两个列表,时间复杂度为O(n),而是sort的复杂度基本上在O(n^2),so,决定作用的反倒是排序了,复杂度为O(n^2)
蛮力法
- 就异序词检测而言,可以用s1中的字符生成所有可能的字符串,看看s2是否在其中,而穷举这些可能就是O(n!),复杂度随n的增大,爆炸式升高。
计数法
- 两个异序词有同样数目的a、同样数目的b…,要判断两个词是否为异构词,先数下每个字符出现的次数。
def func(s1, s2):
c1 = [0] * 26
c2 = [0] * 26
for i in range(len(s1)):
pos = ord(s1[i]) - ord('a')
c1[pos] += c1[pos]
for i in range(len(s2)):
pos = ord(s2[i]) - ord('a')
c2[pos] += c2[pos]
j = 0
stileOK = True
while j < 26 and stileOK:
if c1[j] == c2[j]:
j += 1
else:
stileOK = False
return stileOK
Python数据结构的性能
主要比较列表与字典在做一些操作时的损耗与收益,涉及到性能调优。
-
列表
def test1(): l = [] for i in range(1000): l += [i] def test2(): l = [] for i in range(1000): l.append(i) def test3(): l = [i for i in range(1000)] def test4(): l = list(range(1000))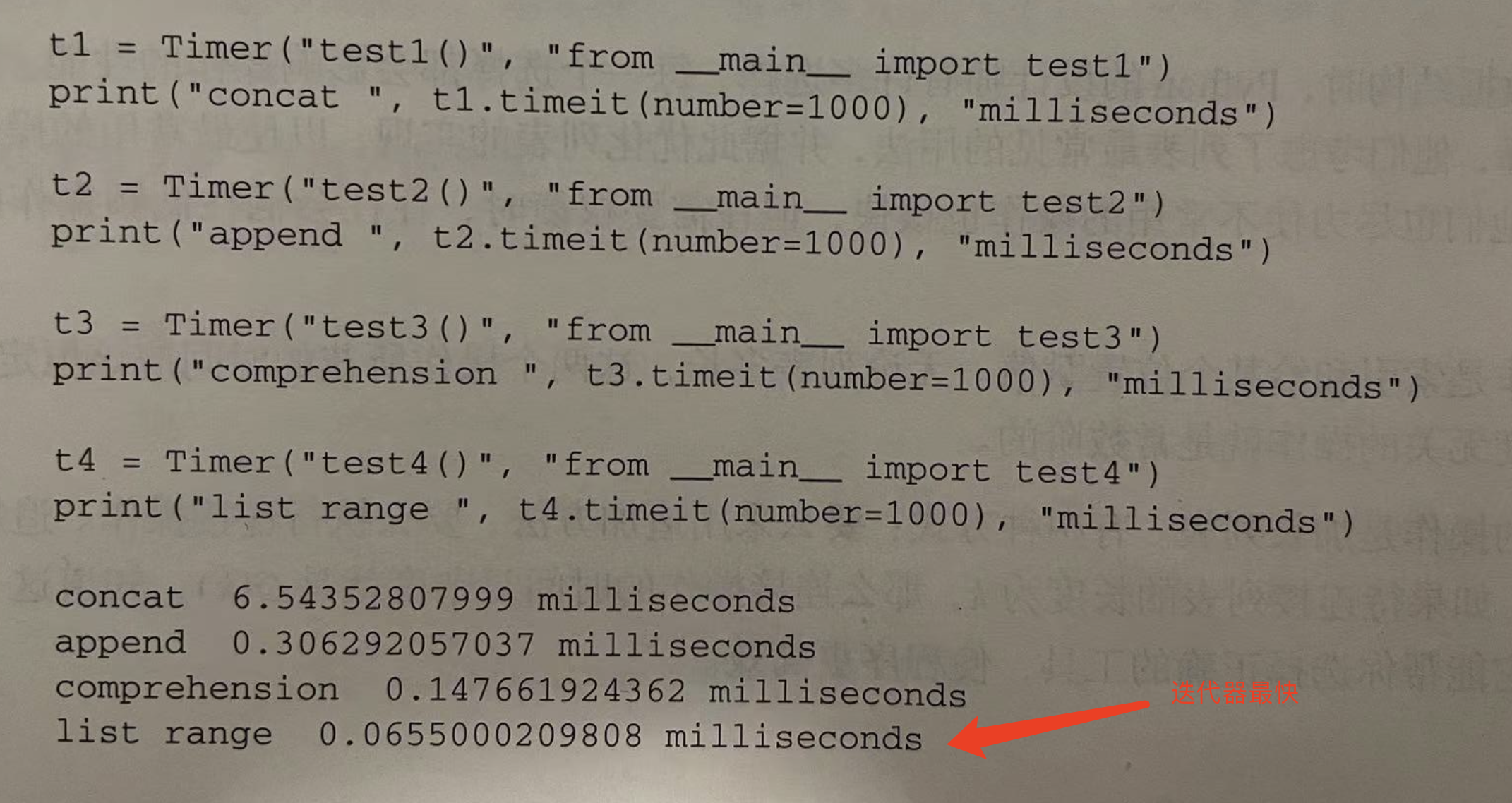

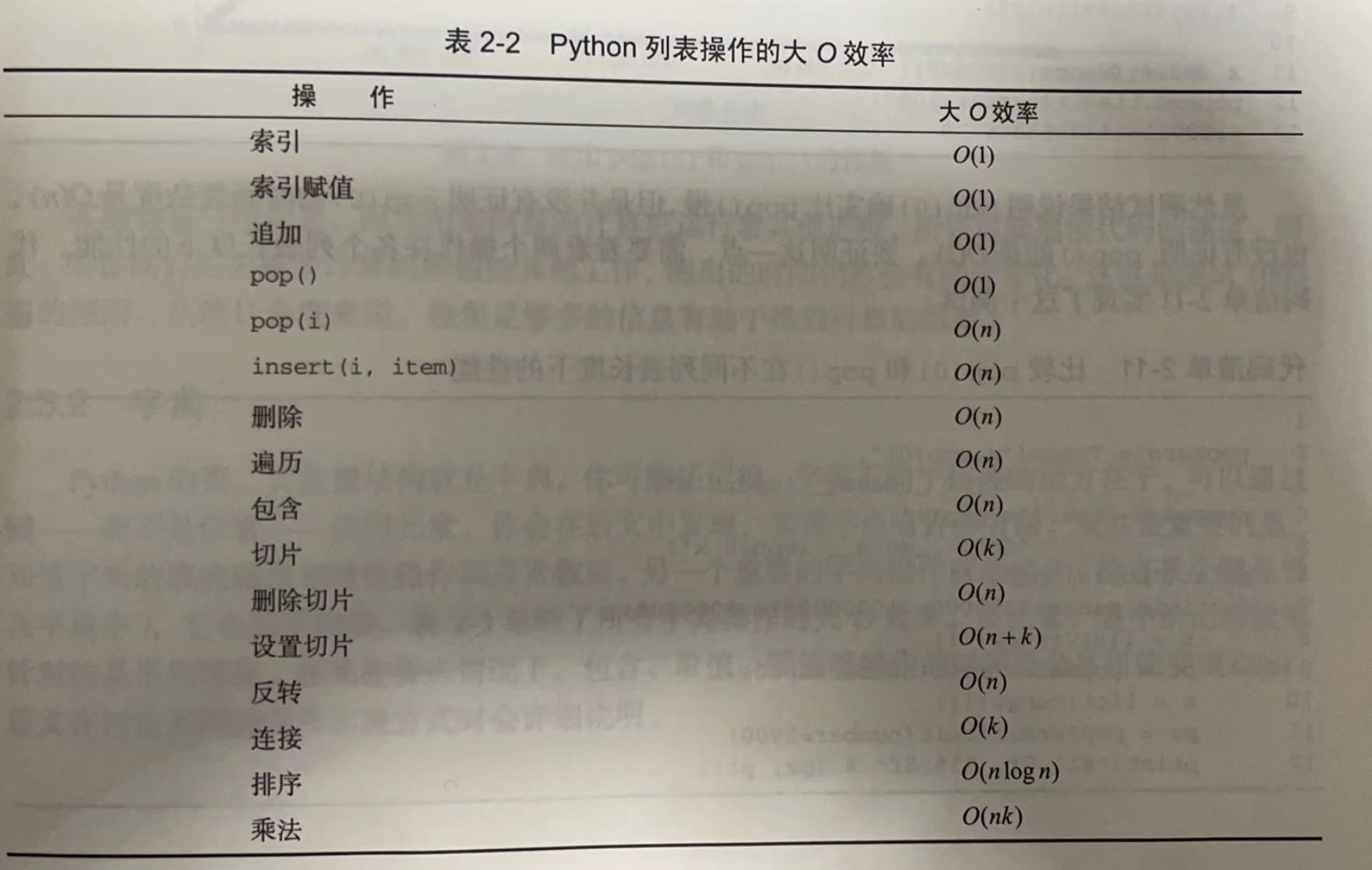
Python列表操作的大O效率
- 关于pop()、pop(i)的大O效率分别为O(1)、O(n)说明:Python在实现功能时,先从列表中拿走一个元素,后面的元素都要向头挪一位。这么做是为了保证索引操作的常数阶。
-
字典
Python字典操作的大O效率
- 值得注意的是包含也是常数阶。在比较列表的包含与字典的包含操作,可以看出随着数据规模的增大,列表包含操作的耗时也增大,而反观字典的包含操作,持续表现为某个常数。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/143964.html

