
概述
我们知道在12c之前的版本,虽然有ACS、CFB等功能通过在SQL文执行时收集信息,来改善SQL文再次执行时的执行计划,但是在SQL文第一次执行时,只能根据统计信息做成的执行计划执行SQL,在执行过程中并不能改变。
如果统计信息不准确,访问的数据行数非常大并且选择的执行计划不是最优时,在SQL文第一次执行时可能会引起在灾难性的性能问题。
自适应执行计划(Adaptive Execution Plans 以后简称AP)是 12C 自适应查询优化功能集合中非常重要的一项功能,它能够使SQL在第一次运行时根据运行时统计信息动态改变最终的执行计划,用于避免SQL语句在第一次执行时由于差的执行计划引起灾难性的性能问题。
其主要包括以下2方面的组件:
自适应连接方法(Adaptive Join Methods 以后简称AJM)
自适应并行分布方法(Adaptive Parallel Distribution Methods 以后简称APDM)
自适应连接方法AJM主要用于改变表的连接方式;
自适应并行分布方法(APDM)主要用于在并行执行时,改变数据在各并行服务器进程的分布方式。
下面我们将通过几个例子来了解一下ACS功能。
自适应连接方法(AJM)
自适应连接方法(AJM)能够在SQL文第一次执行时也能进行执行计划连接方法的切换,从而得到最优的执行计划。
AJM例
让我们通过下面的例子,对自适应连接方法改变表的连接方式的内容进行理解。
1.查看测试表的信息
SQL> alter session set nls_date_format = 'YYYY-MM-DD HH24:MI:SS';
SQL> select TABLE_NAME,NUM_ROWS,BLOCKS from user_tables where TABLE_NAME in ('PRODUCT_INFORMATION','ORDER_ITEMS');
TABLE_NAME NUM_ROWS BLOCKS
-------------------- ---------- ----------
PRODUCT_INFORMATION 288 13
ORDER_ITEMS 665 5
SQL> select count(*) from ORDER_ITEMS;
COUNT(*)
----------
665
SQL> select count(*) from PRODUCT_INFORMATION;
COUNT(*)
----------
288
2.通过EXPLAIN PLAN FOR命令来查看执行计划
SQL> alter session set statistics_level=all;
Session altered.
SQL> SET LINESIZE 200
SQL> SET PAGESIZE 1000
SQL> EXPLAIN PLAN FOR
2 SELECT product_name
3 FROM order_items o, product_information p
4 WHERE o.unit_price = 15
5 AND quantity > 1
6 AND p.product_id = o.product_id
7 ;
Explained.
SQL> --default plan
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------
Plan hash value: 1255158658
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 128 | 7 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 4 | 128 | 7 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 4 | 128 | 7 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | ORDER_ITEMS | 4 | 48 | 3 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | PRODUCT_INFORMATION_PK | 1 | | 0 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| PRODUCT_INFORMATION | 1 | 20 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("O"."UNIT_PRICE"=15 AND "QUANTITY">1)
4 - access("P"."PRODUCT_ID"="O"."PRODUCT_ID")
根据这个输出,我们知道优化器根据统计信息选择的执行计划为,ORDER_ITEMS和PRODUCT_INFORMATION会利用NESTED LOOPS 的方式进行结合(default plan)。
3.执行SQL文并查看实际的执行计划。
SQL> SELECT product_name
2 FROM order_items o, product_information p
3 WHERE o.unit_price = 15
4 AND quantity > 1
5 AND p.product_id = o.product_id
6 ;
PRODUCT_NAME
--------------------------------------------------
Screws <B.28.S>
...
Screws <B.28.S>
13 rows selected.
SQL>
--查看执行计划
SQL> select * from table(dbms_xplan.display_cursor(format=>'typical iostats last -cost -bytes'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------
SQL_ID 7hj8dwwy6gm7p, child number 0
-------------------------------------
SELECT product_name FROM order_items o, product_information p WHERE
o.unit_price = 15 AND quantity > 1 AND p.product_id = o.product_id
Plan hash value: 1553478007
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | E-Time | A-Rows | A-Time | Buffers | Reads |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 13 |00:00:00.04 | 24 | 20 |
|* 1 | HASH JOIN | | 1 | 4 | 00:00:01 | 13 |00:00:00.04 | 24 | 20 |
|* 2 | TABLE ACCESS FULL| ORDER_ITEMS | 1 | 4 | 00:00:01 | 13 |00:00:00.02 | 7 | 6 |
| 3 | TABLE ACCESS FULL| PRODUCT_INFORMATION | 1 | 1 | 00:00:01 | 288 |00:00:00.01 | 17 | 14 |
------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("P"."PRODUCT_ID"="O"."PRODUCT_ID")
2 - filter(("O"."UNIT_PRICE"=15 AND "QUANTITY">1))
Note
-----
- this is an adaptive plan
26 rows selected.
根据这个输出,我们发现E-Rows和A-Rows有一定的差距,并且知道优化器最终ORDER_ITEMS和PRODUCT_INFORMATION会利用HASH JOIN 的方式进行结合(default plan)。
4.让我们通过DBMS_XPLAN.DISPLAY(FORMAT=>’+ADAPTIVE’)的方式,查看完整的执行计划。
SQL> SET LINESIZE 200
SQL> SELECT * FROM TABLE(dbms_xplan.display_cursor('7hj8dwwy6gm7p', NULL,'+ADAPTIVE'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------
SQL_ID 7hj8dwwy6gm7p, child number 0
-------------------------------------
SELECT product_name FROM order_items o, product_information p WHERE
o.unit_price = 15 AND quantity > 1 AND p.product_id = o.product_id
Plan hash value: 1553478007
----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 7 (100)| |
| * 1 | HASH JOIN | | 4 | 128 | 7 (0)| 00:00:01 |
|- 2 | NESTED LOOPS | | 4 | 128 | 7 (0)| 00:00:01 |
|- 3 | NESTED LOOPS | | 4 | 128 | 7 (0)| 00:00:01 |
|- 4 | STATISTICS COLLECTOR ★ | | | | | |
| * 5 | TABLE ACCESS FULL | ORDER_ITEMS | 4 | 48 | 3 (0)| 00:00:01 |
|- * 6 | INDEX UNIQUE SCAN | PRODUCT_INFORMATION_PK | 1 | | 0 (0)| |
|- 7 | TABLE ACCESS BY INDEX ROWID| PRODUCT_INFORMATION | 1 | 20 | 1 (0)| 00:00:01 |
| 8 | TABLE ACCESS FULL | PRODUCT_INFORMATION | 1 | 20 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("P"."PRODUCT_ID"="O"."PRODUCT_ID")
5 - filter(("O"."UNIT_PRICE"=15 AND "QUANTITY">1))
6 - access("P"."PRODUCT_ID"="O"."PRODUCT_ID")
Note
-----
- this is an adaptive plan (rows marked '-' are inactive)
32 rows selected.
我们可以引用Oracle White Paper June 2013 Optimizer with Oracle Database 12c中的插图料描述以上的过程。

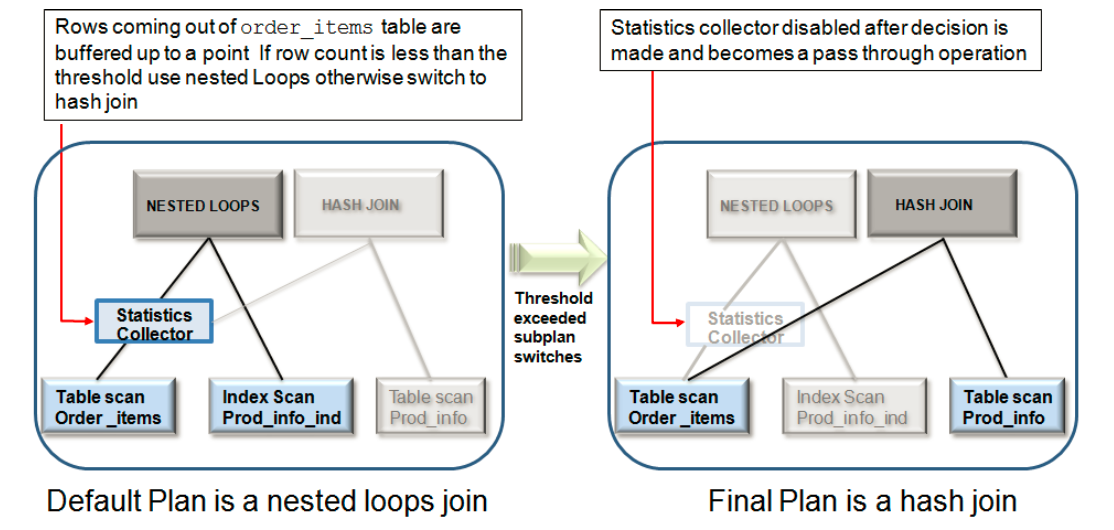
AJM的处理流程
根据上面的例子我们可以看出AJM的处理流程主要包括如下流程:
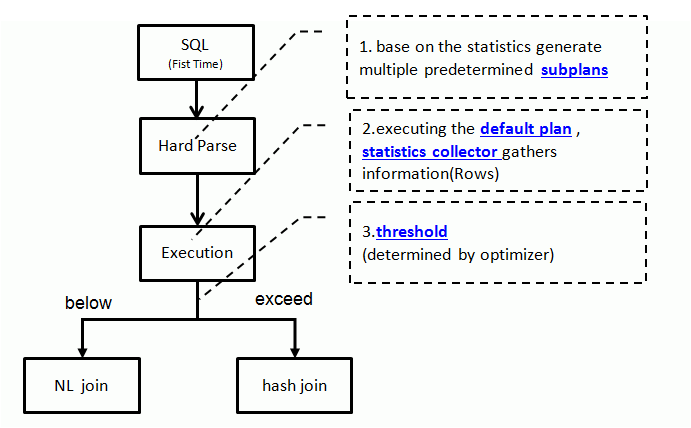
AJM的处理流程可描述如下:
1.根据现有统计信息生成默认的执行计划和可切换的辅助执行计划(subPlan)
2.执行默认的执行计划,并同时通过统计收集器收集实际的统计信息(如行数等)
3.根据收集的实际统计信息和辅助执行计划切换临界值,从多个辅助执行计划(subPlan)中选择最优的一个,作为最终的执行计划。
自适应并行分配方法(APDM)
自适应并行分配方法(APDM)主要用于在并行执行时,改变数据在各并行服务器进程的分配方式。
当SQL文以并行方式执行如并行排序,聚合操作,和连接等操作时,需要在执行SQL的各个并行服务器进程间重新分配数据后进行处理,而数据分配方法又会根据具体的操作过程中并行服务器进程的个数和优化器预估的处理行数来决定。
如果优化器根据统计信息估算的处理行数不准确,就会导致选择的分配方法不是最优的,从而不能够充分利用所有的并行服务器进程,影响性能。
因此,在12c上,Oracle引入了新的自适应分配方法:
可以能够使SQL根据运行时统计信息,进行广播式分配方法(broadcast distribution)和哈希分配方法( hash distribution)的切换,在运行时决定最终的数据分配方法。
APDM例
SQL> conn HR/HR
Connected.
SQL> SET LINESIZE 200
SQL> SET PAGESIZE 1000
SQL> EXPLAIN PLAN FOR
SELECT /*+ parallel(4) full(e) full(d) */ department_name, sum(salary)
FROM employees e, departments d
WHERE d.department_id=e.department_id
GROUP BY department_name
; 2 3 4 5 6
Explained.
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------------
Plan hash value: 2940813933
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 27 | 621 | 5 (20)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10003 | 27 | 621 | 5 (20)| 00:00:01 | Q1,03 | P->S | QC (RAND) |
| 3 | HASH GROUP BY | | 27 | 621 | 5 (20)| 00:00:01 | Q1,03 | PCWP | |
| 4 | PX RECEIVE | | 27 | 621 | 5 (20)| 00:00:01 | Q1,03 | PCWP | |
| 5 | PX SEND HASH | :TQ10002 | 27 | 621 | 5 (20)| 00:00:01 | Q1,02 | P->P | HASH |
| 6 | HASH GROUP BY | | 27 | 621 | 5 (20)| 00:00:01 | Q1,02 | PCWP | |
|* 7 | HASH JOIN | | 106 | 2438 | 4 (0)| 00:00:01 | Q1,02 | PCWP | |
| 8 | PX RECEIVE | | 27 | 432 | 2 (0)| 00:00:01 | Q1,02 | PCWP | |
| 9 | PX SEND HYBRID HASH | :TQ10000 | 27 | 432 | 2 (0)| 00:00:01 | Q1,00 | P->P | HYBRID HASH|
| 10 | STATISTICS COLLECTOR | | | | | | Q1,00 | PCWC | |
| 11 | PX BLOCK ITERATOR | | 27 | 432 | 2 (0)| 00:00:01 | Q1,00 | PCWC | |
| 12 | TABLE ACCESS FULL | DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 | Q1,00 | PCWP | |
| 13 | PX RECEIVE | | 107 | 749 | 2 (0)| 00:00:01 | Q1,02 | PCWP | |
| 14 | PX SEND HYBRID HASH (SKEW)| :TQ10001 | 107 | 749 | 2 (0)| 00:00:01 | Q1,01 | P->P | HYBRID HASH|
| 15 | PX BLOCK ITERATOR | | 107 | 749 | 2 (0)| 00:00:01 | Q1,01 | PCWC | |
| 16 | TABLE ACCESS FULL | EMPLOYEES | 107 | 749 | 2 (0)| 00:00:01 | Q1,01 | PCWP | |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("D"."DEPARTMENT_ID"="E"."DEPARTMENT_ID")
Note
-----
- Degree of Parallelism is 4 because of hint
32 rows selected.
请注意在执行计划中使用了HYBRID HASH和植入了STATISTICS COLLECTOR 。
APDM的处理流程
APDM主要包括如下流程:
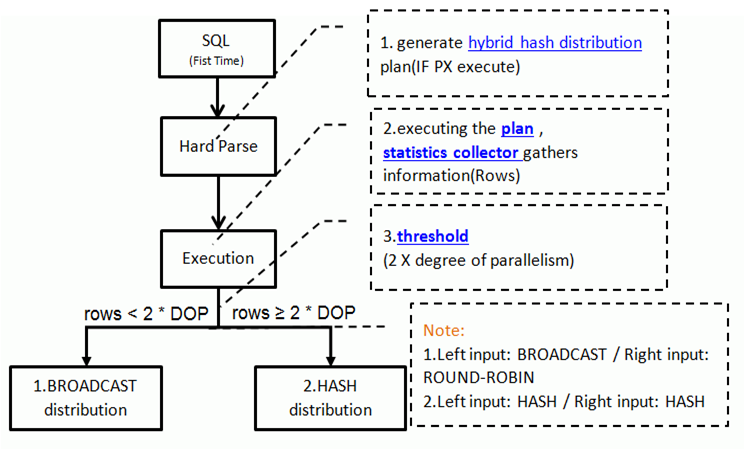
APDM处理流程:
1.根据现有统计信息生成使用混合型哈希分配方法(HYBRID HASH)的执行计划,并在执行分配方法操作前,预置统计收集器。
2.执行默认的执行计划,并同时通过统计收集器收集实际的统计信息(如行数等)
3.根据收集的实际统计信息,如果实际访问行数比临界值小,就把数据分配方法切换成广播式分配方法(broadcast distribution)
否则,如果实际访问行数达到临界值,就切换为哈希分配方法( hash distribution)。
其中临界值(threshold)为并行度的2倍。
关于分配方法
以下对数据的分配方法进行简单的介绍。
广播式分配方法(broadcast distribution):
会把查询结果集发送到所有的并行服务器进程。(每个并行服务器进程都会含有一份相同的查询结果集)。
一般适合并行服务器进程很多,而结果集行数很少的情况。
哈希分配方法( hash distribution):
会把查询结果集通过哈希算法分成N份,发送到各个并行服务器进程。(每个并行服务器进程包含一份查询结果集的子集).
一般适合并行服务器进程较少,而结果集行数较多的情况。
总结
本章通过上面的例子和总结,详细介绍了Oracle 12c 推出的自适应连接方法(Adaptive Join Methods)和自适应并行分布方法(Adaptive Parallel Distribution Methods APDM)。
版权声明:本文为博主原创文章,转载必须注明出处,本人保留一切相关权力!http://blog.csdn.net/lukeunique
参考:
https://docs.oracle.com/database/121/TGSQL/tgsql_optcncpt.htm#TGSQL221
Adaptive Plans
https://docs.oracle.com/database/121/TGSQL/tgsql_interp.htm#TGSQL94854
Reading Adaptive Plans
Oracle White Paper June 2013 Optimizer with Oracle Database 12c
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/141630.html

