
目录
一、XML简介
XML(EXtensible Markup Language):可扩展标记语言,是一种很像HTML的标记语言。XML 的设计宗旨是传输数据,而不是显示数据。XML 标签没有被预定义。您需要自行定义标签。XML 是 W3C 的推荐标准。XML与操作系统、编程语言的开发平台无关、规范统一。
XML 和 HTML 之间的差异
XML 和 HTML 为不同的目的而设计:
XML 被设计用来传输和存储数据,其焦点是数据的内容。
HTML 被设计用来显示数据,其焦点是数据的外观。
1、XML声明
XML声明:用以表明该文件是一个XML文档
语法:
<?xml version="1.0" encoding="UTF-8"?>
XML声明的组成部分:
version:文档符合XML1.0规范
encoding:文档字符编号,默认为”UTF-8”
对于任何一个XML文档,其声明部分都是固定的格式
XML标签:用<>括起来的各种标签来标记数据,并且要成对出现
语法:
<标签名>标签描述的内容</标签名>
<author>明日科技</author>
标签名是自己命名的,要见名知意,任何一个XML文件可以包含任意数量的标签
2、XML元素
元素由开始标签、元素内容和标签组成。元素内容可以包含子元素、字符数据等。
语法:
<元素名 属性名=“属性值”>元素内容</元素名>
实例:
<book id="101">
<author>明日科技</author>
<title>Java从入门到精通</title>
<description>零基础入门,适合自学</description>
</book>
3、XML根元素
每个XML文档有且只有一个根元素
根元素特点:
1、根元素是一个完全包括文档中其他所有元素的元素。
2、根元素的开始标签要放在所有其他元素的开始标签之前。
3、根元素的结束标签要放在所有其他元素的结束标签之后。
4、MXL属性
1、一个元素可以有多个属性,多个属性之间用空格隔开
2、属性只能放在开始标签中。
3、属性值用双引号包括,属性值中不能直接包含<,>,”,&
语法:
<元素名 属性名=“属性值” 属性名=“属性值” >元素内容</元素名>
实例:
<book id="101">
<author>明日科技</author>
<title>Java从入门到精通</title>
<description>零基础入门,适合自学</description>
</book>
5、XML中特殊字符处理
XML文档中,有时在元素的文本中会出现一些特殊的字符(如<、>、’、”、&),为了正确的解析这些特殊字符内容,可以使用转义符和CDATA节。
| 符号 | 转义符 |
| < | < |
| > | > |
| “ | " |
| ‘ | &apos |
| & | & |
当元素中出现很多特殊字符时,可以使用CDATA节,如:
<description>
<![CDATA[讲解了元素<title>以及</title>的使用]]>
</description>
6、XML格式:
1、必须有XML声明语句。
2、必须有且只有一个根元素。
3、XML标签对大小写敏感。
4、XML标签成对出现。
5、XML元素正确的嵌套。
6、元素名称可以包含字母、数字或其他的字符。
7、元素名称不能以数字或者标点符号开始。
8、元素名称中不能含空格。
XML的命名空间:
XML解析器在解析XML文档时,对于重名的元素,可能出现解析冲突。
命名空间的作用:命名空间有助于标准化元素和属性,并为它们加上唯一的标识,提供避免元素命名冲突的方法。
语法:
xmlns:[prefix]=“[命名空间的URI]”
实例:
<?xml version="1.0" encoding="UTF-8"?>
<cameras xmlns:canon="http://www.canon"
xmlns:nikon="http://www.nikon.com">
<canon:camera prodID="P663" name="Camera傻瓜相机"/>
<nikon:camera prodID=“K29B3” name=“Camera超级35毫米相机"/>
</cameras>
XML实例:
<?xml version="1.0" encoding="UTF-8"?><books>
<book id="101">
<author>李刚</author>
<title>Java从入门到精通</title>
<description>零基础入门,适合自学</description>
</book>
<book id="102">
<author>关东升</author>
<title>Java从小白到大牛</title>
<description>Oracle公司官方推荐用书</description>
</book>二、XML的解析
四种常见的XML解析技术
DOM解析:基于XML树结构、比较耗资源、适用于多次访问XML
SAX解析:基于事件、消耗资源小、适用于数据量较大的XML
JDOM解析:比DOM更快、JDOM仅使用具体类而不使用接口
DOM4J解析:非常优秀的Java XML API、性能优异、功能强大、开放源代码
本文主要写DOM解析和DOM4J解析:
1、DOM介绍
DOM是Document Object Model即文档对象模型的简称。DOM把XML文档映射成一个倒挂的树。
DOM可以把XML模型表示出来,例如:
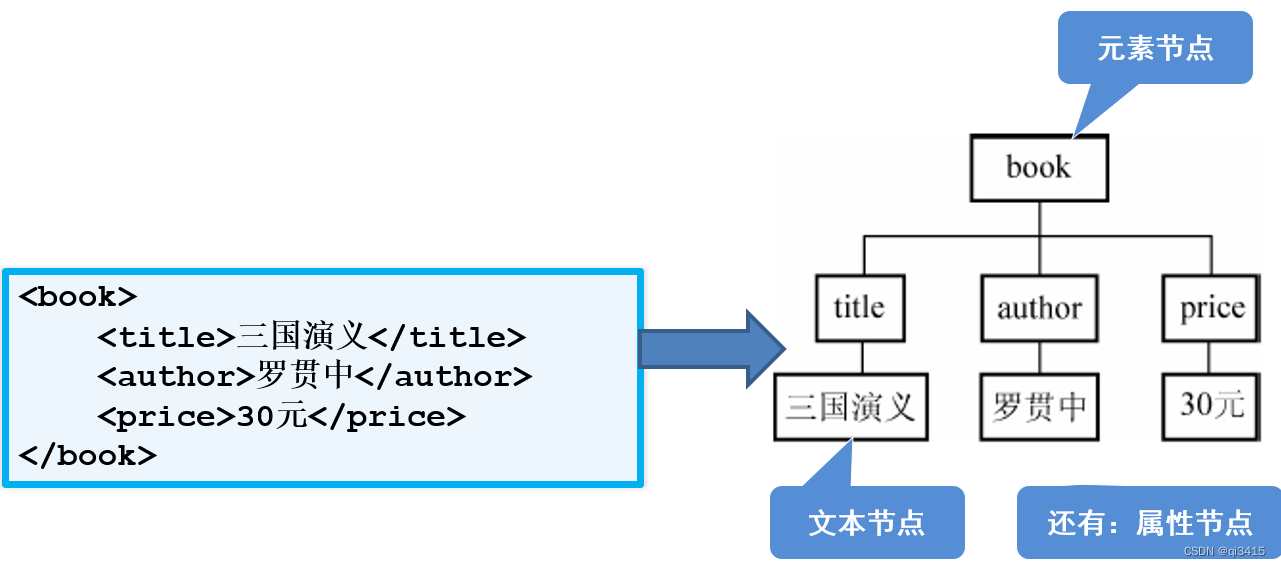

DOM解析XML:
甲骨文公司提供了JAXP(Java API for XML Processing)来解析XML。
JAXP会把XML文档转换成一个DOM树。
JAXP包含3个包,这3个包都在JDK中:
org.w3c.dom:W3C推荐的用于使用DOM解析XML文档的接口。
org.xml.sax:用于使用SAX解析XML文档的接口。
javax.xml.parsers:解析器工厂工具,程序员获得并配置特殊的解析器。
2、org.w3c.dom包中的常用接口
Document接口:Document对象代表整个XML文档,它也是对XML文档进行操作的起点。Document接口继承自Node接口
| 常用方法 | 方法说明 |
|
Element createElement(String tagName) |
创建指定标记名称的元素。 |
|
Element getDocumentElement() |
获取代表XML文档根元素的对象。 |
|
NodeList getElementsByTagName(String tagName) |
按文档顺序返回文档中指定标记名称的所有元素集合 |
Node接口:表示树中的一个抽象节点。
| 常用方法 | 方法说明 |
|
Node appendChild(Node newChild) |
将节点 newChild 添加到此节点的子节点列表的末尾。 |
|
NodeList getChildNodes() |
获取该元素的所有子节点,返回节点的列表。 |
|
Node getFirstChild() |
此节点的第一个子节点。 |
|
Node getLastChild() |
此节点的最后一个节点。 |
|
Node getParentNode() |
此节点的父节点。 |
|
String getNodeName() |
获取节点的名称。 |
|
String getTextContent() |
此属性返回此节点及其后代的文本内容。 |
|
Node removeChild(Node newChild) |
从子节点列表中移除 oldChild 所指示的子节点,并将其返回。 |
NodeList接口:包含了一个或者多个节点的列表。
| 常用方法 | 方法说明 |
|
int getLength (String tagName) |
返回列表的长度。 |
|
Node item(int index) |
返回集合中的第 index 个项。如果 index 大于或等于此列表中的节点数,则返回 null。 |
Element接口:代表XML文档中的标签元素。
Element接口继承自Node,也是Node最主要的子对象。在标签中可以包含属性。
| 常用方法 | 方法说明 |
|
String getAttribute(String name) |
通过名称获得属性值。 |
|
Attr getAttributeNode(String name) |
通过名称获得属性节点。 |
|
NodeList getElementsByTagName(String tagName) |
以文档顺序返回具有给定标记名称的所有后代 Elements 的 NodeList。 |
|
void setAttribute(String name, String value) |
添加一个新属性 |
3、DOM读取XML的步骤
1.创建解析器工厂对象(DocumentBuilderFactory)。
2.由解析器工厂对象创建解析器对象(DocumentBuilder)。
3.由解析器对象对指定XML文件进行解析,构建相应DOM树,创建Document对象。
4.以Document对象为起点对DOM树的节点进行增删改查操作使用
4、读取DOM树
public void show(){
Document document = null;
//创建解析器工厂实例
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
//从解析器工程获取解析器实例
DocumentBuilder builder = factory.newDocumentBuilder();
//解析XML文件,创建Document对象,得到DOM树
document = builder.parse("E:\\javapj\\advanced\\books.xml");
//得到所有Book节点信息
NodeList bookList = document.getElementsByTagName("book");
//遍历所有book节点
for (int i = 0; i < bookList.getLength(); i++) {
//获取第i个book元素信息
Node bookNode = bookList.item(i);
//获取第i个book节点的id属性
Element bookEle = (Element) bookNode;
String bookStr = bookEle.getAttribute("id");
//打印输出
System.out.println("id:" + bookStr);
//获取所有book的子标签
NodeList childList = bookNode.getChildNodes();
String nodeName = "";
//对所有节点的子节点循环遍历
for (int j = 0; j < childList.getLength(); j++) {
//获取第j个子节点元素信息
Node childNode = childList.item(j);
//如果当前Node是Element,则进行转换
if (childNode.getNodeType() == Node.ELEMENT_NODE){
Element childEle = (Element)childNode;
//获取子节点的属性
String childName = childEle.getAttribute("name");
//获取子节点的内容
nodeName = childNode.getTextContent();
System.out.println( childName + "\t" + nodeName);
}
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
}5、保存XML文件
public void saveXML(String path){
//创建一个转换工厂
TransformerFactory factory = TransformerFactory.newInstance();
try {
//使用转换工程创建一个转换器
Transformer former = factory.newTransformer();
//进行转换,DOM树-----》XML文件
Source xmlSource = new DOMSource(document);
//path为文件地址
Result outPutTarget = new StreamResult(path);
former.transform(xmlSource,outPutTarget);
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
}
}6、DOM树添加信息
public void addBook(){
//创建一个book节点
Element newBook = document.createElement("book");
//添加节点属性
newBook.setAttribute("id","004");
//创建子节点
Element newauthor = document.createElement("author");
//对子节点添加属性
newauthor.setAttribute("name","刘慈欣");
//添加内容
newauthor.setTextContent("女");
//创建子节点
Element newtitle = document.createElement("title");
newtitle.setTextContent("三体");
//将子节点连接到节点处
newBook.appendChild(newauthor);
newBook.appendChild(newtitle);
//将newBook挂到DOM树上
document.getElementsByTagName("book").item(0).appendChild(newBook);
}7、DOM树修改信息
public void revise(){
//找到book节点
NodeList bookList = document.getElementsByTagName("book");
//对book节点循环遍历
for (int i = 0; i < bookList.getLength(); i++) {
Node bookNode = bookList.item(i);
Element bookElement = (Element) bookNode;
if (bookElement.getAttribute("id").equals("101")){
//修改节点的name属性值
bookElement.setAttribute("id","111");
}
//获取所有book的子标签
NodeList childList = bookNode.getChildNodes();
//获取子节点的id
int id = Integer.parseInt(bookElement.getAttribute("id"));
if (id == 111){
//对子节点循环遍历
for (int j = 0; j < childList.getLength(); j++) {
Node childNode = childList.item(j);
//对子节点的内容进行修改
if ("author".equals(childNode.getNodeName())){
childNode.setTextContent("女");
}
}
}
}
}8、DOM树删除信息
public void delete() {
//找到book节点
NodeList bookList = document.getElementsByTagName("book");
//对book节点循环遍历
for (int i = 0; i < bookList.getLength(); i++) {
Node bookNode = bookList.item(i);
Element bookElement = (Element) bookNode;
//获取子节点的id
int id = Integer.parseInt(bookElement.getAttribute("id"));
if (id==102){
//删除id为102的节点
document.getDocumentElement().removeChild(bookElement);
}
}
}DOM4J
DOM4J是 dom4j.org 出品的一个开源 XML 解析包。
Dom4J是一个易用的、开源的库,用于XML,XPath和XSLT。它应用于Java平台,采用了Java集合框架并完全支持DOM,SAX和JAXP。
1、DOM4j的常用接口
DOM4J的常用接口都在org.dom4j包里定义。
| 接口 | 说明 |
|
Attribute |
定义了 XML 的属性。 |
|
Document |
定义了XML 文档。 |
|
Element |
定义了XML 元素 |
|
Node |
为DOM4J中所有的XML节点定义了多态行为 |
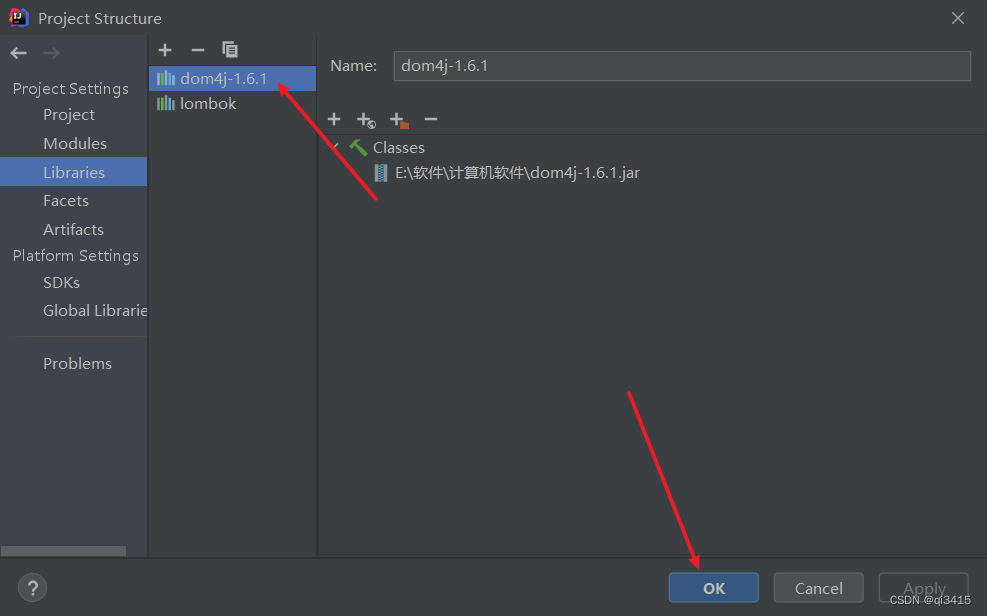
2、DOM4J的安装
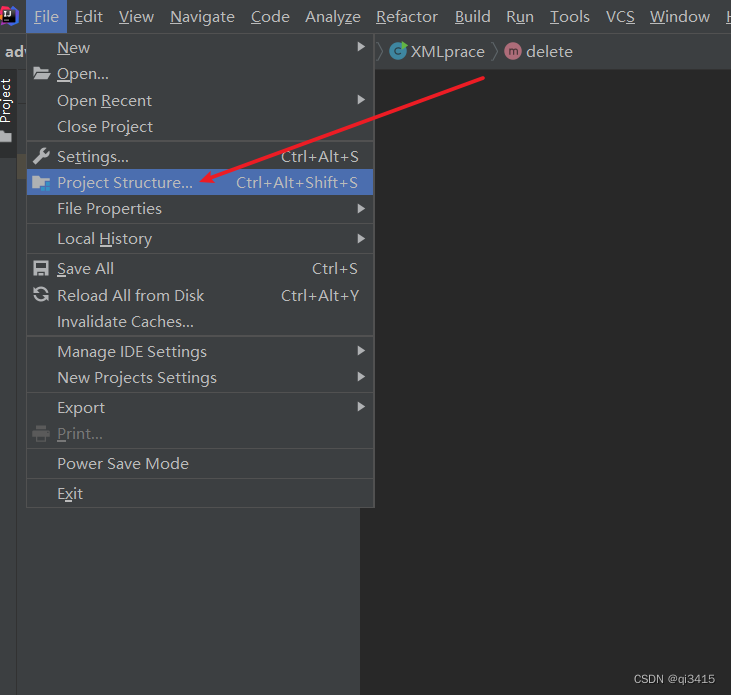
首先下载Dom4J
1、点击file选择ProjectStructure
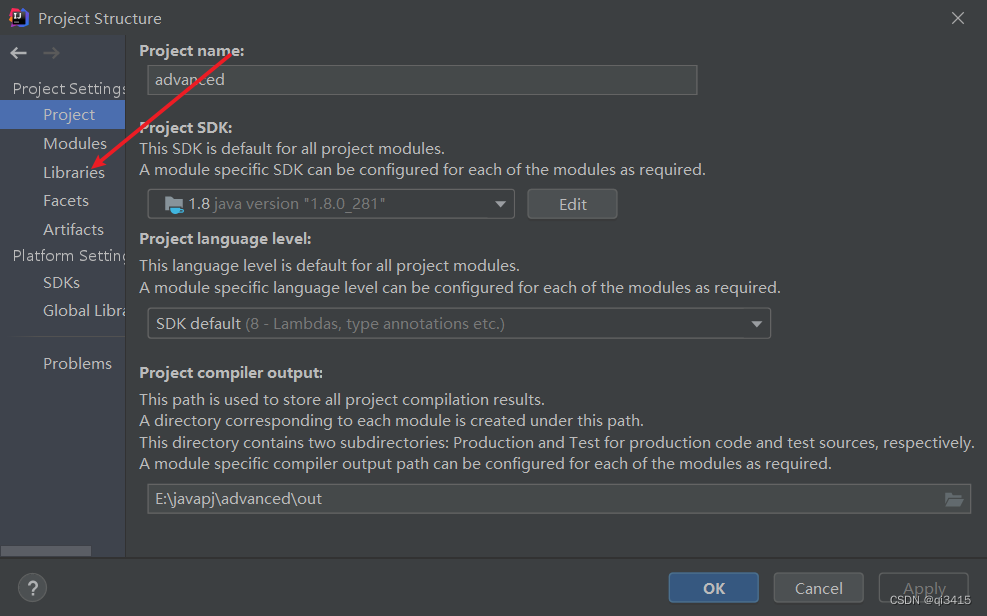
2、点击Libraries
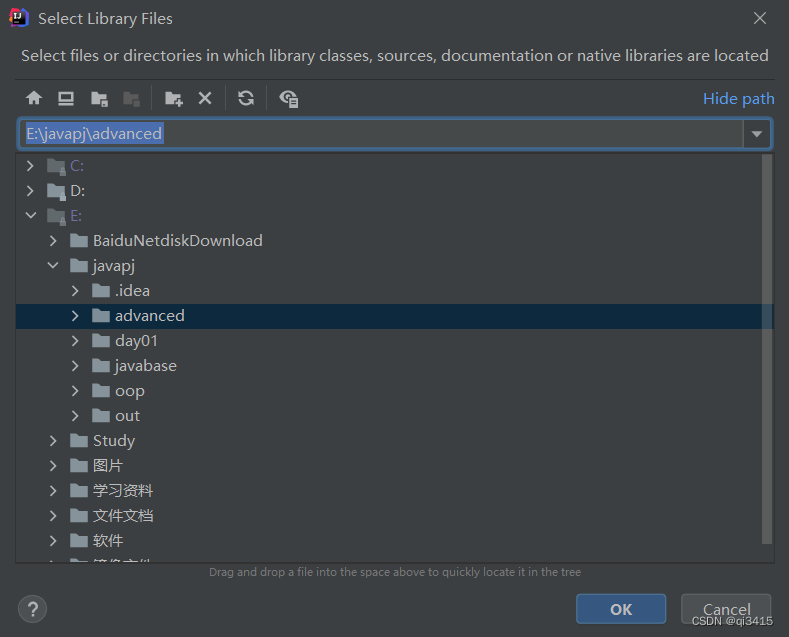
3、先点击+,然后选择java

4、找到下好的DOM4J文件目录点击ok
5、点击ok
3、DOM4J对XMl文件的操作
加载DOM树信息
public class Dom4j {
Document document = null;
//加载DOM树信息
public void LoadDom(){
SAXReader saxReader = new SAXReader();
try {
document = saxReader.read("E:\\javapj\\advanced\\books.xml");
} catch (DocumentException e) {
e.printStackTrace();
}
}显示XML信息
public void show(){
//获取DOM树根节点
Element root = document.getRootElement();
Iterator itBook = root.elementIterator();
//遍历迭代器,itBook.hasNext()判断是否有下一个元素
while (itBook.hasNext()){
//获取根节点
Element bookEle = (Element) itBook.next();
//获取根节点属性
String bookStr = bookEle.attributeValue("id");
//使用迭代器获取子节点
Iterator childIt = bookEle.elementIterator();
System.out.println(bookStr);
//遍历迭代器,childIt.hasNext()判断是否有下一个元素
while (childIt.hasNext()){
//获取子节点
Element authorEle = (Element) childIt.next();
//获取子节点属性
String authorStr = authorEle.attributeValue("name");
//获取子节点内容
String author = authorEle.getText();
System.out.println(authorStr + "\t" + author);
}
}
}保存XML文件
public void saveXML(String path){
//创建格式化器
OutputFormat format = OutputFormat.createPrettyPrint();
//指定编码格式
format.setEncoding("utf-8");
try {
//指定XML文件的保存路径,new FileWrite字符流 path为路径
XMLWriter writer = new XMLWriter(new FileWriter(path),format);
writer.write(document);
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}DOM树添加节点
public void addbook(){
//获取根节点
Element root = document.getRootElement();
//创建一个book节点
Element bookEle = root.addElement("book");
//给book节点设置属性
bookEle.addAttribute("id","006");
//创建子节点
Element authorEle = bookEle.addElement("author");
//给子节点节点设置属性
authorEle.addAttribute("name","李白");
//给子节点添加内容
authorEle.addText("蜀道难");
this.saveXML("新的数据.xml");
}DOM树修改节点
public void revise(){
//获取根节点
Element root = document.getRootElement();
int id = 0;
使用迭代器获根节点
Iterator itbook = root.elementIterator();
//遍历根节点
while (itbook.hasNext()){
id++;
Element bookEle = (Element) itbook.next();
//对根节点属性进行修改
bookEle.addAttribute("id",id + "");
}
}DOM树删除节点
public void delete(){
//获取根节点
Element root = document.getRootElement();
//使用迭代器获根节点
Iterator itbook = root.elementIterator();
//遍历根节点
while (itbook.hasNext()){
Element bookEle = (Element) itbook.next();
//找到id为1的节点
if (bookEle.attributeValue("id").equals("1")){
//删除节点
bookEle.getParent().remove(bookEle);
}
}
}版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/93370.html

