
前言
我们知道,生产者发送给kafka的数据肯定是需要存储的,存储意味着数据落盘,但是这个数据存储的结构是怎样的呢?
不妨先来了解下kafka文件存储机制
- Topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数据;
- Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment;
- 每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号,例如:first-0;
总体的文件结构如下图所示:
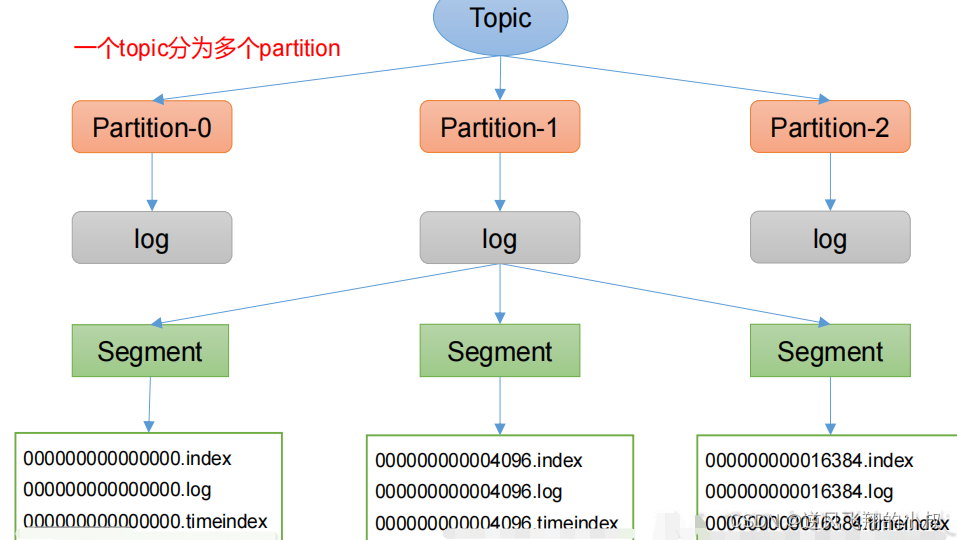
对上面的文件结构再做几点补充说明:
- 一个partition分为多个segment
- .log 日志文件 .index 偏移量
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/143306.html

