
1、前言
在Redis常见的5大数据类型中,List和Set作为集合容器经常会被使用,但这二者的弊端也是非常明显。List中的数据是有序但不去重,Set中的数据是去重但无序,当我们既需要集合中的数据有序,又需要集合中的数据去重的话,那该怎么办呢?这时候就需要Sorted Set登场了。
2、初识Sorted Set
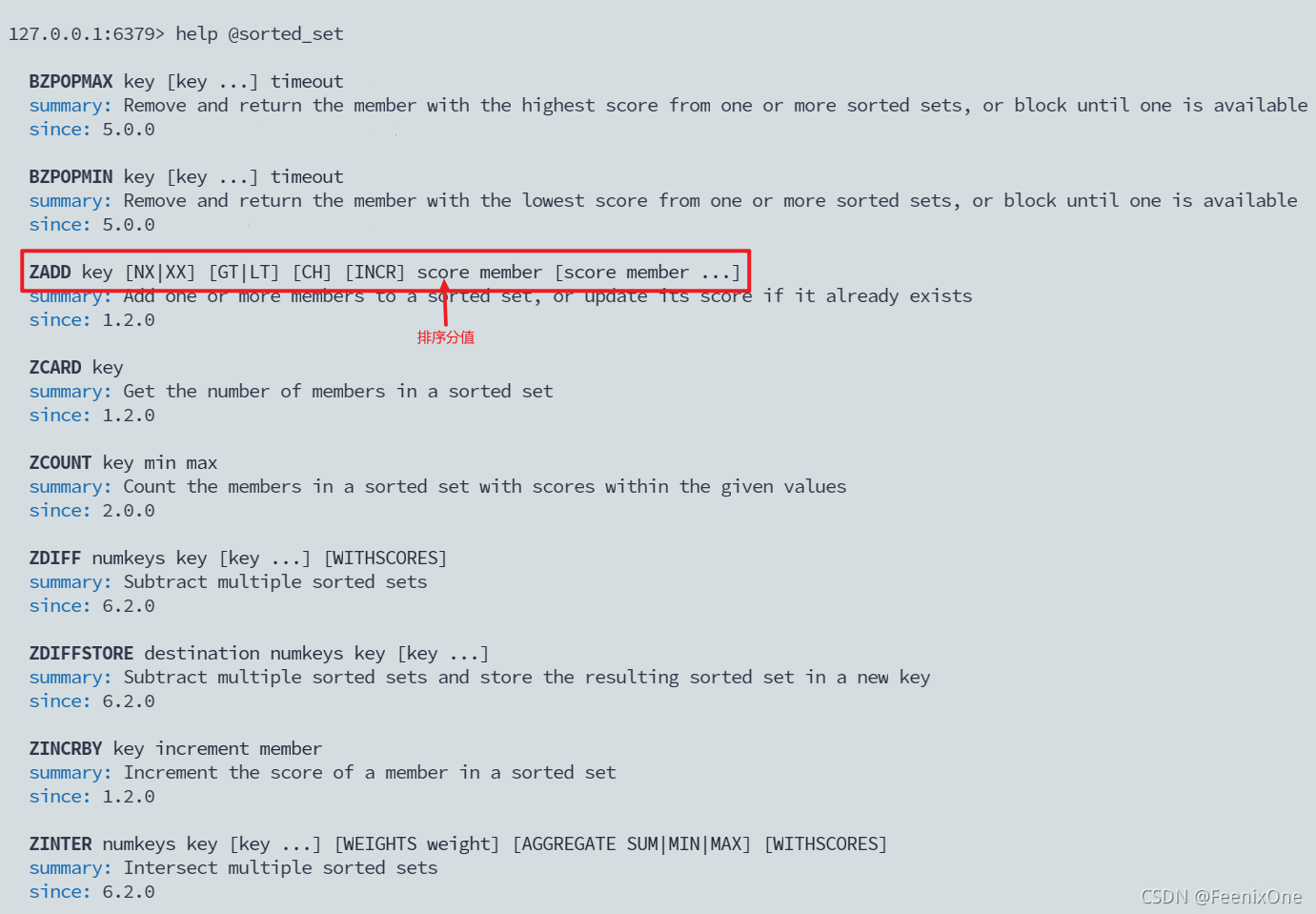
通过Redis中的help @Sorted_Set查看Sorted Set相关命令,及操作方法。
3、Sorted Set的一些简单命令使用
Sorted Set在设值的时候,不同于Set,得给出一个score分值,作为排序的基准。如果不想按照分值来排序的话,分值全部设为1即可。
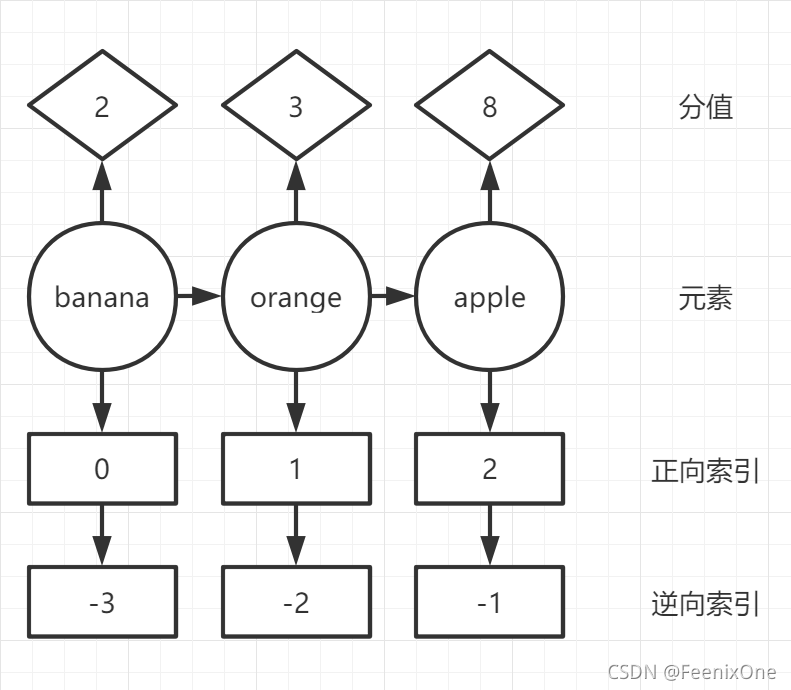
例如:zadd k1 8 apple 2 banana 3 orange
这就是设置了一个Sorted Set数据集,在Sorted Set集合中,以一个有序的链表方式存储,默认的是以左小右大的方式在物理内存中摆放,拉链似的在内存中排好。
这时,使用zrange k1 0 -1就可以查看Sorted Set中全部的元素(0 -1是面向字节的正负索引)。

也可以使用zrange k1 0 -1 withscores在查询的时候一并显示元素的相关分值。

如果你想按照分值取出,这么写:zrangebyscore k1 3 8

如果想按照分值由低到高取出前两位的水果,这么写:zrange k1 0 1
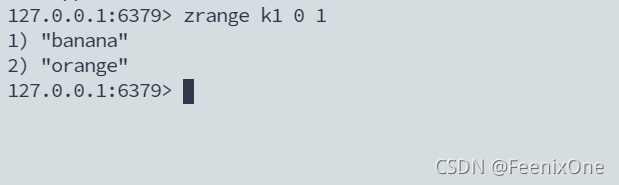
如果是由高到低,命令则是:zrevrange k1 0 1,而不是zrange k1 -2 -1,这两个命令取出来的结果完全不一样!

这便是上文所提到的物理内存左小右大,且这个顺序不随命令发生变化,无论是正向命令zrange还是反向命令zrevrange。
还可以根据元素取出对应的分值:zscore k1 apple

也可以根据元素取出对应的默认排序下的排名:zrank k1 apple(返回的排名从0开始)

也可以直接对元素的分值进行数值计算:

再次查看集合中的元素,顺序发生了变化。Sorted Set会实时根据计算后的数值,改变元素的顺序。这种机制使得Sorted Set有了极大的使用场景,比如各大APP的排行榜数据,通过热度啊、点击啊、下载啊、评论啊之类的排序,一个Sorted Set就搞定,根本不需要用到关系型数据库。数据库在这种场景下的并发处理起来很麻烦,但Redis是单进程的,所有用户的操作都给我排着队一个一个来,而且Sorted Set还实时排序,一个命令就可以全部查询。
4、Sorted Set的一些集合操作命令使用
准备两个演示集合数据

并集操作:zunionstore unKey 2 k1 k2

zunionstore是将集合中的元素并集处理后的结果存放到目标Key中,unKey是并集处理后的结果存放的目标Key,2是需要并集处理几个集合,k1 k2是需要处理的集合。
默认是没有加权重,如果需要加权重,那就是:zunionstore unweKey 2 k1 k2 weights 1 0.5

加权计算其实就是集合中元素的分值*集合对应的权重,然后再进行并集计算得出结果。
如果不想集合中的元素分值进行相加,而是想对集合中的相同元素进行比较取出最大的那个,可以使用:zunionstore unmaxKey 2 k1 k2 aggregate max
不仅仅是取最大,使用aggregate聚合指令还可以取最小,求和等操作。
5、Sorted Set排序原理
使用Sorted Set排序多了以后,就会发现Sorted Set对元素的实时排序非常快,那么为什么Sorted Set的排序可以做到如此的快速高效?这就不得不提Sorted Se的底层存储结构的数据结构:skip list(跳跃表)。
说跳跃表之前,先看一下普通的链表对于元素的处理,链表是怎么对其中的元素进行排序?循环遍历去比较呗,这也是最容易实现的。随着链表中元素的不断增加,假设表中有1万个元素,第1万〇1个元素进表的时候,最坏的情况就是要比较1万次。
如何提高效率呢?二分法可不可以?如果使用二分方法,那么谁是中间的那个元素呢?这是个链表,不是数组,如果要找中间的元素还是得1个1个遍历过去。
而跳跃表所采取的方式就是分多层,看下图
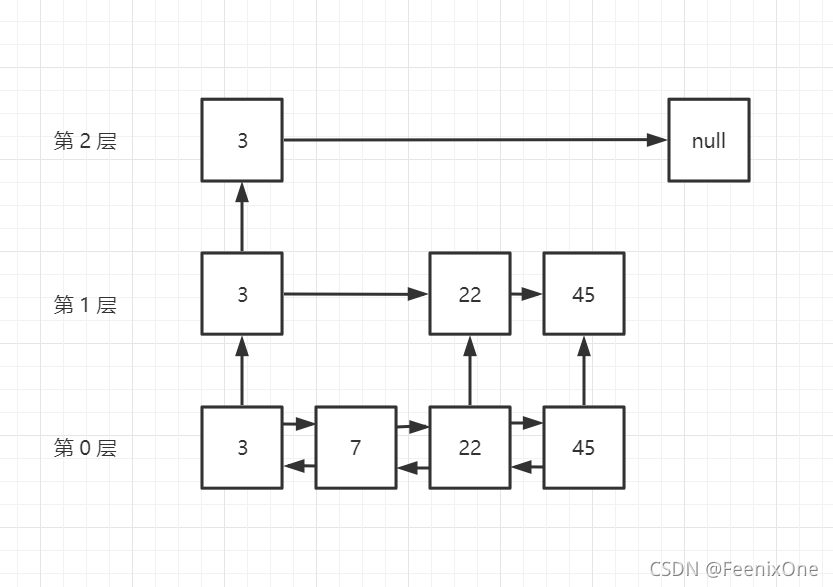
假设在一个跳跃表中已经存有4个元素,分别是3、7、22和45。第0层是最底层的物理数据层,在第0层之上,还会将表中数据随机挑选出来在随机层建立引用。
①现在有一个元素11要插入,当11进来开始比较的时候,是和第1个元素(3)的最高一层(第 2 层)中去比较,如果11<3,直接插入即可,因为3本身就是在第1个位置,如果11>3,那么会和下一个元素去比较,下一个是null,没得比;
②就会降级降到下一层(第1层)继续和后面的元素(22)进行比较。结果11<22,那么就不用了再和22后面的元素(45)比较了;
③继续来到下一层(第0层),开始向左去比较数据,最终找到自己的位置插入;
④当这个元素插入成功以后,是不是也需要给自己再其它层制作引用呢?是的,这就是跳跃表元素的随机造层。
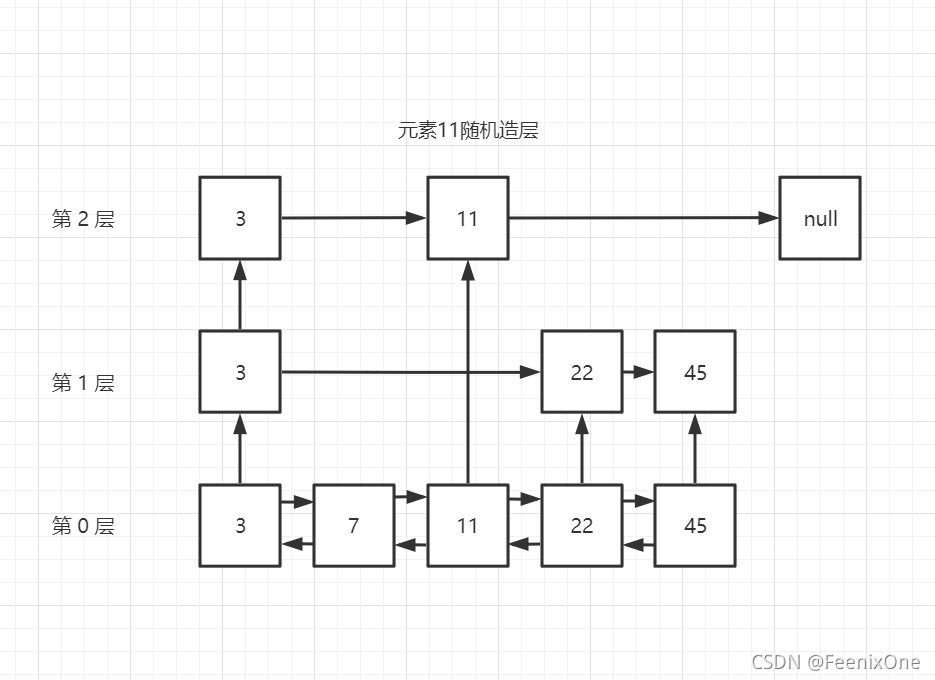
每个元素插入成功以后,都会进行一个随机造层,可能造1层,可能造2层,可能造3层,也有可能压根就不造层。当然,这个最高层数会有一个初始值,就尽量造的层数不会超过这个初始值。一个跳跃表中不可能每个元素都造3层,那就等于这个元素存了3倍,所以一定是间接的跳着随机造层,其实就是吸收存储空间来换未来的查询速度。
其实跳跃表是类平衡树的,所谓平衡树就是左旋右旋,从而让所有的深度基本保持一致,就是插到任何位置的速度差不多一致。总的来看,当处于高并发的时候,综合所有的增删改查操作的效率来看,平均速度相对是最稳定的。这也是为什么使用跳跃表而不是使用平衡树、红黑树的原因。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/111960.html

