
之前在讨论AFK原理的时候,我们说单节点有三个问题:
① 单点故障问题;
② 容量有限问题;
③ 访问压力问题。
而在前两篇的文章中,我们通过主从复制解决了访问压力问题,可以对主机和从机进行一个读写分离的操作,这样主机和从机的访问量会下降不少,并且我们通过哨兵解决了单点故障的问题。也就是说xyz三轴当中x轴的单点故障问题基本上已经被解决,但是y轴和z轴的容量有限问题好像还没有解决,那么这个容量有限的问题到底要怎么样去解决呢?
其实光是在Redis中至少有8、9种方法,可以解决这个容量有限的问题。单台Redis的内存总是有限的,即使你服务器的配置很高,有1T的内存,那也不可能说这1T的内存全部拿来让你只放Redis。一般在企业中都会设置一个Redis实例尽量只吃几G的内存就可以了。而且即便你的可用内存非常大,但是也尽量不要让Redis占用太多的内存,因为当占用的内存过多的时候,在序列化持久化的时候也会非常的慢,那么我们要怎么样去控制这个radius,让他尽可能的变得轻量级。
1、数据通过业务逻辑拆分
每个Redis实例中存放不同的业务数据,然后在客户端通过不同的业务逻辑代码,让你访问不同的数据的时候,指定向不同的Redis实例。

2、数据通过modula算法(hash取模)拆分

取的这个模的数就是Redis总台数,假设有5台,那么就根据5来取模。
这种方式的弊端是:hash取模算法有一个天生的弊端,取模的值是固定的。同样的一个数据,你取模的模数不一样,它会去到不同的节点,这会影响到分布式下的扩展。说简单一点就是假设公司原来只有5台机器,那么你根据5来取模,那么你的数据会存在以5取模的各个片里面。后来公司发达了,有了10台机器,那么你这些数据再根据10去取模的时候,它指向的那些Redis跟你原来所存放的Redis会不一致,就会导致取不出数据的情况。
3、数据随机拆分

随机存取的问题在于根本不知道这个数据放到哪个片里面去了,换句话说就是找不出来。那为什么这种算法还会存在?因为在某些特殊的场景中,这种算法非常的实用。

在消息推列中,这种算法就显得非常的实用,当两台客户端同样连接着Redis的时候,其中一台客户端只要负责往Redis中存入数据,另外一台客户端从Redis中弹出数据就行了。不用管随机到哪台Redis,反正另外一台客户端只要你有存我就来取,在高流量并发的时候有多台Redis共同消化这些流量。Kafka用的就是这种设计理念,只不过Kafka是基于磁盘的可以重消费,Redis是基于内存的追求速度的快。
4、数据通过Ketama hash一致性算法拆分
一致性哈希算法没有取模,因为取模的话受限于模数。一致性哈希算法要求的是数据的Key和Redis的节点都需要参与映射计算:
首先,会规划出一个圆形的哈希环。然后,每一台Redis实例有一个唯一的id号。每一个Redis的id经过哈希算法会产生一个映射值,这些值分布在这个虚拟的环上。然后数据的Key也会根据算法去计算出某一个映射值,然后在这个环上找到离这个Key的映射值最近的一个Redis的映射值,将数据存进去这个对应的Redis中。
本质上就是将这个虚拟环作为一个中间第三方,然后为Redis的节点经过一个算法分布在环上,然后再让数据的Key经过这个算法分布在环上,然后两个近乎相交的点就成了匹配对应的存储点。

这种算法的优点在于节点的增加确实可以分担其余节点的压力,而且因为没有取模的过程,所以就不会造成全局洗牌。
而缺点就是新增节点会造成一小部分数据不能命中,假设原来有1、2、3三个节点,数据a离节点1最近。现在增加了第4个节点,经过哈希算法算完以后发现数据a离节点4更近,后面再查询数据a的时候会发现数据节点4里面查询不到数据。
这样造成的问题就是:如果数据a在关系型数据库中存储着,那么就会造成数据击穿,压力直接到数据库。有一个解决方案就是:数据经过计算以后,每次取两个最近的Redis节点。当然这也不能100%保证数据一定会取到,这只是一个概率问题,取两个节点的击穿概率肯定是比取一个节点的概率要低,那你取三个节点的概率肯定比取两个节点的概率低,也就是说具体取多少个节点在于一个权衡判断。
所以这种方案对于Redis的使用方面更倾向于将Redis作为缓存,而不是数据库使用。
对于这个算法还可以再补充一点,就是虚拟节点:假设一开始只有两个Redis节点的时候,通过哈希一致性算法,只会在虚拟环上占两个点。但是这两个点的分布就过于的散开,这样会导致数据很有可能经过算法算完以后疯狂的传到一个点里面。这个时候可以将两个节点的id后面分别拼接1~10个不同的数字再进去计算,那这样就相当于1个节点在环上站了10个节点的位置,而这10个节点分别都指向于这1个物理节点,这样更有利于数据存储的更加均匀,很大程度上可以解决数据存储倾斜的问题。
以上这些方案都是基于特殊算法来进行Sharding分片数据的划分存储,这些算法既可以在客户端中使用代码来实现,也可以使用不同的代理来实现,比如tweproxy、predixy等,而Redis自己本身也有集群的方式进行解决。
5、Redis集群算法
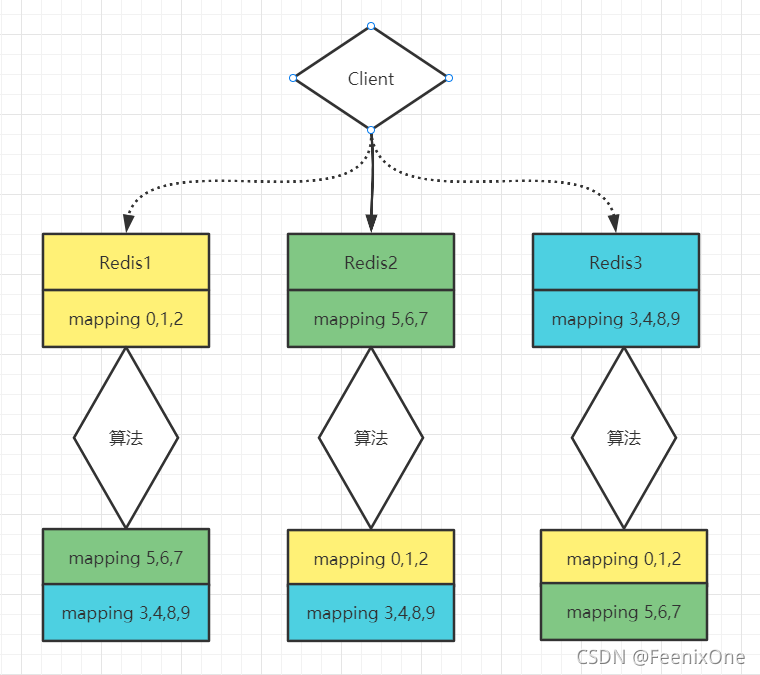
假设现在有三台Redis节点,每一个节点所存放的槽位是不一样的: Redis1可以存放槽位0、1、2;Redis2可以存放槽位5、6、7;Redis3可以存放槽位3、4、8、9。客户端可以连接哪个节点是任意的,当客户端连接到Redis2节点时,set数据a进来。数据a经过算法算算完以后,得出它的槽位是5,Redis二节点会先对比自己是否有这个槽位,如果自己有这个槽位,则直接将数据存储在自己节点上;如果自己没有这个槽位,会将数据对应槽位的节点返回给客户端,再由客户端将数据发送给对应槽位的节点进行存储。
也就是说,在这个集群中,每一个Redis的节点都会有其它所有节点的槽位映射关系以及相同的算法。那么在这个前提得到保证的情况下,每一个Redis的节点,无论是哪个实例,只要是在这个集群里面,每一个节点都可以当家作主,因为每一个节点都知道别人的槽位,都知道大家所有相同的算法。
这是一种无主的集群,起码在业务层面上没有所谓的master,大家都是master。从非严格的角度来说也可以说成是主主模型,但是主主模型一般强调的是全量,所以这个从严格角度来说还是归为无主模型。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/111950.html

