
1、增加数据
1.1 单条数据插入
示例代码:
from redis import StrictRedis
import time
try:
start = time.time()
s = StrictRedis.from_url('redis://192.168.124.49/1')
for i in range(100000):
s.set(f"name_{i}", f"dgw_{i}")
print("耗时:", time.time() - start)
except Exception as e:
print(e)
运行结果:

1.2 使用管道批量插入(10)
示例代码:
from redis import StrictRedis
import time
try:
start = time.time()
s = StrictRedis.from_url('redis://192.168.124.49/1')
pipe = s.pipeline()
for i in range(100000):
pipe.set(f"name_{i}", f"dgw_{i}")
if i % 10 == 0:
pipe.execute()
# 防止i不是整数倍时管道内部分命令不执行
pipe.execute()
print("耗时:", time.time() - start)
except Exception as e:
print(e)
运行结果:

1.3 使用管道批量插入(50)
示例代码:
from redis import StrictRedis
import time
try:
start = time.time()
s = StrictRedis.from_url('redis://192.168.124.49/1')
pipe = s.pipeline()
for i in range(100000):
pipe.set(f"name_{i}", f"dgw_{i}")
if i % 50 == 0:
pipe.execute()
# 防止i不是整数倍时管道内部分命令不执行
pipe.execute()
print("耗时:", time.time() - start)
except Exception as e:
print(e)
运行结果:

1.4 使用管道批量插入(100)
示例代码:
from redis import StrictRedis
import time
try:
start = time.time()
s = StrictRedis.from_url('redis://192.168.124.49/1')
pipe = s.pipeline()
for i in range(100000):
pipe.set(f"name_{i}", f"dgw_{i}")
if i % 100 == 0:
pipe.execute()
# 防止i不是整数倍时管道内部分命令不执行
pipe.execute()
print("耗时:", time.time() - start)
except Exception as e:
print(e)
运行结果:

1.5 使用管道批量插入(1000)
示例代码:
from redis import StrictRedis
import time
try:
start = time.time()
s = StrictRedis.from_url('redis://192.168.124.49/1')
pipe = s.pipeline()
for i in range(100000):
pipe.set(f"name_{i}", f"dgw_{i}")
if i % 1000 == 0:
pipe.execute()
# 防止i不是整数倍时管道内部分命令不执行
pipe.execute()
print("耗时:", time.time() - start)
except Exception as e:
print(e)
运行结果:
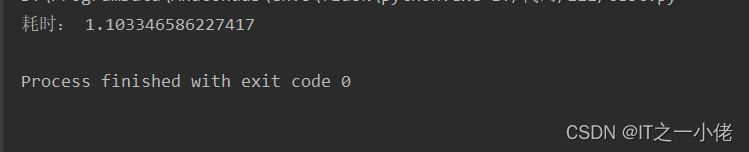
2、删除数据
2.1 单条数据删除
示例代码:
from redis import StrictRedis
import time
try:
start = time.time()
s = StrictRedis.from_url('redis://192.168.124.49/1')
count = 0
for key in s.scan_iter():
print(key)
count += 1
s.delete(key)
print(count)
print("耗时:", time.time() - start)
except Exception as e:
print(e)
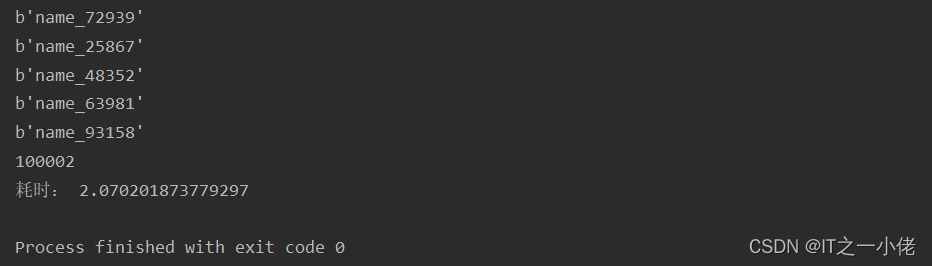
运行结果:

2.2 使用管道批量删除数据
示例代码:
from redis import StrictRedis
import time
try:
start = time.time()
s = StrictRedis.from_url('redis://192.168.124.49/1')
pipe = s.pipeline()
count = 0
for key in s.scan_iter(count=1000):
print(key)
count += 1
pipe.delete(key)
if count % 1000 == 0:
pipe.execute()
# 防止i不是整数倍时管道内部分命令不执行
pipe.execute()
print(count)
print("耗时:", time.time() - start)
except Exception as e:
print(e)
运行结果:
注意: 代码中的scan_iter()中的count的大小也会影响速度效率,pipeline批量的操作的大小也是影响速度效率的一个原因。具体数值设置多少根据实际情况而定,一般设置1000就好。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/142803.html

