
BufferPool是什么
- mysql中的一块缓冲池,用来提升读写效率
- 所有的增删改查不直接操作硬盘,都针对bufferpool进行,然后bufferpool再定时向磁盘中刷新数据
- bufferPool中的数据是按页从磁盘中加载而来,被修改的数据页称为脏页(与磁盘数据页不同步)
BufferPool是如何工作的
流程很复杂,一图千言,直接看图
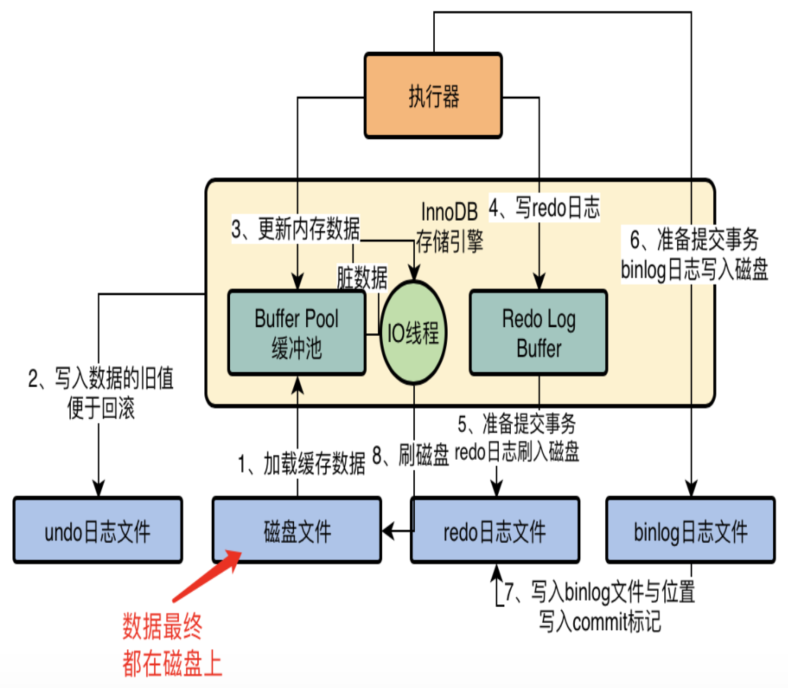

- 1、从磁盘中加载数据到bufferpool,按页加载(每页4K大小)
- 2、将数据的旧值写入到undo_log,以便后续回滚
- 3、数据对bufferpool进行修改,修改后的数据页称为脏页
- 4、修改数据同时写入redo_log buffer
- 5、准备提交事务时,将redo_log刷入磁盘,并标记为prepare状态
- 6、写入bin_log日志
- 7、提交事务,写入redo_log,并标记为commit状态
- 8、bufferpool的脏页数据,通过单独的IO线程,定时刷入磁盘
BufferPool是如何提升效率的
bufferpool
- bufferpool是一个内存的缓冲池,直接针对内存操作,内存io相比于磁盘io,会有巨大幅度的性能提升(差不多1000倍),在很多服务组件上都使用缓冲池来提升性能
- bufferpool 中的数据,通过一条io线程,在mysql闲时或者bufferpool容量已满时,向磁盘中刷新数据
同时写多份log,如何保证效率的
- redo_log、bin_log 都有对应的buffer,先写buffer后再刷磁盘,且刷磁盘是顺序io,效率上比随机io要高的多
故障重启后如何保障数据恢复
- 故障数据主要通过bin_log回滚,具体回滚过程详见https://blog.csdn.net/shehuinidaye/article/details/108959753
Innodb的LRU算法
- innodb 的LRU算法是非常巧妙的,通过将LRU连表分为新生代和老年代,比例为63:37,解决了预读失败的问题
- 老年代又做了优化,使用一个时间窗口,当老年代的数据,停留超过默认时间窗口(1秒)后,被放入到新生代的头部
详细的文章链接 https://www.jianshu.com/p/f9ab1cb24230
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/83655.html

