
文章目录
前言
本文记录的是spark-3.1.2的安装详细步骤,建议收藏起来悄悄卷~~
一、事先准备
- 集群机器相互同步时间
- 机器之间实现免密登录
- 所有机器都关闭防火墙
- 所有机器都需要安装JDK1.8
- Hadoop环境最好是在3.2
二、上传安装包到linux上
安装包名:spark-3.1.2-bin-hadoop3.2.tgz
我是上传到了softwares目录下
三、解压安装包
先cd进softwares目录下,然后将安装包解压至/usr/local/路径下
[root@cq01 softwares]# tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C /usr/local/
进入/usr/local下,对spark-3.1.2-bin-hadoop3.2.tgz进行重命名为spark
[root@cq01 softwares]# cd /usr/local/
[root@cq01 local]# mv spark-3.1.2-bin-hadoop3.2/ spark
四、配置文件
从安装路径进入到conf下,进行配置
[root@cq01 local]# cd /usr/local/spark/conf/
1.spark-env.sh.template
重命名为spark-env.sh
[root@cq01 conf]# mv spark-env.sh.template spark-env.sh
编辑spark-env.sh文件
[root@cq01 conf]# vi spark-env.sh
在文档末尾添加上jdk的安装路径

2.workers.template
重命名为workers
[root@cq01 conf]# mv workers.template workers
根据自己的节点来添加从节点(注意不要写Master节点进去)
[root@cq01 conf]# vi workers

五、分发给其他结点
先退回到local路径下
[root@cq01 conf]# cd /usr/local/
将配置好的内容分发给其他节点(根据自己集群机器的数量来分发)
[root@cq01 local]# scp -r ./spark/ cq02:$PWD
[root@cq01 local]# scp -r ./spark/ cq03:$PWD
六、配置全局环境变量
配置好全局环境变量可以在任意位置使用bin下的脚本。注意顺便把其他几台的环境变量也配一下。
[root@cq01 local]# vi /etc/profile
#spark environment
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin

重新启动环境变量
[root@cq01 local]# source /etc/profile
七、启动集群
进入安装目录下的sbin目录
[root@cq01 spark]# cd /usr/local/spark/sbin/
启动
[root@cq01 sbin]# ./start-all.sh
出现以下提示则表示启动完成

八、查看进程
使用jps命令查看进程。我这里是写了一个查看集群所有机器的进程。
[root@cq01 sbin]# jps-cluster.sh
出现以下的进程表示已经启动成功

九、网页访问
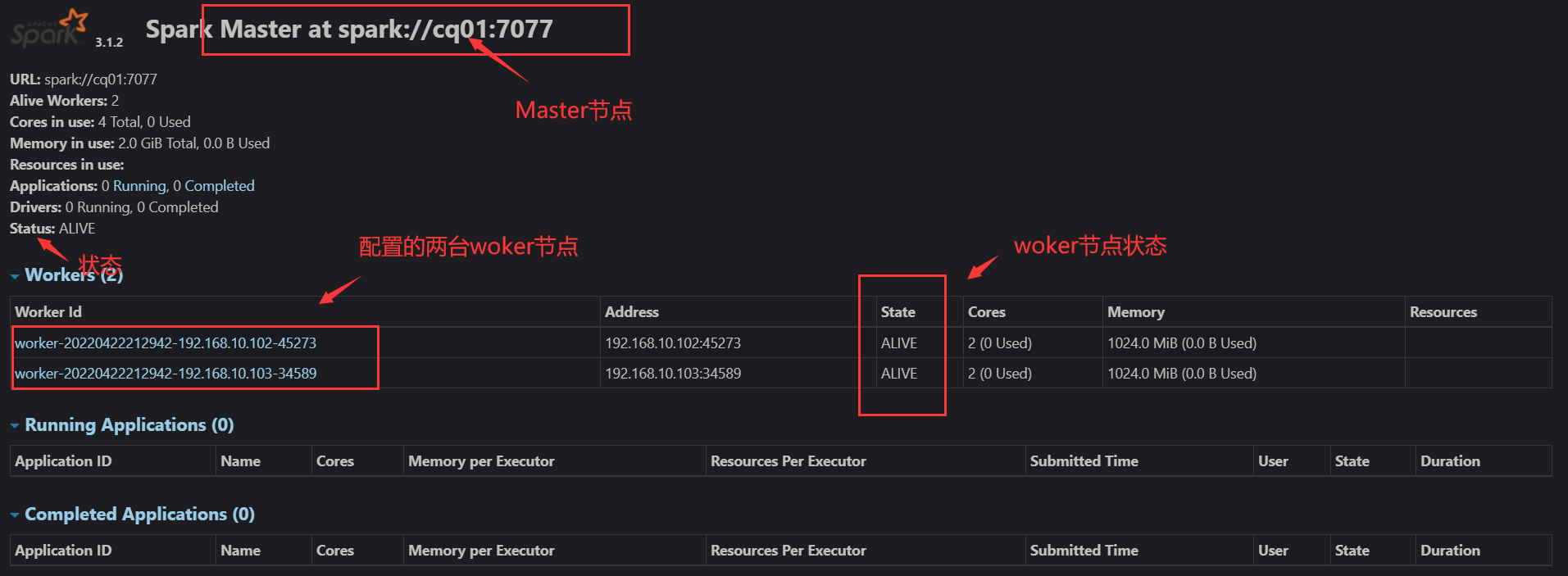
spark3.1.2提供的webUI界面端和tomcat的端口一样8080,所以我们可以通过输入网址http://虚拟机Master的IP地址:8080来访问,然后就会出现下图界面
十、验证
进入到spark的bin目录下,执行以下命令
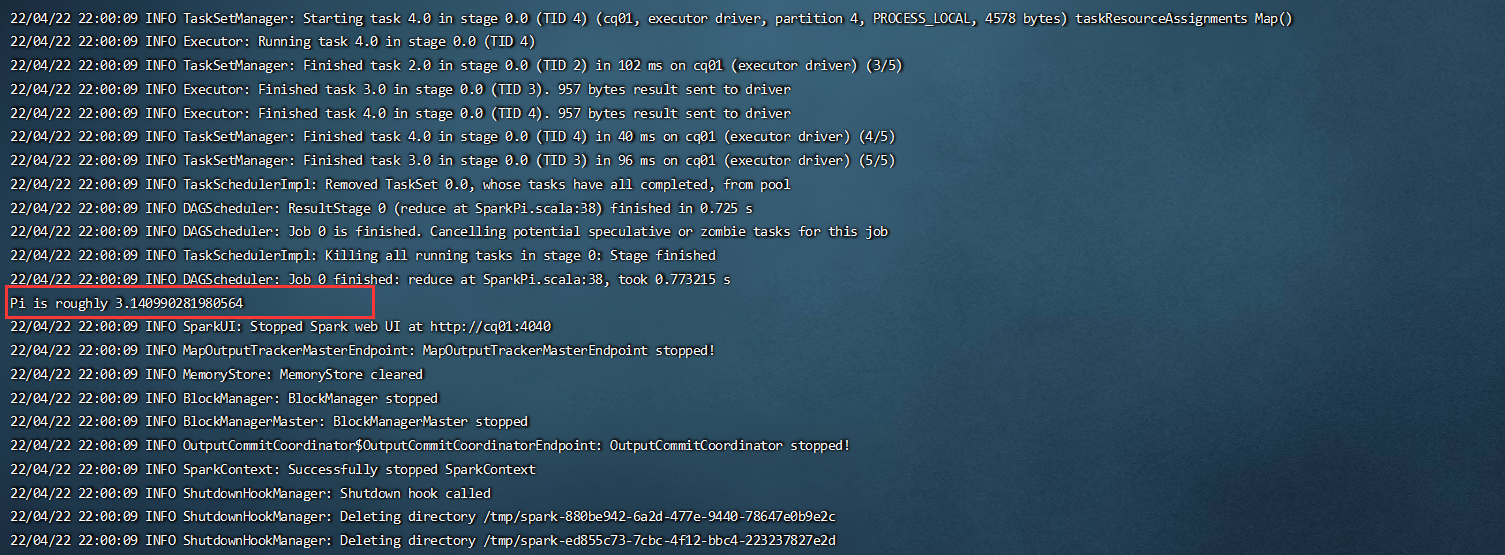
[root@cq01 bin]# ./run-example SparkPi 5 --master local[1]
出现以下界面,则表示以及成功运行
总结
至此就已经完成了spark-3.1.2的安装。如果有什么问题,欢迎一起交流。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/116580.html

