
一. 一些基础问题
- 什么是字符串的模式匹配?
给定两个串S=“s1s2s3 …sn”和T=“t1t2t3 …tn”,在主串S中寻找子串T的过程叫做模式匹配,T称为模式。 - 如何寻找?
我们先从比较好理解的暴力匹配(朴素模式匹配BF算法)开始,进而引出KMP算法
二 暴力匹配(朴素模式匹配BF)
规定i是主串S的下标,j是模式T的下标。现在假设现在主串S匹配到 i 位置,模式串T匹配到 j 位置。
如果当前字符匹配成功(即S[i] = T[j]),则i++,j++,继续匹配下一个字符;
如果失配(即S[i] != T[j]),令i = i – (j – 1),j = 0。相当于每次匹配失败时,i 回溯到本次失配起始字符的下一个字符,j 回溯到0。
int BF(char S[],char T[])
{
int i=0,j=0;
while(S[i]!='\0'&&T[j]!='\0')
{
if(S[i]==T[j])
{
i++;
j++;
}
else
{
i=i-j+1;
j=0;
}
}
if(T[j]=='\0') return (i-j); //主串中存在该模式返回下标号
else return -1; //主串中不存在该模式
}
我们用一个例子来说明一些这个算法:现在有主串S:ababcabcacbab,模式串T:abcac。我们来看一下是如何匹配的。i从0开始,j也从0开始。
在第一次匹配中,i从0开始,j从0开始。当i=2,j=2时匹配失败,此时i回溯到1,j回溯到0。
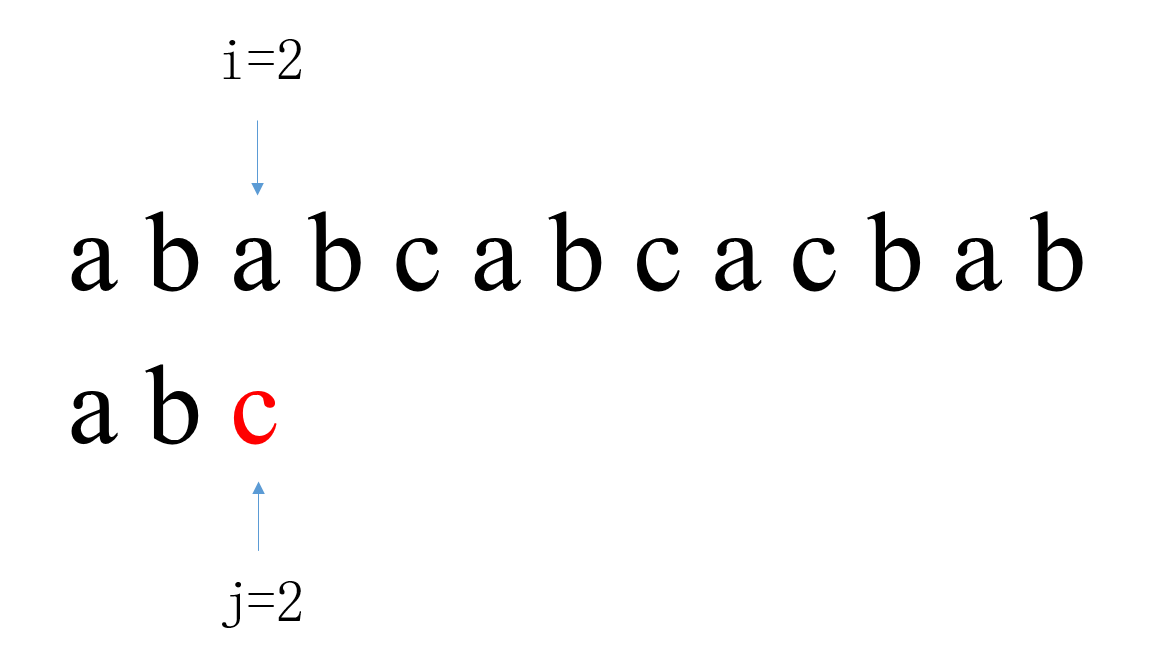 第二次匹配中,i从1开始,j从0开始。当i=1,j=0时匹配失败,此时i回溯到2,j回溯到0。
第二次匹配中,i从1开始,j从0开始。当i=1,j=0时匹配失败,此时i回溯到2,j回溯到0。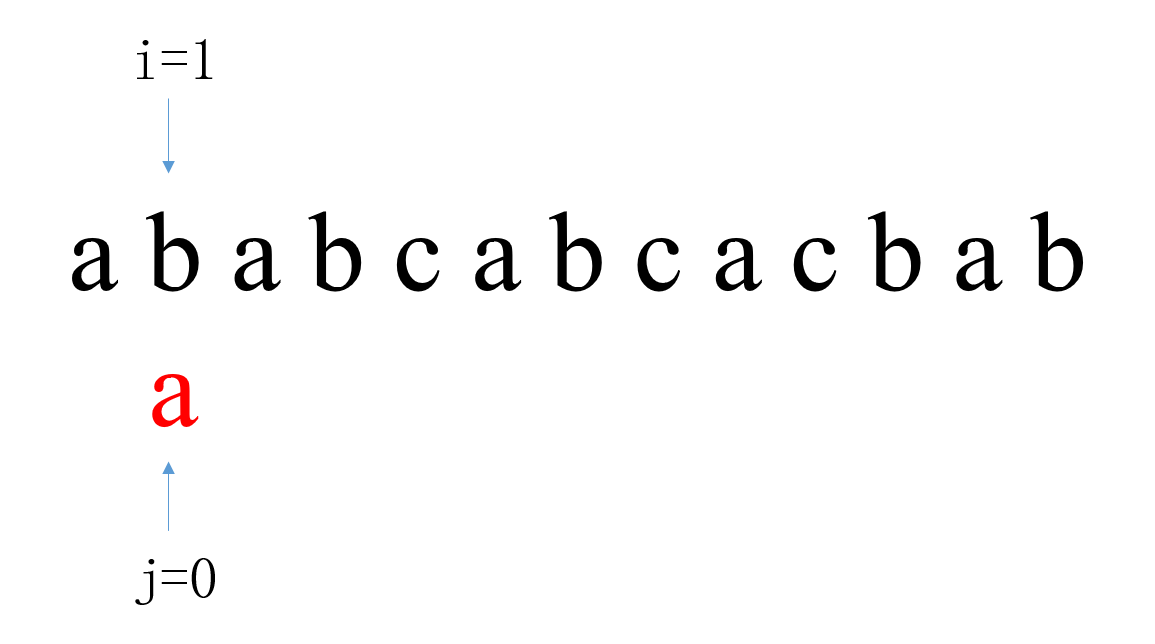 第三次匹配中,i从2开始,j从0开始。当i=6,j=4时匹配失败,此时i回溯到3,j回溯到0。
第三次匹配中,i从2开始,j从0开始。当i=6,j=4时匹配失败,此时i回溯到3,j回溯到0。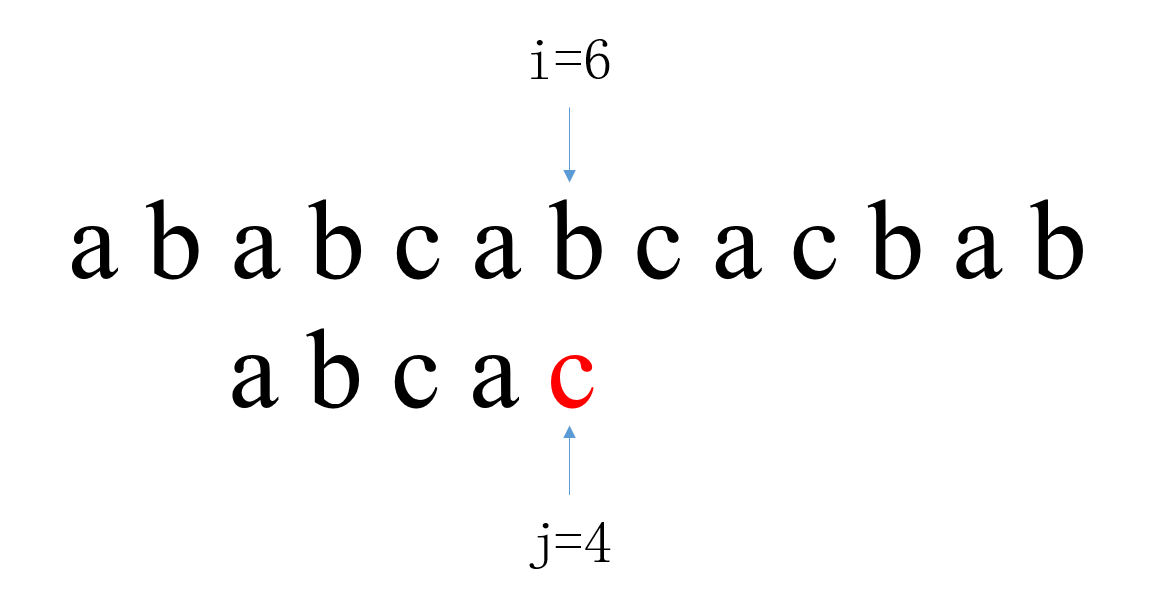 第四次匹配中,i从3开始,j从0开始。当i=3,j=0时匹配失败,此时i回溯到4,j回溯到0。
第四次匹配中,i从3开始,j从0开始。当i=3,j=0时匹配失败,此时i回溯到4,j回溯到0。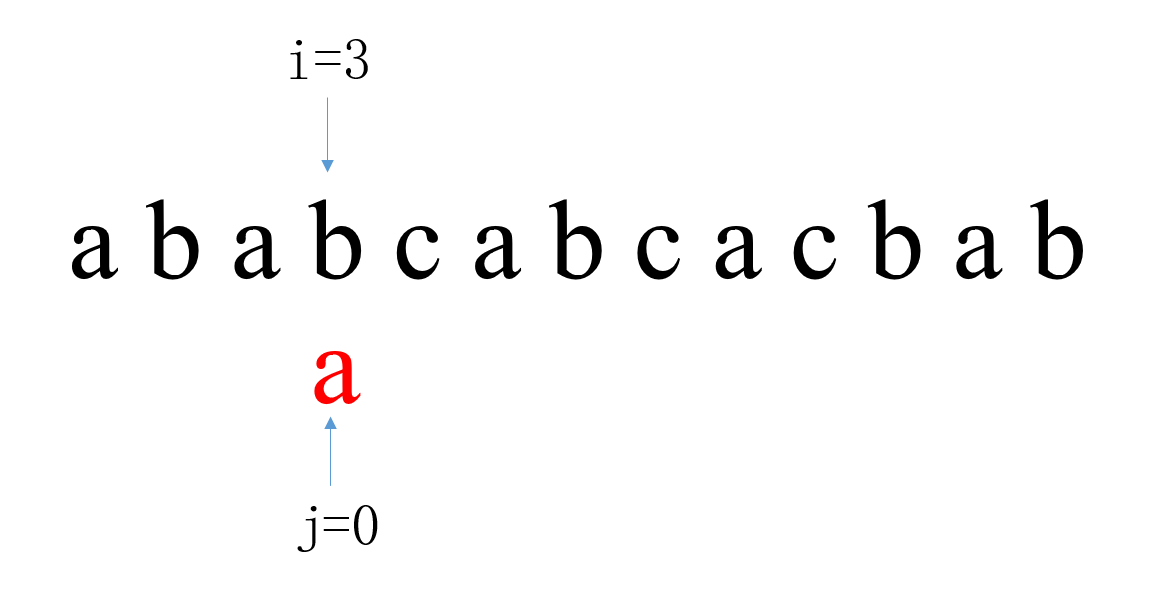 第五次匹配中,i从4开始,j从0开始。当i=4,j=0时匹配失败,此时i回溯到5,j回溯到0。
第五次匹配中,i从4开始,j从0开始。当i=4,j=0时匹配失败,此时i回溯到5,j回溯到0。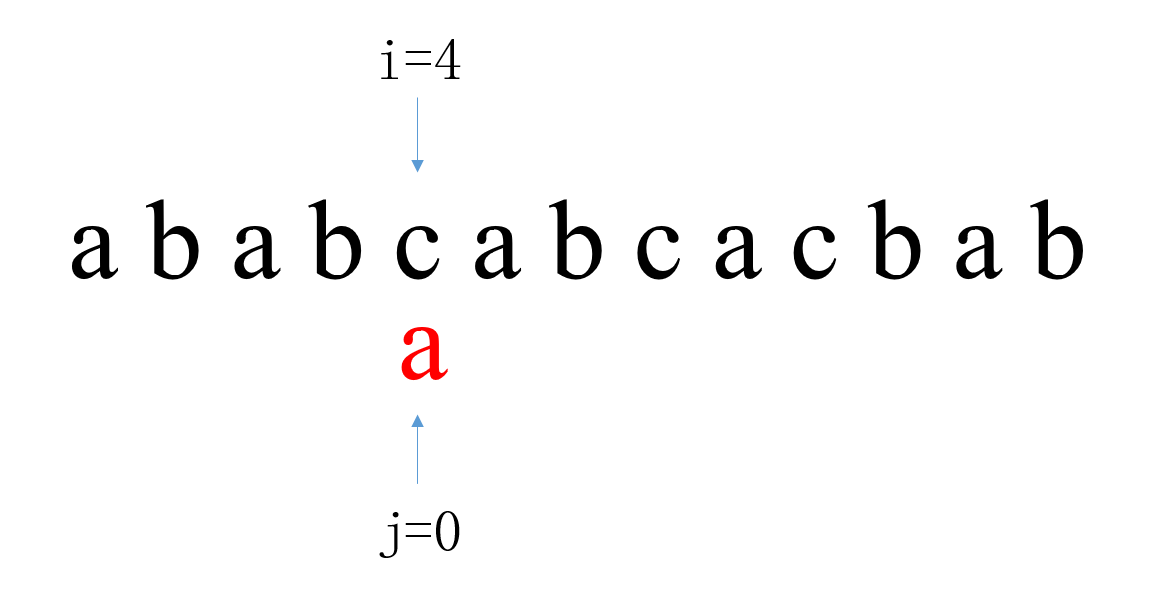 第六次匹配中,i从5开始,j从0开始。i=10,j=5,T中全部字符比较完,匹配成功,返回本次匹配起始位置下标i – j。(i=9和j=4的时候匹配成功,i和j会再加一次,所以i=10,j=5)
第六次匹配中,i从5开始,j从0开始。i=10,j=5,T中全部字符比较完,匹配成功,返回本次匹配起始位置下标i – j。(i=9和j=4的时候匹配成功,i和j会再加一次,所以i=10,j=5)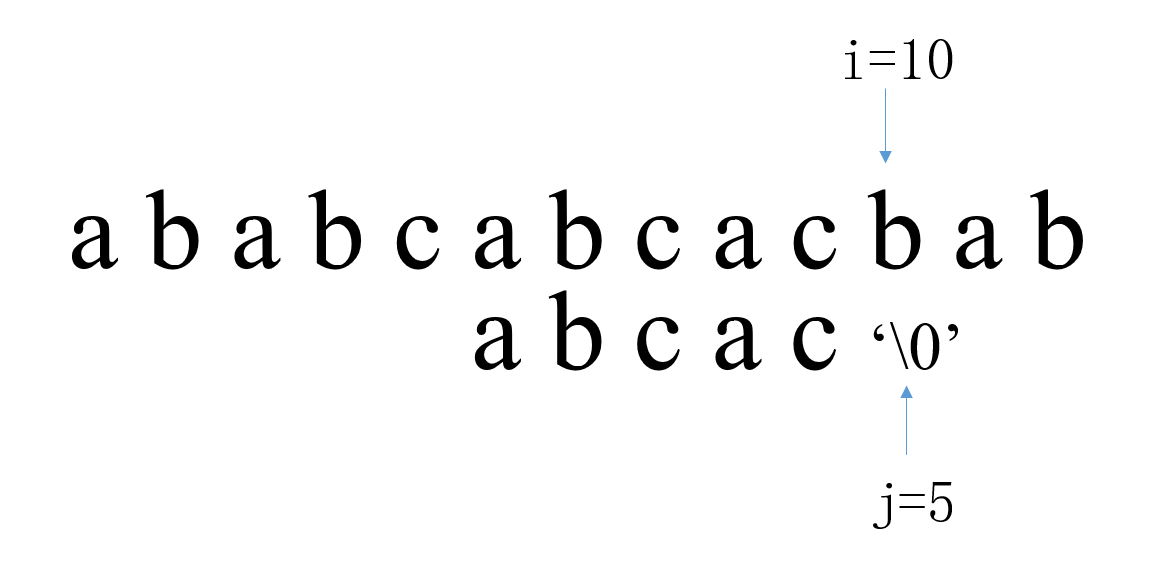 可见,如果i已经匹配了一段字符后出现了失配的情况,i会重新往回回溯,j又从0开始比较。这样浪费的大量的时间。在第三次匹配结束后,我们可以发现:i=3和j=0,i=4和j=0以及i=5和j=0是不必进行的,因为从第三次部分匹配过程中我们可以得出,主串中第3,4,5个字符必然是‘b’,‘c’,‘a’(即与模式串的第1,2,3个字符分别对应相等),而模式的首字符是‘a’,它分别与‘b’,‘c’不等,与‘a’相等。如果将模式向右滑动3个字符继续进行i=6和j=1时的字符比较,很明显会加快进程。这样就引出了我们的KMP算法,不回溯i,加快匹配效率。
可见,如果i已经匹配了一段字符后出现了失配的情况,i会重新往回回溯,j又从0开始比较。这样浪费的大量的时间。在第三次匹配结束后,我们可以发现:i=3和j=0,i=4和j=0以及i=5和j=0是不必进行的,因为从第三次部分匹配过程中我们可以得出,主串中第3,4,5个字符必然是‘b’,‘c’,‘a’(即与模式串的第1,2,3个字符分别对应相等),而模式的首字符是‘a’,它分别与‘b’,‘c’不等,与‘a’相等。如果将模式向右滑动3个字符继续进行i=6和j=1时的字符比较,很明显会加快进程。这样就引出了我们的KMP算法,不回溯i,加快匹配效率。
三. KMP算法
.背景
KMP算法一种改进的模式匹配算法,是D.E.Knuth、V.R.Pratt、J.H.Morris于1977年联合发表,KMP算法又称克努特-莫里斯-普拉特操作。它的改进在于:每当从某个起始位置开始一趟比较后,在匹配过程中出现失配,不回溯i,而是利用已经得到的部分匹配结果,将一种假想的位置定位“指针”在模式上向右滑动尽可能远的一段距离到某个位置后,继续按规则进行下一次的比较。
简要:
- 什么是前缀表
- 为什么一定要用前缀表
- 如何计算前缀表
- 前缀表与next数组
- 使用next数组来匹配
- 时间复杂度分析
- 构造next数组
- 使用next数组来做匹配
- 前缀表统一减一 C++代码实现
- 前缀表(不减一)C++实现
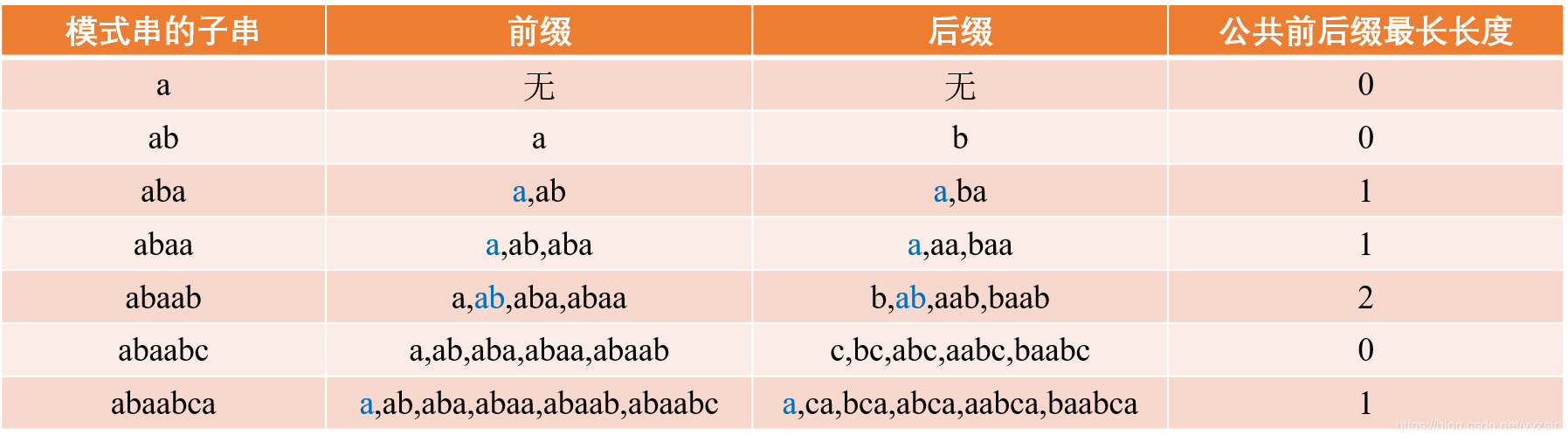
前缀 后缀 最长公共前后缀
前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串
最长公共前后缀:因为前缀表要求的就是相同前后缀的长度
前缀表与next数组
很多KMP算法的时间都是使用next数组来做回退操作,那么next数组与前缀表有什么关系呢?
next数组就可以是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为-1)之后作为next数组。
为什么这么做呢,其实也是很多文章视频没有解释清楚的地方。
其实这并不涉及到KMP的原理,而是具体实现,next数组即可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。
后面我会提供两种不同的实现代码,大家就明白了。
构造next数组
构造next数组其实就是计算模式串s,前缀表的过程。 主要有如下三步:
- 初始化
- 处理前后缀不相同的情况
- 处理前后缀相同的情况
接下来我们详解详解一下。
- 初始化:
定义两个指针i和j,j指向前缀末尾位置,i指向后缀末尾位置。
int j=-1;
int next[0]=jj 为什么要初始化为 -1呢,因为之前说过 前缀表要统一减一的操作仅仅是其中的一种实现,我们这里选择j初始化为-1.
- 处理前后缀不相同的情况
因为j初始化为-1,那么i就从1开始,进行s[i] 与 s[j+1]的比较。
所以遍历模式串s的循环下标i 要从 1开始,代码如下
for(int i=0;i<s.size();i++)如果 s[i] 与 s[j+1]不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回退。
怎么回退呢?
next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度。
那么 s[i] 与 s[j+1] 不相同,就要找 j+1前一个元素在next数组里的值(就是next[j])。
所以,处理前后缀不相同的情况代码如
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
3.处理前后缀相同的情况
如果 s[i] 与 s[j + 1] 相同,那么就同时向后移动i 和j 说明找到了相同的前后缀,同时还要将j(前缀的长度)赋给next[i], 因为next[i]要记录相同前后缀的长度。
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j;最后整体构建next数组的函数代码如下:
void getNext(int* next, const string& s){
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}使用Next数组来做匹配
在文本串s里 找是否出现过模式串t。
定义两个下标j 指向模式串起始位置,i指向文本串起始位置。
那么j初始值依然为-1,为什么呢? 依然因为next数组里记录的起始位置为-1。
i就从0开始,遍历文本串,代码如下:
int j = -1; // 因为next数组里记录的起始位置为-1
for (int i = 0; i < s.size(); i++) { // 注意i就从0开始
while(j >= 0 && s[i] != t[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
if (s[i] == t[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (t.size() - 1) ) { // 文本串s里出现了模式串t
return (i - t.size() + 1);
}
}前缀表统一减一 C++代码实现
lass Solution {
public:
void getNext(int* next, const string& s) {
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
int strStr(string haystack, string needle) {
if (needle.size() == 0) {
return 0;
}
int next[needle.size()];
getNext(next, needle);
int j = -1; // // 因为next数组里记录的起始位置为-1
for (int i = 0; i < haystack.size(); i++) { // 注意i就从0开始
while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t
return (i - needle.size() + 1);
}
}
return -1;
}
};版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/129652.html

