
1.虚拟机环境准备
1.1 克隆虚拟机
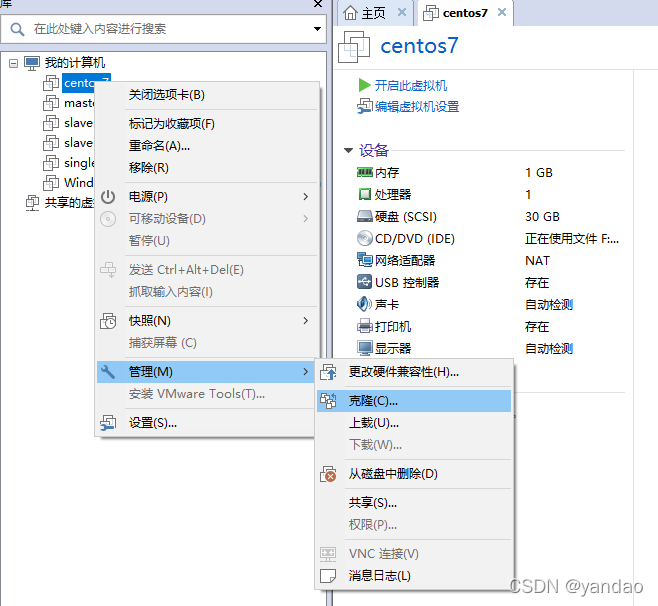

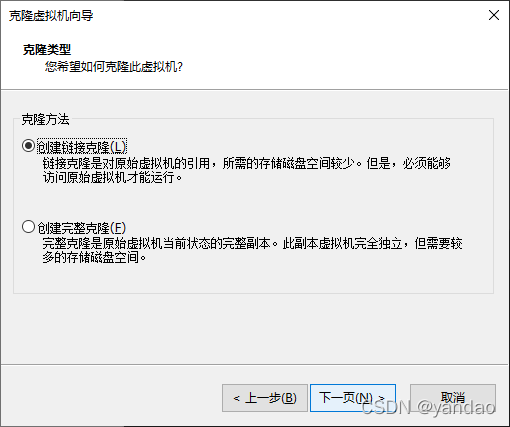
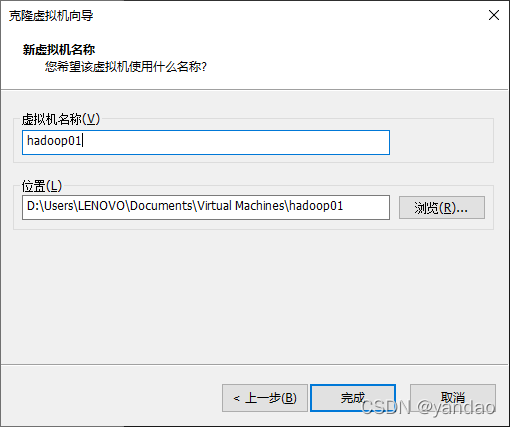
1.2. 修改克隆虚拟机的静态IP
| 机器名 | 静态IP |
|---|---|
| master | 192.168.121.151 |
| slaver1 | 192.168.121.152 |
| slaver2 | 192.168.121.153 |
[root@master Desktop]# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
#输入以下内容
DEVICE=eno16777736
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.121.151
GATEWAY=192.168.121.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
DNS2=114.114.114.114
systemctl restart network
ping www.baidu.com
ping 本机ip
配置参数:
| 参数 | 含义 |
|---|---|
| ONBOOT=yes | 启动这块网卡 |
| BOOTPROTO=static | 使用静态路由协议,保持固定的IP |
| IPADDR | IP地址,这里的IP地址需要和规划的IP地址保持一致,为以后主机名和IP对应做准备 |
| GATEWAY | 虚拟网关,通常都是将IP地址最后一个数位变成2,这个设置和VMare中V8保持一致 |
| NETMASK | 子网掩码,通常是255.255.255.0 |
| DNS1=8.8.8.8 | 域名解析器服务器,此处采用的是Google提供的免费的DNS服务器8.8.8.8,也可以使用自己的PC的域名机械其 |
| DNS2=114.114.114.114 | 国内移动、电信和联通通用的DNS服务器 |
| 常用的DNS服务: | |
| – | – |
| 114.114.114.114 | 国内移动、电信和联通通用的DNS,手机和电脑端都可以使用,干净无广告,解析成功率相对来说更高,国内用户使用的比较多,而且速度相对快、稳定,是国内用户上网常用的DNS |
| 8.8.8.8 | GOOGLE公司提供的DNS,该地址是全球通用的,相对来说,更适合国外以及访问国外网站的用户使用 |
| 223.5.5.5、223.6.6.6 | 阿里DNS服务 |
| 180.76.76.76 | 百度DNS服务 |
1.3 修改主机名
[root@master Desktop]# hostnamectl set-hostname master
#该文件用来指定服务器上的网络配置信息
[root@master Desktop]# vi /etc/sysconfig/network
#修改内容如下
NETWORKING=yes
HOSTNAME=master
[root@master Desktop]# reboot
1.4 修改IP映射
# 主机名和IP配置文件
[root@master Desktop]# vi /etc/hosts
#添加 ip 名字
192.168.121.151 master
192.168.121.152 slaver1
192.168.121.153 slaver2
1.5 关闭防火墙和SELINUX
[root@master Desktop]# systemctl stop firewalld
[root@master Desktop]# systemctl disable firewalld
[root@master Desktop]# vi /etc/sysconfig/selinux
#修改如下内容,需要重启生效
SELINUX=disabled
#查看状态
[root@master Desktop]# systemctl status firewalld
#输出
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Apr 17 17:36:55 master systemd[1]: Stopped firewalld - dynamic firewall daemon.
Hint: Some lines were ellipsized, use -l to show in full.
[root@master Desktop]#
[root@master Desktop]# sestatus
#输出
SELinux status: disabled
1.6 在/目录下创建文件夹
在/目录下创建software,servers,data,conf文件夹
[root@master Desktop]# mkdir -p /export/software
[root@master Desktop]# mkdir -p /export/servers
[root@master Desktop]# mkdir -p /export/data
[root@master Desktop]# mkdir -p /export/conf
#确认文件夹创建成功
[root@master Desktop]# ls -ll /export/
total 0
drwxr-xr-x 2 root root 6 Apr 17 17:46 conf
drwxr-xr-x 2 root root 6 Apr 17 17:45 data
drwxr-xr-x 2 root root 6 Apr 17 17:45 servers
drwxr-xr-x 2 root root 6 Apr 17 17:45 software
2 安装JDK
2.1 卸载现有JDK
(1)查询是否安装Java软件:
[root@master Desktop]# rpm -qa | grep java
(2)如果安装的版本低于1.7,卸载该JDK:
[root@master Desktop]# rpm -e --nodeps 软件包
(3)查看JDK安装路径:
[root@master Desktop]# which java
/usr/bin/which: no java in (/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/bin:/sbin:/export/servers/jdk/bin:/export/servers/zookeeper/bin:/export/servers/hadoop/bin:/export/servers/hadoop/sbin:/root/bin:/export/servers/jdk/bin:/export/servers/zookeeper/bin:/export/servers/hadoop/bin:/export/servers/hadoop/sbin)
2.2 下载JDK
(1)下载JDK,从https://www.oracle.com官网上下载所需要的JDK
https://www.oracle.com/java/technologies/downloads/#java8
https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html
(2)上传文件到/export/software
D:\Users\LENOVO\Desktop\开源大数据\software>scp jdk-8u311-linux-x64.tar.gz root@192.168.121.151:/export/software
root@192.168.121.151's password:
jdk-8u311-linux-x64.tar.gz 100% 140MB 63.6MB/s 00:02
2.3 安装JDK
#解压
[root@master Desktop]# tar -xzvf /export/software/jdk-8u311-linux-x64.tar.gz -C /export/servers/
#确认文件夹存在
[root@master Desktop]# cd /export/servers/
[root@master servers]# ls -ll
total 4
drwxr-xr-x 8 10143 10143 4096 Sep 27 2021 jdk1.8.0_311
#创建软件链接
[root@master servers]# ln -s jdk1.8.0_311/ jdk
#确认软连接存在
[root@master servers]# ls -ll
total 4
lrwxrwxrwx 1 root root 13 Apr 17 18:45 jdk -> jdk1.8.0_311/
drwxr-xr-x 8 10143 10143 4096 Sep 27 2021 jdk1.8.0_311
2.4 配置环境变量
[root@master servers]# touch /etc/profile.d/hadoop_env.sh
[root@master servers]# vi /etc/profile.d/hadoop_env.sh
#输入内容如下
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
#source使得设置生效
[root@master servers]# source /etc/profile.d/hadoop_env.sh
#确定java配置成功
[root@master servers]# which java
/export/servers/jdk/bin/java
[root@master servers]# javac -version
javac 1.8.0_311
[root@master servers]# java -version
java version "1.8.0_311"
Java(TM) SE Runtime Environment (build 1.8.0_311-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.311-b11, mixed mode)
3 安装hadoop
3.1 下载hadoop
https://hadoop.apache.org/
https://archive.apache.org/dist/hadoop/common/
3.2 安装hadoop
本地上传下载的hadoop压缩文件
D:\Users\LENOVO\Desktop\开源大数据\software>scp hadoop-2.7.3.tar.gz root@192.168.121.151:/export/software
root@192.168.121.151's password:
hadoop-2.7.3.tar.gz 100% 204MB 77.8MB/s 00:02
解压
[root@master software]# cd /export/software/
[root@master software]# tar -xzvf hadoop-2.7.3.tar.gz -C /export/servers/
确认解压成功
[root@master software]# cd /export/servers/
[root@master servers]# ls -ll
total 4
drwxr-xr-x 9 root root 139 Aug 17 2016 hadoop-2.7.3
lrwxrwxrwx 1 root root 13 Apr 17 18:45 jdk -> jdk1.8.0_311/
drwxr-xr-x 8 10143 10143 4096 Sep 27 2021 jdk1.8.0_311
建立软链接方便配置
[root@master servers]# ln -s hadoop-2.7.3/ hadoop
[root@master servers]# ls -ll
total 4
lrwxrwxrwx 1 root root 13 Apr 17 19:19 hadoop -> hadoop-2.7.3/
drwxr-xr-x 9 root root 139 Aug 17 2016 hadoop-2.7.3
lrwxrwxrwx 1 root root 13 Apr 17 18:45 jdk -> jdk1.8.0_311/
drwxr-xr-x 8 10143 10143 4096 Sep 27 2021 jdk1.8.0_311
配置环境变量
[root@master servers]# vi /etc/profile.d/hadoop_env.sh
#修改文件如下
export JAVA_HOME=/export/servers/jdk
export HADOOP_HOME=/export/servers/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source文件使得配置生效
[root@master servers]# source /etc/profile.d/hadoop_env.sh
[root@master servers]# hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /export/servers/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar
3.3 hadoop目录
[root@master servers]# cd $HADOOP_HOME
[root@master hadoop]# ls -ll
total 116
drwxr-xr-x 2 root root 4096 Aug 17 2016 bin
drwxr-xr-x 3 root root 19 Aug 17 2016 etc
drwxr-xr-x 2 root root 101 Aug 17 2016 include
drwxr-xr-x 3 root root 19 Aug 17 2016 lib
drwxr-xr-x 2 root root 4096 Aug 17 2016 libexec
-rw-r--r-- 1 root root 84854 Aug 17 2016 LICENSE.txt
-rw-r--r-- 1 root root 14978 Aug 17 2016 NOTICE.txt
-rw-r--r-- 1 root root 1366 Aug 17 2016 README.txt
drwxr-xr-x 2 root root 4096 Aug 17 2016 sbin
drwxr-xr-x 4 root root 29 Aug 17 2016 share
| 目录 | 说明 |
|---|---|
| bin | 存放操作Hadoop相关服务(HDFS,YARN)的脚步,但是通常使用sbin目录下的脚本 |
| etc | 存放Hadoop配置文件,主要包含core-site.xml,hdfs-site.xml,mapred-site.xml等从Hadoop1.x集成而来的文件和yarn-site,xml等Hadoop2.x新增的配置文件 |
| include | 对外提供编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通用用于C++访问HDFS和编写MapReduce程序 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用 |
| libexec | 各个服务对用的shell文件所在的目录,可用于配置日志输出,启动参数(比如JVM参数)等信息 |
| sbin | 存放Hadoop管理脚本,主要包含HDFS和YARN中各类服务的启动/关闭脚本 |
| share | Hadoop各个模块编译后的jar包所在的目录,包括Hadoop的依赖jar包、文档、和官方案例等 |
| 有的时候需要把Hadoop的源码包src存放到src包中。 |
4 配置另外的机器
4.1 可以基于master克隆虚拟机
克隆slaver1、slaver2
4.2 配置机器
4.2.1 配置slaver1 IP
[root@slaver1 Desktop]# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
#输入以下内容
DEVICE=eno16777736
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.121.151
GATEWAY=192.168.121.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
DNS2=114.114.114.114
systemctl restart network
4.2.2 修改主机名
[root@slaver1 Desktop]# hostnamectl set-hostname slaver1
#该文件用来指定服务器上的网络配置信息
[root@slaver1 Desktop]# vi /etc/sysconfig/network
#修改内容如下
NETWORKING=yes
HOSTNAME=slaver1
[root@master Desktop]# reboot
4.2.3 配置slaver2 IP
[root@slaver2 Desktop]# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
#输入以下内容
DEVICE=eno16777736
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.121.151
GATEWAY=192.168.121.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
DNS2=114.114.114.114
systemctl restart network
4.2.4 修改主机名
[root@slaver2 Desktop]# hostnamectl set-hostname slaver2
#该文件用来指定服务器上的网络配置信息
[root@slaver2 Desktop]# vi /etc/sysconfig/network
#修改内容如下
NETWORKING=yes
HOSTNAME=slaver2
[root@master Desktop]# reboot
5.hadoop分布式配置
5.1 了解配置文件
| 配置文件 | 功能描述 |
|---|---|
| hadoop-env.sh | 配置Hadoop运行所需要的环境变量 |
| mapred-env.sh | 配置MapReduce运行所需要的环境变量 |
| yarn-env.sh | 配置YARN运行所需要的环境变量 |
| core-site.xml | Hadoop核心全局配置文件,可在其他配置文件中引用该文件 |
| hdfs-site.xml | HDFS配置文件,继承core-site.xml配置文件 |
| mapred-site.xml | MapReduce配置文件,继承core-site.xml配置文件 |
| yarn-site.xml | YARN配置文件,继承core-site.xml配置文件 |
| slaves | 用于记录集群所有的从节点的主机名,包括HDFS的DataNode节点和YARN的NodeManager节点 |
5.2 规划集群
| master | slaver1 | slaver2 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
5.3 配置文件
5.3.1 hadoop-env.sh
hadoop-env.sh用来保证Hadoop系统能够正常执行HDFS的守护进程NameNode,SecondaryNameNode和DataNode,这个文件需要修改JAVA_HOME
[root@master hadoop]# cd $HADOOP_HOME
[root@master hadoop]# vi etc/hadoop/hadoop-env.sh
#修改内容如下
export JAVA_HOME=/export/servers/jdk
5.3.2 core-site.xml
该文件是Hadoop的核心配置文件,其目的是配置HDFS地址,端口号,以及临时文件目录
[root@master hadoop]# cd $HADOOP_HOME
[root@master hadoop]# vi etc/hadoop/core-site.xml
#配置内容如下
<configuration>
<!--指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--指定Hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop/tmp</value>
</property>
</configuration>
5.3.3 hdfs-site.xml
配置SecondaryNameNode和DataNode两大进程
[root@master hadoop]# cd $HADOOP_HOME
[root@master hadoop]# vi etc/hadoop/hdfs-site.xml
#配置内容如下
<configuration>
<!--指定HDFS中副本的数量,默认值是3,此处可以省略-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slaver2:50090</value>
</property>
</configuration>
5.3.4 mapred-env.sh
该文件是MapReducer的核心配置文件,用于指定MapRedue运行的时候的框架。
[root@master hadoop]# cd $HADOOP_HOME
[root@master hadoop]# vi etc/hadoop/mapred-env.sh
#修改内容如下
export JAVA_HOME=/export/servers/jdk
5.3.5 mapred-site.xml
该文件是MapReducer的核心配置文件,用于指定MapRedue运行的时候的框架。
[root@master hadoop]# cd $HADOOP_HOM
#该文件不存在,需要先复制
[root@master hadoop]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[root@master hadoop]# vi etc/hadoop/mapred-site.xml
<configuration>
#配置内容如下
<!-- 指定MR运行时的框架,这里指定是yarn,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.3.6 yarn-env.sh
yarn-env.sh用来保证YARN的守护进程ResourceManager和NodeManager,这个文件需要修改JAVA_HOME
[root@master hadoop]# cd $HADOOP_HOME
[root@master hadoop]# vi etc/hadoop/yarn-env.sh
#修改内容如下
export JAVA_HOME=/export/servers/jdk
5.3.7 yarn-site.xml
指定yarn集群的管理者
[root@master hadoop]# cd $HADOOP_HOME
[root@master hadoop]# vi etc/hadoop/yarn-site.xml
#配置内容如下
<configuration>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slaver1</value>
</property>
</configuration>
文件中配置了yarn运行时候的主机为slaver1(192.168.121.152),同时配置了NodeManger运行时的附属服务,需要配置mapreduce_shuffle才能正常运行MapReducer程序。
5.3.8 slaves
用于记录集群所有的从节点的主机名,包括HDFS的DataNode节点和YARN的NodeManager节点
[root@master hadoop]# cd $HADOOP_HOME
[root@master hadoop]# vi etc/hadoop/slaves
#内容如下
master
slaver1
slaver2
5.4文件的分发
[root@master ~]# scp -r /export/servers/hadoop/etc root@slaver1:/export/servers/hadoop/
[root@master ~]# scp -r /export/servers/hadoop/etc root@slaver2:/export/servers/hadoop/
6 集群单点启动
(1)如果集群是第一次启动,需要格式化NameNode
[root@master ~]# hadoop namenode -format
或者是使用
[root@master ~]# hdfs namenode -format
格式化成功的标志是格式化时输出以下信息:
22/04/17 22:31:12 INFO common.Storage: Storage directory /export/data/hadoop/tmp/dfs/name has been successfully formatted.
如果格式化不成功,或者出现问题的时候,需要重新格式化,格式化之前需要删除所有的进程,删除目录
#删除所有的进程,删除hadoop临时文件,删除logs,重新格式化
[root@master ~]# jps |awk '{print $1}' |xargs kill -9
[root@master ~]# rm -rf /export/data/hadoop
[root@master ~]# rm -rf /export/servers/hadoop-2.7.3/logs
[root@slaver1 ~]# jps |awk '{print $1}' |xargs kill -9
[root@slaver1 ~]# rm -rf /export/data/hadoop
[root@slaver1 ~]# rm -rf /export/servers/hadoop-2.7.3/logs
[root@slaver2 ~]# jps |awk '{print $1}' |xargs kill -9
[root@slaver2 ~]# rm -rf /export/data/hadoop
[root@slaver2 ~]# rm -rf /export/servers/hadoop-2.7.3/logs
[root@master ~]# hadoop namenode -format
(2)在节点master上启动NameNode
[root@master ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /export/servers/hadoop-2.7.3/logs/hadoop-root-namenode-master.out
[root@master ~]# jps
8887 Jps
9085 NameNode
(3)在节点slaver2上启动SecondaryNameNode
[root@slaver2 ~]# hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /export/servers/hadoop/logs/hadoop-root-secondarynamenode-slaver2.out
[root@slaver2 ~]# jps
3760 Jps
3719 SecondaryNameNode
(4)在master,slaver1以及slaver2上分别启动DataNode
[root@master ~]# hadoop-daemon.sh start datanode
starting datanode, logging to /export/servers/hadoop-2.7.3/logs/hadoop-root-datanode-master.out
[root@master ~]# jps
8993 DataNode
9171 Jps
9085 NameNode
[root@slaver1 hadoop]# hadoop-daemon.sh start datanode
starting datanode, logging to /export/servers/hadoop/logs/hadoop-root-datanode-slaver1.out
[root@slaver1 hadoop]# jps
3798 DataNode
3870 Jps
[root@slaver2 ~]# hadoop-daemon.sh start datanode
starting datanode, logging to /export/servers/hadoop/logs/hadoop-root-datanode-slaver2.out
[root@slaver2 ~]# jps
3925 DataNode
3719 SecondaryNameNode
3997 Jps
(5)在slaver1启动ResourceManager
[root@slaver1 hadoop]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /export/servers/hadoop/logs/yarn-root-resourcemanager-slaver1.out
[root@slaver1 hadoop]# jps
3798 DataNode
4027 ResourceManager
4236 Jps
(6)在master,slaver1以及slaver2上分别启动NodeManager
[root@master ~]# yarn-daemon.sh start nodemanager
starting nodemanager, logging to /export/servers/hadoop-2.7.3/logs/yarn-root-nodemanager-master.out
[root@master ~]# jps
8993 DataNode
9397 Jps
9304 NodeManager
9085 NameNode
[root@slaver1 hadoop]# yarn-daemon.sh start nodemanager
starting nodemanager, logging to /export/servers/hadoop/logs/yarn-root-nodemanager-slaver1.out
[root@slaver1 hadoop]# jps
4369 Jps
3798 DataNode
4027 ResourceManager
4316 NodeManager
[root@slaver2 ~]# yarn-daemon.sh start nodemanager
starting nodemanager, logging to /export/servers/hadoop/logs/yarn-root-nodemanager-slaver2.out
[root@slaver2 ~]# jps
3925 DataNode
4102 NodeManager
3719 SecondaryNameNode
4137 Jps
7.免密登录
master,slaver1,slaver2执行
[root@master~] cd
[root@master~] rm -rf .ssh
[root@master~] ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
[root@slaver1 ~] cd
[root@slaver1 ~] rm -rf .ssh
[root@slaver1 ~] ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
[root@slaver2 ~] cd
[root@slaver2 ~] rm -rf .ssh
[root@slaver2 ~] ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
上传密钥
master,slaver1,slaver2执行
[root@master~] ssh-copy-id -i ~/.ssh/id_rsa.pub master
[root@master~] ssh-copy-id -i ~/.ssh/id_rsa.pub slaver1
[root@master~] ssh-copy-id -i ~/.ssh/id_rsa.pub slaver2
[root@slaver1~] ssh-copy-id -i ~/.ssh/id_rsa.pub master
[root@slaver1~] ssh-copy-id -i ~/.ssh/id_rsa.pub slaver1
[root@slaver1~] ssh-copy-id -i ~/.ssh/id_rsa.pub slaver2
[root@slaver2~] ssh-copy-id -i ~/.ssh/id_rsa.pub master
[root@slaver2~] ssh-copy-id -i ~/.ssh/id_rsa.pub slaver1
[root@slaver2~] ssh-copy-id -i ~/.ssh/id_rsa.pub slaver2
8.启动
master上启动dfs
[root@master~] start-dfs.sh
slaver1上启动yarn
[root@slaver1~] start-yarn.sh
9.启动总结
9.1 各个服务组件逐一启动/停止
9.1.1分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
9.1.2启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
9.2 各个模块分开启动/停止(配置ssh是前提)常用
9.2.1 整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
9.2.2 整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
10.时钟同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了会产生时间偏差,导致集群执行任务时间不同步。
需求:找一个机器,作为时间服务器,所有的及其与这台集群时间进行定时同步,生产环境根据任务对时间的准确度要求周期同步
10.1 时间服务器配置(必须root用户)
10.1.1 检查ntp是否安装
[root@master~]# rpm -qa|grep ntp
ntp-4.2.6p5-22.el7.centos.x86_64
fontpackages-filesystem-1.44-8.el7.noarch
python-ntplib-0.3.2-1.el7.noarch
ntpdate-4.2.6p5-22.el7.centos.x86_64
如果没有安装则需要安装
yum install ntp ntpdate -y
10.1.2 修改ntp配置文件
[root@master~]# vi /etc/ntp.conf
修改内容如下
#修改1(授权192.168.121.0-192.168.121.255网段上的所有机器可以从这台机器上查询和同步时间),把下面#的行修改为没有#的行
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
restrict 192.168.121.0 mask 255.255.255.0 nomodify notrap
#修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
10.1.3 修改/etc/sysconfig/ntpd 文件
[root@master~]# vim /etc/sysconfig/ntpd
#增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
10.1.4 重新启动ntpd服务
[root@master~]# service ntpd status
Redirecting to /bin/systemctl status ntpd.service
● ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)
Active: inactive (dead)
[root@master~]# service ntpd start
10.1.5 设置ntpd服务开机启动
[root@master~]# chkconfig ntpd on
#或者
[root@master~]# systemctl is-enabled ntpd
10.2 其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[root@slaver1 ~]# crontab -e
#编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate master
(2)修改任意机器时间
[root@slaver1 ~]# date -s "2017-9-11 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[root@slaver1 ~]# date
说明:测试的时候可以将10分钟调整为1分钟,节省时间。
或者使用如下方式:
vi /export/servers/hadoop/etc/hadoop/hadoop-env.sh
export HADOOP_OPTS="$HADOOP_OPTS -Duser.timezone=GMT+08"
vi /export/servers/hadoop/etc/hadoop/yarn-env.sh
YARN_OPTS="$YARN_OPTS -Duser.timezone=GMT+08"
#hbase的配置,暂时不需要配置
vi hbase-env.sh
export TZ="Asia/Shanghai"
12.取消/var/spool/mail/root邮件提醒
[root@slaver1 ~] vi /etc/profile
#添加如下内容
unset MAILCHECK
[root@slaver1 ~] source /etc/profile
11通过UI查询hadoop运行状态
Hadoop正常启动后,它开放了两个端口50070和8088两个端口用于监控HDFS和YARN的集群。
注意
如果namenode的resourceManager不在一台机器上的话 ,那么不能再namenode上启动resourceManager 也就是只能在resourceManager部署的机器上启动。
脚本
jps.sh
[root@master conf]# cd /export/conf/
[root@master conf]# touch jps.sh
[root@master conf]# vi jps.sh
#输入以下内容
#!/bin/bash
for i in master slaver1 slaver2
do
echo "========$i的JPS========"
ssh $i "jps"
done
[root@master conf]# chmod 777 jps.sh
[root@master conf]# ./jps.sh
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/140768.html

