
一、安装环境
node1 10.3.45.112
node2 10.3.45.113
node3 10.3.45.115
硬件配置:1C1G,另外每台机器器最少挂载二块硬盘
二、环境准备,每台都得执行
(1)关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
(2)关闭selinux:
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
(3)关闭NetworkManager
systemctl disable NetworkManager && systemctl stop NetworkManager
(4)添加主机名与IP对应关系:
vim /etc/hosts
10.3.45.112 node1
10.3.45.113 node2
10.3.45.115 node3
(5)设置主机名:
hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname node3
(6)同步网络时间和修改时区
echo '*/2 * * * * /usr/sbin/ntpdate cn.pool.ntp.org' &>/dev/null >>/var/spool/cron/root
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
(7)设置文件描述符
ulimit -n 65535
cat >> /etc/security/limits.conf << EOF
* soft nofile 65535
* hard nofile 65535
EOF
sysctl -p
(8)在node1上配置免密登录到node2、node3
ssh-copy-id root@node1
ssh-copy-id root@node2
ssh-copy-id root@node3
三、配置yum源,每台都得执行
[root@node1 ~]# yum install epel-release -y
[root@node1 ~]# cat /etc/yum.repos.d/ceph.repo
[ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/$basearch
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/noarch
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/SRPMS
enabled=0
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
四、部署rados集群(mon、mgr、mds、rados),以下操作在/etc/ceph目录下
1、创建一个ceph集群,生成mon
yum install ceph-deploy -y
mkdir /etc/ceph
cd /etc/ceph
ceph-deploy new node1 node2 node3 #生成mon


解决方法 百度网盘链接:https://pan.baidu.com/s/1ShQK4lGke0m6hcDvXP1jWA
提取码:5elt
wget https://pypi.python.org/packages/source/d/distribute/distribute-0.7.3.zip --no-check-certificate
unzip distribute-0.7.3.zip
cd distribute-0.7.3
python setup.py install
2、安装ceph软件
ceph-deploy install --no-adjust-repos node1 node2 node3
3、生成monitor检测集群所使用的的秘钥
ceph-deploy mon create-initial
4、修改ceph.conf配置
vim /etc/ceph/ceph.conf
[global]
fsid = b697e78a-2687-4291-93bf-42739e967bec
mon_initial_members = node1, node2, node3
mon_host = 10.3.45.112,10.3.44.113,10.3.45.115
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
#注意:此文件的最底部要留有最少一个空行
mon clock drift allowed = 2
mon clock drift warn backoff = 30
# 内外网分离配置(非必须,多网卡的情况下可以配置)
public_network = 10.3.45.0/24
#cluster_network = 10.4.41.0/24
#depends on you amount of PGs
#每个OSD允许的最大pg数
mon_max_pg_per_osd = 2000
#default is 2, try to set at least 5. It will be
osd_max_pg_per_osd_hard_ratio = 10
#without it you can't remove a pool
mon_allow_pool_delete = true
#指定Ceph在OSD守护进程的多少秒时间内没有响应后标记其为“down”或“out”状态
mon_osd_down_out_interval = 86400
# 存储集群副本个数(如果只有2个OSD此处请设置为2否则会WARN)
osd_pool_default_size = 2
# 在degraded状态下允许只存在一个副本
osd_pool_default_min_size = 1
#ceph为了限制pg分裂的速度,设置了mon_osd_max_split_count这个参数。这个参数表示【在分裂的时候,每个osd容许的最大分裂数量
mon_osd_max_split_count = 100
#若少于5个OSD, 设置pg_num为128。
#5~10个OSD,设置pg_num为512。
#10~50个OSD,设置pg_num为4096。
#超过50个OSD,可以参考pgcalc计算。
#池的pg数量,Total PGs = ((Total_number_of_OSD * 100) / max_replication_count) / pool_count 结算的结果往上取靠近2的N次方的值
# 两台ceph每台二个osd pg_num计算得为512
osd_pool_default_pg_num = 512
# 两台ceph每台二个osd pgp_num计算得为512
osd_pool_default_pgp_num = 512
# CRUSH规则用到chooseleaf时的bucket的类型,默认值1
osd_crush_chooseleaf_type = 1
#关闭自动分片
rgw_dynamic_resharding = false
# 每个桶的索引的分片数量(后期可以根据需求动态的针对某个桶更新)
rgw_override_bucket_index_max_shards = 100
rgw_max_chunk_size = 1048576
rgw_cache_lru_size = 1000000
rgw_bucket_default_quota_max_objects = -1
# 如果磁盘容量大,则告警阈值从0.85调为0.9
osd_failsafe_full_ratio = 0.98
mon_osd_full_ratio = 0.95
mon_osd_backfillfull_ratio = 0.93
mon_osd_nearfull_ratio = 0.9
[osd]
#默认值2,osd发送heartbeat给其他osd的间隔时间
osd_heartbeat_interval = 15
#默认值7,OSD 多久没心跳就会被集群认为它挂( down )了
osd_heartbeat_grace = 60
# 处理peering等请求的线程数
osd_op_threads = 8
# 处理snap trim,replica trim及scrub等的线程数
osd_disk_threads = 4
# 如果这个参数被设置,那么Ceph集群启动时,就会在操作系统层面设置最大打开文件描述符。这就避免OSD进程出现与文件描述符不足的情况。参数的缺省值为0,可以设置成一个64位整数
max_open_files = 10485760
# 如果初始化的时候,把该值设置为true,然后重启所有osd。不然创建完pool会提示:100.000% pgs unknown100.000% pgs unknown。所有osd都加入,集群ok后,再统一把该值设置为false, 然后重启所有osd
osd_crush_update_on_start = true
# bluestore存储小文件的优化
#bluestore_cache_autotune = 0
bluestore_cache_size_hdd = 3221225472 #3G
bluestore_cache_kv_ratio = 0.6
bluestore_cache_meta_ratio = 0.4
bluestore_cache_kv_max = 1073741824 #1G
bluestore_csum_type = none
bluestore extent map shard max size = 200
bluestore extent map shard min size = 50
bluestore extent map shard target size = 100
bluestore rocksdb options = compression=kNoCompression,max_write_buffer_number=32,min_write_buffer_number_to_merge=2,recycle_log_file_num=32,compaction_style=kCompactionStyleLevel,write_buffer_size=67108864,target_file_size_base=67108864,max_background_compactions=31,level0_file_num_compaction_trigger=8,level0_slowdown_writes_trigger=32,level0_stop_writes_trigger=64,max_bytes_for_level_base=536870912,compaction_threads=32,max_bytes_for_level_multiplier=8,flusher_threads=8,compaction_readahead_size=2MB
osd map share max epochs = 100
osd max backfills = 5
osd memory target = 4294967296
osd op num shards = 8
osd op num threads per shard = 2
osd min pg log entries = 10
osd max pg log entries = 10
osd pg log dups tracked = 10
osd pg log trim min = 10
# scrub优化
osd scrub begin hour = 0
osd scrub end hour = 7
osd scrub chunk min = 1
osd scrub chunk max = 1
osd scrub sleep = 3
osd deep scrub interval = 241920
5、修改密钥权限并传送ceph.conf文件以及集群所使用的的秘钥
[root@node1 ceph]# chmod +r /etc/ceph/ceph.client.admin.keyring
[root@node1 ceph]# ceph-deploy --overwrite-conf admin node1 node2 node3
6、配置mgr,用于管理集群
[root@node1 ceph]# ceph-deploy mgr create node1 node2 node3
7、开启 dashboard (在任一 mon_server 节点上),传送ceph.conf文件
[root@node1 ceph]# echo -e "\n[mgr]\nmgr modules = dashboard\n" >> /etc/ceph/ceph.conf
[root@node1 ceph]# ceph mgr dump #获取mgrmap,默认最新
[root@node1 ceph]# ceph mgr module enable dashboard
[root@node1 ceph]# ceph mgr dump #获取mgrmap,默认最新

[root@node1 ceph]# ss -anpt|grep 7000
LISTEN 0 5 [::]:7000 [::]:* users:(("ceph-mgr",pid=2154,fd=26))
[root@node1 ceph]# ceph-deploy --overwrite-conf config push node1 node2 node3
8、准备磁盘(node1、node2、node3三个节点)
#磁盘初始化
parted /dev/sdb mklabel gpt -s
parted /dev/sdc mklabel gpt -s
#建立磁盘分卷
ceph-volume lvm zap /dev/sdb
ceph-volume lvm zap /dev/sdc
9、添加OSD
ceph-deploy osd create --data /dev/sdb node1
ceph-deploy osd create --data /dev/sdb node2
ceph-deploy osd create --data /dev/sdb node3
ceph-deploy osd create --data /dev/sdc node1
ceph-deploy osd create --data /dev/sdc node2
ceph-deploy osd create --data /dev/sdc node3
效果
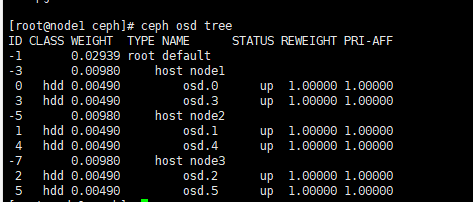
五、部署文件系统
1、部署mds服务
ceph-deploy mds create node1 node2 node3
##查看状态
ceph mds stat
2、创建进程池
ceph fs ls
一个 Ceph 文件系统至少需要两个 RADOS 池,一个用于数据,一个用于元数据。创建存储池
ceph osd pool create cephfs_data 128
ceph osd pool create cephfs_metadata 128
3、创建文件系统
ceph fs new cephfs cephfs_metadata cephfs_data #cephfs可自定义
- 关于创建存储池:
确定pg_num取值是强制性的,因为不能自动计算。下面是几个常用的值:
*少于5 个OSD 时可把pg_num设置为128
*OSD 数量在5 到10 个时,可把pg_num设置为512
*OSD 数量在10 到50 个时,可把pg_num设置为4096
*OSD 数量大于50 时,你得理解权衡方法、以及如何自己计算pg_num取值
*自己计算pg_num取值时可借助pgcalc 工具
随着OSD 数量的增加,正确的pg_num取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。
4、挂载
mount -t ceph 10.3.45.112:6789:/ /lijia -o name=admin,secret=AQBUlxxiSSHyCRAARXCvpSml2Eh5bj/eZvX5Kg==
- #10.3.45.112:6789:/ , MON 的套接字
- #/lijia,需要挂载的目录
- #name=admin,secret=AQBUlxxiSSHyCRAARXCvpSml2Eh5bj/eZvX5Kg==,CephX 用户的密钥 例如:

成功结果

5、设置持久挂载
vim /etc/fstab
10.3.45.112:6789:/ /lijia ceph name=admin,secret=AQBUlxxiSSHyCRAARXCvpSml2Eh5bj/eZvX5Kg==,noatime,_netdev 0 2

- _netdev参数,表示当系统联网后再进行挂载操作,以免系统开机时间过长或开机失败
- noatime 可以显著提高文件系统的性能。默认情况下,Linux ext2/ext3
文件系统在文件被访问、创建、修改等的时候记录下了文件的一些时间戳,比如:文件创建时间、最近一次修改时间和最近一次访问时间。因为系统运行的时候要访
问大量文件,如果能减少一些动作(比如减少时间戳的记录次数等)将会显著提高磁盘 IO 的效率、提升文件系统的性能。Linux 提供了
noatime 这个参数来禁止记录最近一次访问时间戳。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/75695.html

