
Spark中的 Shuffle
Shuffle,中文的意思就是洗牌。
将所有分区的数据重新打散,然后根据某种特征 汇聚到不同节点的过程就是Shuffle;
如reduceByKey时,需要根据key对不同分区的数据重新聚合;


Spark Shuffle 分为两种:一种是基于 Hash 的 Shuffle;另一种是基于 Sort 的 Shuffle。
1. Hash Shuffle
(一)未优化的Hash Shuffle
假设前提:每个 Executor 只有 1 个 CPU core,也就是说,无论这个 Executor 上分配多少个 task 线程,同一时间都只能执行一个 task 线程(并发);
如下图中有 3 个 Reducer,从 Task 开始那边各自把自己进行 Hash 计算(分区器:hash/numreduce 取模),分类出 3 个不同的类别,
每个 Task 都分别有对应reduce个数的数据,对应reduce个数的本地文件,然后 Reducer 会在每个 Task 中把属于自己类别的数据收集过来,汇聚成一个同类别的大集合;
即每 1 个 Task 输出 3 份本地文件对应3个reduce!
这里有 4 个Mapper Tasks,所以总共输出了 4 个 Tasks x 3 个分类文件 = 12 个本地小文件。

缺点:每个Task对都有每种类型的文件,小文件太多,效率低;
(二)优化的Hash Shuffle
优化的 HashShuffle 过程就是启用合并机制,合并机制就是复用 buffer;开启合并机制的配置是 spark.shuffle.consolidateFiles。该参数默认值为 false,将其设置为 true 即可开启优化机制;
在同一个进程中,无论是有多少个 Task,都会把同样的Key的数据 放在同一个 Buffer 里,然后把 Buffer 中的数据写入【以 Core 数量为单位】的本地文件中,(一个 Core 只有一种类型的Key 的数据),
每 1 个Task 所在的进程中,分别写入共同进程中的 3 份本地文件,这里有 4 个 Mapper Tasks,
所以总共输出是 2 个Cores x 3 个分类文件 = 6 个本地小文件。
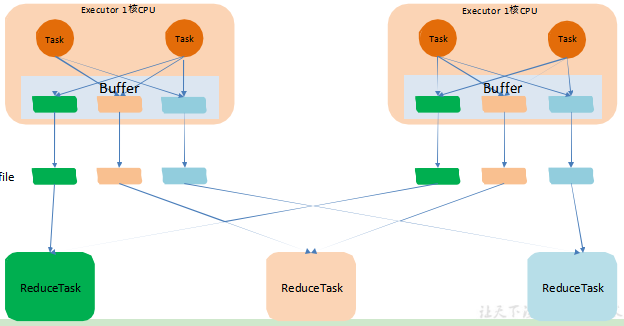
缺点:但任务过多,核数过多,依然有很多小文件!
总结Hash Shuffle
优点:
可以省略不必要的排序开销;避免了排序所需的内存开销。
缺点:
生产的文件过多,会对文件系统造成压力。
2. Sort Shuffle
(一)普通 Sort Shuffle
- 会先将数据先写入一个【内存中的】数据结构Map,一边通过 Map 局部聚合,一遍写入内存,当达到阀值就将数据溢写到磁盘,清空内存中数据结构;(类似hadoop)
- 【在溢写磁盘前】,先根据 key 进行排序,然后
分批写入到磁盘文件中,默认一批是10000条数据;每一批溢写都会产生一个 磁盘文件,也就是说一个Task 过程会产生多个临时文件。 - 最后 【在每个 Task 中】,将所有的临时文件merge合并(即一个Task对应一个文件),此过程将所有临时文件读取出来,一次写入到最终文件;同时写一份索引文件,标识下游各个Task 的数据在文件中的索引,
start offset和end offset。

对应Task 输出 3个文件;
(二)bypass SortShuffle
bypass 运行机制的触发条件如下:
1)shuffle reduce task 数量小于等于 spark.shuffle.sort.bypassMergeThreshold 参数的值,默认为 200。
2)不是聚合类的 shuffle 算子(比如 reduceByKey)。
- 此时每个task 都会为每种reduce 都创建一个临时磁盘文件,并将数据按 key 进行hash 然后根据 key 的 hash 值,将数据 写入对应的磁盘文件之中;(类似未优化的Hash Shuffle,小文件非常多)
- 最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
bypass SortShuffle 类似未优化的Hash Shuffle,只是最后将临时文件合成了大文件并创建索引文件;
bypass SortShuffle 与普通 SortShuffleManager 运行机制的不同在于不会进行排序,所以节省了排序的性能开销;

Sort 的 Shuffle 机制的优缺点
优点:
1.小文件的数量大量减少,Mapper 端的内存占用变少;
缺点:
1.普通的Sort Shuffle需要排序,有排序的开销;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/89179.html

