
一、数据仓库简介
数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
数据仓库是伴随着企业信息化发展起来的,在企业信息化的过程中,随着信息化工具的升级和新工具的应用,数据量变的越来越大,数据格式越来越多,决策要求越来越苛刻,数据仓库技术也在不停的发展。
数据仓库的趋势:
实时数据仓库以满足实时化&自动化决策需求;
大数据&数据湖以支持大量&复杂数据类型(文本、图像、视频、音频);
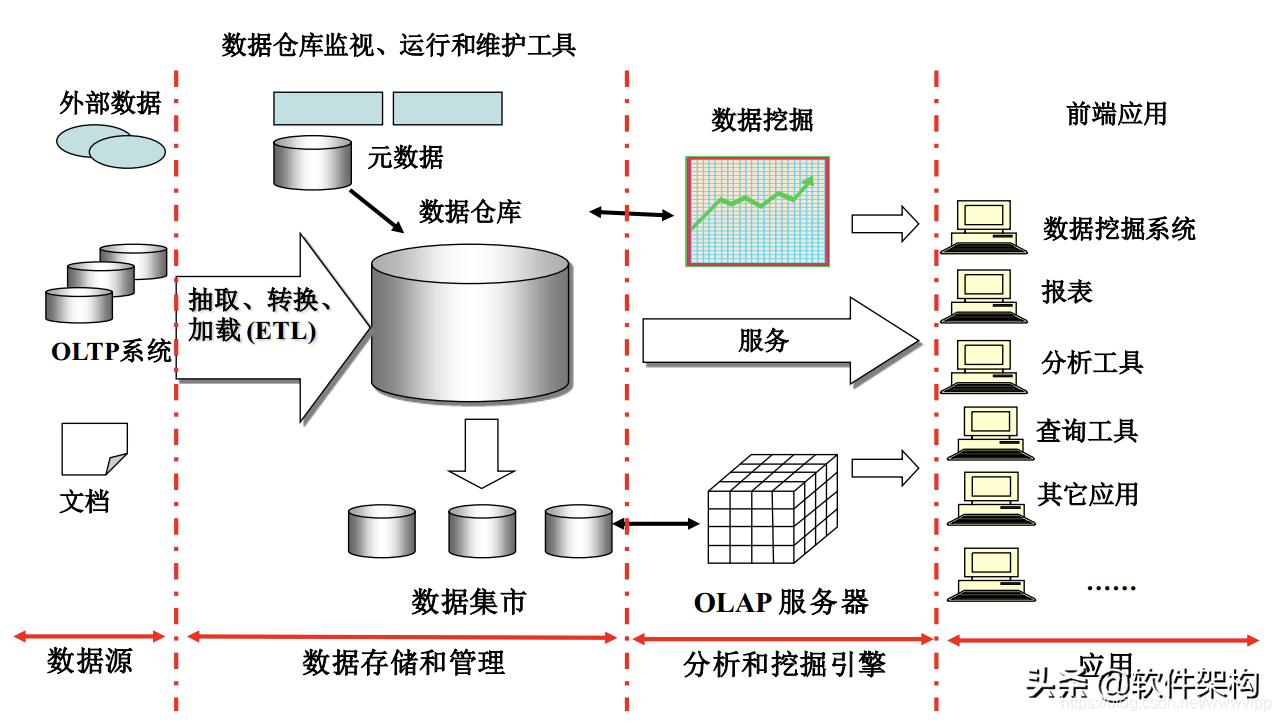
数据仓库的体系结构通常包含四个层次:数据源、数据存储和管理、数据服务、数据应用:
数据源:是数据仓库的数据来源,包括了外部数据、现有业务系统和文档资料等;
数据集成:完成数据的抽取、清洗、转换和加载任务,数据源中的数据采用 ETL 工具以固定的周期加载到数据仓库中;
数据存储和管理:这一层次主要涉及对数据的存储和管理,包括数据仓库、数据集市、数据仓库检测、运行与维护工具和元数据管理等;
数据服务:为前端工具和应用提供数据服务,可以直接从数据仓库中获取数据供前端应用使用,也可以通过 OLAP 服务器为前端应用提供更加复杂的数据服务。 OLAP服务器提供了不同聚集粒度的多维数据集合,使得应用不需要直接访问数据仓库中的底层细节数据,大大减少了数据计算量,提高了查询响应速度。 OLAP 服务器还支持针对多维数据集的上钻、下探、切片、切块和旋转等操作,增强了多维数据分析能力;
数据应用:这一层次直接面向最终用户,包括数据查询工具、自由报表工具、数据分析工具、数据挖掘工具和各类应用系统。

二、OLTP和OLAP
OLTP的全称是 Online Transaction Processing, OLTP主要用传统的关系型数据库来进行事务处理。OLTP最核心的需求是业务数据的高效快速处理,索引技术、分库分表等最根本的诉求就是解决此问题。
OLAP的全称是 Online Analytical Processing,OLAP能够处理和统计大量的数据,不像OLTP数据库需要考虑数据的增删改查和并发控制等,OLAP数据一般只需要处理数据查询请求、数据批量导入等,因此通过列存储,列压缩和位图索引等技术可以大大加快响应请求的速度。
OLAP支持以多维度的方式分析数据,并且能弹性地提供上卷(Roll-up)、下钻(Drill-down)和透视分析(Pivot)等操作。
三、事实表和维度表
维度建模用于决策制定,并侧重于业务如何表示和理解数据。基本的维度模型由维度和度量两类对象组成。
维度建模尝试以逻辑、可理解的方式呈现数据,以使得数据的访问更加直观。维度设计的重点是简化数据和加快查询。
事实表(Fact Table)
是指存储事实记录的表,如系统日志、销售记录等,并且是维度模型中的主表,代表着键和度量的集合。事实表的记录会不断地动态增长,所以它的体积通常远大于其他表,通常事实表占据数据仓库中90%或更多的空间。
维度表(Dimension Table),也称维表或查找表(Lookup Table)
,是与事实表相对应的一种表。维度表的目的是将业务含义和上下文。
添加到数据仓库中的事实表和度量中。纬度表是事实表的入口点,纬度表实现了数据仓库的业务接口。它们基本上是事实表中键引用的查找表。
常见的纬度表有:日期表(存储日期对应的周、月、季度等属性)
使用纬度表的好处如下:
1.减小了事实表的大小;
2.便于纬度的管理和维护,增加、删除和修改纬度的属性时,不必对事实表的大量记录进行改动
3.纬度表可以为多个事实表同时使用,减少重复工作
根据事实表和纬度表的关系,又可以将常见的模型分为星型模型 和 雪花模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。
当所有纬度表都直接连到“事实表”上时,整个图形就像星星一样,故将该模型称为型模型,如图所示。
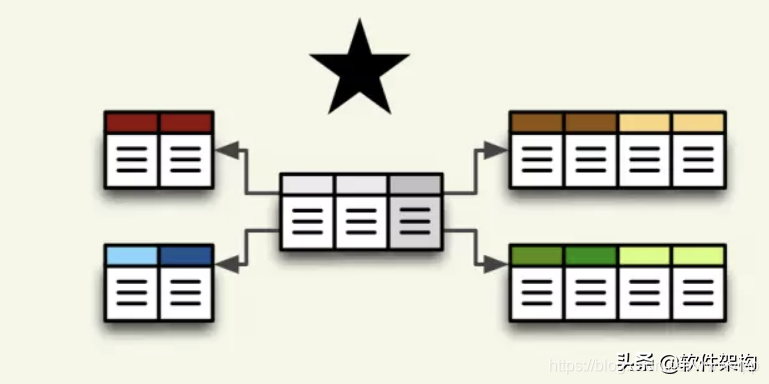
星型模型是一种非正规化的结构,多维数据集的每一个纬度都直接与事实表相连接,不存在渐变纬度,所以数据有一定的冗余,如在地域纬度表中,存在国家A省B的城市C,以及国家A省B的城市D两条记录,那么国家A省B的信息分别存储了两次,即存在冗余。
当有一个或多个纬度没有直接连接到事实表上,而是通过其它纬度表连接到事实表上时,其图解就像多个雪花连接在一起,故城雪花模型,雪花模型是对星型模型的扩展,它对星型模型的纬度表进一步层次化,原有的各纬度表可能被扩展为小的事实表,形成一些局部的“层次”区域,这些被分解
的表都连接到纬度表而不是事实表。
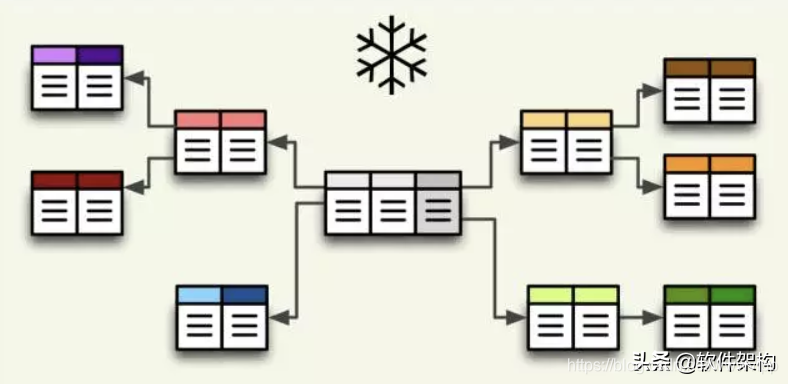
将地域表又分解为国家,省份,城市等纬度。它的优点是:通过最大限度的减少数据存储量以及联合较小的纬度表来改善查询性能。雪花型结构去除了数据冗余。
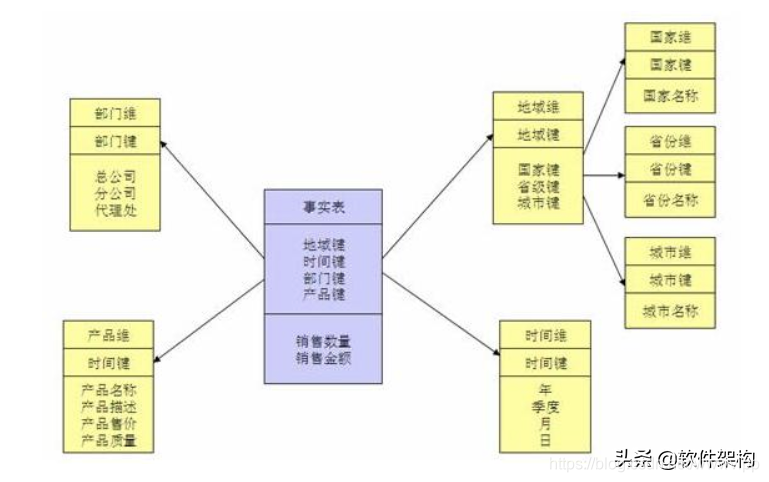
根据项目经验,一般建议使用星型模型,因为在实际项目中,往往最关注的是查询性能问题,至于磁盘空间一般都不是问题。当然,在纬度表数量较大,需要节省存储空间的情况下,或者业务逻辑比较复杂,必须要体现清晰的层次概念情况下,可以使用雪花型模型
四、纬度和度量
前面有介绍过纬度和度量的概念,这里再次回顾下这个基本概念
纬度:即观察数据的角度
纬度是人们观察数据的特定角度,是考虑问题时的一类属性。它通常是数据记录的一个特征,如时间、地点等。同时,纬度具有层级概念,可能存在细节程度不同的描述方面,如日期、月份、季度、年份等。
度量:即被聚合(观察)的统计值,也就是聚合运算的结果
在数据仓库中,可以在数学上求和的事实属性称为度量。例如,可以对度量进行总计、平均、以百分比形式使用等。度量是纬度模型的核心。通常,在单个查询中检索数千个或数百万个事实行,其中对结果集进行数数学方程。
在一个SQL查询中,Group By的属性通常就是纬度,而其所计算的值则是度量。
纬度的基数(Cardinality)指的是该纬度在数据集中出现的不同值的个数。例如,”国家“是一个纬度,有200个不同的值,那么此纬度的基数是200.通常,一个纬度的基数为几十到几万,个别纬度如“用户ID”的基数会超过百万甚至千万,基础超过一百万的纬度通常称为超过基数纬度(Ultra High Cardinality,UHC),需要引起设计者的注意。
Cube中所有纬度的基数可以体现Cube的复杂度,如果一个Cube中有多个超高基数纬度,那么这个Cube膨胀的几率就会很高,在创建Cube前对所有纬度的基数做一个了解,可以帮助设计合理的Cube。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/130235.html

