
paoxs算法
- Paxos算法,读作[ˈpæksoʊs],是基于消息传递且具有高度容错特性的一致性算法,是目前公认的解决分布式一致性问题最有效的算法之一
- Paxos算法的通俗理解
- 假设有十个人要去旅游,目的地有成都和拉萨两个地点。为了统一目的地,简单的方法可以拉个微信群组聊天,大家投票,按少数服从多数的原则。但是在Paxos算法里,觉得微信平台不可靠,它挂了怎么办?Paxos的原则是容错性一定要很强,所以paxos采取相互发短信
- 找另外三个人当中介人(也可从十个人中选,也不局限三个中介),十个人给他们发短信,中介者之间可以不通信
- 申请阶段:每个人的短信都会带一个发送时间,中介只会和最新短信的提议者交流,而且只能和一个人交流。每个人疯狂向中介发短信,希望获得沟通权
- 沟通阶段:如果获得半数的中介者沟通权。提议者则会给这些中介提议自己希望的旅游地(例如成都)。而收到的结果有三种;
- A: 超过半数的中介者同意,收东西去成都;
- B: 至少有一个中介者决定了旅游地(不一定是成都,可能是其他提议者和中介商定的拉萨),那先看看是否超过半数的旅游地,如果没有,则下次顶最近时间选择出的旅游地
- C: 失去沟通权,再继续发短信。。。。。。
- Paxos的一致性,是为了解决冗余副本的一致性,和关系型数据库中ACID的一致性说的不是一个东西
Raft算法
- 由于Paxos难以理解,也难以实现。于是有了新的共识算法。Raft,读音[rɑːft],有三种角色
- Leader: 处理所有客户端交互,日志复制等,同一时刻只有一个有效的Leader
- Follower: 类似选民,完全被动
- Candidate候选人: 可以被选为一个新的领导人
选举阶段
- 一开始任何一个服务器都是Follwer,它们内置一个倒计时,当倒计时结束时变成Candidate,向其他follwers发出要求选举自己的请求
- 此时有三个状态
- A:超过半数follwers追随,成为新的leader
- B:存在竞争者,且有超过半数追随者,放弃竞选,成为其follwer
- C:存在竞争者,大家半斤八两。Candidate则在下个竞选周期term再次发起竞选,此时也有内置一个倒计时,谁先倒计时结束快,谁则先成为抢占半数follwer的leader(注意:前一轮成为别人的follwer不能在竞选了)
日志复制阶段
1:Leader领导人已经选出,客户端发出增加一个日志的要求,比如日志是”hello”
2:Leader要求Followe遵从他的指令,都将这个新的日志内容追加到他们各自日志中
3:大多数follower服务器将日志写入磁盘文件后,确认追加成功,发出Commited Ok
4:在下一个心跳heartbeat中,Leader会通知所有Follwer更新commited 项目
如果在这一过程中,发生了网络分区或者网络通信故障。使得Leader不能访问大多数Follwers了,而follwers重新选举新的Leade对外提供服务。在恢复网络时,旧的leader会成为拥有多数follwer的新Leader的follwer。故障期间的commit回滚。
详细可查看我之前写的这篇文章:Raft算法详解
zab算法
ZXID
协议的事务编号 Zxid 设计中, Zxid 是一个 64位的数字
- 其中低 32 位是一个简单的单调递增的计数器, 针对客户端每一个事务请求,计数器加 1
- 而高 32 位则代表 Leader 周期 epoch 的编号,每个当选产生一个新的 Leader 服务器,就会从这个 Leader 服务器上取出其本地日志中的最大事务 ZXID ,并从中读取 epoch 值,然后加 1 ,以此作为新的 epoch。而低 32 位计数器则从 0 开始重新计数
崩溃恢复模式(选举)
- 集群初始化或者Leader失去连接时,节点(任意节点)发起选主,然后集群其他节点会为发起选主的节点进行投票。
- 节点B判断确定A可以成为Leader,那么节点B就投票给节点A,判断的依据是:election epoch(A) > election epoch (B) || zxid(A) > zxid(B) || sid(A) > sid(B)。并更新自己的投票为B投票。
- sid是服务ID,人为配置的。
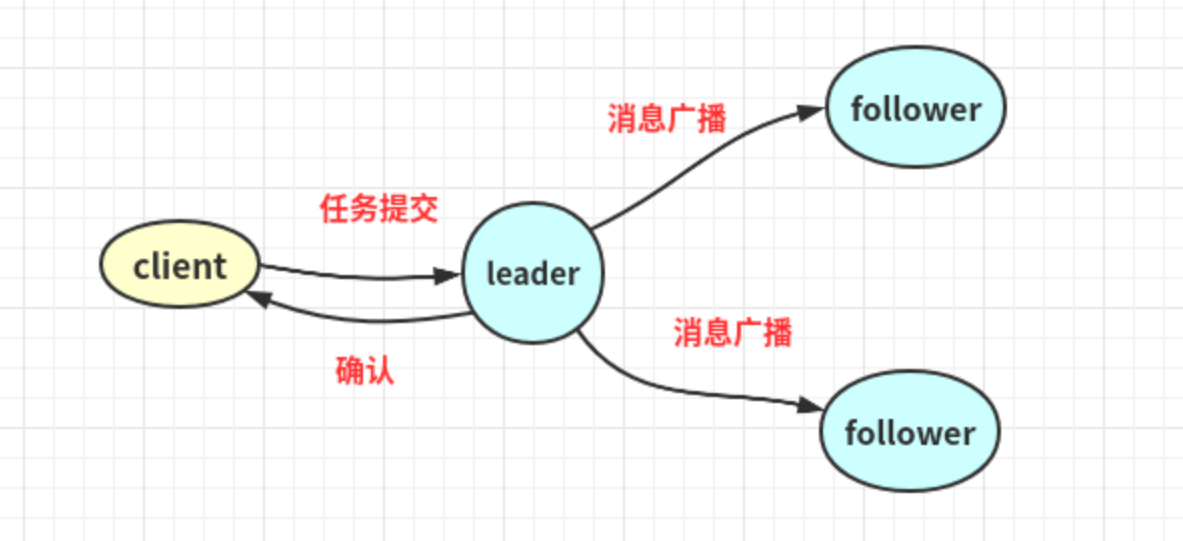
消息广播模式
- Leader将客户端的request转化成一个Proposal(提议)。
- Leader为每一个Follower准备了一个FIFO队列,并把Proposal发送到队列上。
- Leader若收到follower的半数以上ACK反馈。
- Leader向所有的follower发送commit图片。

一些细节
- Leader在收到客户端请求之后,会将这个请求封装成一个事务,并给这个事务分配一个全局递增的唯一ID,称为事务ID(ZXID),ZAB协议需要保证事务的顺序,因此必须将每一个事务按照ZXID进行先后排序然后处理。
- 在Leader和Follwer之间还有一个消息队列,用来解耦他们之间的耦合,解除同步阻塞。
- zookeeper集群中为保证任何所有进程能够有序的顺序执行,只能是 Leader 服务器接受写请求,即使是 Follower 服务器接受到客户端的请求,也会转发到 Leader 服务器进行处理。
分布式事务一致性
对于分布式一致性和分布式事务一致性。我更愿意区分开来:
- A-分布式一致性是为了解决数据分布在多个服务的状态一致(多个副本保持一致)
- B-分布式事务一致性,更加类似关系型数据库的一致性,是约束数据在分布式服务的关系(比如数据a在服务A的状态和数据b在服务B需要保持一个固定的映射关系)
分布式共识算法和分布式事务一致性的区别
共识算法就是为了解决分布式一致性的算法,但不适合解决分布式事务一致性(可以解决只是不合适)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/132098.html

