
作者:非妃是公主
专栏:《机器学习》
个性签:顺境不惰,逆境不馁,以心制境,万事可成。——曾国藩
专栏地址
专栏系列文章

无监督学习基础知识
提及无监督学习,我们首先会想到聚类。聚类跟分类的区别在于训练样本的类标记是未知的。
所谓聚类就是将对物理或抽象对象的集合分组成为由类似的对象组成的多个簇的过程。
聚类生成的组称为簇,簇是数据对象的集合。簇内部的任意两个对象之间具有较高的相似度,而属于不同簇的两个对象之间具有较高的相异度。
相似度和相异度可以根据描述对象的属性值来计算,对象间的距离是最常采用的相异度度量指标。相似度与相异度通常成反比函数关系。
聚类既能作为一个单独过程,用于找寻数据内在的分布结构,也可作为分类等其他学习任务的前驱过程。
比如,在一些商业应用中需对新用户的类型进行判别,但定义用户类型对商家来说却可能不太容易,此时往往可先对用户数据进行聚类,然后再根据聚类结果将每个簇定义为一个类,最后再基于这些类训练分类模型,用于判别新用户的类型。
基于不同的学习策略,人们设计出多种不同类型的聚类算法,很难对这些聚类算法提出一个简洁的分类。大体上,主要的聚类算法可以分为如下五类:
1)基于划分的方法:
2)基于层次的方法:
3)基于密度的方法:
4)基于网格的方法:
5)基于模型的方法:
下面就基于划分的方法做一个简单的介绍。简单说,基于划分的方法就是采用目标函数最小化的策略,通过迭代把数据对象划分成K个组,每个组为一个簇。
基于划分的方法需要满足如下两个条件:
1)每个分组至少包含一个对象;
2)每个对象属于且仅属于某一个分组。
基于划分的方法主要包括K均值(k-means) 聚类算法及其变种:K众数(k-modes) 、K原型(k-rototypes) 、K中心点(k-medoids) 、以及K分布(k-distributions) 。
K均值聚类算法

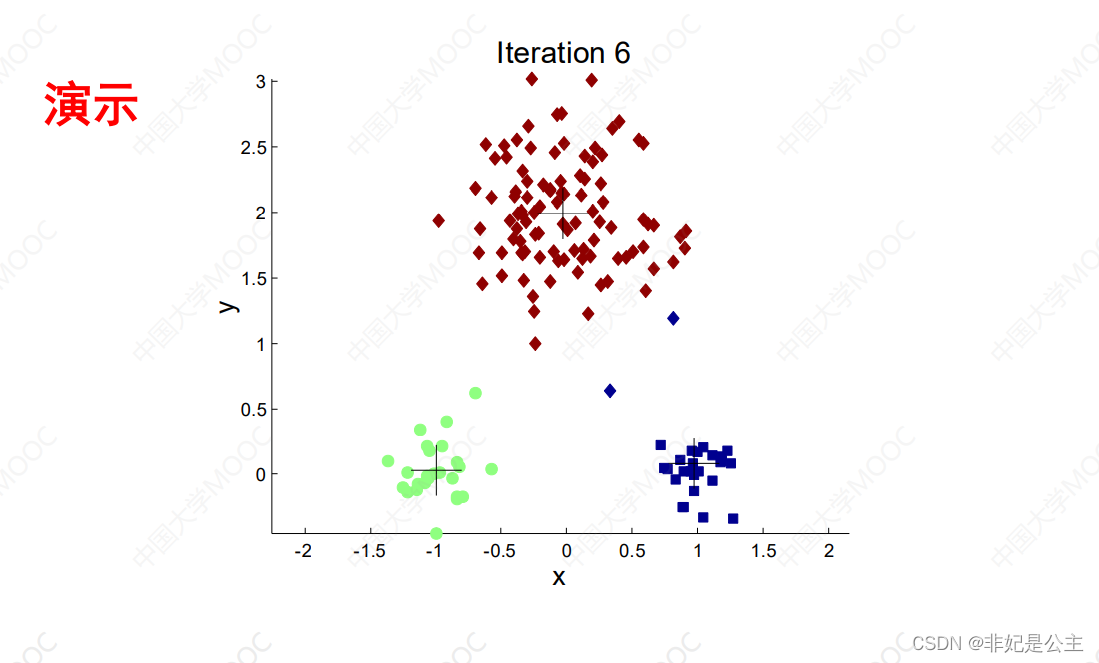

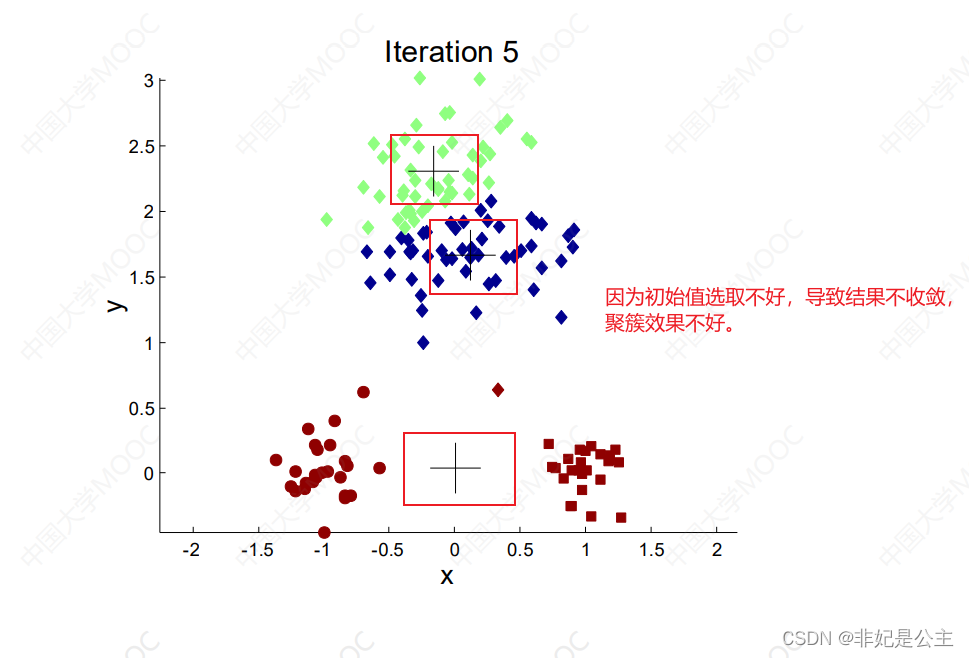
K均值聚类算法变种
K众数算法

K原型算法

K中心点算法

K分布算法

划分簇的过程中相当于增加了随机性,原来是生成K个随机数(随机选择K个点作为初始中心点,随机数为K),现在生成N个随机数(每个点都要随机选一个簇,随机数为N)


K均值聚类算法的理解



版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/130532.html

