
8.2 整合DruidDataSource数据源
- Spring Boot 2.x 默认使用 HikariCP 作为数据源,在项目中导入了 Spring Boot 的 JDBC 场景启动器,便可以使用 HikariCP 数据源获取数据库连接,对数据库进行增删改查等操作。
- HikariCP 是目前市面上性能最好的数据源产品,但在实际的开发过程中,企业往往更青睐于另一款数据源产品:Druid,它是目前国内使用范围最广的数据源产品。
- Druid简介:Druid是阿里巴巴开源平台上一个数据库连接池实现,结合了C3PO、DBCP、PROXOOL等DB池的优点,同时加入了日志监控。Druid 支持所有 JDBC 兼容的数据库,包括 Oracle、MySQL、SQL Server 和 H2 等等。
- Druid的监控功能,可以实时观察数据库连接池和 SQL 的运行情况,帮助用户及时排查出系统中存在的问题,天生就是针对监控而生的DB连接池。
- Spring Boot2.0以上默认使用Hikari数据源,可以说Hikari与Driud都是当前Java Web上最优秀的数据源,我们来重点介绍Spring Boot如何集成Druid数据源,如何实现数据库监控。
- com.alibaba.druid.pool.DruidDataSource基本配置参数如下:
| 字段 | 默认值 | 说明 |
|---|---|---|
| url | 连接数据库的url,不同数据库连接字符串不一样 | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码 | |
| driverClassName | 数据库驱动,这一项可配可不配,默认可根据URL自动识别,Druid会根据url自动识别dbType,然后选择相应的driverClassName。 | |
| initialSize | 0 | 启动池时创建的初始连接数,初始化发生在显示调用init方法或者第一次getConnection时。 |
| maxAtivce | 8 | 最大连接数 |
| minIdle | 0 | 最小连接数 |
| maxWait | 无限期 | 没有可用连接时,最大等待时间(毫秒) ,-1:无限期等待 |
| validationQuery | 检测连接是否有效的SQL,必须是一个查询语句,常用SELECT ‘X’。若validationQuery为null,则testOnBorrow、testOnReturn、testWhileIdle等配置不起作用。 | |
| validationQueryTimeout | no timeout | 检测连接是否有效的超时时间(秒)。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法 |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 60000 | 有两个含义:一个是desdtroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接;另一个是testWhileIdle的判断依据,详细看testWhileIdle属性的说明,单位毫秒 |
| minEvictableIdleTimeMillis | 连接保持空闲而不被驱逐的最小时间(毫秒) | |
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 默认根据dbType自动识别。当数据库抛出一些不可恢复的异常时,抛弃连接。 | |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有:监控统计用的filter:stat、日志用的filter:log4j、防御sql注入的filter:wall。 | |
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系。 | |
| asyncInit | 如果有initialSize数量较多时,打开会加快应用启动时间。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxPoolPreparedStatementPerConnectionSize | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100。 |
| removeAbandoned | 当程序存在缺陷时,申请的连接忘记关闭,这时候,就存在连接泄漏了。Druid提供了RemoveAbandanded相关配置,用来关闭长时间不使用的连接。注:配置removeAbandoned对性能会有一些影响,建议怀疑存在泄漏之后再打开。在上面的配置中,如果连接超过30分钟未关闭,就会被强行回收,并且日志记录连接申请时的调用堆栈。 | |
| removeAbandonedTimeout | 连接超时多长时间关闭(毫秒) | |
| logAbandoned | 关闭abandoned连接时输出错误日志。 |
- Druid 不是 Spring Boot 内部提供的技术,它属于第三方技术,我们可以通过以下两种方式进行整合:
- 自定义整合 Druid
- 通过 starter 整合 Druid
8.2.1 自定义整合 Druid
-
自定义整合 Druid 是指:根据 Druid 官方文档和自身的需求,通过手动创建 Druid 数据源的方式,将 Druid 整合到 Spring Boot 中。
-
导入com.alibaba.druid依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.11</version>
</dependency>
-
druid包结构:filter过滤包、mock测试用的包、pool池
-
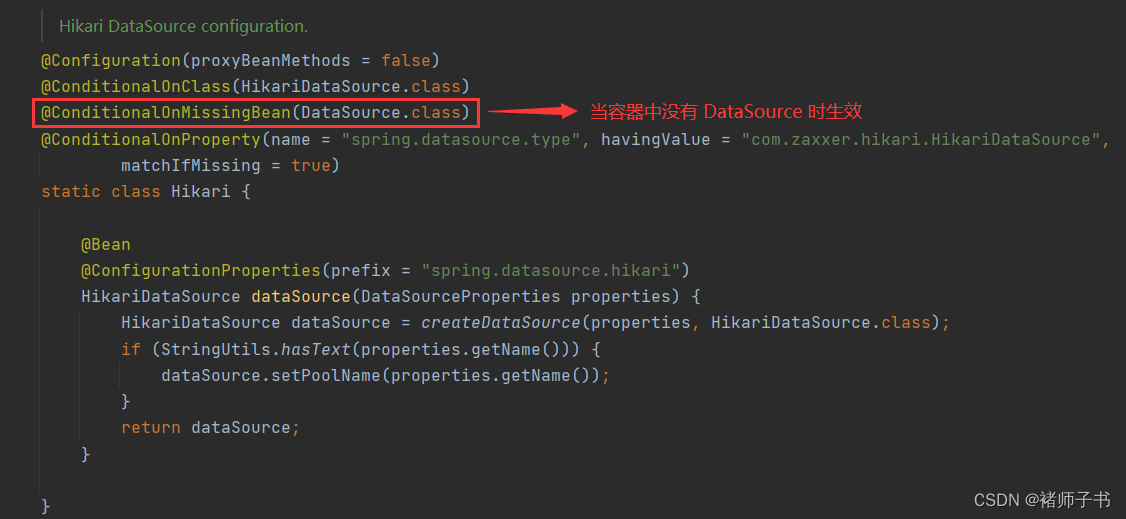
Spring Boot 使用 HikariCP 作为其默认数据源,但其中有一个十分重要的条件
@ConditionalOnMissingBean(DataSource.class) 的含义是:当容器中没有 DataSource(数据源类)时,Spring Boot 才会使用 HikariCP 作为其默认数据源。 也就是说,若我们向容器中添加 Druid 数据源类(DruidDataSource,继承自 DataSource)的对象时,Spring Boot 就会使用 Druid 作为其数据源,而不再使用 HikariCP。

- 创建一个名为 DruidConfig的配置类,并将 Druid 数据源对象添加到容器中
@Configuration
public class DruidConfig {
//注册配置自定义的DruidDataSource,供后续后台监控和过滤使用和链接数据库执行sql使用
//使用 @ConfigurationProperties 将配置文件中 spring.datasource 开头的配置与数据源中的属性进行绑定
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource(){
return new DruidDataSource();
}
}
我们一般不建议将数据源属性硬编码到代码中,而应该在配置文件中进行配置(@ConfigurationProperties 绑定) druidDataSource.setUrl(“jdbc:mysql://localhost:3306/jdbcstudy?useSSL=true&useUnicode=true&characterEncoding=utf-8&serverTimeZone=UTC”);
druidDataSource.setUsername(“root”);
druidDataSource.setPassword(“123456”);
druidDataSource.setDriverClassName(“com.mysql.cj.jdbc.Driver”);
注:配置类创建 Druid 数据源对象时,应该尽量避免将数据源信息(例如 url、username 和 password 等)硬编码到代码中,而应该通过 @ConfigurationProperties(“spring.datasource”) 注解,将 Druid 数据源对象的属性与配置文件中的以“spring.datasource”开头的配置进行绑定。
- 之后在application.yml,指定数据源为DruidDataSource,制定了type那么数据源就是指定的类型
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql://localhost:3306/jdbcstudy?useSSL=true&useUnicode=true&characterEncoding=utf-8&serverTimeZone=UTC
type: com.alibaba.druid.pool.DruidDataSource
#SpringBoot默认是不注入这些的,需要自己绑定
#druid数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许报错,java.lang.ClassNotFoundException: org.apache.Log4j.Priority
#则导入log4j 依赖就行
filters: stat,wall,log4j2
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
- 测试下数据源类型是否为 Druid
@SpringBootTest
class SpringbootData03ApplicationTests {
@Autowired
DataSource dataSource;
@Test
void contextLoads() throws SQLException {
//查看默认的数据源 com.zaxxer.hikari.HikariDataSource dbcp/c3p0/druid
System.out.println(dataSource.getClass());
//获得数据库链接
Connection connection = dataSource.getConnection();
//com.mysql.cj.jdbc.ConnectionImpl@4451f60c
System.out.println(connection);
//关闭链接
connection.close();
}
//控制台输出
//class com.alibaba.druid.pool.DruidDataSource
//com.alibaba.druid.proxy.jdbc.ConnectionProxyImpl@4645679e
}
- 导入springboot中自带了log4j2
<!--springboot中自带了log4j-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
- 开启 Druid 内置监控页面
Druid 内置提供了一个名为 StatViewServlet 的 Servlet,这个 Servlet 可以开启 Druid 的内置监控页面功能, 展示 Druid 的统计信息,它的主要用途如下:
- 提供监控信息展示的 html 页面
- 提供监控信息的 JSON API
注意:使用 StatViewServlet,建议使用 Druid 0.2.6 以上版本。
- 根据 Druid 官方文档-配置_StatViewServlet 配置,StatViewServlet 是一个标准的 javax.servlet.http.HttpServlet,想要开启 Druid 的内置监控页面,需要将该 Servlet 配置在 Web 应用中的 WEB-INF/web.xml 中,web.xml 中配置如下。
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
-
Spring Boot 项目中是没有 WEB-INF/web.xml 的,因此我们可以在配置类中,通过 ServletRegistrationBean 将 StatViewServlet 注册到容器中,来开启 Druid 的内置监控页面。如下配置
-
配置druid的后台监控页面(将 StatViewServlet 注入到容器中)及账户初始化信息和过滤功能的实现
package com.zk.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.servlet.Filter;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* @author CNCLUKZK
* @create 2022/8/3-13:52
*/
@Configuration
public class DruidConfig {
//注册配置自定义的DruidDataSource,供后续后台监控和过滤使用和链接数据库执行sql使用
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource(){
return new DruidDataSource();
}
//后台监控: Servlet注册bean,相当于web.xml
//springboot内置了Servlet容器,所以没有web.xml,ServletRegistrationBean这种注册bean方式是web.xml的替代
// 但若要给Servlet容器扩展其他的功能,如:将druid监控功能的bena注册进去
@Bean
public ServletRegistrationBean statViewServlet(){
//访问这个路径,就进入了后台监控页面,页面已经做好,可以访问就用
ServletRegistrationBean<StatViewServlet> servletRegistrationBean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
Map<String, String> initParameters = new HashMap<>();
//配置后台登陆用户,key是默认的不可改,账号密码配置和shiro和security的配置类似
initParameters.put("loginUsername","admin");
initParameters.put("loginPassword","123456");
//配置谁可以访问
//不写谁都可以访问
//localhost只有本机访问
//具体的人只有此人可以访问
initParameters.put("allow","");
//配置谁不可以访问 initParameters.put("zk","192.168.1.2");
//设置初始化参数
servletRegistrationBean.setInitParameters(initParameters);
return servletRegistrationBean;
}
//过滤功能
@Bean
public FilterRegistrationBean filterRegistrationBean(){
FilterRegistrationBean<Filter> filterFilterRegistrationBean = new FilterRegistrationBean<>();
//设置一个com.alibaba.druid.support.http.WebStatFilter过滤器
filterFilterRegistrationBean.setFilter(new WebStatFilter());
//可以过滤那些请求
Map<String, String> initParameters = new HashMap<>();
//key从WebStatFilter中获取
//这些静态资源不进行过滤
initParameters.put("exclusions","*.js,*.css,/druid/*");
filterFilterRegistrationBean.setInitParameters(initParameters);
return filterFilterRegistrationBean;
}
}
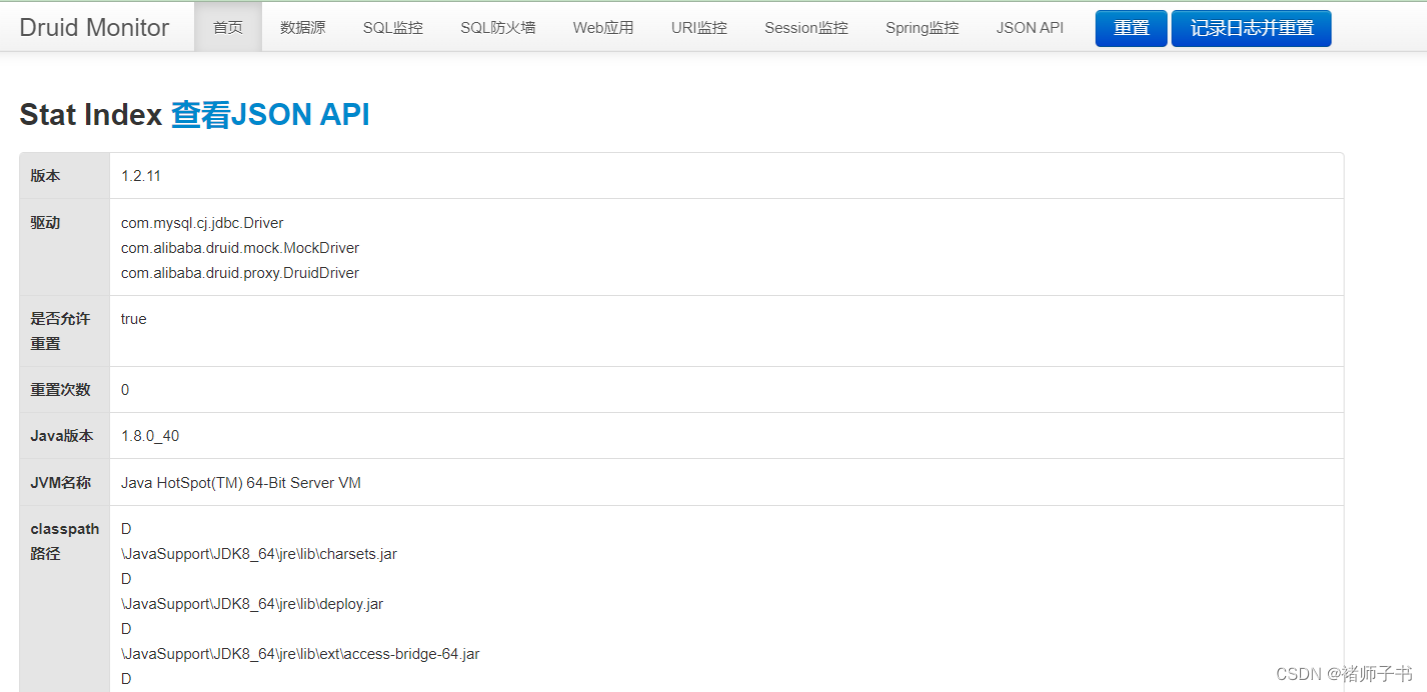
- 然后访问http://127.0.0.1:8080/druid/输入账号密码(admin/123456)进入,可以看到druid的监控后台
- 开启开启 SQL 监控,Druid 内置提供了一个 StatFilter,通过它可以开启 Druid 的 SQL 监控功能,对 SQL 进行监控。
- StatFilter 的别名是 stat,这个别名的映射配置信息保存在 druid-xxx.jar!/META-INF/druid-filter.properties 中。Druid 官方文档-配置_StatFilter 中给出了在 Spring 中配置该别名(stat)开启 Druid SQL 监控的方式,配置如下。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
... ...
<property name="filters" value="stat" />
</bean>
- 所以只要在 dataSource 的 Bean 中添加一个取值为“stat”的“filters”属性,就能开启 Druid SQL 监控,因此我们只要将该配置转换为在配置类中进行即可 。
//注册配置自定义的DruidDataSource,供后续后台监控和过滤使用和链接数据库执行sql使用
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource(){
DruidDataSource druidDataSource = new DruidDataSource();
//设置 filters 属性值为 stat,开启 SQL 监控
druidDataSource.setFilters("stat");
return druidDataSource;
}
- 但一般我们配置在application.yml文件中,即
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许报错,java.lang.ClassNotFoundException: org.apache.Log4j.Priority
#则导入log4j 依赖就行
filters: stat,wall,log4j2
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
- 然后在访问下业务功能http://127.0.0.1:8080/userList,控制器如下,数据库数据可以自定义
@RestController
public class JdbcController {
@Autowired
JdbcTemplate jdbcTemplate;
@GetMapping("/userList")
public List<Map<String, Object>> getUserList(){
//查询数据库的所有信息
//没有实体类,数据库中的东西,怎么获取?Map
String sql = "select * from jdbcstudy.users";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
return maps;
}
}

- 访问 Druid 的内置监控页面,切换到 SQL 监控模块,可以看到 Druid SQL 监控已经开启,然后发现sql监控台出现了这条sql的执行记录

- 开启防火墙
- Druid 内置提供了一个 WallFilter,使用它可以开启防火墙功能,防御 SQL 注入攻击。
- WallFilter 的别名是 wall,这个别名映射配置信息保存在 druid-xxx.jar!/META-INF/druid-filter.properties 中。Druid 官方文档-配置 wallfilter 中给出了在 Spring 中使用该别名(wall)开启防火墙的方式,配置如下。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
... ...
<property name="filters" value="wall" />
</bean>
-
WallFilter 可以结合其他 Filter 一起使用,例如:
-
所以只要在 dataSource 的 Bean 中添加一个取值为“wall”的“filters”属性,就能开启 Druid 的防火墙功能,因此我们只需要在配置类中为 dataSource 的 filters 属性再添加一个“wall”即可(多个属性值之间使用逗号“,”隔开),也可以在application.yml文件中配置。
//注册配置自定义的DruidDataSource,供后续后台监控和过滤使用和链接数据库执行sql使用
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource(){
DruidDataSource druidDataSource = new DruidDataSource();
//设置 filters 属性值为 stat,开启 SQL 监控
druidDataSource.setFilters("stat","wall");
return druidDataSource;
}
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许报错,java.lang.ClassNotFoundException: org.apache.Log4j.Priority
#则导入log4j 依赖就行
filters: stat,wall,log4j2
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
- 访问 Druid 的内置监控页面,切换到 SQL 防火墙,可以看到 Druid 防火墙已经开启,如下图

-
开启 Web-JDBC 关联监控
-
Druid 还内置提供了一个名为 WebStatFilter 的过滤器,它可以用来监控与采集 web-jdbc 关联监控的数据。
-
根据 Druid 官方文档-配置_配置WebStatFilter,想要开启 Druid 的 Web-JDBC 关联监控,只需要将 WebStatFilter 配置在 Web 应用中的 WEB-INF/web.xml 中即可,web.xml 配置如下。
<filter>
<filter-name>DruidWebStatFilter</filter-name>
<filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class>
<init-param>
<param-name>exclusions</param-name>
<param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>DruidWebStatFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
- Spring Boot 项目中是没有 WEB-INF/web.xml 的,但是我们可以在配置类中,通过 FilterRegistrationBean 将 WebStatFilter 注入到容器中,来开启 Druid 的 Web-JDBC 关联监控。
//过滤功能
// 向容器中添加 WebStatFilter
//开启内置监控中的 Web-jdbc 关联监控的数据
@Bean
public FilterRegistrationBean filterRegistrationBean(){
FilterRegistrationBean<Filter> filterFilterRegistrationBean = new FilterRegistrationBean<>();
//设置一个com.alibaba.druid.support.http.WebStatFilter过滤器
filterFilterRegistrationBean.setFilter(new WebStatFilter());
//监控所有的访问
filterFilterRegistrationBean.setUrlPatterns(Arrays.asList("/*"));
//可以过滤那些请求
Map<String, String> initParameters = new HashMap<>();
//key从WebStatFilter中获取
//这些静态资源不进行过滤
initParameters.put("exclusions","*.js,*.css,/druid/*");
filterFilterRegistrationBean.setInitParameters(initParameters);
return filterFilterRegistrationBean;
}
- 然后在访问下业务功能http://127.0.0.1:8080/userList,

- 然后再访问 Druid 的内置监控页面,切换到 Web 应用模块,可以看到 Druid 的 Web 监控已经开启,如下图

- 同时,URI 监控和 Session 监控也都被开启

下一篇:SpringBoot-25-整合持久层-通过Spring Boot starter 整合 Druid
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/123847.html

