
MySQL表的增删改查(进阶)
CRUD中的增删改,讲到 上一篇博客 ,其实就差不多完了。
真正复杂的是查询!!!
一、数据库约束
关系型数据库的一个重要功能就是需要保证数据的“完整性”,即正确的数据。
可以通过人工的方式来观察确认数据的正确性,但是不合适!可能会因为人的疏忽,没把一些错误检查出来。
而约束,就是让数据库帮助程序猿更好地检查数据是否正确!
1.1 约束类型
| 类型 | 说明 |
|---|---|
| not null | 指示某列不能存储 NULL 值 |
| unique | 保证某列的每行必须有唯一的值(不能重复) |
| default | 规定没有给列赋值时的默认值 |
| primary key | not null 和 unique 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录 |
| foreign key | 保证一个表中的数据匹配另一个表中的值的参照完整性 |
| check | 保证列中的值符合指定的条件。对于MySQL数据库,对check子句进行分析,但是忽略check子句 |
补充:
- 允许为null:选填项;不允许为null:必填项。
- primary key:主键,非常重要的约束!每条记录的身份标识~
- foreign key:多个表的关联关系,要求某个记录必须在另外一个表里存在。
- check:显式通过条件来描述字段的取值(MySQL 5 不支持check)
1.2 not null 约束
create table student (id int not null,name varchar(20));
desc student;:


此时id不允许为空,不能插入null。
1.3 unique:唯一约束
create table student (id int unique,name varchar(20));
desc student;:
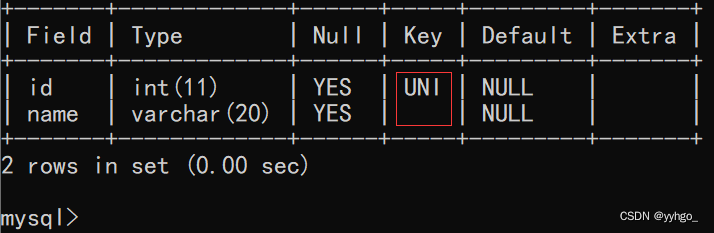
此时不可以插入两个相同的id。否则报错:

Duplicate是“重复的”的意思,entry一般有两个意思:1.入口 ;2.条目
此处entry显然是条目的意思。(回忆:Java中遍历map可以使用entrySet)
那么数据库是如何判定当前这一条记录是重复的?:先查找,没有再插入。
所以我们发现,加上约束之后,数据库的执行过程可能就变了,很可能执行时间/效率就受到很大影响。但是这里的代价再大,也比手工检查—遍代价小很多,而且准确率也高很多。
1.4 primary key:主键约束
约束是可以组合使用的:
create table student(id int not null unique,name varchar(20));
desc student;:

我们发现,此时id的Key为:PRI,即 primary key
所以,主键约束其实就是not null + unique,既是非空同时又是唯一的。
create table student(id int primary key,name varchar(20));
desc student;:
我们发现,效果与上面一种是相同的,同时具有非空和唯一要求,这就是主键约束。
主键约束也同样是在插入记录的时候,需要先查询,再进行真正的插入。
正因为主键和unique都有先查询的过程,mysql 就会默认给 primary key 和 unique 这样的列自动添加索引,来提高查询的速度。
主键注意:
- 实际开发中,大部分的表一般都会带有一个主键。主键往往是一个整数表示的id。
- 在mysql中,一个表里只能有一个主键,不能有多个,否则报错:

“多个主键被定义” - 虽然主键不能有多个,mysql允许把多个列放到一起共同作为一个主键(联合主键)。
- 主键另外一个非常常用的用法就是,使用mysql自带的 “自增主键” 作为主键的值。
主键需要保证不重复,如果全靠程序猿自己生成一些不重复的主键值就比较麻烦,所以才需要“自增主键”:
create table student (id int primary key auto_increment,name varchar(20));
desc student;:

此时插入 id 的时候,可以手动指定,也可以不手动指定(null),则会由mysql自动生成:
insert into student values (null,'张三');
insert into student values (null,'张三');
insert into student values (null,'张三');
哎?前面不是刚说主键不能设置为空null吗?
注意,我们这里写null的意思不是插入一个空值,而是交给数据库使用自增主键!
所以当我们去查询的时候可以看到:
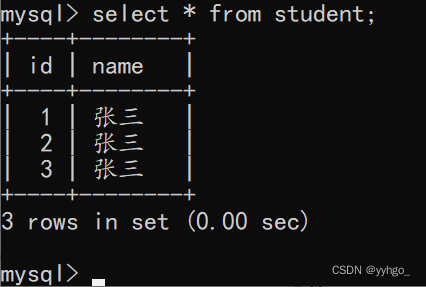
这里的“1”就是自增主键来去自动生成的。
每次插入数据的时候,mysql就会自动找到上一条记录的 id,在这个基础之上进行自增。
当然我们也可以自己设置 id:
insert into student values (100,'李四');
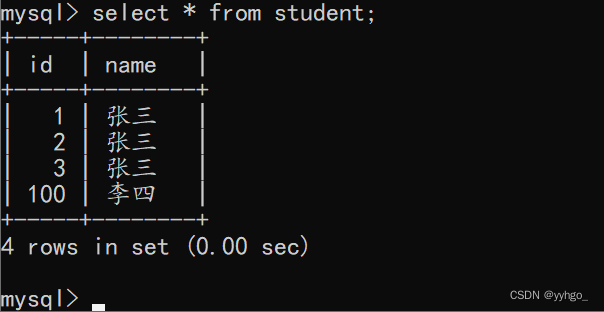
如果此时再使用“自增主键”呢?
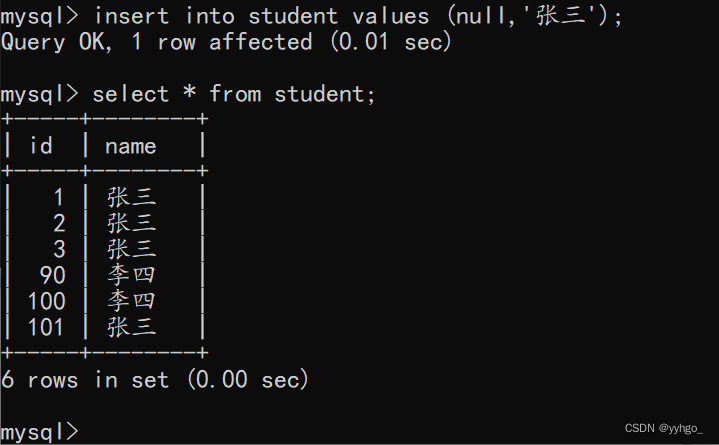
新增的id为“101”!
所以我们要注意:自增主键并不会利用中间的空隙,而是依照之前的最大值,来往后累加的。因为这样做是最快的,不然还得去查找中间哪些id是空闲的,没有必要。
有人会有疑问:这样做不就浪费了很多id吗?格局要大一点!当前int类型,可以支持的范围是-21亿 -> +21亿。所以即使你浪费了很多,剩余的空间还是很大的,问题不大~
有过这样一个面试题:如果自增的id超过231之后该怎么办?
mysql的数据量比较小时,所有的数据都在一个mysql服务器上,此时“自增主键”是可以很好地工作的。
但如果mysql的数据量很大,一台主机放不下时,就需要进行分库分表,使用多个主机来进行存储。
本质上就是把一张大表分成两个/多个小的表,每个数据库服务器,分别只存一部分数据。
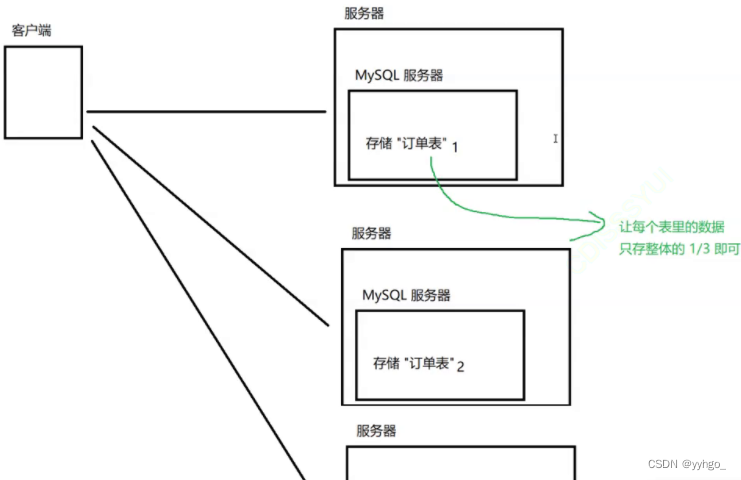
在这个场景下,如果再新插入一个数据,这个数据就会落在三个服务器之一。那么新的这个数据的主键id,如何分配?能否继续使用mysql自带的“自增主键”呢?(三个服务器上的数据的id是都不能重复的)
这就涉及到一个“分布式系统中唯一id生成算法”,业界有很多具体的实现,并不是统一的。
实现公式:时间戳 结合 主机编号 结合 随机因子,结合这三个部分,就可以得到一个全局唯一的id。
1.5 default:默认值约束
create table student(name varchar(50),age int default '无名氏');
desc student;:

此时若不给name值,默认为“无名氏”:

1.6 foreign key:外键约束
外键约束是针对两个表之间,产生的约束。
create table class(id int,name varchar(20));
create table student(id int,name varchar(20),classId int);
insert into class values(1,'java1'),(2,'java2'),(3,'java3');
insert into student values (1,'张三',1),(2,'李四',2);
两个表:
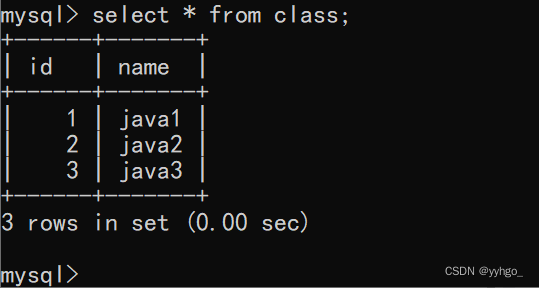
此时两个表之间还没有“外键约束”,插入classId为100的学生(非法数据)也不会报错,但事实上非法数据不应该可以插入。
为了让mysql帮我们自动完成上述检查工作,就引入了“外键约束”。
接下来我们重新创建表:
create table class(id int primary key,name varchar(20));
create table student (id int primary key,name varchar(20),classId int,foreign key (classId) references class(id));
desc student;:
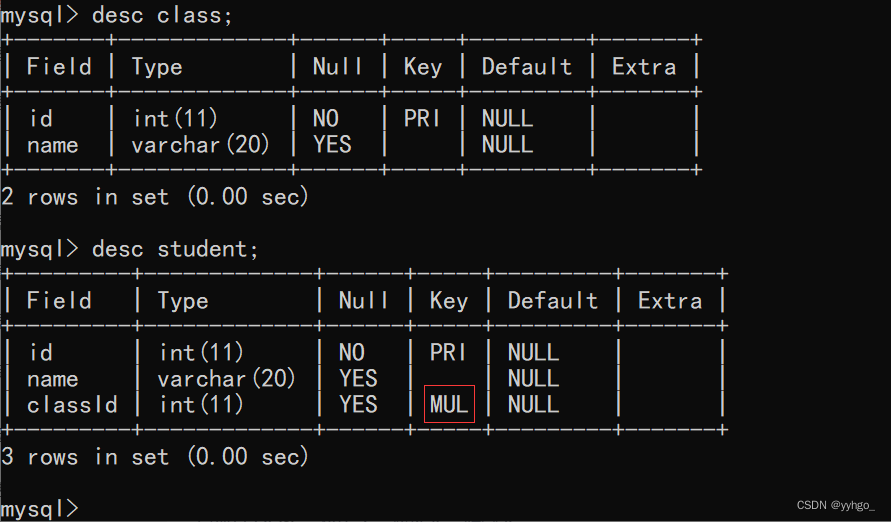
此时两个表之间的相互约束,就称为“外键约束”。(MUL)
此处外键约束的含义,就是要求student里的classld务必要在class表的id列中存在!
这时如果往student表中插入或者修改一个不存在的classId,就会报错:

报错信息中的“child”可以这样理解:child对应parent。学生表中的数据要依赖班级表的数据,班级表的数据要对学生表产生约束力(父亲对孩子有约束力),此处起到约束作用的班级表就叫做“父表”(parent),被约束的这个表就叫做“子表”(child)。
表面上看,父表对子表有约束。实际上,子表也在反过来约束了父表!:
insert into class values(1,'java1');
insert into student values (1,'张三',1);
delete from class where id = 1;
删除或者修改时可能会报错:

而若删除id为2的class(假设“2班”没有student),则一切正常!
分析:id为1,被子表给引用了,如果删除成功,子表的数据不就僵住了嘛;id为2,没有被引用,可以删掉~
同理,直接删除表当然也不可行!(删库可以哈哈哈哈~)
所以,如果想顺利删除,那就需要先删除子表,再删除父表!
还有一个问题,如果我们这样创建:
create table class(id int,name varchar(20));
create table student (id int primary key,name varchar(20),classId int,foreign key (classId) references class(id));
结果:

为什么报错了呢?
通过对比发现,这次我们两个表都没有设置主键!那么是哪个主键的问题呢?
经过试验,我们发现原因是父表主键没有设置(或者给一个unique约束)。
分析:
- 每次给子表插入数据时,势必要在父表中查询一下,看看这个id是否存在。默认情况下查询是需要遍历表的,在表非常大的时候,遍历效率非常低!为了提高效率:使用索引~所以必须要有主键!
- 保证子表外键引用的唯一性!
总结:要想创建外键,就要求父表的对应的列,得有primary key或者unique约束!
可以相互设置外键吗?当然不行~创建外键约束时,必然是先创建父表,后创建子表。如果先创建子表了,父表还没有呢,肯定就报错了。
考虑一个场景:
电商。有一个商品表,商品表里面有很多的商品信息;还有一个订单表,订单表里带有商品id这一列。订单中的商品id必然要在商品表中存在。假如T恤这个商品已经有很多订单了,现在需要把T恤这个商品给下架,怎么办?
分析:直接删除商品信息显然不合适,这时我们可以再多添加一个字段:“是否下架”,这样做就可以避免触发外键约束的限制了~ 这种叫作“逻辑删除”。
有人可能会问了:如果搞这种“逻辑删除”,意味着商品表里的数据就会越来越多,占用的空间就越来越大啊?实际上,硬盘空间是不值钱的!充钱就可以解锁海量的硬盘空间~
二、表的设计
表的设计/数据库的设计要做的工作,就是明确一个程序里,需要使用几个数据库,几个表,表里都有哪些列。
设计表/数据库基本思路:
- 先明确实体;
- 再明确实体之间的关系;
- 根据上述内容,套入到固定的“公式”中,然后表就出来了。
注意:
- “实体”和以前谈到的“对象”是类似的,即需求中的“关键的名词/概念”。
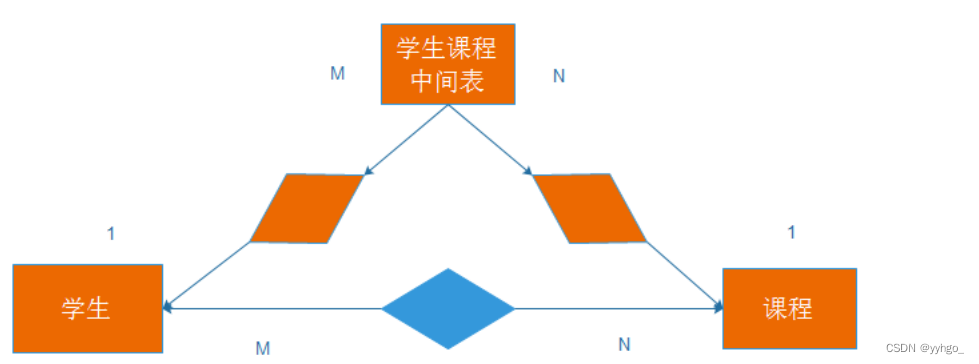
- 关系是固定的套路:1.一对一;2.一对多;3.多对多;4.没有关系。
一对一:(一个人只有一个身份证;一个身份证也只对应一个人)

一对多:(一个学生只能在一个班级里;一个班级里会有多个学生)

多对多:(一个学生可以有多个课程;一个课程也可以被多个学生选择)
三、插入查询结果(新增)
先创建两个学生表,student1和student2:
insert into student2 select * from student;
使用前提:要求查询结果临时表的列数和列的类型,要和student2完全匹配。
前面讲过的所有针对select的规则都是可以使用的~
四、查询
4.1 聚合查询
本质上是在针对行和行之间进行运算。
4.1.1 聚合函数
SQL中内置的一组函数。
| 函数 | 说明 |
|---|---|
| count([distinct] expr) | 返回查询到的数据的 数量 |
| sum([distinct] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| avg([distinct] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| max([distinct] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| min([distinct] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
这些操作都是针对某个列的所有行来进行运算的。
count:
select count(*) from exam_result;
这个操作就相当于先进行select *,然后针对返回的结果,再进行count运算~求结果集合的行数。
不一定非要写 *,还可以写成任意的列名/表达式:
select count(name) from exam_result;
此时不会计算name中为null值的。
注意: count和后面的“()”之间不能有空格!必须紧挨着。
sum:
求和,即把这一列的所有行进行加和,要求这个列得是数字,不能是字符串/日期!否则会报警告(show warnings; 查看警告)
select sum(chinese) from exam_result;
注意:null不会参与运算!因为之前说过,null和任何数字进行运算结果都是null~
也可以理解为:聚合函数对null作特殊处理了。
avg:
select avg(chinese) from exam_result;
求平均值。同样要求必须是数字!
当然也可以填入一个表达式~ 起别名也没问题。
select avg(chinese+math+english) from exam_result;
max、min:最大值、最小值
select max(chinese),min(chinese) from exam_result;
4.1.2 group by子句
对表中的行进行分组。
不用group by分组的时候,相当于就只有一组,即把所有的行进行聚合。引入group by就可以针对不同的组来分别进行聚合。
我们先给一个场景:一家公司(emp表),有老板、产品经理、程序员、运营、保洁等岗位(role字段),当我们想知道平均工资(salary字段)时,显然分组来求才有意义。这时候,就用到了group by:
select role,avg(salary) from emp group by role;
结果:

相同的role被分到了一组。然后针对每个分组来进行计算。
如果不使用聚合函数的话,group by 并没有什么意义~(得到的结果是每个分组的第一条记录,如果没有order by的话“第一条”也是不确定的,所以无意义)
注意:group by 后也可以跟两个字段,用逗号连接!两个字段都相同时分为一组~
4.1.3 having
这里我们详细讲解一下指定条件的几种情况:
- 分组之前,指定条件,先筛选再分组; 使用where子句
- 分组之后,指定条件,先分组再筛选; 使用having子句
- 分组之前和之后,都指定条件。
分组前指定条件(先筛选再分组):
select role,avg(salary) from emp where name!='张三' group by role;
分组后指定条件(先分组后筛选):
select role,avg(salary) from emp group by role having avg(salary)<100000;
分组之前和之后,都指定条件:
select role,avg(salary) from emp where name!='张三' group by role having role!='老板';
4.2 联合查询
4.2.1 基本语法
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积:
select * from aaa,bbb;
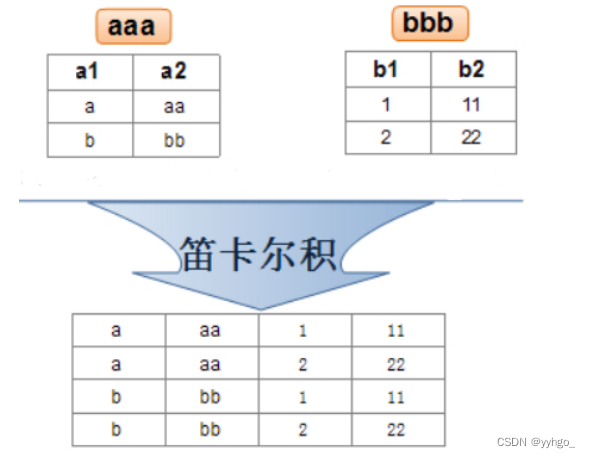
笛卡尔积即是通过排列组合来的,得到一个更大的表:列数就是两个表列数之和,行数就是两个表行数之积。
笛卡尔积里的结果,很多是无效的数据(不符合事实),只有一部分是有意义的~ 因此需要把无意义的数据给去掉。
若有两张表,分别是student和class,每张表都包含一个“classId”字段,经过笛卡尔积后,只有两个classId相同的记录才是有意义的数据!如果我们这样设置条件:
select * from student,class where classId=classId;
这样会报错!classId是含糊不清的。前面加上 表名. (成员访问运算符~,库和表之间也可以)即可解决:
select * from student,class where class.classId=student.classId;
我们把这个用来筛选有效数据的条件,称为连接条件。
或者使用 (inner) join…on 来完成:
select * from student join class on class.classId=student.classId;
实际开发中,多表查询用得一般不会特别多(运行开销比较大,尤其是针对大表)
4.2.2 例题
给出四张表:
drop table if exists classes;
drop table if exists student;
drop table if exists course;
drop table if exists score;
create table classes (id int primary key auto_increment, name varchar(20), `desc` varchar(100));
create table student (id int primary key auto_increment, sn varchar(20), name varchar(20), qq_mail varchar(20) ,
classes_id int);
create table course(id int primary key auto_increment, name varchar(20));
create table score(score decimal(3, 1), student_id int, course_id int);
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),
-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);
(1)查询“许仙”同学的 成绩?

- 先计算笛卡尔积
select * from student,score;
- 加上连接条件
select * from student,score where student.id=score.student_id;
此处不写表名也行,因为当前的id和student_id都是无二义性的。
但是为了代码的可读性,还是把表名给加上比较好~
- 再根据需求,加入必要的条件即可
select * from student,score where student.id=score.student_id and student.name='许仙';
- 把不必要的列去掉,保留想关注的列
select student.name,score.score from student,score where student.id=score.student_id and student.name='许仙';
初学阶段,不要急于一步到位。一步一步写,把大的步骤拆成多个小的步骤~
联合查询还有一种写法,使用 (inner) join…on 来完成:
select * from student join score on student.id=score.student_id and student.name='许仙';
select * from student inner join score on student.id=score.student_id and student.name='许仙';
这种写法看起来没有第一种写法简洁。但是from多个表,只能够实现内连接,而(inner) join on既可以实现内连接也可以实现外连接。
(2)查询所有同学每人的总成绩,及同学的个人信息:

- 先计算笛卡尔积
select * from student,score;
- 加上连接条件
select * from student,score where student.id=score.student_id;
- 加上聚合查询(把同一个同学的行,合并到一个组里,同时进行计算总分)
select name,sum(score.score) from student,score where student.id=score.student_id group by student.name;
(3)查询所有同学的成绩,及同学的个人信息

- 先计算笛卡尔积
select * from student,course,score;
- 加上连接条件
select * from student,course,score where student.id=score.student_id and course.id=score.course_id;
- 针对要求的列进行精简
select student.name as 学生姓名,course.name as 课程名称,score.score from student,course,score where student.id=score.student_id and course.id=score.course_id;
使用 (inner) join…on 来完成:
select student.name as 学生姓名,course.name as 课程名称,score.score from student join score on student.id=score.student_id join course on score.course_id=course.id;
4.2.3 内连接和外连接
内连接和外连接在大多数情况下并没有什么区别~
如果要连接的两个表里面的数据都是一一对应的,这个时候没区别;而如果不是一一对应的,呢内连接和外连接就有区别了!
下面两张表内的数据并不是一一对应的关系:
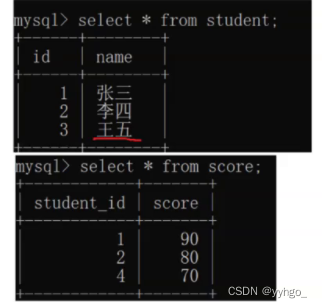
这时使用联合查询,无论是from多个表名还是(inner) join on都只会显示两条记录:

这两种写法,都是“内连接”。接下来我们介绍外连接:
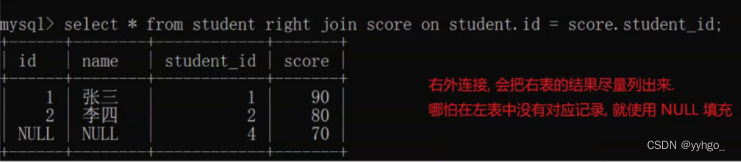
“外连接”有两种:左外连接、右外连接,分别是 join前+left / right
左外连接:

右外连接:
4.2.4 自连接
即自己和自己进行笛卡尔积。
这个操作属于“奇淫巧技”,不是一个通用的解决方案,而是特殊问题的特殊处理方法。自连接的效果就是把行转成列!
SQL中无法针对行和行之间使用条件比较,但是有的需求里又需要行和行进行比较,这时就可以使用自连接,把行转成列!把未知转化为已知~~
例题:显示所有“计算机原理”成绩比“Java”成绩高的成绩信息

这时需要行与行间进行比较,那么怎样实现自连接呢?
select * from score,score;
这样写会报错:

所以我们需要起别名:
select * from score as s1,score as s2;
我们注意到:起别名不仅仅可以针对列,还可以针对表名~ 还有,起别名的时候as可以省略,但是不建议!
这时两个score表之间就进行了排列组合。
自连接排列组合也产生了大量的无效数据,所以也需要指定连接条件:此处是需要每个同学自己的计算机原理和自己的java进行比较,因此使用student_id来作为连接条件,保证每行记录的所有列都是针对同一个同学描述的。
select * from score as s1,score as s2 where s1.student_id=s2.student_id;
此时:

仔细观察,就会发现其中有些记录符合左侧是计算机原理,右侧是java。把这样的行给挑出来!所以进行进一步简化:
select * from score as s1,score as s2 where s1.student_id=s2.student_id and s1.course_id=3 and s2.course_id=1;

接下来要做的就是,看这三行里谁符合 计算机原理 > Java 就行了:
select * from score as s1,score as s2 where s1.student_id=s2.student_id and s1.course_id=3 and s2.course_id=1 and s1.score>s2.score;
然后精简列什么的都是可以操作的~~
4.2.5 子查询
子查询本质上就是套娃,把多个SQL组合成一个了。实际开发中,子查询要慎用!因为子查询可能会构造出非常复杂,非常不好理解的SQL。对于代码的可读性很可能是毁灭性的打击;对于SQL的执行效率,也很可能是毁灭性的打击…
1.单行子查询:返回一行记录的子查询
问题:查询“不想毕业”同学的同班同学?(依然使用4.2.2例题中的表)
思路:先去查询“不想毕业”这个同学的班级id,再按照班级id来查哪些同学和他一个班。
分步实现:
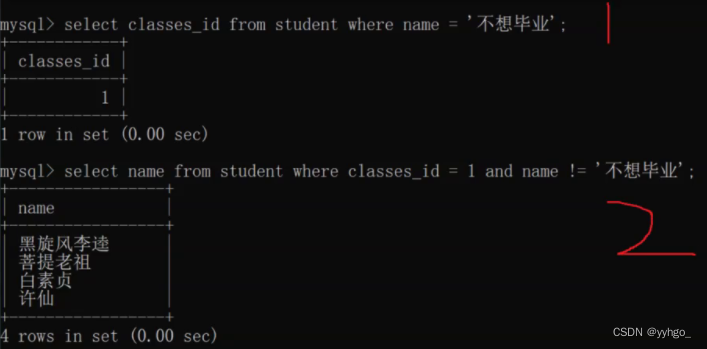
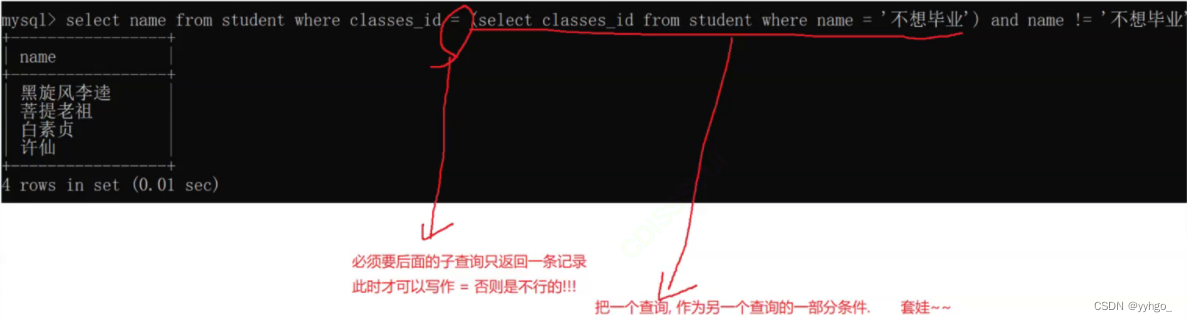
子查询就是把两个操作合并:
2.多行子查询:返回多行记录的子查询
问题:查询”语文”“或”英文””课程的成绩信息?
思路:先根据名字查询出课程id,然后根据课程id查询出课程分数。
分步实现:
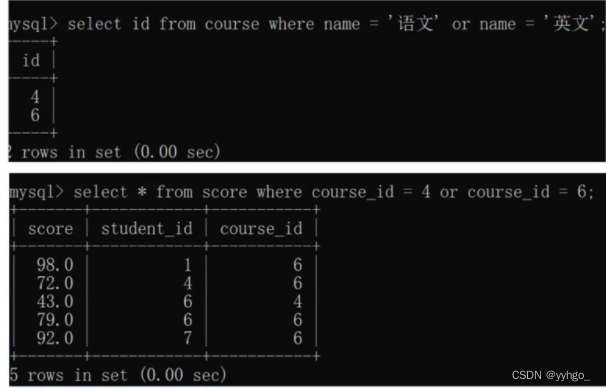
子查询:

这里的套娃是无穷无尽、深不见底的,但是一般不建议这样做!
除了in关键字,exists关键字也可以实现多行子查询(exists本质上也是让数据库执行很多个查询操作)。但是它的可读性比较差,执行效率也大大低于 in 写法,使用它是为了解决特殊场景:查询结果是在内存中,如果查询结果太大了,内存放不下,这时 in 就用不了了,就可以使用 exists 代替。(实际上更推荐的是直接多步完成查询就好,没必要强行合成一个!)
4.2.6 合并查询
合并查询本质上就是把两个查询的结果集,合并成一个。
注意:要求这两个结果集的列相同,才能进行合并!
例题:查询id小于3,或者名字为“英文”的课程?
使用合并查询:
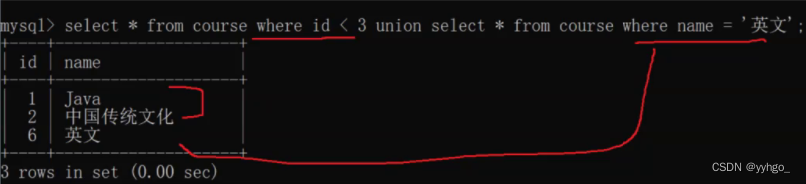
有朋友会发现,直接来个or不就行了吗?何必用union?
用 or 的话查询只能是来自于同一个表;如果是用 union 查询结果可以是来自于不同的表,只要查询结果的列匹配(列的类型、个数、名字相同),即可!
union all和union差不多,union是会进行去重的(把重复的行只保留一份);union all则是可以保留多份,不去重。
五、总结
经过 MySQL数据库基础 和 MySQL表的增删改查(基础) 和 此篇 ,SQL的基本用法,也就差不多告一段落了~~
有的朋友会问:SQL是个编程语言,那么能否定义变量?能否使用条件、循环、函数呢?
实际上,SQL也是有这些语法的,但是不太建议大家用这些,因为其相对更复杂,执行效率也不高,所以一般很少会使用。
工作中更常见的还是基本的增删改查+搭配某个编程语言来写业务逻辑,这样做也避免了业务逻辑和数据库操作耦合太厉害~~
写代码要追求高内聚,低耦合。这样才是比较好的,容易维护的代码。
这里还是补充一下:
写代码的时候,一定是耦合低比较好!因为关联大,就可能导致修改一个模块会影响到另一个模块,关联大,工作量也大,也就容易出错了。把有关联关系的代码写到一起就是高内聚~~
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/93255.html

