
一,什么是 Elasticsearch
(一)Elasticsearch
按照Elasticsearch官网的说法:
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
你可能还见过一些其他的说法,在“是一个”后面往往跟着一堆牛逼的词:分布式、可扩展、高性能、近实时…把需要对比才能体现的总结性词汇放到解释性语句里,反倒增加了理解成本,让人感到着急!
简单来说,Elasticsearch 就是一个数据搜索引擎,只不过随着大数据分析方向上的功能扩展,它就成了扩展后的 Elastic Stack 技术栈的一部分。
但无论怎样,只要始终记得 Elasticsearch 是做搜索引擎起家的。
(二)从 Apache Lucene 开始
说到搜索引擎,你可能想到的是 Google、Bing 等(baidu狗都不用🐶),但“搜索引擎”是一个笼统的概念。这些搜索引擎,可以理解为就是功能强大的网络爬虫,是互联网级别的。它们能够搜集并整理网络资源,然后对用户的搜索动作做出响应。
另一类搜索引擎的作用是在软件系统中提供基于字段的搜索,比如对 Apache Lucene 工具包封装而来的 Elasticsearch、Solr等。
- 作为免费、开源、高性能的、纯 Java 编写的全文检索引擎,Apache Lucene 几乎适用任何需要全文检索的场景。它还提供了 python 扩展包 PyLucene。
尽管这两类作用对象不同的搜索引擎的数据来源可能不同,但都需要考虑的是如何做好搜索关键词与目标之间的映射以及通过索引搜索数据——索引和查询。
可以简单去看看 Lucene,有利于后面理解 Elasticsearch。
1,Apache Lucene 是什么
Apache Lucene 是一个 Java 语言开发的搜索引擎库,主要提供全文检索功能。通过使用额外的扩展,还能够提供例如多语言处理、拼写检查、高亮显示等各种各样的功能。
可以下载单个的 Apache Lucene Core 库文件使用最主要的功能,也能自定义扩展它来打造定制化的搜索引擎。
2,Apache Lucene 中的核心概念
- document:索引与搜索的主要数据载体,它包含一个或多个 field。存放将要写入索引的或将从索引搜索出来的数据。
- field:document 的一个片段,它包括名称和内容两个部分。
- term:搜索时的一个单位,代表了文本中的一个词。
- token:term 在 field 文本中的一次出现,包括 term 的文本、开始和结束的偏移以及词条类型。
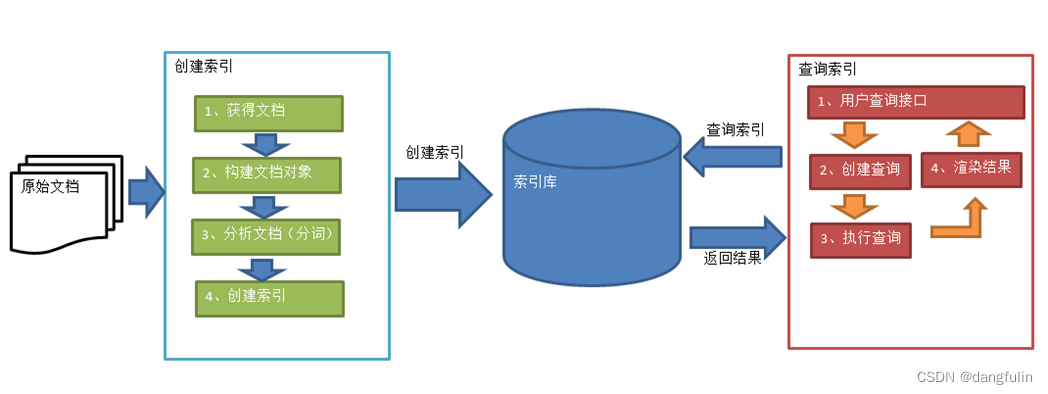

(三)Elasticsearch 中的一些基础概念
1,节点
节点(node):Elasticsearch 节点是 Elasticsearch 的单个运行实例。如果数据量增加,我们就可以在集群中使用节点来水平扩展搜索服务。主节点就用于集群中所有结点的信息。
2,集群
集群(cluster ):Elasticsearch 集群由一个或多个协同工作的节点组成。集群具有容错能力,能容纳巨大数据。
3,文档
文档(document):Elasticsearch 文档是以 JSON 格式存储的单个记录,其中键是字段的名称,值是该字段的值。文档类似于 TRDBMS 数据表中存储的一行数据。
例如,一条表示某项活动的文档:
{
"name": "Elasticsearch Denver",
"organizer": "Lee",
"location": {
"name": "Denver, Colorado, USA",
"geolocation": "39.7392, -104.9847"
},
"members": ["Lee", "Mike"]
}
Elasticsearch 是面向文档的,这意味着索引和搜索数据的最小单位是文档,类似于“”行记录。
- 自包含:文档同时包含字段及其取值。
- 层次型:字段值除了可以是字符串、整数外,还可以包含其他字段和取值。
- 无模式:并非所有的文档都需要拥有相同的字段。
4,索引
索引(index):Elasticsearch 索引是一个用于存储相同结构文档的逻辑命名空间。例如,如果我们想要存储商品详细信息,我们应该创建一个带有产品名称的索引,并将文档存储到其中,搜索商品信息时,就在这里搜索文档。
除了文档之外,索引还包含一些必要配置项,比如刷新间隔时间 refresh_interval 、分片配置等。
使用 postman 发送包含下列内容的 PUT 请求来创建一条文档:

得到:
{
"_index": "get-together", # 索引
"_type": "group", # 类型
"_id": "1", # 索引 ID
"_version": 1, # 版本
"result": "created", # 操作结果
"_shards": { # 分片信息
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
5,分片
分片(shard):分片是一个独立且功能齐全的 Lucene 索引。单个 Elasticsearch 索引可以拆分为多个 Lucene 索引,即数据可以拆分为多个分片,并且可以均匀地分布到 Elasticsearch 集群上的多个节点。分片可以有两种类型:主分片(primary shards)和副分片(replica shards)。主分片包含主数据,而副分片包含主分片的副本,用副本分片来做备份,并提高集群的搜索性能。
二,为什么可以用Elasticsearch 进行搜索
在网站中提供搜索功能是非常有用的。但实现搜索功能会遇到挑战:
- 结果要准确。
- 返回结果的速度要快。
如果仅仅是使用 TRDBMS 中的查询语句来完成数据查询,将面临巨大的性能瓶颈,而这正号可以使用 Elasticsearch 之类的搜搜引擎来解决:
在 TRDBMS 或 NoSQL DBMS 的数据上建立索引以加快查询速度。
使用 Elasticsearch 有一些优势:
- Elasticsearch 充分封装了 Lucene,并提供了额外的扩展,使存储、索引、搜索都变得更快、更容易。
- 各项特性都可以通过配置来进行指定,足够灵活、有弹性。
- 可用 RESTful HTTP请求来实现索引化、搜索并管理 Elasticsearch 集群。
而且通过 Elasticsearch 可以实现简单搜索的扩展:
- 指定搜索结果相关性。
- 自动的输入建议。
- 搜索结果分类。
- 搜索结果的数据聚合。
- …
正是由于拥有这些特点,Elasticsearch 将能够适用于以下场景或领域:
- 数据搜索业务:电子商务网站、旅游网站、社交网站、生物信息学网站、新闻和博客门户等,它们都需要显示快速的搜索结果。
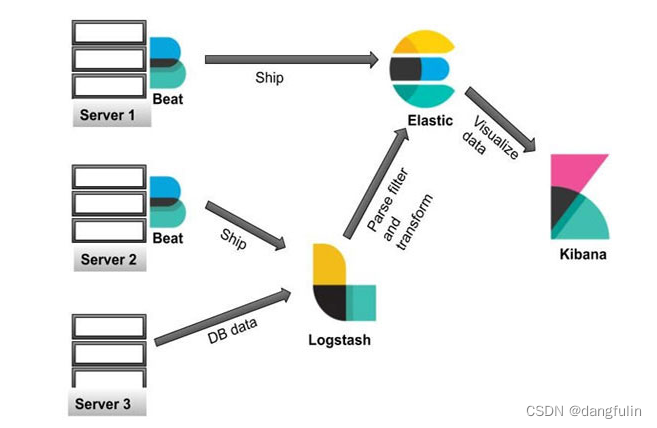
- 数据记录和分析是我们广泛使用 Elasticsearch 以及 Elastic Stack 的其他工具(如Beats,Logstash和Kibana)的另一个重要领域。在这里,Beats 和 Logstash 作为数据摄取工具工作,使用它我们从不同的来源获取数据(如日志数据、应用数据、网络数据和不同的系统指标数据),并将数据推送到 Elasticsearch 中。一旦数据被推送到 Elasticsearch 中,我们就使用 Kibana 来分析它。许多公司正在使用 Elastic Stack 进行集中式数据分析。
- 应用性能监控:配合 Elastic Stack APM 等工具,监控应用程序的性能和可用性,以轻松确定系统中是否存在问题。
- 数据可视化:Kibana、Grafana 或 Graylog 可以配置为可视化 Elasticsearch 数据。
- …
三,怎样使用 Elasticsearch
既然 Elasticsearch 能将文档作为存储对象,并以此构建索引和搜索功能,那么是否可以将
- Elasticsearch 作为主要数据源
- Elasticsearch 作为搜索的辅助数据源
- Elasticsearch 作为一个独立的子系统
(一)作为主要数据源
如果轻微的数据丢失对应用程序来说不是问题,那么可以使用 Elasticsearch 作为主要数据源。
对于需要较少数据更新的搜索密集型应用程序,我们可以使用Elasticsearch,而无需任何其他数据存储工具。

(二)作为搜索的辅助数据源
这是 Elasticsearch 最常见和最理想的用途:主数据库提供数据存储,而 Elasticsearch 用于数据搜索。
这样做的关键点是必须同步主数据库与索引。

(三)作为一个独立的子系统
使用 Elasticsearch 作为子系统的数据库,比如用 Elasticsearch 以及 Elastic Stack 的其他工具构建用于日志分析、数据分析仪表板、监控和安全分析等子系统。
四,简单操作
Elasticsearch 非常灵活,这里仅做简单的演示。
(一)准备 Elasticsearch
1,安装 Elasticsearch
安装 Elasticsearch 之前,需要先安装并配置好 Java。
然后进入 Download Elasticsearch 下载合适的版本。
更多安装方式请参考:Installing Elasticsearch
2,启动 Elasticsearch 服务。
以 Windows 为例,先切换到 安装目录:
C:\Users\PC>cd D:\tools_software\Elasticsearch\elasticsearch-7.3.1
C:\Users\PC>D:
D:\tools_software\Elasticsearch\elasticsearch-7.3.1>
然后执行:
D:\tools_software\Elasticsearch\elasticsearch-7.3.1>bin\elasticsearch.bat
Java HotSpot(TM) 64-Bit Server VM warning: Ignoring option UseConcMarkSweepGC; support was removed in 14.0
Java HotSpot(TM) 64-Bit Server VM warning: Ignoring option CMSInitiatingOccupancyFraction; support was removed in 14.0
Java HotSpot(TM) 64-Bit Server VM warning: Ignoring option UseCMSInitiatingOccupancyOnly; support was removed in 14.0
[2022-05-11T20:53:46,875][INFO ][o.e.e.NodeEnvironment ] [DANGFULIN] using [1] data paths, mounts [[(D:)]], net usable_space [158.8gb], net total_space [299.9gb], types [NTFS]
[2022-05-11T20:53:46,878][INFO ][o.e.e.NodeEnvironment ] [DANGFULIN] heap size [1gb], compressed ordinary object pointers [true]
[2022-05-11T20:53:46,888][INFO ][o.e.n.Node ] [DANGFULIN] node name [DANGFULIN], node ID [8AXMVaArTkSvEcgPeO8_iQ], cluster name [elasticsearch]
[2022-05-11T20:53:46,889][INFO ][o.e.n.Node ] [DANGFULIN] version[7.3.1], pid[19156], build[default/zip/4749ba6/2019-08-19T20:19:25.651794Z], OS[Windows 10/10.0/amd64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/14.0.1/14.0.1+7]
[2022-05-11T20:53:46,889][INFO ][o.e.n.Node ] [DANGFULIN] JVM home [D:\tools_software\jdk-14.0.1]
[2022-05-11T20:53:46,889][INFO ][o.e.n.Node ] [DANGFULIN] JVM arguments [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -Des.networkaddress.cache.ttl=60, -Des.networkaddress.cache.negative.ttl=10, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.io.tmpdir=C:\Users\PC\AppData\Local\Temp\elasticsearch, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m, -Djava.locale.providers=COMPAT, -Dio.netty.allocator.type=unpooled, -XX:MaxDirectMemorySize=536870912, -Delasticsearch, -Des.path.home=D:\tools_software\Elasticsearch\elasticsearch-7.3.1, -Des.path.conf=D:\tools_software\Elasticsearch\elasticsearch-7.3.1\config, -Des.distribution.flavor=default, -Des.distribution.type=zip, -Des.bundled_jdk=true]
[2022-05-11T20:53:48,202][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [aggs-matrix-stats]
[2022-05-11T20:53:48,203][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [analysis-common]
[2022-05-11T20:53:48,203][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [data-frame]
[2022-05-11T20:53:48,203][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [flattened]
[2022-05-11T20:53:48,204][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [ingest-common]
[2022-05-11T20:53:48,204][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [ingest-geoip]
[2022-05-11T20:53:48,204][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [ingest-user-agent]
[2022-05-11T20:53:48,204][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [lang-expression]
[2022-05-11T20:53:48,204][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [lang-mustache]
[2022-05-11T20:53:48,205][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [lang-painless]
[2022-05-11T20:53:48,205][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [mapper-extras]
[2022-05-11T20:53:48,205][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [parent-join]
[2022-05-11T20:53:48,205][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [percolator]
[2022-05-11T20:53:48,206][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [rank-eval]
[2022-05-11T20:53:48,206][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [reindex]
[2022-05-11T20:53:48,206][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [repository-url]
[2022-05-11T20:53:48,207][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [transport-netty4]
[2022-05-11T20:53:48,208][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [vectors]
[2022-05-11T20:53:48,209][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-ccr]
[2022-05-11T20:53:48,211][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-core]
[2022-05-11T20:53:48,212][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-deprecation]
[2022-05-11T20:53:48,212][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-graph]
[2022-05-11T20:53:48,213][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-ilm]
[2022-05-11T20:53:48,213][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-logstash]
[2022-05-11T20:53:48,214][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-ml]
[2022-05-11T20:53:48,214][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-monitoring]
[2022-05-11T20:53:48,214][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-rollup]
[2022-05-11T20:53:48,215][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-security]
[2022-05-11T20:53:48,215][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-sql]
[2022-05-11T20:53:48,216][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-voting-only-node]
[2022-05-11T20:53:48,216][INFO ][o.e.p.PluginsService ] [DANGFULIN] loaded module [x-pack-watcher]
[2022-05-11T20:53:48,217][INFO ][o.e.p.PluginsService ] [DANGFULIN] no plugins loaded
[2022-05-11T20:53:50,658][INFO ][o.e.x.s.a.s.FileRolesStore] [DANGFULIN] parsed [0] roles from file [D:\tools_software\Elasticsearch\elasticsearch-7.3.1\config\roles.yml]
[2022-05-11T20:53:51,143][INFO ][o.e.x.m.p.l.CppLogMessageHandler] [DANGFULIN] [controller/1336] [Main.cc@110] controller (64 bit): Version 7.3.1 (Build 1d93901e09ef43) Copyright (c) 2019 Elasticsearch BV
[2022-05-11T20:53:51,363][DEBUG][o.e.a.ActionModule ] [DANGFULIN] Using REST wrapper from plugin org.elasticsearch.xpack.security.Security
[2022-05-11T20:53:51,722][INFO ][o.e.d.DiscoveryModule ] [DANGFULIN] using discovery type [single-node] and seed hosts providers [settings]
[2022-05-11T20:53:52,158][INFO ][o.e.n.Node ] [DANGFULIN] initialized
[2022-05-11T20:53:52,159][INFO ][o.e.n.Node ] [DANGFULIN] starting ...
[2022-05-11T20:53:52,326][INFO ][o.e.t.TransportService ] [DANGFULIN] publish_address {192.168.1.11:9300}, bound_addresses {[::]:9300}
[2022-05-11T20:53:52,346][INFO ][o.e.c.c.Coordinator ] [DANGFULIN] cluster UUID [L-bKAPr-QniKUkBJi_qDTA]
[2022-05-11T20:53:52,638][INFO ][o.e.c.s.MasterService ] [DANGFULIN] elected-as-master ([1] nodes joined)[{DANGFULIN}{8AXMVaArTkSvEcgPeO8_iQ}{tqkXdkVjRLiVyddIAzIhBQ}{192.168.1.11}{192.168.1.11:9300}{dim}{ml.machine_memory=34198495232, xpack.installed=true, ml.max_open_jobs=20} elect leader, _BECOME_MASTER_TASK_, _FINISH_ELECTION_], term: 8, version: 59, reason: master node changed {previous [], current [{DANGFULIN}{8AXMVaArTkSvEcgPeO8_iQ}{tqkXdkVjRLiVyddIAzIhBQ}{192.168.1.11}{192.168.1.11:9300}{dim}{ml.machine_memory=34198495232, xpack.installed=true, ml.max_open_jobs=20}]}
[2022-05-11T20:53:52,835][INFO ][o.e.c.s.ClusterApplierService] [DANGFULIN] master node changed {previous [], current [{DANGFULIN}{8AXMVaArTkSvEcgPeO8_iQ}{tqkXdkVjRLiVyddIAzIhBQ}{192.168.1.11}{192.168.1.11:9300}{dim}{ml.machine_memory=34198495232, xpack.installed=true, ml.max_open_jobs=20}]}, term: 8, version: 59, reason: Publication{term=8, version=59}
[2022-05-11T20:53:52,927][INFO ][o.e.h.AbstractHttpServerTransport] [DANGFULIN] publish_address {192.168.1.11:9200}, bound_addresses {[::]:9200}
[2022-05-11T20:53:52,927][INFO ][o.e.n.Node ] [DANGFULIN] started
[2022-05-11T20:53:53,036][INFO ][o.e.l.LicenseService ] [DANGFULIN] license [2d2fe540-74e4-4d46-9554-c5b2395502d8] mode [basic] - valid
[2022-05-11T20:53:53,036][INFO ][o.e.x.s.s.SecurityStatusChangeListener] [DANGFULIN] Active license is now [BASIC]; Security is disabled
[2022-05-11T20:53:53,043][INFO ][o.e.g.GatewayService ] [DANGFULIN] recovered [1] indices into cluster_state
[2022-05-11T20:53:53,677][INFO ][o.e.c.r.a.AllocationService] [DANGFULIN] Cluster health status changed from [RED] to [GREEN] (reason: [shards started [[elastic_news][0]] ...]).
在其中可以看到一些配置信息:
1,节点与集群信息:
[2022-05-11T20:53:46,888][INFO ][o.e.n.Node ] [DANGFULIN] node name [DANGFULIN], node ID [8AXMVaArTkSvEcgPeO8_iQ], cluster name [elasticsearch]
...
[2022-05-11T20:53:52,346][INFO ][o.e.c.c.Coordinator ] [DANGFULIN] cluster UUID [L-bKAPr-QniKUkBJi_qDTA]
[2022-05-11T20:53:52,638][INFO ][o.e.c.s.MasterService ] [DANGFULIN] elected-as-master ([1] nodes joined)[{DANGFULIN}{8AXMVaArTkSvEcgPeO8_iQ}{tqkXdkVjRLiVyddIAzIhBQ}{192.168.1.11}{192.168.1.11:9300}{dim}{ml.machine_memory=34198495232, xpack.installed=true, ml.max_open_jobs=20} elect leader, _BECOME_MASTER_TASK_, _FINISH_ELECTION_], term: 8, version: 59, reason: master node changed {previous [], current [{DANGFULIN}{8AXMVaArTkSvEcgPeO8_iQ}{tqkXdkVjRLiVyddIAzIhBQ}{192.168.1.11}{192.168.1.11:9300}{dim}{ml.machine_memory=34198495232, xpack.installed=true, ml.max_open_jobs=20}]}
[2022-05-11T20:53:52,835][INFO ][o.e.c.s.ClusterApplierService] [DANGFULIN] master node changed {previous [], current [{DANGFULIN}{8AXMVaArTkSvEcgPeO8_iQ}{tqkXdkVjRLiVyddIAzIhBQ}{192.168.1.11}{192.168.1.11:9300}{dim}{ml.machine_memory=34198495232, xpack.installed=true, ml.max_open_jobs=20}]}, term: 8, version: 59, reason: Publication{term=8, version=59}
2,进程信息:
[2022-05-11T20:53:46,889][INFO ][o.e.n.Node ] [DANGFULIN] version[7.3.1], pid[19156], build[default/zip/4749ba6/2019-08-19T20:19:25.651794Z], OS[Windows 10/10.0/amd64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/14.0.1/14.0.1+7]
3,通信地址信息:
[2022-05-11T20:53:52,326][INFO ][o.e.t.TransportService ] [DANGFULIN] publish_address {192.168.1.11:9300}, bound_addresses {[::]:9300}
...
[2022-05-11T20:53:52,927][INFO ][o.e.h.AbstractHttpServerTransport] [DANGFULIN] publish_address {192.168.1.11:9200}, bound_addresses {[::]:9200}
- 节点之间的通信使用 9300
- HTTP的通信使用 9200
4,状态讯息:
[2022-05-11T20:53:52,927][INFO ][o.e.n.Node ] [DANGFULIN] started
可用过 CURL 工具发送 HTTP 请求来验证服务是否启动:
C:\Users\PC>curl -XGET "http://127.0.0.1:9200"
curl: (6) Could not resolve host: GET
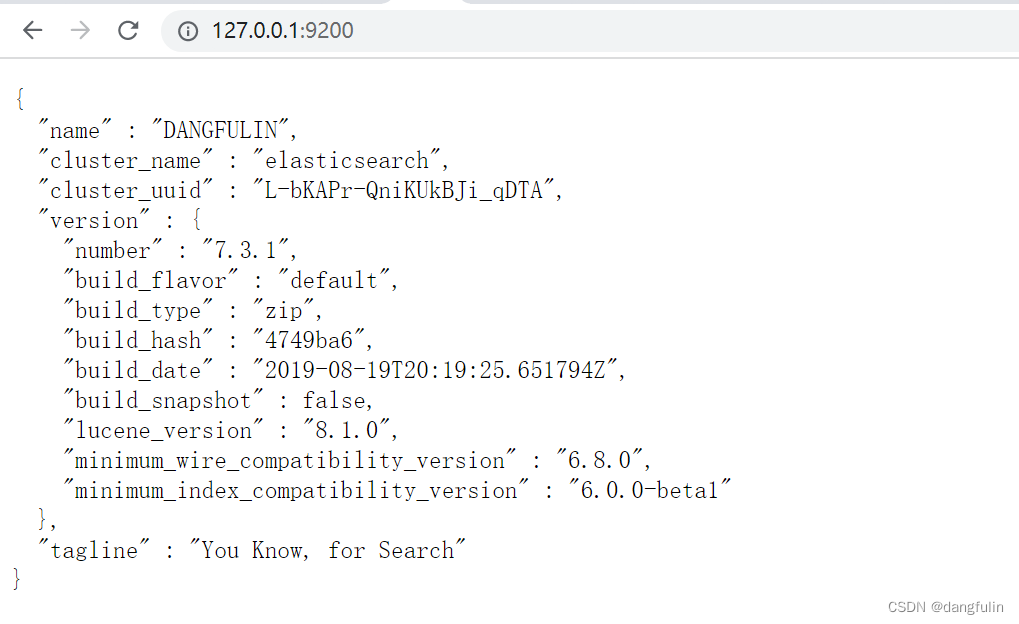
{
"name" : "DANGFULIN",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "L-bKAPr-QniKUkBJi_qDTA",
"version" : {
"number" : "7.3.1",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "4749ba6",
"build_date" : "2019-08-19T20:19:25.651794Z",
"build_snapshot" : false,
"lucene_version" : "8.1.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
或者直接访问 http://127.0.0.1:9200:
(二)REST APIs
在正式开始比较细节的操作之前,先来看看 Elasticsearch 提供的 REST APIs,它们非常有用。
1,cat APIs
尽管 Elasticsearch 使用 JSON 作为数据格式,但真正需要查看一些信息的时候是不太方便的,所以 Elasticsearch 为我们提供了获取所有细节的 API —— _cat :
C:\Users\PC> curl -XGET "http://localhost:9200/_cat
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
(1)常用参数
1,Verbose:能显示数据信息的含义。
不用 Verbose 参数:
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/nodes"
192.168.1.11 11 48 5 dim * DANGFULIN
用:
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.1.11 12 48 6 dim * DANGFULIN
2,Help:查看信息中各字段的细节。
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/master?v"
id host ip node
8AXMVaArTkSvEcgPeO8_iQ 192.168.1.11 192.168.1.11 DANGFULIN
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/master?v&help"
id | | node id
host | h | host name
ip | | ip address
node | n | node name
3,Headers:只输出指定字段。
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/nodes?v&h=ip,cpu"
ip cpu
192.168.1.11 6
4,Response formats:指定输出格式(JSON, text, YAML, smile, or cbor format based on the requirement. )。
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/indices?format=YAML"
---
- health: "green"
status: "open"
index: "elastic_news"
uuid: "livS2KxwRrK7c1eBbEf-mQ"
pri: "1"
rep: "0"
docs.count: "120000"
docs.deleted: "0"
store.size: "67mb"
pri.store.size: "67mb"
- health: "green"
status: "open"
index: "personinfo"
uuid: "R9u7MsnuR5ChQ2bPyuWuXg"
pri: "1"
rep: "0"
docs.count: "60000"
docs.deleted: "0"
store.size: "6.1mb"
pri.store.size: "6.1mb"
5,Sort:对输出的信息字段进行排序。
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/templates?v"
name index_patterns order version
.ml-meta [.ml-meta] 0 7030199
.ml-config [.ml-config] 0 7030199
.ml-anomalies- [.ml-anomalies-*] 0 7030199
.monitoring-es [.monitoring-es-7-*] 0 7000199
.data-frame-notifications-1 [.data-frame-notifications-*] 0 7030199
.monitoring-logstash [.monitoring-logstash-7-*] 0 7000199
.data-frame-internal-1 [.data-frame-internal-1] 0 7030199
.monitoring-beats [.monitoring-beats-7-*] 0 7000199
.logstash-management [.logstash] 0
.triggered_watches [.triggered_watches*] 2147483647
.monitoring-alerts-7 [.monitoring-alerts-7] 0 7000199
.monitoring-kibana [.monitoring-kibana-7-*] 0 7000199
.ml-state [.ml-state*] 0 7030199
.ml-notifications [.ml-notifications] 0 7030199
.watch-history-10 [.watcher-history-10*] 2147483647
.watches [.watches*] 2147483647
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/templates?v&s=version:desc,order"
name index_patterns order version
.ml-meta [.ml-meta] 0 7030199
.ml-config [.ml-config] 0 7030199
.ml-anomalies- [.ml-anomalies-*] 0 7030199
.data-frame-notifications-1 [.data-frame-notifications-*] 0 7030199
.data-frame-internal-1 [.data-frame-internal-1] 0 7030199
.ml-state [.ml-state*] 0 7030199
.ml-notifications [.ml-notifications] 0 7030199
.monitoring-es [.monitoring-es-7-*] 0 7000199
.monitoring-logstash [.monitoring-logstash-7-*] 0 7000199
.monitoring-beats [.monitoring-beats-7-*] 0 7000199
.monitoring-alerts-7 [.monitoring-alerts-7] 0 7000199
.monitoring-kibana [.monitoring-kibana-7-*] 0 7000199
.logstash-management [.logstash] 0
.triggered_watches [.triggered_watches*] 2147483647
.watch-history-10 [.watcher-history-10*] 2147483647
.watches [.watches*] 2147483647
下面就来解释其中出现的额外的选项的意义。
(2)count API
统计计算单个索引或所有索引中的文档数:
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/count?v"
epoch timestamp count
1652409109 02:31:49 180000
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/count/personinfo"
1652409115 02:31:55 60000
(3)health API
查看使用中的集群的健康状态:
C:\Users\PC> curl -X GET "localhost:9200/_cat/health?v&pretty"
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1652409245 02:34:05 elasticsearch green 1 1 2 2 0 0 0 0 - 100.0%
(4)indices API
查看一个集群中的所有索引信息:
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open elastic_news livS2KxwRrK7c1eBbEf-mQ 1 0 120000 0 67mb 67mb
green open personinfo R9u7MsnuR5ChQ2bPyuWuXg 1 0 60000 0 6.1mb 6.1mb
(5)master API
查看主节点含的信息:
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/master?v"
id host ip node
8AXMVaArTkSvEcgPeO8_iQ 192.168.1.11 192.168.1.11 DANGFULIN
(6)nodes API
查看一个集群中的节点信息:
C:\Users\PC>curl -XGET "http://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.1.11 35 48 6 dim * DANGFULIN
(7)shards API
查看不同节点及其分片信息:
C:\Users\PC> curl -XGET "http://localhost:9200/_cat/shards?v"
index shard prirep state docs store ip node
elastic_news 0 p STARTED 120000 67mb 192.168.1.11 DANGFULIN
personinfo 0 p STARTED 60000 6.1mb 192.168.1.11 DANGFULIN
2,Cluster APIs
集群级别的 API 能应用于集群中的所有节点。
(1)health API
获取群集的运行状况:
C:\Users\PC> curl -XGET "http://localhost:9200/_cluster/health"
{"cluster_name":"elasticsearch","status":"green","timed_out":false,"number_of_nodes":1,"number_of_data_nodes":1,"active_primary_shards":2,"active_shards":2,"relocating_shards":0,"initializing_shards":0,"unassigned_shards":0,"delayed_unassigned_shards":0,"number_of_pending_tasks":0,"number_of_in_flight_fetch":0,"task_max_waiting_in_queue_millis":0,"active_shards_percent_as_number":100.0}
(2)stats API
获取索引指标和节点指标等不同的详细信息:
C:\Users\PC>curl -XGET "http://localhost:9200/_cluster/state/_all/twitter"
{"cluster_name":"elasticsearch","cluster_uuid":"L-bKAPr-QniKUkBJi_qDTA","version":102,"state_uuid":"lS4O2LAqS3ac58c12dQt7Q","master_node":"8AXMVaArTkSvEcgPeO8_iQ","blocks":{},"nodes":{"8AXMVaArTkSvEcgPeO8_iQ":{"name":"DANGFULIN","ephemeral_id":"g2vOjJCsRT2j5uHNQyzWew","transport_address":"192.168.1.11:9300","attributes":{"ml.machine_memory":"34198495232","xpack.installed":"true","ml.max_open_jobs":"20"}}},"metadata":{"cluster_uuid":"L-bKAPr-QniKUkBJi_qDTA","cluster_coordination":{"term":11,"last_committed_config":["8AXMVaArTkSvEcgPeO8_iQ"],"last_accepted_config":["8AXMVaArTkSvEcgPeO8_iQ"],"voting_config_exclusions":[]},"templates":{},"indices":{},"index-graveyard":{"tombstones":[]}},"routing_table":{"indices":{}},"routing_nodes":{"unassigned":[],"nodes":{"8AXMVaArTkSvEcgPeO8_iQ":[]}}}
(三)演示项目:在线书店
这里将通过一个在线书店小项目(来自《Elasticsearch in Action, Second Edition MEAP》)来演示更多对 Elasticsearch 8.X 的使用方式。
1,准备数据
巧妇难为无米之炊😢我们需要为 Elasticsearch 填充一些数据以作为搜索的基础。
(1)项目概述
这里并不是要创建一个完整好的项目,只是为了演示 Elasticsearch 的一些特点,所以我们要做的就是创建一个图书库存清单,并做一些查询工作。
数据模型 books 非常简单:

(2)数据源
从数据库的角度来说,elasticsearch 是一个文档数据库,它使用 JSON 格式来描述文档内容:

有好几种方式能让客户端的数据被 elasticsearch 索引:
- 创建一个从相关数据库输送数据的适配器。
- 从文件系统中提取数据。
- 从实时的数据源的流事件中获取数据。
无论哪种方式,我们都通过基于 JSON 格式的 RESTful APIs 将数据加载到 elasticsearch。
(3)文档 APIs
为了能索引文档(indexing documents),我们需要事先使用 HTTP PUT 或 POST 请求将数据传到 elasticsearch。
请求的具体格式解释如下:
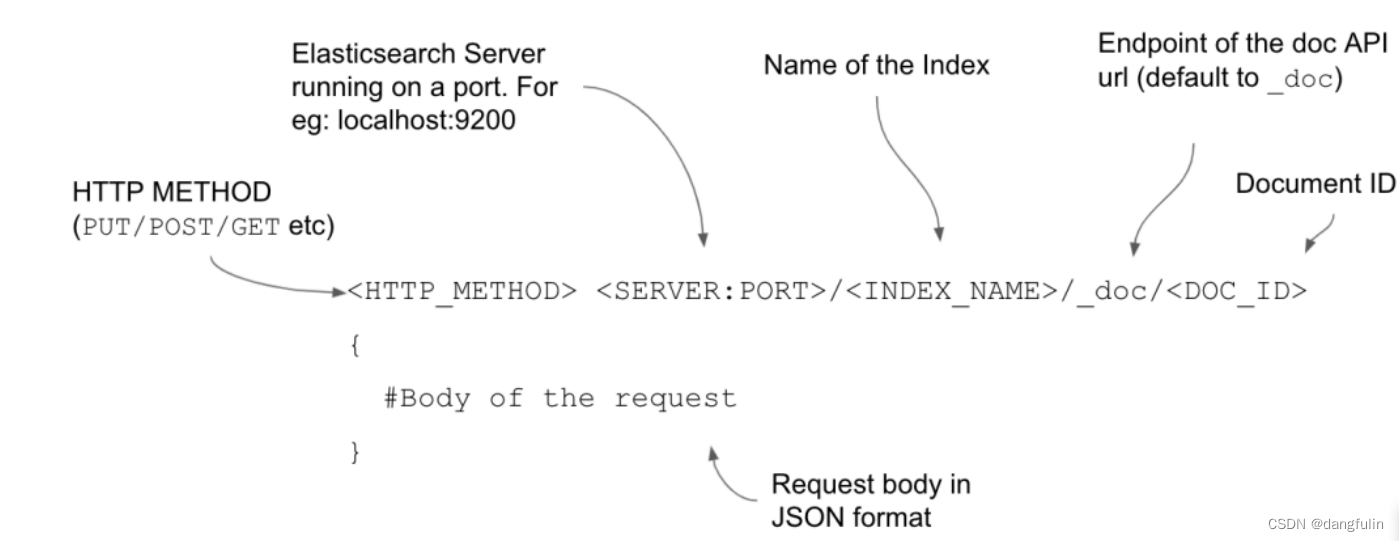
通过下面的内容创建一条文档:
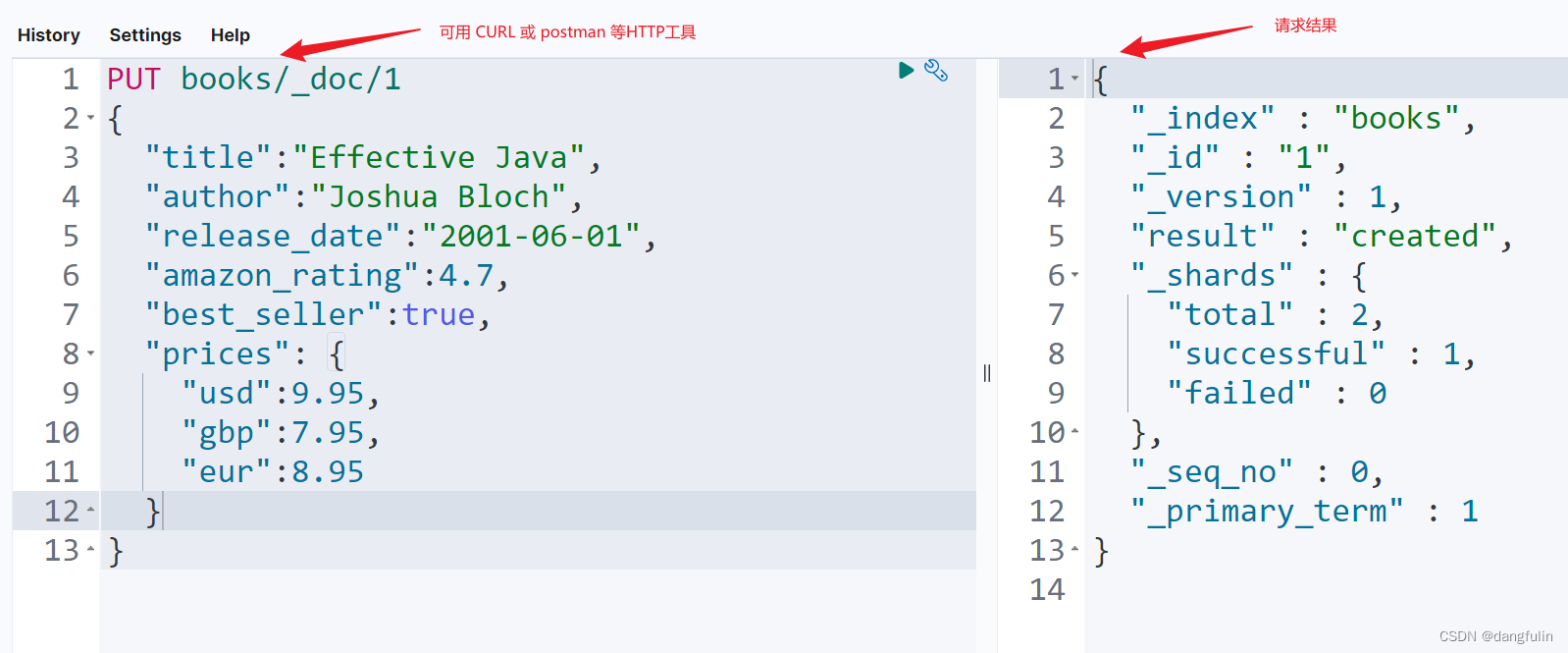
- 注意!不要忘记在 POST 的请求路径的最后添加文档 ID
使用 curl 工具时,具体命令及解释如下:
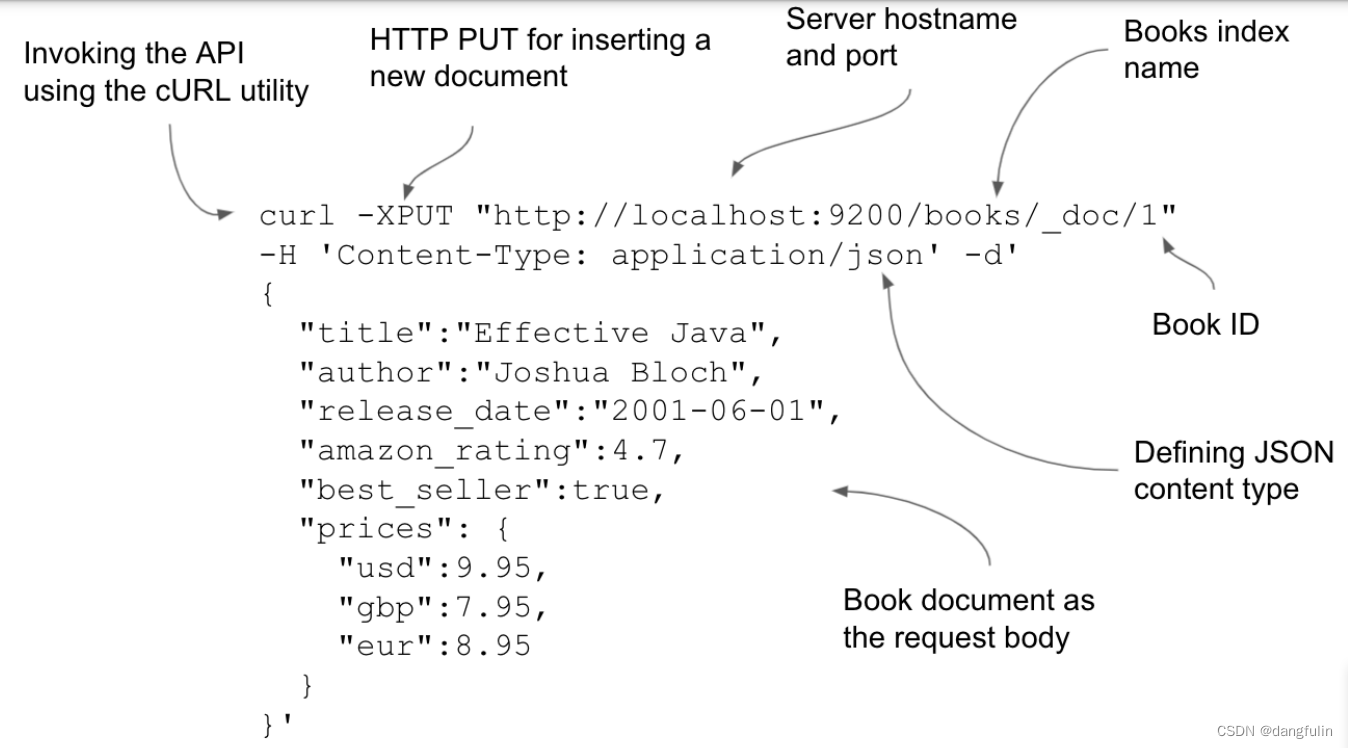
好了,这就创建好一个文档了,具体如整个过程到底是怎样实现的、依赖了些什么、响应中的一些元数据的意义是什么等等,都放到后面来说😆
(4)索引文档
虽然还不会涉及过多的细节,但从较高层级来看,是这样一个过程:
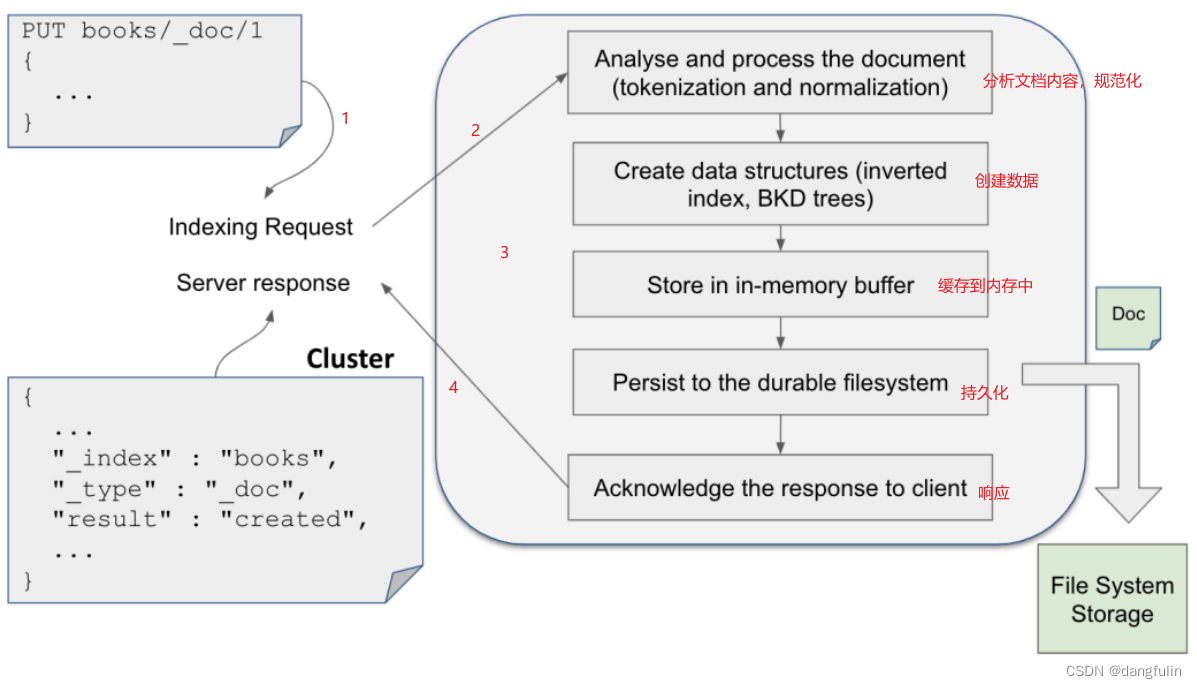
就这样,我们就索引了一条文档,有点像往 RDBMS 插入一条记录的样子哈😀但最主要不同的是,在索引第一条文档之前我们并没有类似定义 schema 的动作,但实际上 elasticsearch 已经自动替我们完成相关动作了。
以索引文档的方式创建索引:
POST index/_doc/1
{
JSON key-value pairs
}
为了让后面的演示能继续进行,请索引跟多文档。
(5)批量索引文档
在接触查询之前,让我们用 _bulk API 批量索引文档:
POST _bulk
{"index":{"_index":"books","_id":"1"}}
{"title": "Core Java Volume I – Fundamentals","author": "Cay S. Horstmann","edition": 11, "synopsis": "Java reference book that offers a detailed explanation of various features of Core Java, including exception handling, interfaces, and lambda expressions. Significant highlights of the book include simple language, conciseness, and detailed examples.","amazon_rating": 4.6,"release_date": "2018-08-27","tags": ["Programming Languages, Java Programming"]}
{"index":{"_index":"books","_id":"2"}}
{"title": "Effective Java","author": "Joshua Bloch", "edition": 3,"synopsis": "A must-have book for every Java programmer and Java aspirant, Effective Java makes up for an excellent complementary read with other Java books or learning material. The book offers 78 best practices to follow for making the code better.", "amazon_rating": 4.7, "release_date": "2017-12-27", "tags": ["Object Oriented Software Design"]}
{"index":{"_index":"books","_id":"3"}}
{"title": "Java: A Beginner’s Guide", "author": "Herbert Schildt","edition": 8,"synopsis": "One of the most comprehensive books for learning Java. The book offers several hands-on exercises as well as a quiz section at the end of every chapter to let the readers self-evaluate their learning.","amazon_rating": 4.2,"release_date": "2018-11-20","tags": ["Software Design & Engineering", "Internet & Web"]}
{"index":{"_index":"books","_id":"4"}}
{"title": "Java - The Complete Reference","author": "Herbert Schildt","edition": 11,"synopsis": "Convenient Java reference book examining essential portions of the Java API library, Java. The book is full of discussions and apt examples to better Java learning.","amazon_rating": 4.4,"release_date": "2019-03-19","tags": ["Software Design & Engineering", "Internet & Web", "Computer Programming Language & Tool"]}
{"index":{"_index":"books","_id":"5"}}
{"title": "Head First Java","author": "Kathy Sierra and Bert Bates","edition":2, "synopsis": "The most important selling points of Head First Java is its simplicity and super-effective real-life analogies that pertain to the Java programming concepts.","amazon_rating": 4.3,"release_date": "2005-02-18","tags": ["IT Certification Exams", "Object-Oriented Software Design","Design Pattern Programming"]}
{"index":{"_index":"books","_id":"6"}}
{"title": "Java Concurrency in Practice","author": "Brian Goetz with Tim Peierls, Joshua Bloch, Joseph Bowbeer, David Holmes, and Doug Lea","edition": 1,"synopsis": "Java Concurrency in Practice is one of the best Java programming books to develop a rich understanding of concurrency and multithreading.","amazon_rating": 4.3,"release_date": "2006-05-09","tags": ["Computer Science Books", "Programming Languages", "Java Programming"]}
{"index":{"_index":"books","_id":"7"}}
{"title": "Test-Driven: TDD and Acceptance TDD for Java Developers","author": "Lasse Koskela","edition": 1,"synopsis": "Test-Driven is an excellent book for learning how to write unique automation testing programs. It is a must-have book for those Java developers that prioritize code quality as well as have a knack for writing unit, integration, and automation tests.","amazon_rating": 4.1,"release_date": "2007-10-22","tags": ["Software Architecture", "Software Design & Engineering", "Java Programming"]}
{"index":{"_index":"books","_id":"8"}}
{"title": "Head First Object-Oriented Analysis Design","author": "Brett D. McLaughlin, Gary Pollice & David West","edition": 1,"synopsis": "Head First is one of the most beautiful finest book series ever written on Java programming language. Another gem in the series is the Head First Object-Oriented Analysis Design.","amazon_rating": 3.9,"release_date": "2014-04-29","tags": ["Introductory & Beginning Programming", "Object-Oriented Software Design", "Java Programming"]}
{"index":{"_index":"books","_id":"9"}}
{"title": "Java Performance: The Definite Guide","author": "Scott Oaks","edition": 1,"synopsis": "Garbage collection, JVM, and performance tuning are some of the most favorable aspects of the Java programming language. It educates readers about maximizing Java threading and synchronization performance features, improve Java-driven database application performance, tackle performance issues","amazon_rating": 4.1,"release_date": "2014-03-04","tags": ["Design Pattern Programming", "Object-Oriented Software Design", "Computer Programming Language & Tool"]}
{"index":{"_index":"books","_id":"10"}}
{"title": "Head First Design Patterns", "author": "Eric Freeman & Elisabeth Robson with Kathy Sierra & Bert Bates","edition": 10,"synopsis": "Head First Design Patterns is one of the leading books to build that particular understanding of the Java programming language." ,"amazon_rating": 4.5,"release_date": "2014-03-04","tags": ["Design Pattern Programming", "Object-Oriented Software Design eTextbooks", "Web Development & Design eTextbooks"]}
美两行实现一条文档的索引:
- 前一行指定记录文档所用的元数据。
- 后一行才是文档数据本身。
2,查询数据
尽管数据量非常少😆但也是时候行动起来检查我们如何检索、搜索和聚合这些文档了。
(1)文档总数
了解索引中有多少条文档是非常必要的, _count API 就提供这项功能:

- 从指定的索引(books)中获取文档数量。
获取文档总数:
GET index/_count 从指定索引获取文档总数
GET index-1,index-2/_count 从多个指定索引获取文档总数
GET _count 获取所有文档总数
(2)查询文档
每条文档都有独立的标识,有些是我们指定的,有些是自动生的。
只需要记得文档 ID 就能查询文档了:

仔细看看响应的内容,主要包括两部分:
- 由
_source标签包裹的源文档数据。 - 其余的就是元数据。
如果要查询多个文档,就需要通过 _search API 使用包裹在 query 对象中的 ids:

- 在请求体中,使用了
query对象来构建查询。 query对象中包含一个名为ids的内部对象来指定 ID 列表。
不携带请求体的话,会列出所有文档:

查询文档:
GET <index>/_doc/<id> # 查询单条文档
GET <index>/_source/<id> # 只获取源文档数据
GET <index>/_source # 获取指定 ID 的文档数据
{
"query": {
"ids": {
"values": [id array]
}
},
}
目前看来,查询还没展示出 elasticsearch 的真正特性,比如获取某一作者总评分高于4.5的书这类比较复杂的查询,我们后面再讲这类高级的使用方式。
(3)只获取源数据地部分字段
如果需要的话,还能通过下面的方式禁止向客户端发送源数据:
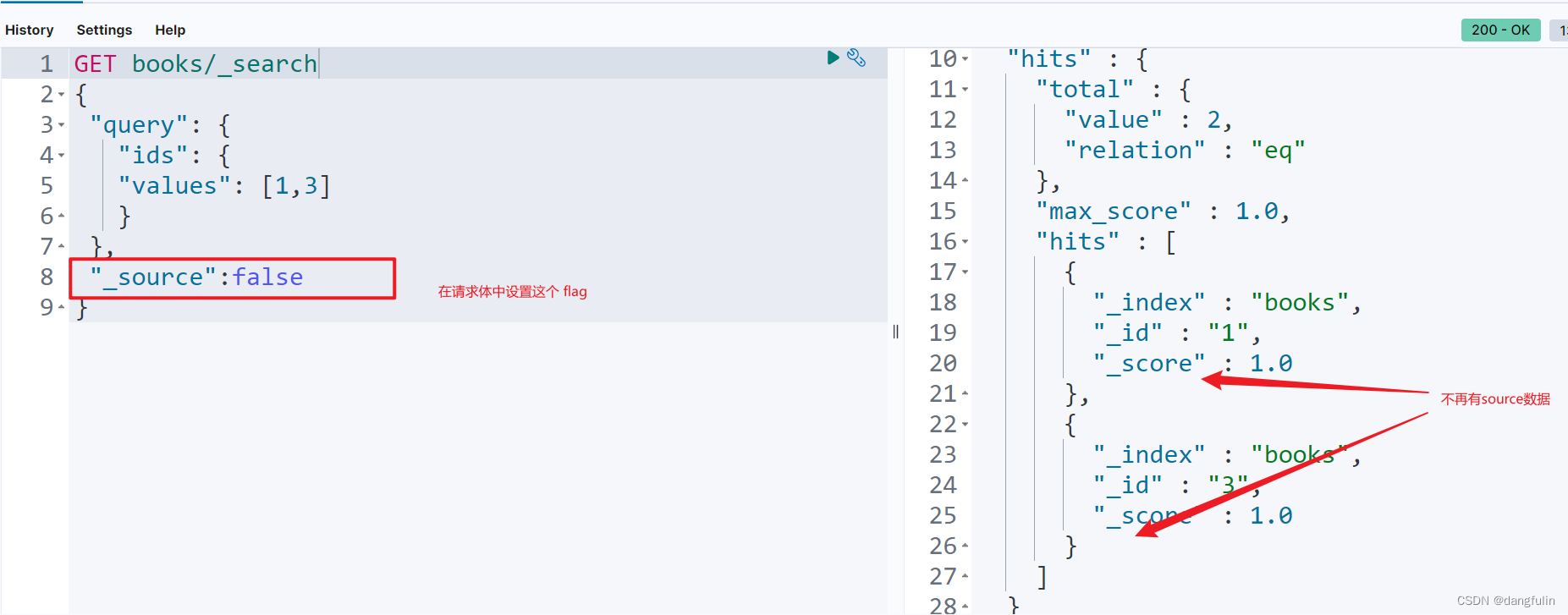
还能进一步在其中添加 includes 参数指定想获取的字段:
GET books/_search
{
"_source": {
"includes": [
"title",
"synopsis"
]
}
}
查询文档:
GET <index>/_source # 不返回 source 数据
{
"_source":false
}
GET books/_search # 返回 source 数据中指定地字段
{
"_source": {
"includes": [
"title",
"synopsis"
]
}
}
GET books/_search # 不返回 source 数据中指定地字段
{
"_source": {
"excludes": [
"title",
"synopsis"
]
}
}
(4)单字段检索
全文检索是 elasticsearch 的重要应用:在已被索引的文档中检索出符合条件内容的文档。
🌰:如果用户想搜索指定作者出的书,那么我们依旧可以使用 _search API,只不过此时要在 author 字段上应用 match query:
GET books/_search
{
"query": {
"match": {
"author": "David Flanagan"
}
}
}
- 请求体的
query对象中包含一个名为match的内部对象来指定在 author 字段上查找 “David Flanagan”。
让我们看看完整的检索结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 3.077668,
"hits" : [
{
"_index" : "books",
"_id" : "3",
"_score" : 3.077668,
"_source" : {
"title" : "JavaScript: The Definitive Guide: Master the World's Most-Used Programming Language 7th Edition",
"author" : "David Flanagan",
"release_date" : "2020-12-01",
"amazon_rating" : 4.7,
"best_seller" : true,
"prices" : {
"usd" : 41.99,
"gbp" : 33.7,
"eur" : 40.07
}
}
},
{
"_index" : "books",
"_id" : "10",
"_score" : 2.2201133,
"_source" : {
"title" : "Java in a Nutshell: A Desktop Quick Reference 7th Edition",
"author" : [
"Benjamin Evans",
"David Flanagan"
],
"release_date" : "2018-12-03",
"amazon_rating" : 4.4,
"best_seller" : false,
"prices" : {
"usd" : 22.69,
"gbp" : 18.69,
"eur" : 21.69
}
}
}
]
}
}
- 可以看到,文档收录了 David Flanagan 写的两本书,且各自的
_score分数还不同。
让我们改变一下 author 的拼写:
"author": "David FlaNagan" 匹配 "_score" : 3.077668, "_score" : 2.2201133, 不变
"author": "DaviD FlaNagan" 匹配 "_score" : 3.077668, "_score" : 2.2201133, 不变
"author": "David Nagan" 匹配 "_score" : 1.538834, "_score" : 1.1100566,
"author": "Flanagan" 匹配 "_score" : 1.538834, "_score" : 1.1100566, 变化
"author": "David" 匹配 "_score" : 1.538834, "_score" : 1.1100566, 变化
"author": "DAVID" 匹配 "_score" : 1.538834, "_score" : 1.1100566, 变化
"author": "david" 匹配 "_score" : 1.538834, "_score" : 1.1100566, 变化
"author": "Nagan" 无检索结果
"author": "Davi" 无检索结果
- 发现没,elasticsearch 会自动调整 score,当某些匹配条件相近时, score 还会保持不变。
- 甚至 David Nagan 都还是能匹配到 David Flanaga 对应的书。
还能使用 prefix query 来实现正则匹配:
prefixquery 是一个词(iterm)级别的查询,所以对应待查询字段的值只能是小写的。
"author": "dav" 匹配 "_score" : 1.0, "_score" : 1.0, 变化
"author": "Dav" 无检索结果
这里继续解释一个现象:搜 David Nagan (不存在的作者)都还是能匹配到 David Flanaga (存在的作者)对应的书。
这是因为 elasticsearch 将搜索 firstname lastname 视为搜索 firstname OR lastname,尽可能地匹配。
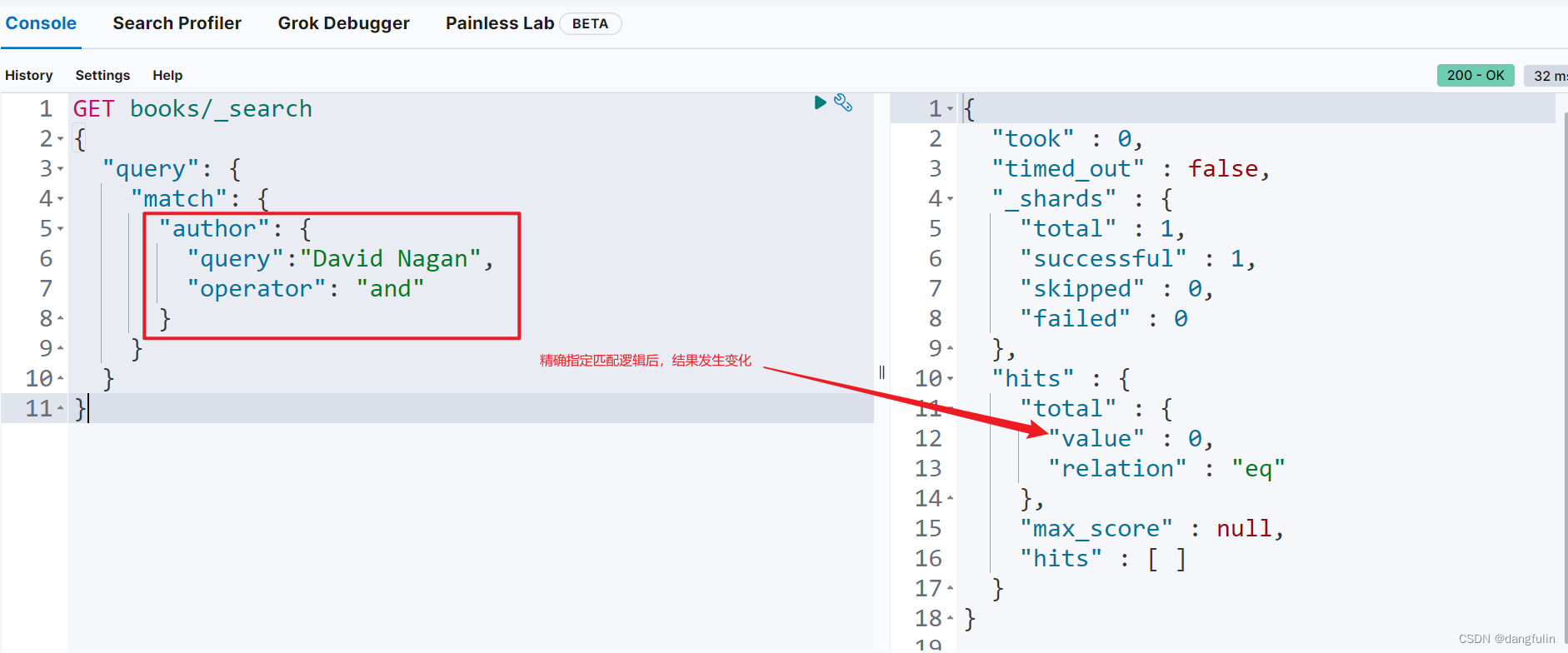
如果要修改这种逻辑关系,我们可以在请求体的字段匹配中使用运算符参数来精确地指定匹配逻辑:
GET books/_search
{
"query": {
"match": {
"author": {
"query":"David Nagan",
"operator": "and"
}
}
}
}
如果我们在搜索 title 时这种逻辑修改的结果更加明显:
GET books/_search
{
"query": {
"match": {
"title": "Java learn"
}
}
}
将匹配七个结果:
"_score": 1.8459845, "title" : "Learn Java the Easy Way: A Hands-On Introduction to Programming",
"_score": 1.6362495, "title" : "Hands-On Software Architecture with Java: Learn key architectural techniques and strategies to design efficient and elegant Java applications",
"_score": 1.1598315, "title" : "Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition",
"_score": 1.0178609, "title" : "Effective Java",
"_score": 0.8989545, "title": "Java: A Beginner’s Guide",
"_score": 0.72870094, "title": "Java: The Complete Reference, Twelfth Edition 12th Edition",
"_score": 0.6656655, "title": "Java in a Nutshell: A Desktop Quick Reference 7th Edition",
修改后:
GET books/_search
{
"query": {
"match": {
"title": {
"query":"Java learn",
"operator": "and"
}
}
}
}
将匹配两个结果:
"_score" : 1.8459845, "title" : "Learn Java the Easy Way: A Hands-On Introduction to Programming",
"_score" : 1.6362495, "title" : "Hands-On Software Architecture with Java: Learn key architectural techniques and strategies to design efficient and elegant Java applications",
(5)跨字段检索
为了给搜索提供尽可能多的结果,我们就不能只将搜索对象限定在一个字段之内。
当能被搜索的字段足够多的时候,就成了所谓的“全文检索”。
elasticsearch 提供 multi_match query 实现多字段搜索。
🌰:从标题和摘要中搜索关键字 Java:
GET books/_search
{
"query":{
"multi_match": {
"query": "Java",
"fields": ["title","synopsis"]
}
},
"_source":{
"includes": [
"title",
"synopsis"
]
}
}
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 12,
"relation" : "eq"
},
"max_score" : 2.1310725,
"hits" : [
{
"_index" : "books",
"_id" : "4",
"_score" : 2.1310725,
"_source" : {
"synopsis" : "Convenient Java reference book examining essential portions of the Java API library, Java. The book is full of discussions and apt examples to better Java learning.",
"title" : "Java - The Complete Reference"
}
},
{
"_index" : "books",
"_id" : "2",
"_score" : 2.0172975,
"_source" : {
"synopsis" : "A must-have book for every Java programmer and Java aspirant, Effective Java makes up for an excellent complementary read with other Java books or learning material. The book offers 78 best practices to follow for making the code better.",
"title" : "Effective Java"
}
},
{
"_index" : "books",
"_id" : "9",
"_score" : 1.902419,
"_ignored" : [
"synopsis.keyword"
],
"_source" : {
"synopsis" : "Garbage collection, JVM, and performance tuning are some of the most favorable aspects of the Java programming language. It educates readers about maximizing Java threading and synchronization performance features, improve Java-driven database application performance, tackle performance issues",
"title" : "Java Performance: The Definite Guide"
}
},
{
"_index" : "books",
"_id" : "6",
"_score" : 1.8910649,
"_source" : {
"synopsis" : "Java Concurrency in Practice is one of the best Java programming books to develop a rich understanding of concurrency and multithreading.",
"title" : "Java Concurrency in Practice"
}
},
{
"_index" : "books",
"_id" : "5",
"_score" : 1.8384864,
"_source" : {
"synopsis" : "The most important selling points of Head First Java is its simplicity and super-effective real-life analogies that pertain to the Java programming concepts.",
"title" : "Head First Java"
}
},
{
"_index" : "books",
"_id" : "1",
"_score" : 1.7416387,
"_source" : {
"synopsis" : "Java reference book that offers a detailed explanation of various features of Core Java, including exception handling, interfaces, and lambda expressions. Significant highlights of the book include simple language, conciseness, and detailed examples.",
"title" : "Core Java Volume I – Fundamentals"
}
},
{
"_index" : "books",
"_id" : "10",
"_score" : 1.5168624,
"_source" : {
"synopsis" : "Head First Design Patterns is one of the leading books to build that particular understanding of the Java programming language.",
"title" : "Head First Design Patterns"
}
},
{
"_index" : "books",
"_id" : "8",
"_score" : 1.3607827,
"_source" : {
"synopsis" : "Head First is one of the most beautiful finest book series ever written on Java programming language. Another gem in the series is the Head First Object-Oriented Analysis Design.",
"title" : "Head First Object-Oriented Analysis Design"
}
},
{
"_index" : "books",
"_id" : "3",
"_score" : 1.3304513,
"_source" : {
"synopsis" : "One of the most comprehensive books for learning Java. The book offers several hands-on exercises as well as a quiz section at the end of every chapter to let the readers self-evaluate their learning.",
"title" : "Java: A Beginner’s Guide"
}
},
{
"_index" : "books",
"_id" : "7",
"_score" : 1.2112259,
"_source" : {
"synopsis" : "Test-Driven is an excellent book for learning how to write unique automation testing programs. It is a must-have book for those Java developers that prioritize code quality as well as have a knack for writing unit, integration, and automation tests.",
"title" : "Test-Driven: TDD and Acceptance TDD for Java Developers"
}
}
]
}
}

我们通常无法一碗水端平——总是需要有侧重点。这就需要通过我们之前提到的 _score 得分 ——一个表明结果中文档与 query 相关度的正浮点数,并以此降序排列搜索结果(Okapi BM25 算法)——来为某些字段提供更高的优先级。
🌰:从标题和摘要中搜索关键字 Java,标题优先级更高:
GET books/_search
{
"query":{
"multi_match": {
"query": "Java",
"fields": ["title","synopsis"]
}
},
"_source":{
"includes": [
"title^2",
"synopsis"
]
}
}
(6)查询短语
到目前为止,我们都是在单词级别进行查询,而多数时候,我们需要查询的是一组短语,比如“must-have book for every Java programmer”,这可以通过使用 match_phrase query 来实现:
GET books/_search
{
"query": {
"match_phrase": {
"synopsis": "must-have book for every Java programmer"
}
}
}
结果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 13.994365,
"hits" : [
{
"_index" : "books",
"_id" : "2",
"_score" : 13.994365,
"_source" : {
"title" : "Effective Java",
"author" : "Joshua Bloch",
"edition" : 3,
"synopsis" : "A must-have book for every Java programmer and Java aspirant, Effective Java makes up for an excellent complementary read with other Java books or learning material. The book offers 78 best practices to follow for making the code better.",
"amazon_rating" : 4.7,
"release_date" : "2017-12-27",
"tags" : [
"Object Oriented Software Design"
]
}
}
]
}
}
而且多数时候我们并不能完全记得完整的短语组,比如漏掉几个词、拼错几个词。如果这时还是使用 match_phrase query 的话就不能搜索到任何内容,比如:

这显然是不能接受的,此时就应该使用带有能指示确实词数量的 slop 参数的 match_phrase query 来完成查询:
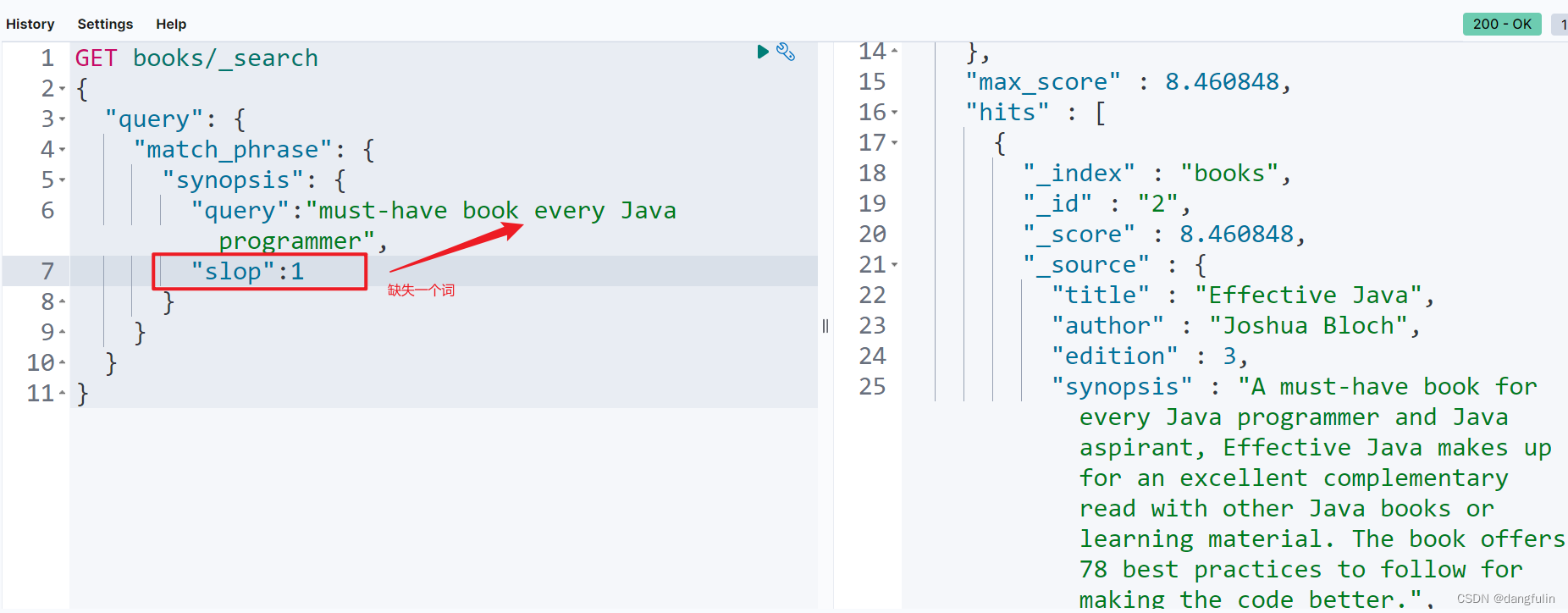
一个变体就是 match_phrase_prefix query,作用与 prefix query 相同,只不过是匹配短语罢了,比如:

(7)模糊查询
相对于漏词,拼错是一个更加普遍的问题。但好在所有的搜索引擎都支持模糊查询,我们可以用 fuzzy query 实现:
GET books/_search
{
"query": {
"fuzzy": {
"title": {
"value": "Kava",
"fuzziness": 1 # 指定模糊量:这里允许模糊一个字母。
}
}
}
}
(8)高亮查询结果
在查询结果中高亮被查询的内容是一个非常有用的功能,可以与 query 对象同级使用 highlight 对象对指定字段进行高亮:

到此为止,非结构化的全文检索的一些简单命令就讲完了,接下来讲讲对结构化数据的全文检索。
(9)iterm 级别的查询
Elasticsearch 创建了一种被称为 iterm 查询的查询形式来支持查询结构化数据。
- 相较于无法确定具体内容的非结构化数据,结构化数据指数字、范围、日期、IP 地址等可直接对比的内容:

- 我们并没有指定结构化数据的类型,主要由 elasticsearch 自行推断(手动指定的方法后面再说)。
elasticsearch 一两种不同的方式对待这两种结构的查询:结构化数据的查询是“非黑即白”的,不存在非结构化数据查询那种模棱两可的情况。
- 要事先分析非结构化数据。
- 直接排序结构化数据。
使用 term query 完成结构化数据的精确查询:

- 发现没,_score 都是 1.0,因为 iterm 级别的查询并不关心这个相似度。
使用 range query 完成结构化数据的范围查询,比如年龄在 18 ~ 65岁的人的信息、总成绩在256 ~ 500分的学生考号、在2020-10-01~2021-10-01期间收录的论文标题等等。举个例子:

我们已讲过这么多查询方式了,它们都比较简单,而实际的查询多数情况下都非常复杂,比如“查询 Joshua 2005年之后出版的评分超过4.5的第一个版本的书”。
3,复合查询
elasticsearch 提供复合查询来满足复杂查询的需要。
复合查询使用被称为叶查询的单个查询来构建健壮的复杂查询,一些复合查询类型如下:

最常用的就是布尔查询了,这里就只介绍它,更多的内容后面再说。
(1)布尔查询
bool query 用于根据布尔条件组合其他查询来创建复杂的查询逻辑。bool查询期望使用下面的 4 个子句构建搜索:
| 子句 | 释义 |
|---|---|
| must | must 子句存放的查询必须在文档中匹配查询条件。应尽可能多地使用叶查询以提高相关性得分。 |
| should | should 子句的查询应该在文档中匹配查询条件。 |
| filter | filter 子句的查询必须在文档中匹配查询条件,但相关性得分会被忽略。 |
| must_not | must_not 子句的查询不必在文档中匹配查询条件,返回所有文档的相关性得分为0。 |
现在将上面那个复杂的查询拆分一下:

(2)must 子句
我们要找 Joshua 写的书,可以创建一个包含 must 子句的布尔查询,然后让 must 子句包含一个 match query:
GET books/_search
{
"query": {
"bool": {
"must": [{
"match":{
"author": "Joshua Bloch"
}
}]
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 6.615054,
"hits" : [
{
"_index" : "books",
"_id" : "2",
"_score" : 6.615054,
"_source" : {
"title" : "Effective Java",
"author" : "Joshua Bloch",
"edition" : 3,
"synopsis" : "A must-have book for every Java programmer and Java aspirant, Effective Java makes up for an excellent complementary read with other Java books or learning material. The book offers 78 best practices to follow for making the code better.",
"amazon_rating" : 4.7,
"release_date" : "2017-12-27",
"tags" : [
"Object Oriented Software Design"
]
}
},
{
"_index" : "books",
"_id" : "6",
"_score" : 2.387682,
"_source" : {
"title" : "Java Concurrency in Practice",
"author" : "Brian Goetz with Tim Peierls, Joshua Bloch, Joseph Bowbeer, David Holmes, and Doug Lea",
"edition" : 1,
"synopsis" : "Java Concurrency in Practice is one of the best Java programming books to develop a rich understanding of concurrency and multithreading.",
"amazon_rating" : 4.3,
"release_date" : "2006-05-09",
"tags" : [
"Computer Science Books",
"Programming Languages",
"Java Programming"
]
}
}
]
}
}
- 布尔查询包含在
query对象中。 - must 子句接收一个 array,这意味着我们能向其中添加更多额外的查询,比如:
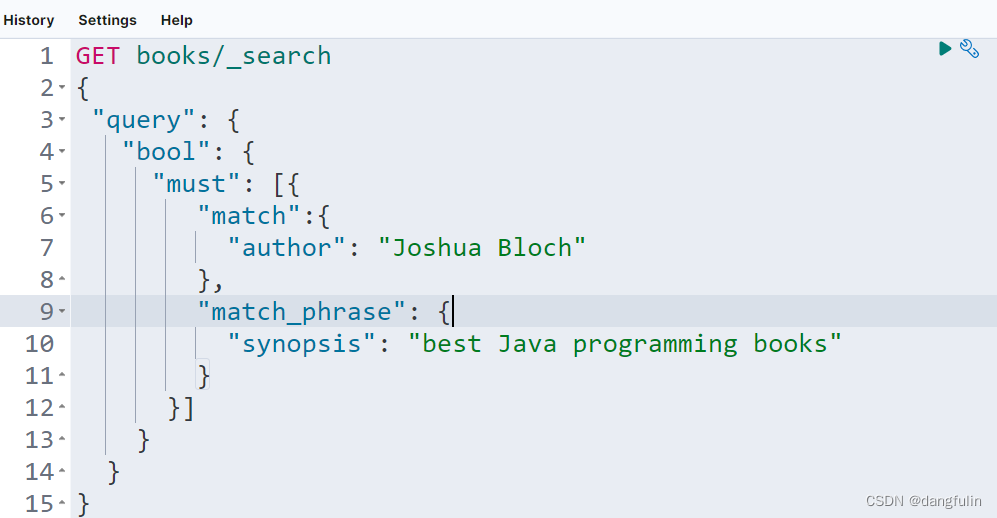
(3)must_not 子句
评分等于高于 4.7 换句话就是评分不低于 4.7。我们就用包含 range query 的 must_not 子句来实现:
GET books/_search
{
"query": {
"bool": {
"must": [{ "match":{ "author": "Joshua Bloch" }}],
"must_not": [{ "range": { "amazon_rating": { "lt": 4.7}}}]
}
}
}
结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 6.615054,
"hits" : [
{
"_index" : "books",
"_id" : "2",
"_score" : 6.615054,
"_source" : {
"title" : "Effective Java",
"author" : "Joshua Bloch",
"edition" : 3,
"synopsis" : "A must-have book for every Java programmer and Java aspirant, Effective Java makes up for an excellent complementary read with other Java books or learning material. The book offers 78 best practices to follow for making the code better.",
"amazon_rating" : 4.7,
"release_date" : "2017-12-27",
"tags" : [
"Object Oriented Software Design"
]
}
}
]
}
}
结果只剩一本书了。
(4)should 子句
除了搜索评分不低于4.7的Joshua所写的书,我们是否可以添加一个条件,如果这些书匹配一个标签(例如tag =“Software”),则可以提高相关度得分?
should 子句的行为类似于 OR 运算符:如果匹配,相关性得分就会上升;如果单词不匹配,查询将不会失败,只是不加分。should 从句更多的是增加相关性分数,而不是影响结果。
GET books/_search
{
"query": {
"bool": {
"must": [{ "match":{ "author": "Joshua Bloch" }}],
"must_not": [{ "range": { "amazon_rating": { "lt": 4.7}}}],
"should": [{"match": {"tags": "Software"}}]
}
}
}
结果:
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 8.156579,
"hits" : [
{
"_index" : "books",
"_id" : "2",
"_score" : 8.156579,
"_source" : {
"title" : "Effective Java",
"author" : "Joshua Bloch",
"edition" : 3,
"synopsis" : "A must-have book for every Java programmer and Java aspirant, Effective Java makes up for an excellent complementary read with other Java books or learning material. The book offers 78 best practices to follow for making the code better.",
"amazon_rating" : 4.7,
"release_date" : "2017-12-27",
"tags" : [
"Object Oriented Software Design"
]
}
}
]
}
}
- 结果的相关性得分更高了,说明结果更加精准了。
(5)filter 子句
我们将过滤出2015年之前出版的书,也就是说,不希望在结果集中出现2015年之前出版的书:
GET books/_search
{
"query": {
"bool": {
"must": [{ "match":{ "author": "Joshua Bloch" }}],
"must_not": [{ "range": { "amazon_rating": { "lt": 4.7}}}],
"should": [{"match": {"tags": "Software"}}],
"filter":[{"range":{"release_date":{"gte": "2015-01-01"}}}]
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 8.156579,
"hits" : [
{
"_index" : "books",
"_id" : "2",
"_score" : 8.156579,
"_source" : {
"title" : "Effective Java",
"author" : "Joshua Bloch",
"edition" : 3,
"synopsis" : "A must-have book for every Java programmer and Java aspirant, Effective Java makes up for an excellent complementary read with other Java books or learning material. The book offers 78 best practices to follow for making the code better.",
"amazon_rating" : 4.7,
"release_date" : "2017-12-27",
"tags" : [
"Object Oriented Software Design"
]
}
}
]
}
}
- 相关性得分没有变化。
4,聚合
我们已经了解了如何从给定的文档语料库中搜索文档。分析操作则着眼于大局,从一个非常高的层次分析数据,从而得出有用结论,比如:
- 我的网站的平均加载时间是多少?
- 根据交易量,谁是我最有价值的客户?
- 什么会被认为是我网络上的大文件?
- 每个产品类别有多少产品?
我们可以使用 aggregation APIs 在 Elasticsearch 中提供这个分析。聚合分为三类:
- Metric aggregations:像 sum、min、max 和 average 这样的简单聚合都属于这一类聚合。它们提供跨一组文档数据的简单聚合值。
- Bucket aggregations:帮助将数据收集到 bucket 中,然后将 bucket 按天数、年龄组等间隔分开。这些可以帮助我们构建直方图、饼图和其他可视化图形。
- Pipeline aggregations:处理来自其他聚合的输出。
我们将在 _search 断点的请求体中使用 aggs 对象来代替 query 对象完成聚合工作。举个例子:

- 语法上来看,是非常清晰的。
为了更有效地展示聚合地作用,这里就使用新的索引:
POST covid/_bulk
{"index":{}}
{"country":"United States of America","date":"2021-03-26","cases":30853032,"deaths":561142,"recovered":23275268,"critical":8610}
{"index":{}}
{"country":"Brazil","date":"2021-03-26","cases":12407323,"deaths":307326,"recovered":10824095,"critical":8318}
{"index":{}}
{"country":"India","date":"2021-03-26","cases":11908373,"deaths":161275,"recovered":11292849,"critical":8944}
{"index":{}}
{"country":"Russia","date":"2021-03-26","cases":4501859,"deaths":97017,"recovered":4120161,"critical":2300}
{"index":{}}
{"country":"France","date":"2021-03-26","cases":4465956,"deaths":94275,"recovered":288062,"critical":4766}
{"index":{}}
{"country":"United kingdom","date":"2021-03-26","cases":4325315,"deaths":126515,"recovered":3768434,"critical":630}
{"index":{}}
{"country":"Italy","date":"2021-03-26","cases":3488619,"deaths":107256,"recovered":2814652,"critical":3628}
{"index":{}}
{"country":"Spain","date":"2021-03-26","cases":3255324,"deaths":75010,"recovered":3016247,"critical":1830}
{"index":{}}
{"country":"Turkey","date":"2021-03-26","cases":3149094,"deaths":30772,"recovered":2921037,"critical":1810}
{"index":{}}
{"country":"Germany","date":"2021-03-26","cases":2754002,"deaths":76303,"recovered":2467600,"critical":3209}
- 让紫铜自动生成文档 ID。
(1)Metrics
这是一类常用的简单聚合,主要是获取一些简单的统计数据。
假设我们想要找到所有前 10 个国家的危重患者总数:
GET covid/_search
{
"size": 0, # 不包含文档数据
"aggs": { #A Writing an aggregation query
"critical_patients": { #B User defined query output name
"sum": {#C The sum metric - sum of all the critical patients
"field": "critical" #D The field on which the aggregation is applied
}
}
}
}
结果:
"aggregations" : {
"critical_patients" : {
"value" : 44045.0
}
}
其它的聚合:
GET covid/_search
{
"size": 0,
"aggs": {
"max_deaths": {
"max": {
"field": "deaths"
}
}
}
}
结果:
"aggregations" : {
"max_deaths" : {
"value" : 561142.0
}
}
GET covid/_search
{
"size": 0,
"aggs": {
"all_stats": {
"stats": { #A stats query returns all five core metrics in one go
"field": "deaths"
}
}
}
}
结果:
"aggregations" : {
"all_stats" : {
"count" : 20,
"min" : 30772.0,
"max" : 561142.0,
"avg" : 163689.1,
"sum" : 3273782.0
}
}
(2)Bucketing
这类聚合就是实现数据分组展示。
GET covid/_search
{
"size": 0,
"aggs": {
"critical_patients_as_histogram": {
"histogram": {
"field": "critical",
"interval": 2500
}
}
}
}
结果为
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"critical_patients_as_histogram" : {
"buckets" : [
{
"key" : 0.0,
"doc_count" : 4
},
{
"key" : 2500.0,
"doc_count" : 3
},
{
"key" : 5000.0,
"doc_count" : 0
},
{
"key" : 7500.0,
"doc_count" : 3
}
]
}
}
}
GET covid/_search
{
"size": 0,
"aggs": {
"range_countries": {
"range": {
"field": "deaths",
"ranges": [
{"to": 60000},
{"from": 60000,"to": 70000},
{"from": 70000,"to": 80000},
{"from": 80000,"to": 120000}
]
}
}
}
}
结果:
"aggregations" : {
"range_countries" : {
"buckets" : [
{
"key" : "*-60000.0",
"to" : 60000.0,
"doc_count" : 1
},
{
"key" : "60000.0-70000.0",
"from" : 60000.0,
"to" : 70000.0,
"doc_count" : 0
},
{
"key" : "70000.0-80000.0",
"from" : 70000.0,
"to" : 80000.0,
"doc_count" : 2
},
{
"key" : "80000.0-120000.0",
"from" : 80000.0,
"to" : 120000.0,
"doc_count" : 3
}
]
}
}
累了,毁灭吧😎
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/98043.html

