
1. Redis主从架构
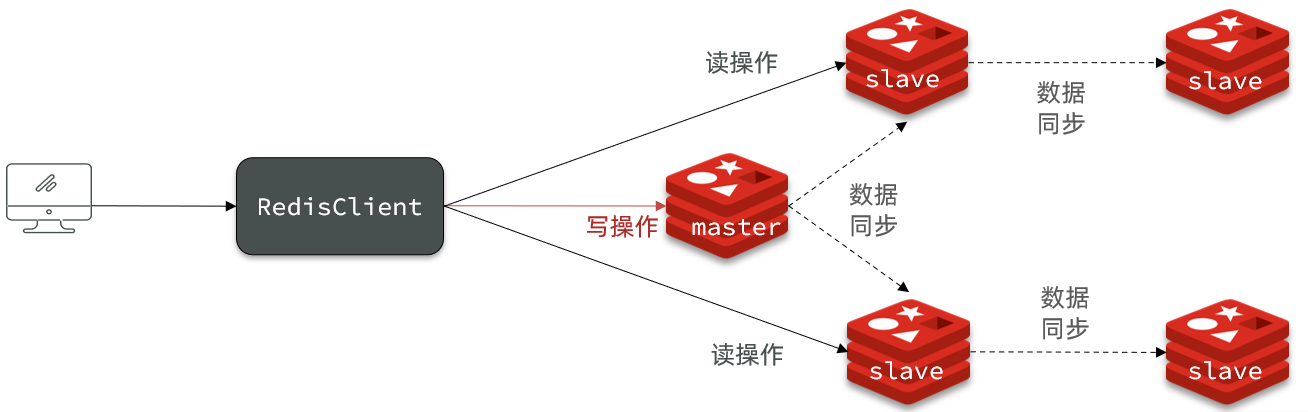
众所周知,单节点Redis的并发能力是有上线的,就像单节点的MySQL一样,要想进一步提高并发能力,就需要搭建主从集群,从而实现读写分离,进而提高并发能力。
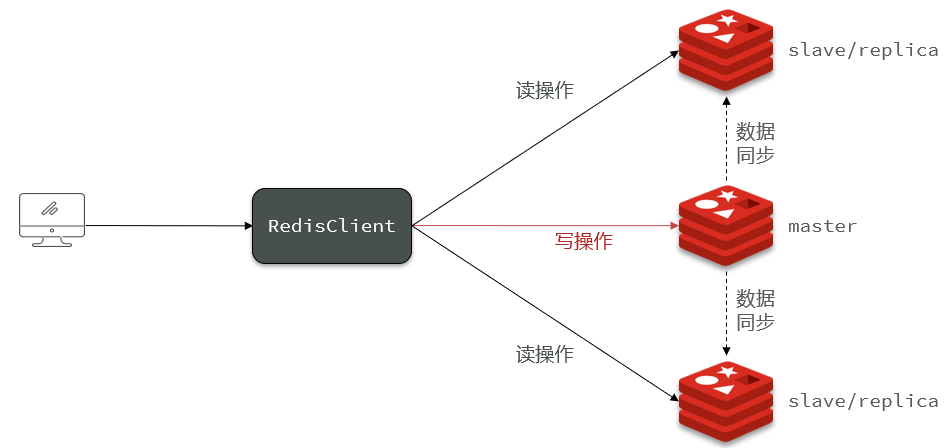
1.1 Redis主从集群的搭建
接下来会根据上图搭建一个Redis主从集群,该集群包含三个节点,一个主节点,两个从节点。
使用虚拟机开启3个Redis实例,模拟主从集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | slave |
| 192.168.150.101 | 7003 | slave |
注意:搭建Redis主从集群需要将持久化模式改为默认的RDB模式,AOF保持关闭状态
# 开启RDB
# save ""
save 3600 1
save 300 100
save 60 10000
# 关闭AOF
appendonly no
准备好3个Redis实例之后,就需要开始配置主从了。
配置主从有临时和永久两种模式:
-
修改配置文件(永久生效)
- 在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
- 在redis.conf中添加一行配置:
-
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>
注意:在5.0以后新增命令replicaof,与salveof效果一致。
这里就使用第二种
接着分别连接7002、7003两台
# 执行slaveof
slaveof 192.168.150.101 7001
# 执行slaveof
slaveof 192.168.150.101 7001
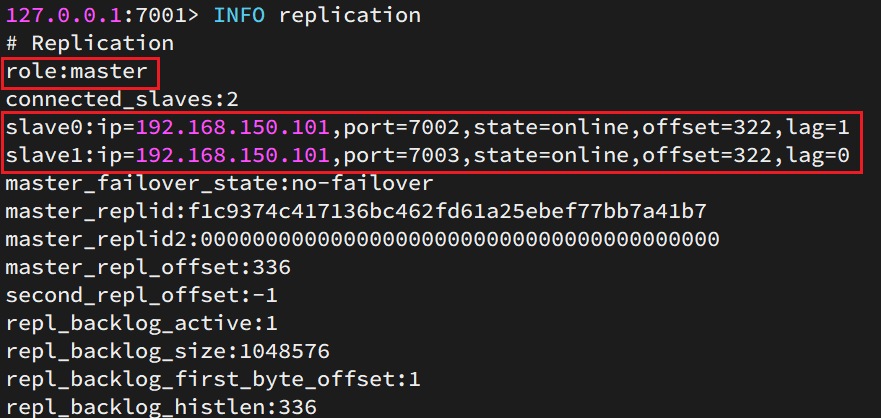
配置完成之后,就可以查看集群状态了
然后连接 7001节点,查看集群状态:
# 连接 7001
redis-cli -p 7001
# 查看状态
info replication
结果:
搭建完Redis主从集群之后执行下列操作以测试:
-
利用redis-cli连接7001,执行
set num 123 -
利用redis-cli连接7002,执行
get num,再执行set num 666 -
利用redis-cli连接7003,执行
get num,再执行set num 888
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。
2. Redis主从数据同步
Redis主从数据同步主要分两种:
- 全量同步
- 增量同步
2.1 全量同步
当主从第一次建立连接的时候,便会执行全量同步,将master节点的所有数据都拷贝给slave节点
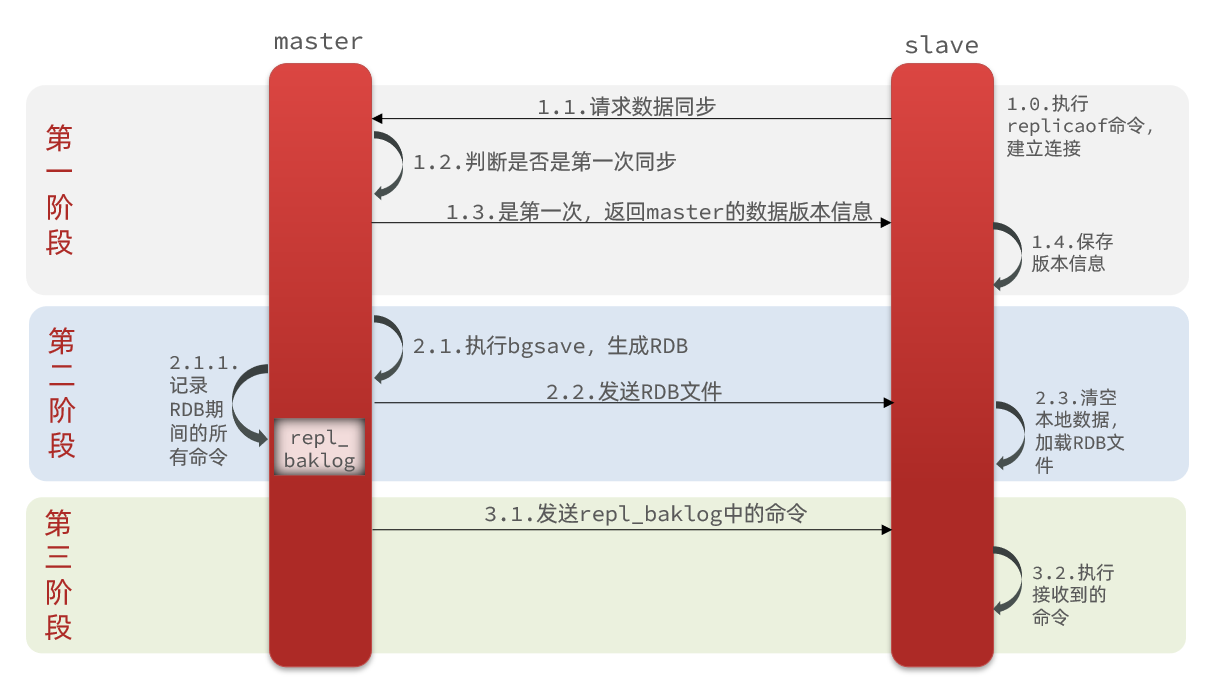
slave第一次与master建立连接的时候,slave会像master请求数据同步
master接收到请求之后,会先判断是否第一次同步
如果是第一次,则会返回master的数据版本信息给slave。
接着slave会保存master返回的数据版本信息。
接下来,master执行bgsave命令,生成RDB文件,在后台执行,没有占用主线程,接着将生成的RDB文件发送给slave。
slave此时会清空本地数据,加载master传来的RDB文件。
当master执行bgsave命令的时候,如果这是对master有操作,会将命令记录保留在一个repl_baklog的缓冲区中。
master会发送repl_baklog中的命令发送给salve,slave会执行接收到的命令。
这样,master和salve之间就实现了数据同步。、
master如何得知salve是第一次来连接呢??
知识点引入:
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集**。每一个master都有唯一的replid**,slave则会继承master节点的replid
- offset:偏移量**,随着记录在repl_baklog中的数据增多而逐渐增大**。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
slave原本是一个master,有属于自己的replid和offset,当第一次变成slave与master建立连接的时候,发送的是原本自己的replid和offset。
master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。
master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。

2.2 增量同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步。
那么增量同步是什么呢?
增量同步就是只更新slave与master存在差异的部分数据
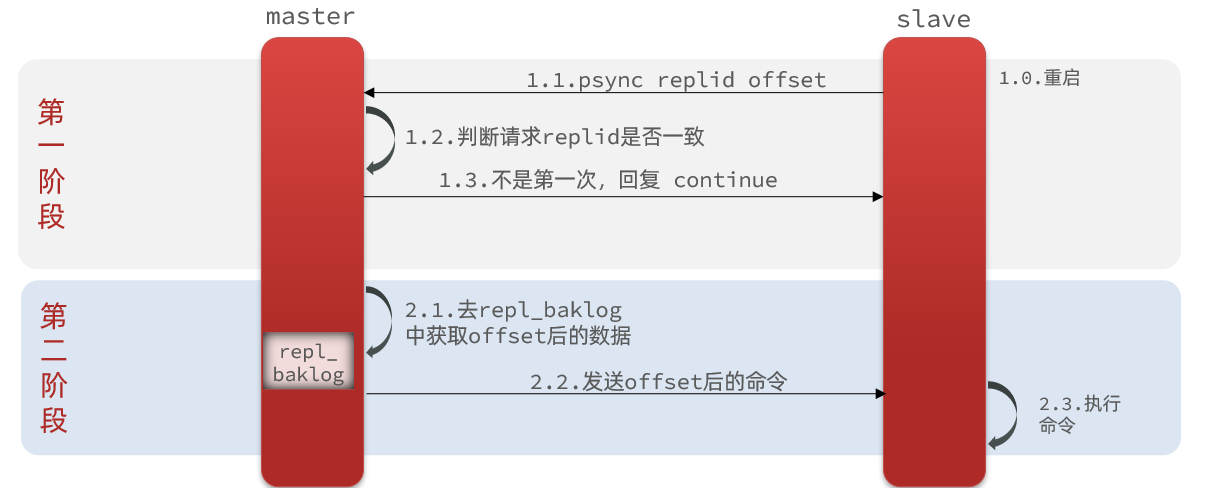
master怎么知道slave与自己的数据差异在哪里呢?
这里就需要引入全量同步时提到的repl_baklog文件了。
这个文件是一个固定大小的数组,只是这个数组是一个环形数组。也就是该数据首尾相连,当角标到达数据末尾的时候,会再次从0开始读写覆盖原来的数据
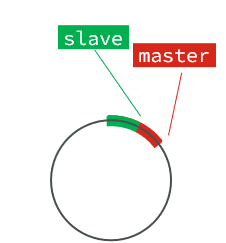
但是会出现这样的清空,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset:
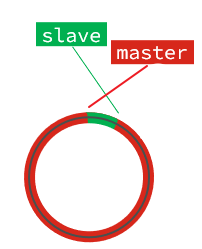
如果master继续写入新数据,其offset就会覆盖旧的数据,直到将slave现在的offset也覆盖:
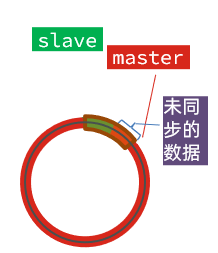
棕色框中的红色部分,就是尚未同步,但是却已经被覆盖的数据。此时如果slave恢复,需要同步,却发现自己的offset都没有了,无法完成增量同步了。只能做全量同步。
repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。
3. Redis主从同步优化
主从同步可以保证主从数据的一致性,非常重要。
可以从以下几个方面来优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- 这种只适应于网络非常好的情况。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
参考:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/94964.html

