
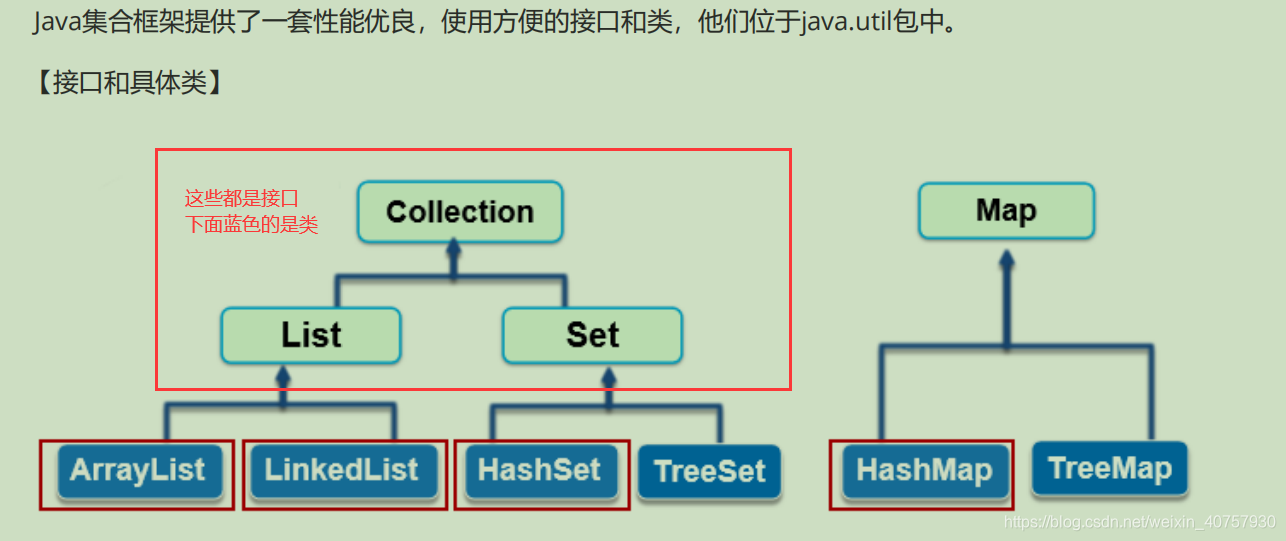
目录
为什么使用集合框架?
变量多了,集合方便管理。集合就是一种数据结构+算法(API),提升开发效率。


hashmap
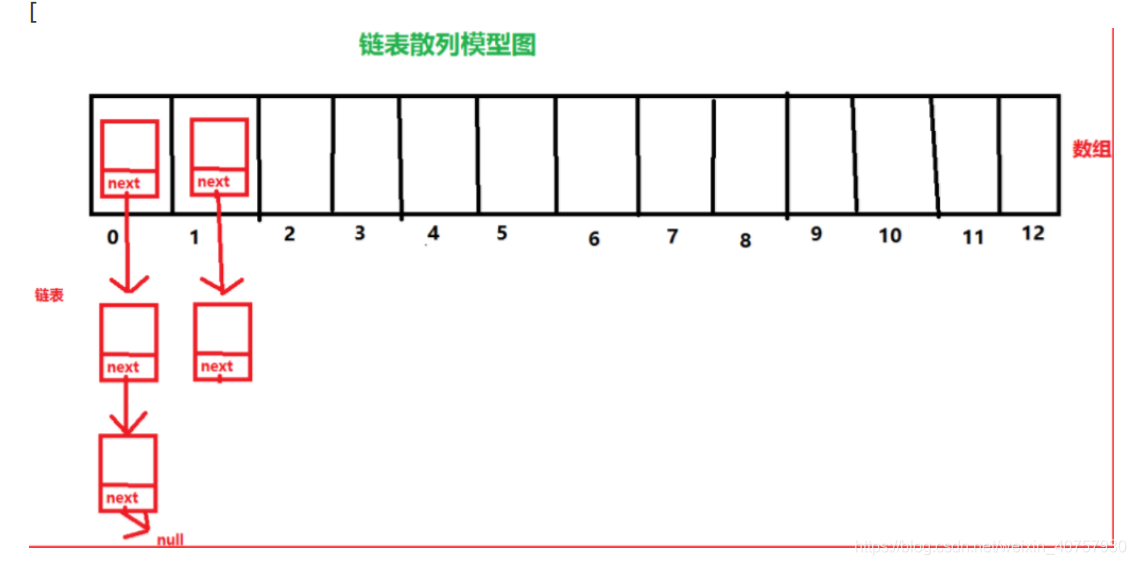
JDK1.8之前hashmap的数据结构是链表散列,也就是链表和数组的结合体。模型图:

hash值就是通过hash算法计算出来的值,这个值就是一个内存地址(不是实际的物理地址)。
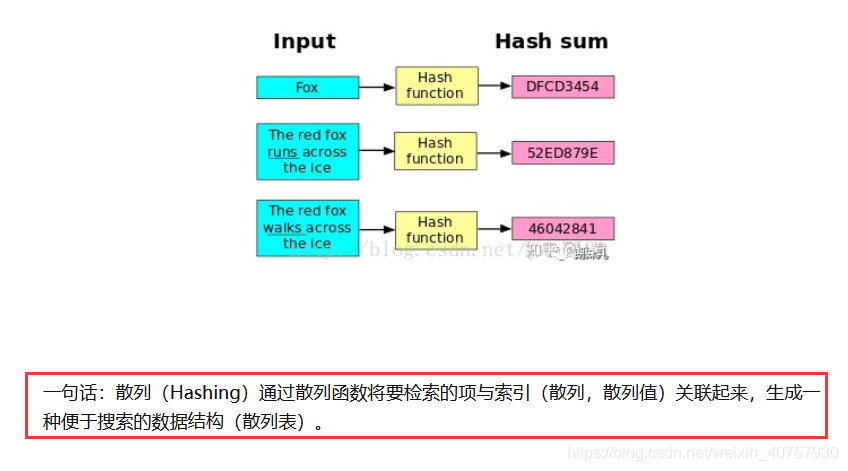
Hash:
- 一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。
- 这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
- 文末有一种hash算法的介绍 SHA算法
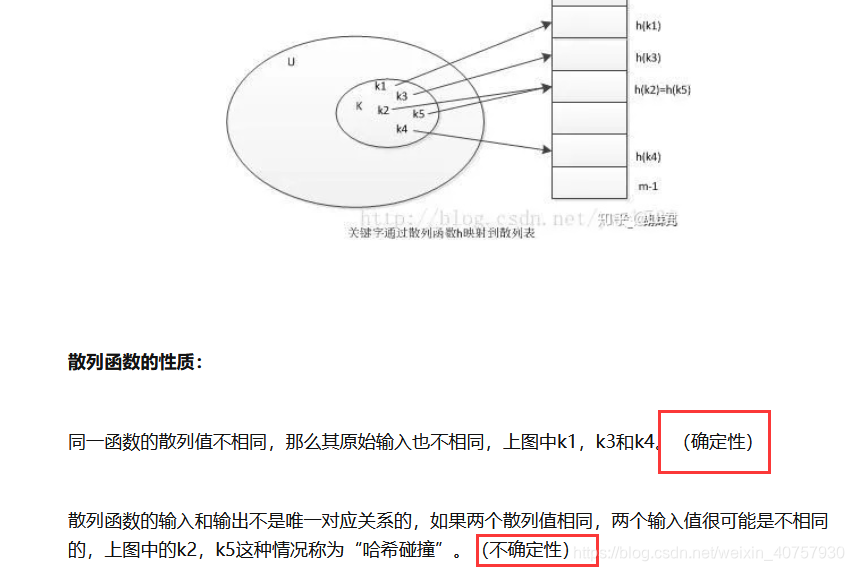
为什么hash表查找数据时间复杂度是O(1)
原理:
- Hash表采用一个映射函数 f : key —> address 将关键字映射到该记录在表中的存储位置,从而在想要查找该记录时,可以直接根据关键字和映射关系计算出该记录在表中的存储位置.
- 通常情况下,这种映射关系称作为Hash函数,而通过Hash函数和关键字计算出来的存储位置(注意这里的存储位置只是表中的存储位置,并不是实际的物理地址)称作为Hash地址.
- 比如上述例子中,假如联系人信息采用Hash表存储,则当想要找到“李四”的信息时,直接根据“李四”和Hash函数计算出Hash地址即可
entry对象的定义为
 JDK1.8之后就hashmap的数据结构变成了 数组+链表+红黑树
JDK1.8之后就hashmap的数据结构变成了 数组+链表+红黑树
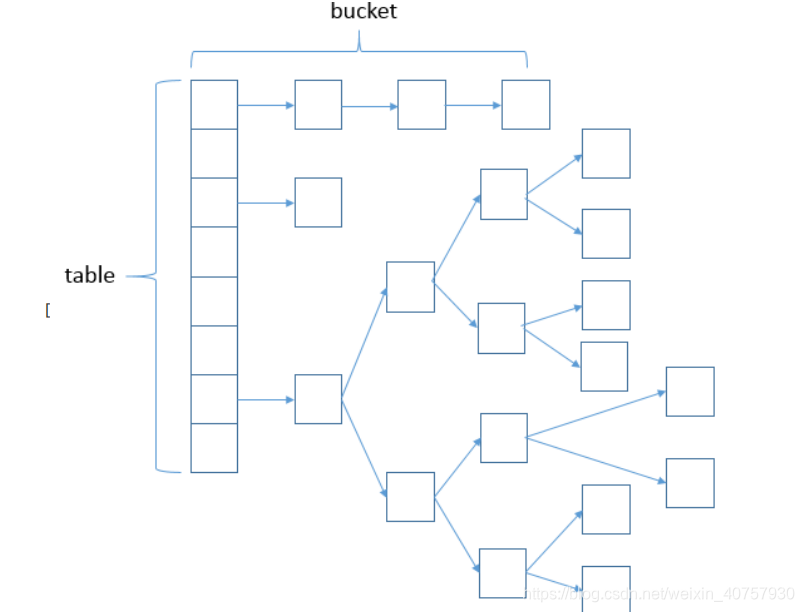
hashmap的扩容机制
首先介绍几个概念
【bucket】桶:
每个桶里就是装一个链表或是红黑树
,链表或是红黑树中可以有很多个元素(entry)
,这就是桶的意思。也就相当于把元素都放在桶中。
capacity
】容量
译为容量代表的数组的容量,也就是数组的长度,同时也是
HashMap
中桶的个数。默认值是16
。
size
】 大小
就是在该
HashMap
的实例中实际存储的元素的个数。
HashMap
满的程度。
loadFactor
的默认值为0.75f
。计算
HashMap
的实时装载因子的方法为:
size/capacity
,而不是占用桶的数量去除以
capacity
。
hashmap初始化默认是有16个桶,当添加一个元素时,通过散列函数生成hash值,也就是地址值,查看当前地址有没有元素,如果没有,就存在该地址的内存中,如果有,使用equals函数判断值是否相等,如果不相等,说明key不一样,那么就以链表的形式挂载在当前地址所存储的元素下,如果相等,则更新value即可。
当添加的元素数量size/capacity达到加载因子并且还要在对应数组位置上有元素时,便进行扩容,桶的数量变为原来的2倍。
loadFactor的大小一般为0.75,过大查找起来耗费时间多,过小空间耗费多。
加载因子是控制数组存放数据的疏密程度,
loadFactor
越趋近于
1
,那么数组中存放的数据(entry)
也就越多,也就越密,也就是会让链表的长度增加,
loadFactor
越小,也就是趋近于
0
,那么数组中存放的数据也就越稀,也就是可能数组中每个位置上就放一个元素。
loadFactor
变为
1最好吗,存的数据很多,但是这样会有一个问题,就是我们在通过
key
拿到我们的
value
时,是先通过
key的
hashcode
值,找到对应数组中的位置,如果该位置中有很多元素,则需要通过
equals来依次比较链表
中的元素,拿到我们的
value
值,这样花费的性能就很高,如果能让数组上的每个位置尽量只有一个元素
最好,我们就能直接得到
value
值了。
loadFactor
变得很小不就好了,但是如果变
得太小,在数组中的位置就会太稀,也就是分散的太开,浪费很多空间,这样也不好,所以在
hashMap
中
loadFactor
的初始值就是
0.75
,一般情况下不需要更改它。
其他
hashmap有很多初始化函数,其中
public
HashMap
(
Map
<?
extends
K
,
?
extends
V
>
m
) {//
初始化填充因子this
.
loadFactor
=
DEFAULT_LOAD_FACTOR
;//
将
m
中的所有元素添加至
HashMap
中putMapEntries
(
m
,
false
);}
Map<? extends K, ? extends V> 中的”?”是什么意思?
map的key要是K类或者其子类的对象,value要是类V或者其子类的对象
为什么要尽量避免数组扩容

通过迭代器访问 hashmap中的value
可以看到 所有的key使用set来维护的,也就是说map中的key具有唯一性。
Collections工具类
Collections是一个工具类,里面提供了操作集合的很多方法,比如排序,查找,替换,直接调用即可。
提供了多个
synchronizedXxx()
方法
·
,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。
HashSet
,
TreeSet
,
arrayList,LinkedList,HashMap,TreeMap
都是线程不安全的。
提供了多个静态方法可以把他们包装成线程同步的集合。
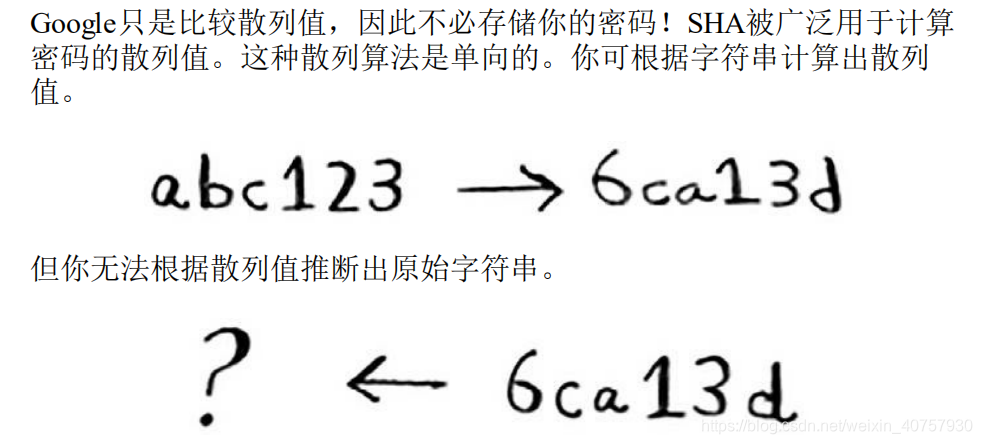
SHA算法
而SHA根据字符串生成另一个字符串
。
用来检查密码
不是直接判断密码是否相等。

局部敏感的散列算法


版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/92883.html

