
目录
一、集合的源头
1、集合背景
在没有集合类之前,实际上在Java语言里已经有一种方法可以存储对象,那就是数组。数组不仅可以存放基本数据类型也可以容纳属于同一种类型的对象。数组的操作是高效率的,但也有缺点。比如数组的长度是不可以变的,数组只能存放同一种类型的对象(或者说对象的引用)。
另外,在程序设计过程中,程序员肯定会经常构建一些特殊的数据结构以正确的描述或者表达现实情况。比如描述火车进站出站,他们会用到“栈”这个数据结构,常用的数据结构还有:队列、链接表、树和散列表等等。这些数据结构几乎在每一段程序设计过程中都会使用到,但是如果每次编程都要重新构建这些数据结构显然违背了软件组件化的思想。因此Java的设计者考虑把这些通用的数据结构做成API供程序员调用。
基于以上几点必须解决的问题。Java提供了对象的数种保存方式,除了内置的数组以外,其余的称为集合类。为了使程序方便地存储和操纵数目不固定的一组数据,JDK中提供了Java集合类,所有Java集合类都位于Java.util包中,与Java数组不同,Java集合不能存放基本数据类型数据,而只能存放对象的引用。(来源于百度)…………………………………….
2、集合的好处
▶ 降低编程难度:在编程中会经常需要链表、向量等集合类,如果自己动手写代码实现这些类,需要花费较多的时间和精力。调用Java中提供的这些接口和类,可以很容易的处理数据。
▶ 提升程序的运行速度和质量:Java提供的集合类具有较高的质量,运行时速度也较快。使用这些集合类提供的数据结构,程序员可以从“重复造轮子”中解脱出来,将精力专注于提升程序的质量和性能。
▶ 无需再学习新的APl:借助泛型,只要了解了这些类的使用方法,就可以将它们应用到很多数据类型中。如果知道了LinkedList的使用方法,也会知道LinkedList怎么用,则无需为每一种数据类型学习不同的API。
▶ 增加代码重用性:也是借助泛型,就算对集合类中的元素类型进行了修改,集合类相关的代码也几乎不用修改。
…………………………………….
3、集合的特点
① 集合类这种框架是高性能的。对基本类集(动态数组,链接表,树和散列表)的实现是高效率的。一般人很少去改动这些已经很成熟并且高效的APl;
② 集合类允许不同类型的集合以相同的方式和高度互操作方式工作;
③ 集合类容易扩展和修改,程序员可以很容易地稍加改造就能满足自己的数据结构需求。
④ 可以动态保存任意多个对象,使用方便。
…………………………………….
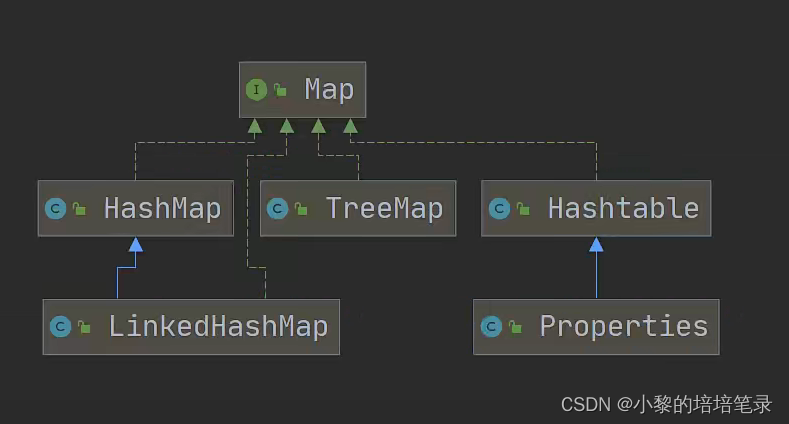
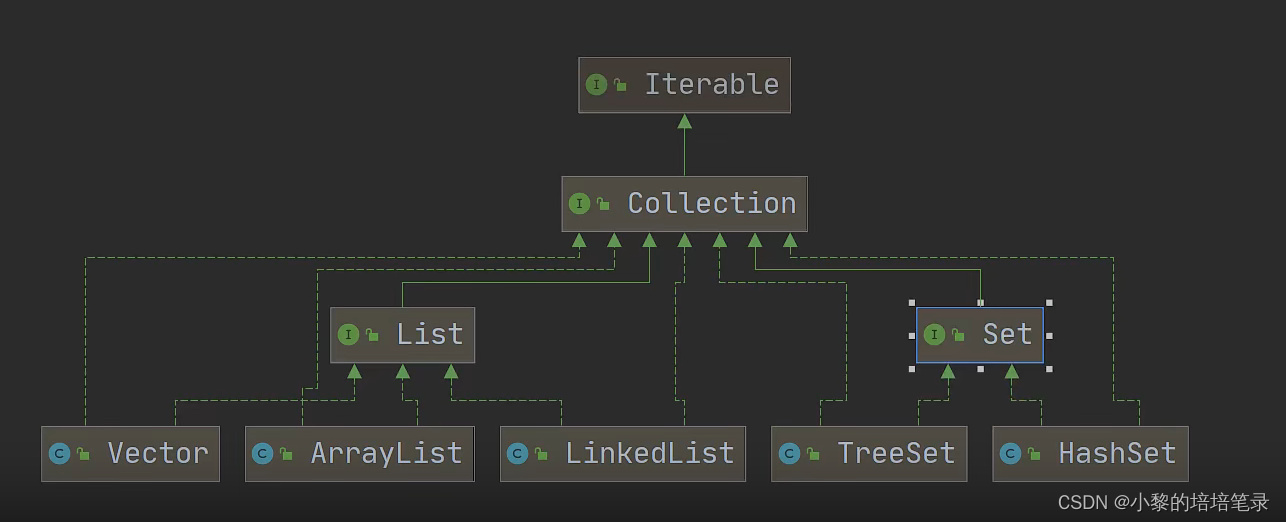
4、集合框架体系 [必背]

二、Collection 接口、方法
1、Collection 接口
▶ 重要的子接口 List,Set , 它们的实现子类都是单列集合
List arrayList = new ArrayList(); arrayList.add("单列集合");▶ 而Map 接口的实现子类是
双列集合Map hashMap = new HashMap(); hashMap.put("双列", "双列集合");▶ Collection实子类可以存放多个元素,每个元素可以是Object▶ 有些Collection的实现类,可以存放重复的元素,有些不可以
▶ 有些Collection的实现类,有些是有序的(List),有些是无序的(Set)
▶ Collection接口没有直接的实现子类,是通过它的子接口Set和List来实现的…………………………………..2、子类ArrayList 的常用方法
▷ add : 添加单个元素
List list = new ArrayList(); list.add("jack"); list.add(10); list.add(new Integer(10)) list.add(true);▷ remove : 删除指定元素
List list = new ArrayList(); list.remove(0);//删除第一个元素 list.remove("jack");//指定删除某个元素▷ size : 获取元素个数
List list = new ArrayList(); System.out.println(list.size());▷ isEmpty : 判断是否为空List list = new ArrayList(); System.out.println(list.isEmpty());▷ clear : 清空所有数据List list = new ArrayList(); list.clear();▷ addAll : 添加多个元素List list = new ArrayList(); ArrayList list2 = new ArrayList(); list2.add("红楼梦"); list2.add("三国演义"); list.addAll(list2);▷ containsAll : 查找多个元素是否都存在System.out.println(list.containsAll(list2));//查找子集合▷
removeAll :删除多个元素list.removeAll(list2);//删除子集合…………………………………..
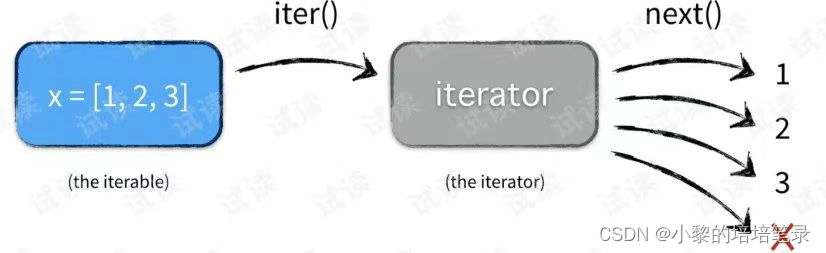
3、遍历方式–Iterator(迭代器)
▷ lterator对象称为迭代器,主要用于遍历Collection集合中的元素
▷ 所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了iterator接口的对象,即可以返回一个迭代器。
▷ lterator仅用于遍历集合, Iterator 本身并不存放对象。
▷ 迭代器原理图:
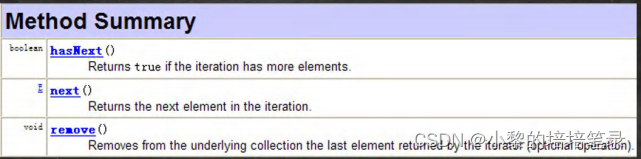
▷ 在调用iterator.next()方法之前必须要调用iterator.hasNext()进行检测。 若不调用,且下一条记录无效,直接调用iterator.next()会抛出NoSuchElementException异常。
▷iterator 接口方法:
▷ 代码示例:
List list = new ArrayList(); list.add("simth"); list.add("tom"); list.add("jakc"); //使用迭代器 Iterator iterator = list.iterator(); //创建list的迭代器 while(iterator.hasNext()){ //判断下一个元素是否为空 Object next = iterator.next();//将元素赋值给next System.out.println(next); //输出元素 }▷ 增强for循环代码示例:
List list = new ArrayList(); list.add("simth"); list.add("tom"); list.add("jakc"); //使用增强for循环 for(Object s : list){//将list集合的单个元素循环赋值给s System.out.println(s);//循环输出单个元素s }
三、List 集合
1、基本介绍
▶ List集合类中元素有序(即添加顺序和取出顺序一致、且可重复
▶ List集合中的每个元素都有其对应的顺序索引 即支持对索引进行增删改查的操作。
▶ List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
▶ 常用的实现类: ArrayList、LinkedList、Vector
List list = new ArrayList();List list = new Vector();List list = new LinkedList();…………………………………..
2、List 接口的常用方法
方法 功能 void add(int index, Object ele)
index 索引
位置插入
ele
元素boolean addAll(int index, Collection eles)
index
位置开始将
eles
中的所有元素添加进来Object get(int index)
index
位置的元素int indexOf(Object obj)
obj
在集合中首次出现的位置int lastIndexOf(Object obj)
obj
在当前集合中末次出现的位置Object remove(int index)
index
位置的元素,并返回此元素Object set(int index, Object ele)
index 位置的元素替换成
ele 元素List subList(int fromIndex, int toIndex)
fromIndex
到
toIndex
位置的子集合…………………………………..
3、List 的三种遍历方式
▷ 使用 iterator-迭代器
▷ 使用增强for循环
▷使用普通for循环
四、底层结构
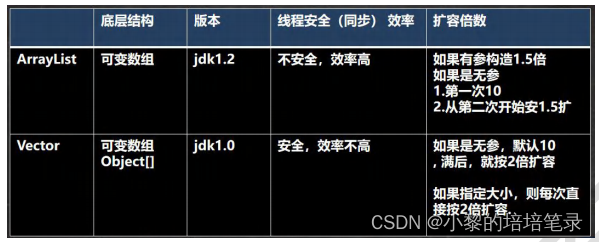
1、ArrayList 分析
(1) 注意事项
- ArrayList 可以加入多个重复null(permits all elements, including null)
- ArrayList 是由数组来实现数据存储的
- ArrayList 基本等同于Vector,除了ArrayList是线程不安全(执行效率高)。在多线程情况下,不建议使用ArrayList。
(2) 底层机制
- ArrayList中维护了一个Object类型的数组elementData. (transient Object[] elementData; 其中transient 表示瞬间,短暂的,表示该属性不会被序列号)
- 当创建ArrayList对象时, 如果使用的是无参构造器, 则初始elementData容量为0, 第一次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍。
- 如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍。
…………………………………..
2、Vector 分析
(1) 注意事项
- Vector底层也是一个对象数组,(protected Objectll elementData;)
- Vector 是线程同步的,即线程安全,Vector类的操作方法带有synchronized关键字
- 在开发中,需要线程同步安全时,考虑使用Vector
(2) Vector 和 ArrayList 比较
…………………………………..
3、LinkedList 分析
(1) 注意事项
- LinkedList底层实现了双向链表和双端队列特点
- 可以添加任意元素(元素可以重复),包括null
- 线程不安全,没有实现同步
(2) 底层机制
- LinkedList底层维护了-个双向链表
- LinkedList中维护了两个属性first和last分别指向首节点和尾节点
- 每个节点(Node对象) ,里面又维护了prev, next、item三个属性,其中通过prev指向前一个,通过next指向后一个节点。最终实现双向链表
- 所以LinkedList的元素的添加和删除,不是通过数组完成的,相对来说效率较高
(3) 常用方法
LinkedList linkedList = new LinkedList(); linkedList.add(1); linkedList.add(2); linkedList.add(3);▷ remove() 删除结点
linkedList.remove(); // 默认删除的是第一个结点 linkedList.remove(2); //指定删除某个结点▷ set() 修改某个结点对象linkedList.set(1, 9);▷ get() 得到某个结点对象Object o = linkedList.get(1);//索引从0开始(4) ArrayList 和 LinkedList 的比较
(5) 如何选择ArrayList和LinkedList
▷ 如果我们改查的操作多,选择ArrayList
▷ 如果我们增删的操作多, 选择LinkedList
▷ 一般来说, 在程序中, 80%-90%都是查询,因此大部分情况下会选择ArrayList
▷ 在一个项目中, 根据业务灵活选择,也可能这样, 一个模块使用的是ArrayList,另外一个模块是LinkedList,也就是说,要根据实际需求来决定如何选择。…………………………………..

五、Set 接口
1、基本介绍
(1) 注意
▷ 无序(添加和取出的顺序不一致) ,但它是固定的,并且没有索引
▷ 不允许重复元素,所以最多包含一一个null
▷ 常用方法和 List 接口一样, Set 接口也是 Collection 的子接口,因此,常用方法和 Collection 接口一样
(2) 遍历方式
▷ 使用迭代器
▷ 使用增强for循环
▷ 不能使用索引的方式,即普通for循环
…………………………………..
2、HashSet 分析
(1) 注意
- HashSet 实现了Set接口
- HashSet 的底层实际上是HashMap
- 可以存放null 值,但是只能有一个null
- HashSet不保证元素是有序的,取决于运算hash值后, 再确定索引的结果, (即不保证存放元素的顺序和取出顺序一致)
- 不能有重复元素或对象
(2) 底层分析
- HashSet 底层是 HashMap
- 添加一个元素时,会先得到hash值,然后会转成索引值
- 找到存储数据表table,看这个索引位置是否已经存放的有元素
- 如果没有, 直接加入
- 如果有,调用equals 比较,如果相同, 就放弃添加,如果不相同,则
添加到(链表的)最后- 在Java8中,如果一条链表的元素个数到达 TREEIFY THRESHOLD(默认是8). 并且table的大小>=MIN TREEIFY CAPACITY(默认64).就会进行树化(红黑树)
(3) 扩容机制
- HashSet底层是HashMap,第一次添加时 table 数组扩容到16, 临界值(threshold)是 16*加载因子(loadFactor)是0.75=12
- 如果table 数组使用到了临界值 12,就会扩容到16*2=32,新的临界值就是32+0.75=24,依次类推
- 在Java8中,如果一条链表的元素个数到达 TREEIFY THRESHOLD(默认是8),并且table的大小>=MIN TREEIFY CAPACITY(默认64).就会进行树化(红黑树),否则仍然采用数组扩容机制
…………………………………..
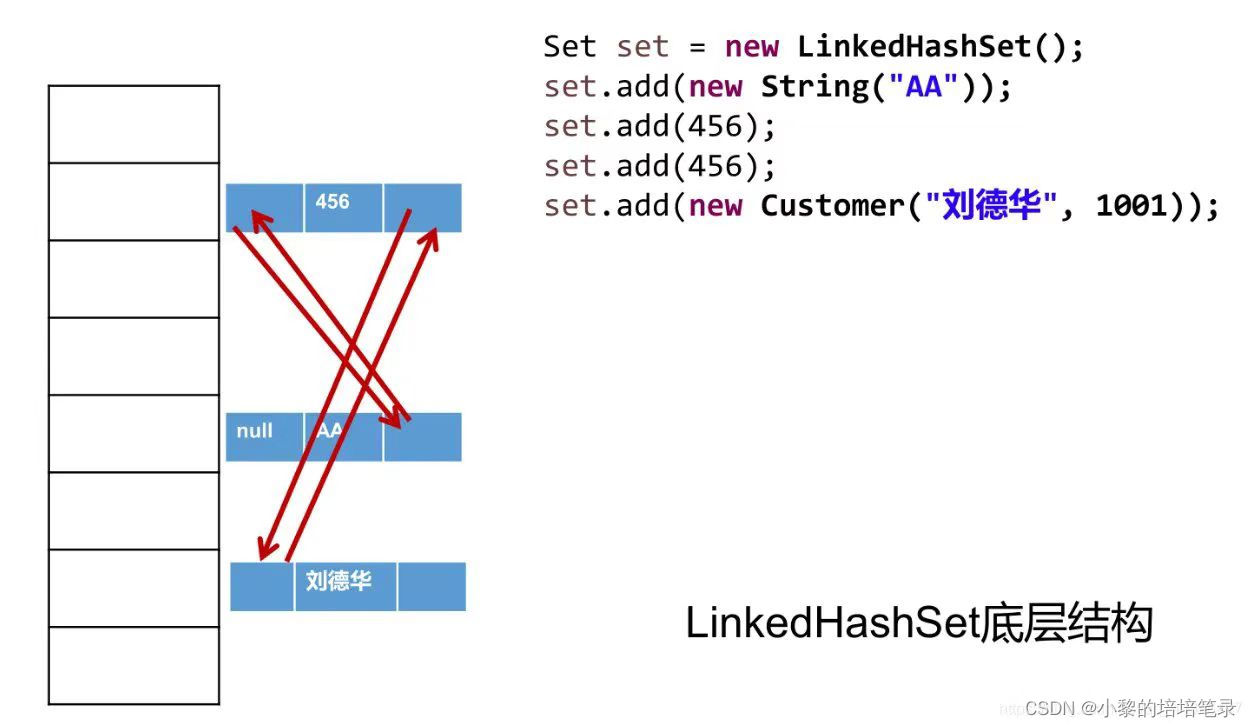
3、LinkedHashSet 分析
(1) 注意事项
- LinkedHashSet 是 HashSet 的子类
- LinkedHashSet 底层是一个LinkedHashMap,底层维护了一个数组+双向链表
- LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序(图),这使得元素看起来是以插入顺序保存的。
- LinkedHashSet 不允许添重复元素
(2) 底层
- 在LinkedHashSet中维护了一个hash表和双向链表
- 每一个节点有 before和 after属性,这样可以形成双向链表
- 在添加一个元素时,先求hash值,再求索引,确定该元素在table数组的位置,然后将添加的元素加入到双向链表(如果已经存在则不添加,(原理和hashset一样)
- 有双向链表的顺序就可以确保加入顺序和取出顺序一致。
(3) 图解
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/119686.html

