
目录
链式存储结构
- 结点在存储器中的位置是任意的,即逻辑上相邻的数据元素在物理上不一定相邻。
- 用一组物理位置任意的存储单元来存放线性表的数据元素(这组存储单元即可以是连续的,也可以是不连续的)
- 链表中元素的逻辑次序和物理次序不一定相同
- 在链表的第一个结点之前附设一个头结点(头指针)head指向第一个结点。头结点的数据域可以不存储任何信息
- 单链表是由表头唯一确定,因此单链表可以用头指针的名字来命名
- 各结点由两个域组成:①数据域:存储元素数值数据;②指针域:存储直接后继结点的存储位置
- 顺序表是随机存取;链表是顺序存取
单链表
结点只有一个指针域的链表,称为单链表或线性链表
双链表
结点有两个指针域的链表,称为双链表
循环链表
首尾相接的链表称为循环链表
头指针、头结点、首元结点
头指针:指向链表中第一个结点的指针
首元结点:链表中存储第一个数据元素a1的结点
头结点:在链表的首元结点之前附设的一个结点
线性表的链式表示
如何表示空表
- 无头结点时,头指针为空时表示空表
- 有头结点时,头结点的指针域(首元结点)为空时表示空表
在链表中设置头结点的好处
- 便于首元结点的处理(首元结点的地址保存在头结点的指针域中,所以在链表的第一个位置上的操作和其他位置相同)
- 便于空表和非空表的统一处理
头结点的数据域中装的是什么
- 头结点的数据域可以为空,也可存放线性表长度等附加信息,但此结点不能计入链表长度值
单链表的定义和表示
带头结点的单链表
| 数据域 | 指针域 |
| data | next |
typedef struct Lnode{
ElemType data;//数据域,保存结点的值
struct Lnode *next;//指针域
}LNode,*LinkList; //LinkList为指向结构体LNode的指针类型- 定义一个单链表L
LinkLIst L;
- 定义结点指针
LNode *p
- 存储学生学号、姓名、成绩的单链表结点类型定义
typedef Struct student{
char num[8];
char name[8];
int score;
struct student *next; //指针域
}LNode,*LinkList;
为了统一链表的操作,通常这样定义
typedef Struct{
char num[8];
char name[8];
int score;
}ElemType;
typedef struct Lnode{
ElemType data;
struct Lnode *next;
}LNode,*LinkList; 单链表各种操作的实现
p = L; //p指向头结点
s = L -> next; //s指向首元结点
p = p -> next; //p指向下一结点单链表的初始化(带头结点的单链表)
Status InitList(LinkList &L){ //构造一个空的单链表
L = new LNode; //或L = (LinkList) malloc (sizeof(LNode));
L -> next = NULL;
return OK;
}判断链表是否为空
空表:链表中无元素,称为空链表(头指针和头结点仍然在)
判断头结点指针域是否为空
int ListEmpty(LinkList L){ //若L为空表,则返回1,否则返回0
if(L -> next) //非空
return 0;
else
return 1;
}单链表的销毁(销毁后不存在)
从头指针开始,依次释放所有结点
Status DestoryList_L(LinkList &L){
LNode *p;
while(L){ //表L不为空
p = L;
L = L -> next;
delete p;
}
return OK;
}单链表的清空(头指针和头结点仍然在)
链表仍存在,但链表中无元素,成为空链表
依次释放所有结点,并将头结点指针域置为空
Status ClearList(LinkList &L){ //将L重置为空表,最后还是头结点的地址
LNode *p,*q;
p = L -> next;
while(p){ //当p和q指针同时指向空结点时,退出循环
q = p -> next;
delete p;
p = q;
}
L -> next = NULL; //将头结点指针域置为空
return OK;
}求链表的表长
int ListLength_L(LinkList L){ //返回L中数据元素的个数
LNode *p;
p = L -> next; //p指向第一个结点
i = 0;
while(p){
i++;
p = p -> next;
}
return i;
}
单链表的取值 O(n)
Status GetElem(LinkList L,int i, ElemType &e){
p = L -> next; j = 1;
while(p && j<i){
p = p -> next;
++j;
}
if(!p || j>i) return ERROR; //第i个元素不存在
e = p -> data;
return OK;
}平均时间复杂度为O(n)
平均查找长度为(n-1)/ 2
单链表的按值查找 O(n)
根据指定数据获取该数据所在的位置(地址)
LNode *LocateElem_L(LinkList L,ELemType e){
//在线性表L中查找值为e的数据元素
//找到,则返回L中值为e的数据元素的地址,查找失败返回NULL
p = L -> next;
while(p && p -> data!=e){
p = p -> next;
return p; //找到了就是目的结点,没找到就是空
}根据指定数据获取该数据的位置序号
int LocateElem_L(LinkList L,ElemType e){
//返回L中值为e的数据元素的位置序号,查找失败返回0
p = L -> next; j = 1;
while(p && p -> data!= e){
p = p-> next;
j++;
}
if(p) return j; //如果找到了,就返回当前位置
else return 0;
}单链表的插入操作 O(n)
在第i个结点前插入值为e的新结点
Status ListInsert_L(LinkList &L,int i,ElemType e){
p = L; j = 0;
while(p && j < i-1){ //寻找第i-1个结点,p指向第i-1个结点
p = p-> next;
++j;
}
if(!p || j > i-1) return ERROR; //i大于表长+1或者小于1,插入位置非法
s = new LNode; s -> data = e;
s -> next = p -> next;
p -> next = s;
return OK;
}单链表的删除操作 O(n)
删除第i个结点
Status ListDelete_L(LinkList &L,int i,ElemType &e){
p = L; j = 0;
while(p -> next && j < i-1){
p = p -> next;
++j; //寻找第i个结点,并令p指向其前驱
}
if(!(p -> next) || j>(i-1)) return ERROR; //删除位置不合理
q = p -> next; //临时保存被删结点的地址以备释放
p -> next = q -> next; //改变删除结点前驱结点的指针域
e = p -> data; //保存删除结点的数据域
delete q; //释放删除结点的空间
return OK;
}
单链表的建立
头插法 O(n)
void CreateList_H(LinkList &L, int n){
L = new LNode;
L -> next = NULL; //建立一个带头结点的单链表
for(i = n;i > 0;--i){
p = new LNode; //生成新结点 p = (LNode *)malloc(sizeof(LNode));
cin >> p -> data;
p -> next = L -> next; //插入到表头
L -> next = p;
}
}尾插法 O(n)
void CreateList_R(LinkList &L, int n){
L = new LNode;
L -> next = NULL; //建立一个带头结点的单链表
for(i = 0;i < n;++i){
p = new LNode; //生成新结点,输入元素值
cin >> p -> data;
p -> next = NULL; //p指针指向的新结点为单个结点
r -> next = p; //插入到表尾
r = p; //r指向新的尾结点
}
}循环链表
循环链表的定义
-
一种头尾相接的链表。其结点是最后一个结点的指针域指向链表的头结点,整个链表的指针域链接成一个环
-
从循环链表的任意一个结点出发都可以找到链表中的其它结点,使得表处理更加方便灵活
循环链表的操作
-
对于单循环链表,除链表的合并外,其他的操作和单线性链表基本上一致,仅仅需要在单线性链表操作算法基础上作修改
p != L //p不等于头指针,说明不是空链表
p->next != L //判断是否是表尾结点 上述操作的时间复杂度为O(1)
尾指针表示的单循环链表
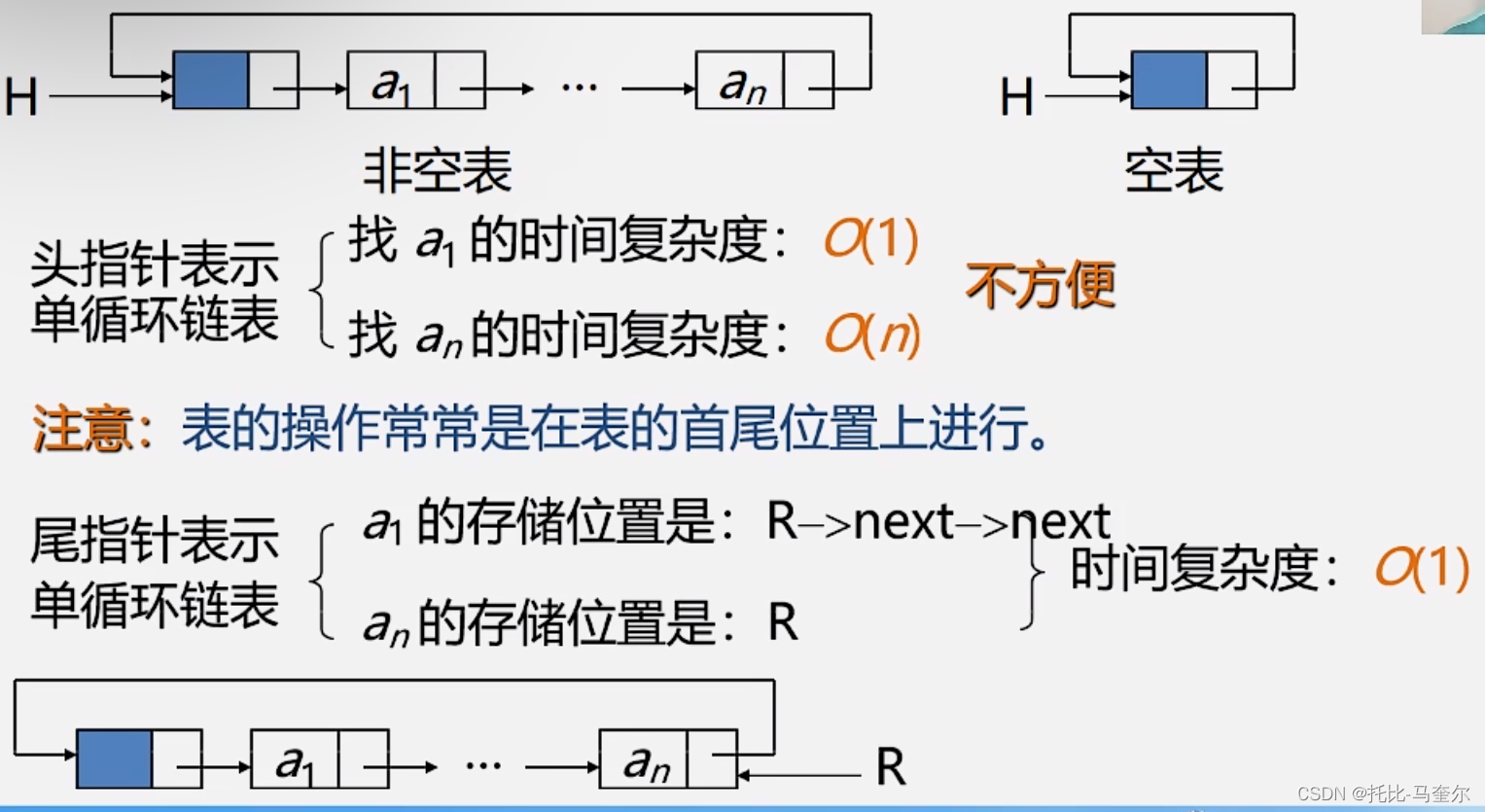
带尾指针循环链表的合并(将Tb合并在Ta之后)
LinkList Connect(LinkList Ta,LinkList Tb){
//假设Ta,Tb都是非空的单循环链表
p = Ta -> next; //p存Ta的表头结点
Ta -> next = Tb -> next -> next; //Tb表头连结Ta表尾
delete Tb -> next; //释放Tb表头结点
Tb -> next = p; //修改指针,使Tb表的尾指针指向Ta的表头结点
return Tb;
}双向链表
- 构成链表的每个结点中设立两个指针域:一个指向其直接前驱的指针域piror,一个指向其直接后继的指针域next。这样形成的链表中有两个方向不同的链,故称为双向链表
双向链表的结点及其类型定义
typedef struct DuLNode{
ElemType data;
struct DuLNode *piror,*next;
}DulNode,*DuLinkList;- 双向循环链表
①让头结点的前驱指针指向链表的最后一个结点
②让最后一个结点的后继指针指向头结点
- 双向链表结构的对称性
(p->piror)->next = p = (p->next)->piror;- 在双向链表中(求链表长度、链表元素取值),因仅涉及一个方向的指针,故它们的算法与线性链表相同。但在插入、删除时,则需同时修改两个方向上的指针,两者的操作时间复杂度为O(n)
双向链表的插入(先左后右) O(n)

void ListInsert_DuL(DuLinkList &L,int i,ElemType e){
//在带头结点的双向循环链表L中第i个位置之前插入元素e
if(!(p = GetElemP_DuL(L,i))) return ERROR; //p指向位置不合理
s = new DuLNode; s -> data = e;
s -> piror = p -> piror;
p -> piror -> next = s;
s -> next = p;
p -> piror = s;
return OK;
}双向链表的删除 O(n)
void ListDelete_DuL(DuLink &L,int i,ElemType &e){
//删除带头结点的双向循环链表L的第i个元素,并用e返回
if(!(p = GetElemP_DuL(L,i))) return ERROR;
//得到的时第i个结点的位置,p指向位置不合理
e = p -> data;
p -> piror -> next = p -> next;
p -> next -> piror = p -> piror;
free(p);
return OK;
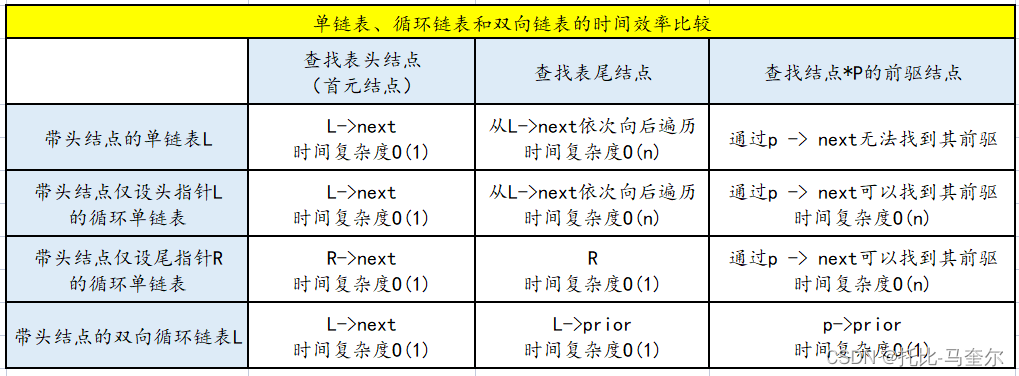
}单链表、循环链表、双向链表的比较
顺序表和链表的比较
- 存储密度:结点数据本身所占的存储量和整个结点结构中所占的存储量之比
存储密度 = 结点数据本身占用的空间 / 结点占用的空间总量
一般地,存储密度越大,存储空间的利用率就越高。显然,顺序表的存储密度为1,而链表的存储密度小于1

线性表的应用
线性表的合并
时间复杂度为O(ListLength(La)*ListLength(Lb))
void union(List &La,List Lb){
La_Len = ListLength(La);
Lb_Len = ListLength(Lb);
for(i = 1;i <= Lb_Len;i++){
GetElem(Lb,i,e);
if(!LocateElem(La,e)) ListInsert(&La,++La_Len,e);
}
}有序表的合并
用顺序表实现
时间复杂度为 O(ListLength(La) + ListLength(Lb))
空间复杂度为 O(ListLength(La) + ListLength(Lb))
void MergeList_Sq(SqList LA,SqList LB,SqList &LC){
pa = LA.elem;
pb = LB.elem; //指针pa和pb的初值分别指向两个表的第一个元素
LC.length = LA.length + LB.length; //新表长度为合并两表的长度之和
LC.elem = new ElemType[LC.length]; //为合并后的新表分配一个数组空间
pc = LC.elem; //指针pc的初值指向表的第一个元素
pa_last = LA.elem + LA.length -1; //指针pa_last指向LA表的最后一个元素
pb_last = LB.elem + LB.length -1; //指针pb_last指向LB表的最后一个元素
while(pa <= pa_last && pb <= pb_last){ //两个表都非空
if(*pa <= *pb) *pc++ = *pa++; //依次摘取两个表中值较小的结点
else *pc++ = *pb++; //先赋值,然后指针向后移动
}
while(pa <= pa_last) *pc++ = *pa++; //LB表已到达表尾,将LA中剩余元素加入LC
while(pb <= pb_last) *pc++ = *pb++; //LA表已到达表尾,将LB中剩余元素加入LC
}用链表实现
时间复杂度为 O(ListLength(La) + ListLength(Lb))
void MergeList_L(LinkList &La,LinkList &Lb,LinkList &Lc){
pa = La -> next; pb = pb -> next;
pc = Lc = La; //用La的头结点作为Lc的头结点
while(pa && pb){
if(pa -> data <= pb -> data){
pc -> next = pa;
pc = pa; //pc指针向后移动
pa = pa -> next;
}
else{
pc -> next = pb;
pc = pb;
pb = pb -> next;
}
pc -> next = pa? pa:pb; //插入剩余段
delete Lb; //释放Lb的头结点
}案例分析与实现
一元多项式的运算
主要是用两个线性表,分别存储每一项的每个指数对应的系数
指数相等的系数相加之后,就可以存储在一个新的线性表中
稀疏多项式的运算
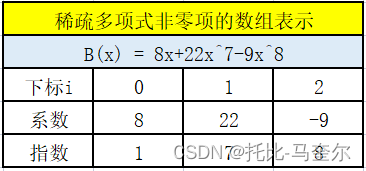
线性表B = ((8,1)(22,7)(-9,8))
顺序存储实现
①存储空间分配不灵活
②运算的空间复杂度高
链式存储实现
结点类型定义
typedef struct PNode{
float coef; //系数
int expn; //指数
struct PNode *next; //指针域
}PNode,*Polynomial;- 多项式创建 O(n^2)
多项式的指数从小到大依次增大

void CreatePolyn(Polynomial &P,int n){
//输入m项的系数和指数,建立表示多项式的有序链表P
P = new LNode;
P -> next = NULL; //建立一个带头结点的单链表
for(i = 1;i < n;++i){ //依次输入n个非零项
s = new PNode; //生成新结点
cin>>s->coef>>s->expn; //输入系数和指数
pre = P; //pre用于保存q的前驱,初值为头结点
q = P -> next; //q初始化,指向首元结点
while(q && q->expn < s->expn){ //找到第一个大于输入项指数的项*q
pre = q; q=q->next;
}
s -> next = q; //将插入项s插入到q和其前驱结点pre之间
pre -> next = s;
}
}- 多项式相加 时间复杂度为O(m+n) 空间复杂度为O(1)

void AddPolyn(Polynomial &Pa,Polynomial &Pb){
p1 = Pa -> next;
p2 = Pb -> next; //p1和p2初值分别指向Pa和Pb的首元结点
p3 = Pa; //p3指向和多项式的当前结点,初值为Pa
while(p1 && p2){ //二者非空
if(p1 -> expn == p2 -> expn){ //指数相等
sum = p1 -> coef + p2 -> coef; //sum保存两项的系数和
if(sum != 0){
p1 -> coef = sum; //修改Pa当前结点的系数值为两项系数的和
p3 -> next = p1; p3 = p1; //将修改后的Pa当前结点链在p3之后
p1 = p1 -> next; //p1指向后一项
r = p2; p2 = p2 -> next; delete r; //删除Pb当前结点,p2指向后一项
}
else{
r = p1; p1 = p1 -> next; delete r; //删除Pa当前结点,p1指向后一项
r = p2; p2 = p2 -> next; delete r; //删除Pb当前结点,p2指向后一项
}
}
else if(p1 -> expn < p2 -> expn){ //Pa当前结点的指数值小
p3 -> next = p1; //将p1链在p3之后
p3 = p1; //p3指向p1
p1 = p1 -> next; //p1指向后一项
}else{
p3 -> next = p2; //将p2链在p3之后
p3 = p2; //p3指向p2
p2 = p2 -> next; //p2指向后一项
}
}
p3 -> next = p1?p1:p2; //插入非空多项式的剩余段
delete Pb; //释放Pb的头结点
}图书信息管理系统
struct Book{
char id[20]; //ISBN
char name[50]; //书名
int price; //定价
};
typedef struct{ //顺序表
Book *elem;
int length;
}SqList;
typedef struct LNode{ //链表
Book data;
struct LNode *next;
}LNode,*LinkList;版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/83256.html

