
5.8 Eureka 自我保护机制
-
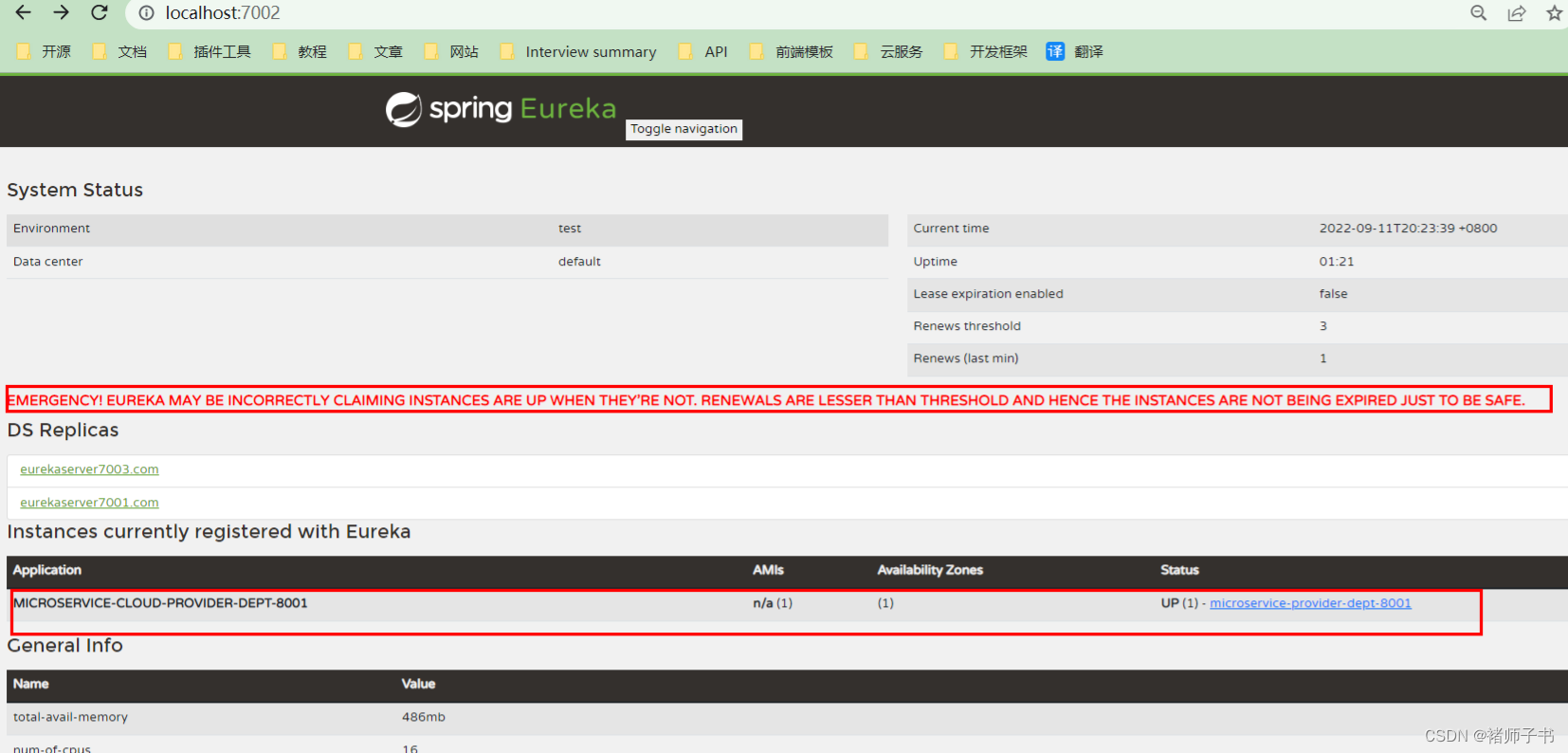
当我们在本地调试基于 Eureka 的程序时,Eureka 服务注册中心很有可能会出现如下图所示的红色警告


-
实际上,这个警告是触发了 Eureka 的自我保护机制而出现的。默认情况下,如果 Eureka Server 在一段时间内(默认为 90 秒)没有接收到某个服务提供者(Eureka Client)的心跳,就会将这个服务提供者提供的服务从服务注册表中注销该实例。 这样服务消费者就再也无法从服务注册中心中获取到这个服务了,更无法调用该服务。
-
但是当网络分区故障(例如网络延迟、卡顿、拥挤等原因)发生时,微服务与Eureka之间无法正常通讯,此时 Eureka Server 因为没有接收心跳而误将健康的服务从服务列表中移除可能变得非常危险了,因为微服务本身其实是健康的,此时本不应该注销这个服务。Eureka通过自我保护机制来解决这个问题。
-
所谓 “Eureka 的自我保护机制”,当EurekaServer节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。一旦进入该模式,EurekaServer就会保护服务注册表中的信息,不再删除服务注册表中的数据(也就是不会注销任何微服务)。当网络故障恢复后,该EurekaServer节点会自动退出自我保护模式。一旦网络恢复即当它收到的心跳数重新恢复到阈值以上时,该EurekaServer节点就会自动退出自我保护模式这些 Eureka Client 提供的服务还可以继续被服务消费者消费。
-
综上,自我保护模式是一种应对网络异常的安全保护措施。它的架构哲学是宁可同时保留所有微服务注册信息(健康的微服务和不健康的微服务都会保留),也不盲目注销任何健康的微服务实例。这也是一种熔断机制,断连达到85%以下的服务才会开启自我保护。使用自我保护模式,可以让Eureka集群更加的健壮和稳定
-
在SpringCloud中,默认情况下,Eureka 的自我保护机制是开启的,如果想要关闭,可以使用eureka.server.enable-self-preservation=false禁用自我保护模式【不推荐关闭自我保护机制】
eureka:
server:
enable-self-preservation: false # false 关闭 Eureka 的自我保护机制,默认是开启,一般不建议大家修改
-
我们通过一个例子,来验证下 Eureka 的自我保护机制
-
如果我们在 microservice-cloud-eureka-7001 的配置文件 application.yml 中添加以下配置,关闭 Eureka 的自我保护机制。
eureka:
instance:
hostname: eurekaserver7001.com #eureka7001.comeureka服务端的实例名称,主机名是否可以在配置时确定(否则将从操作系统原语中猜测)
client:
register-with-eureka: false #false表示不向注册中心注册自己。
fetch-registry: false #指示此客户端是否应从 eureka 服务器获取 eureka 注册表信息
service-url: #监控页面地址
#defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/ #发布的服务注册中心地址,单机
defaultZone: http://eurekaserver7002.com:7002/eureka/,http://eurekaserver7003.com:7003/eureka/ #集群版 将当前的 Eureka Server 注册到 7003 和 7003 上,形成一组互相注册的 Eureka Server 集群
server:
enable-self-preservation: false # false 关闭 Eureka 的自我保护机制,默认是开启,一般不建议大家修改
-
集群中的 microservice-cloud-eureka-7002 和 microservice-cloud-eureka-7003 不作任何修改,即它们的自我保护机制是开启的。
-
重启 Eureka Server 集群以及 服务提供者microservice-cloud-provider-dept-8001,使用浏览器访问“http://eureka7001.com:7001/”,结果如下图。

-
在 DS Replicas 选项上面出现了红色警告信息“THE SELF PRESERVATION MODE IS TURNED OFF. THIS MAY NOT PROTECT INSTANCE EXPIRY IN CASE OF NETWORK/OTHER PROBLEMS”,出现该信息则表示“ Eureka 自我保护模式已关闭。而集群中的 microservice-cloud-eureka-7002 和 microservice-cloud-eureka-7003的自我保护模式不变
-
重启服务提供者microservice-cloud-provider-dept-8001重启时先关闭几分钟,再次访问“http://eureka7001.com:7001/”,结果如下图。

-
由上图可知,在 DS Replicas 选项上面出现了红色警告信息“RENEWALS ARE LESSER THAN THE THRESHOLD. THE SELF PRESERVATION MODE IS TURNED OFF. THIS MAY NOT PROTECT INSTANCE EXPIRY IN CASE OF NETWORK/OTHER PROBLEMS.”,出现该信息则表示 Eureka 的自我保护模式已关闭,且已经有服务被移除。
-
而访问“http://eureka7002.com:7002/”或“http://eureka7003.com:7003/”由于其自我保护模式未关闭,该注册中心的实例服务不会注销
Eureka 的自我保护机制也存在弊端。如果在 Eureka 自我保护机制触发期间,服务提供者提供的服务出现问题,那么服务消费者就很容易获取到已经不存在的服务进而出现调用失败的情况,此时,我们可以通过客户端的容错机制来解决此问题,详情请参考本专栏后续的章节 Ribbon和 Hystrix
5.9 CAP原则的选择
RDBMS关系型数据库需满足ACID原则:原子性、一致性、隔离性、持久性
分布式数据库NOSQL(Redis,MongDB)需满足CAP中的CP原则
-
CAP原则:指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三个要素最多同时实现两点不可能同时实现。
-
- C(Consistency)一致性:分布式系统中所有数据备份同一时刻值都相同。
- A(Availability)可用性:负载过大后,集群整体还能响应客户端的读写请求。
- P(Partition tolerance)分区容错性:分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。
-
由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。既然分布式系统中P肯定要满足,所以只能在CA中二选一没有最好的选择,最好的选择是根据业务场景来进行架构设计
如果要求一致性,则选择zookeeper,如金融行业;如果要求可用性,则Eureka,如电商系统
- 根据CAP原理,将NoSQL数据库分成了满足CA原则,满足CP原则和满足AP原则三大类
- CA :如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。单点集群,满足一致性,可用性的系统,通常可扩展性较差;放弃 P 的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。
- CP :如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。设计成 CP 的系统其实不少,最典型的就是分布式数据库,如 Redis、HBase 等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,没必要再浪费资源来部署分布式数据库。
- AP:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。典型的场景就如抢购畅销品的场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。
5.9.1 作为服务注册中心,Eurekab比Zookeeper对比?
- 著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)、P(容错性)。由于分区容错性P在分布式系统中是必须要保证的,因此我们只能在A和C之间进行权衡。
如果要求一致性,则选择zookeeper(Zookeeper保证的是CP),如金融行业;如果要求可用性,则Eureka(Eureka保证的是AP),如电商系统
-
对于分布式系统,当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。zookeeper恰恰是要求一致性高于可用性。
-
Zookeeper保证的是CP:master节点因为网络故障或者停电与其它节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30-120s,且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因为网络问题使得zk集群失去master节点是较大概率会发生的事件,虽然服务最终能够恢复,但是漫长的选举时间导致的注册中心长期不可用是不可容忍的
-
Eureka保证的是AP:Eureka各个节点是平等的,某个节点挂掉不会影响其它节点的正常工作,剩下的节点依然可以提供注册和查询的服务。而Eureka的客户端在向某个Eureka注册时,如果发现连接失败,则会自动切换到其它的节点,只要有一台Eureka节点还在,就能保证服务的可用性,只不过查到的信息可能不是最新的。Eureka可以很好的应对因为网络故障导致部分节点失去联系的情况,而不会像zookeeper这样使整个注册服务瘫痪
-
Eureka还有一种自我保护机制,如果15分钟之内超过85%的节点都没有正常的心跳,那么Eureka就会认为客户端现注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务;
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用);
- 当网络稳定时,当前实例新的注册信息会被同步到其它的节点中;
-
总结:现如今,对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,节点只会越来越多,所以节点故障、网络故障是常态,因此分区容错性也就成为了一个分布式系统必然要面对的问题。那么就只能在 C 和 A 之间进行取舍。但对于传统的项目就可能有所不同,拿银行的转账系统来说,涉及到金钱的对于数据一致性不能做出一丝的让步,C 必须保证,出现网络故障的话,宁可停止服务,可以在 A 和 P 之间做取舍。
下一篇:SpringCloud-13-负载均衡介绍
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/123815.html

