
Java容器整体框架
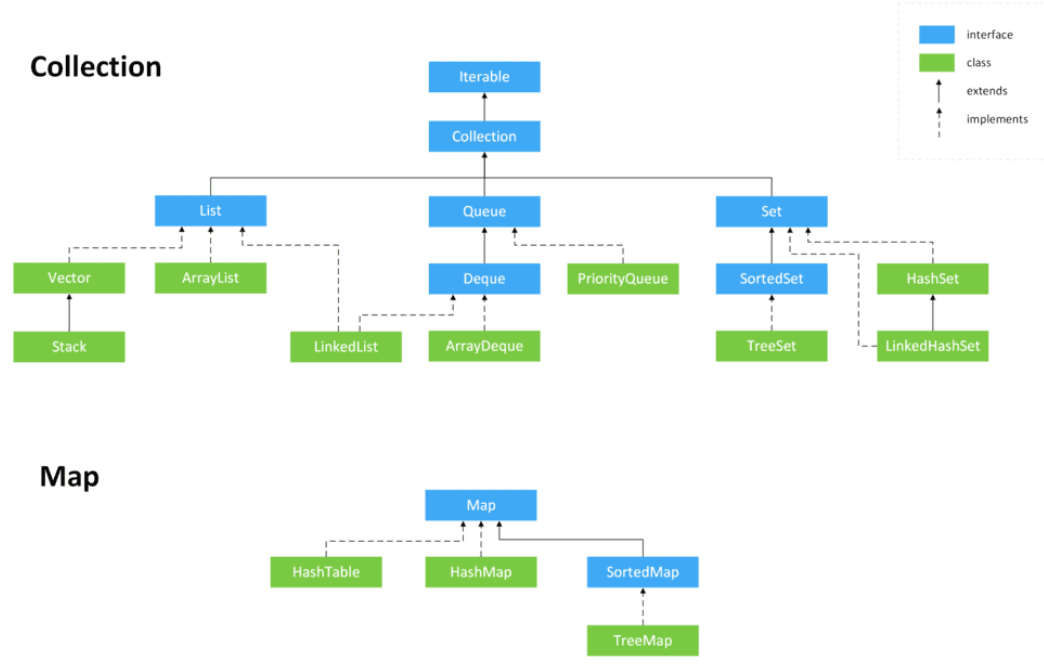 Java容器主要分两大“派系”,Collection接口和Map接口
Java容器主要分两大“派系”,Collection接口和Map接口
Collection接口存放单一元素;Map接口存放key-value键值对形式元素
1.Collection
定义的常用方法详见GitHub笔记仓库(Java高级.md)
继承于Iterable接口,所以Collection接口的实现类可以通过调用对象名.iterator() 获取一个迭代器
Iterator接口 VS Iterable接口
Iterable接口位于java.lang包下,声明的方法如下
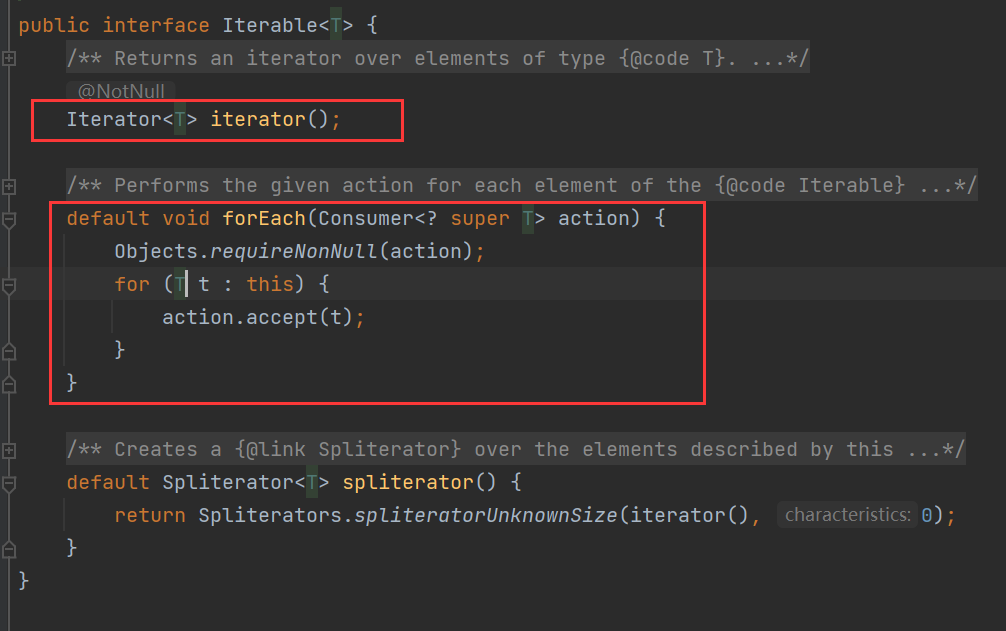 用于约束一个类“是否可迭代”,只要实现了Iterable接口,就可以获取迭代器
用于约束一个类“是否可迭代”,只要实现了Iterable接口,就可以获取迭代器
Iterator接口位于java.util包下,声明方法如下
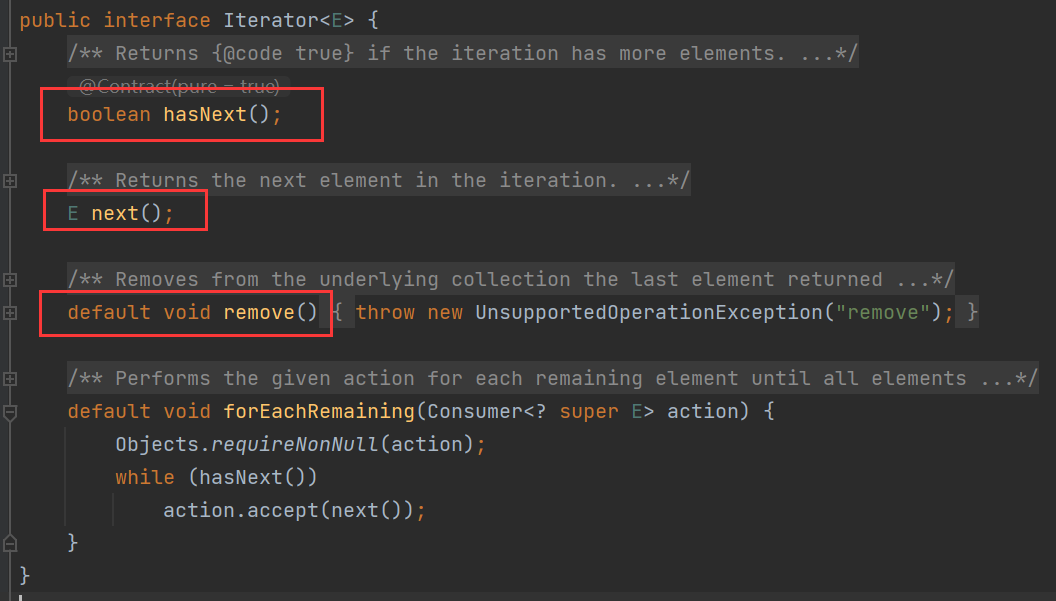 用于声明迭代器内部应该有哪些操作
用于声明迭代器内部应该有哪些操作
为什么要实现Iterable接口,而不是直接实现Iterator接口?
因为Iterator接口的核心方法next()或者hasNext() 是依赖于迭代器的当前迭代位置的。 如果Collection直接实现Iterator接口,势必导致集合对象中包含当前迭代位置的数据(指针)。 当集合在不同方法间被传递时,由于当前迭代位置不可预知,那么next()方法的结果会变成不可预知。 除非再为Iterator接口添加一个reset()方法,用来重置当前迭代位置。 但即使这样,Collection也只能同时存在一个当前迭代位置。 而Iterable每次调用都会返回一个从头开始计数的迭代器。 多个迭代器是互不干扰的。
Collection接口派生出三个子接口:List接口、Queue接口、Set接口
1.1 List接口
List定义的集合元素有序且可以重复,有三个实现类ArrayList、LinkedList、Vector(不常用)
-
ArrayList底层用Object数组实现,可以根据索引查询元素
线程不安全
增、删操作时间复杂度O(N),返回某个下标元素时间复杂度O(1);适用于频繁的查找工作
jdk7 实例化ArrayList时默认创建一个长度为10的数组;jdk8之后,实例化ArrayList时不会创建长度为10的数组而是初始化为空集合{},第一次add元素时才会创建数组。
ArrayList的扩容机制
(ArrayList每次扩容会变为原容量的1.5倍;当需要添加大量元素时,先调用扩容方法,再添加元素) -
LinkedList底层用双向链表实现,只能根据元素自身查询
线程不安全
增、删操作时间复杂度O(1),查询某个元素时间复杂度O(n)
每个元素相当于一个结点,除了维护自身值,还需维护两个指向前驱和后继结点的指针 -
Vector底层用Object数组实现,是List接口的古老实现类,已经不常用
线程安全
1.2 Set接口
Set接口定义元素无序(不是随机,而是根据元素计算出哈希值进行存储)且不可重复
-
HashSet底层用HashMap实现,元素作为key,Object对象作为value
线程不安全
无序、唯一 -
LinkedHashSet底层用LinkedHashMap实现,是HashSet的子类
线程不安全
无序、唯一 -
TreeSet是SortedSet接口的实现类,底层用TreeMap实现,可以进行自然排序或定制排序
线程不安全
有序、唯一
1.3 Queue接口
单端队列,遵循FIFO原则,只能在头部删除元素、在尾部增加元素
根据增删操作失败后处理方式不同,分成两类方法
| 操作 | 抛出异常 | 返回特殊值 |
|---|---|---|
| 插入队首 | add(E e) | offer(E e) |
| 删除队尾 | remove() | poll() |
| 查询队首 | element() | peek() |
-
PriorityQueue 优先队列(元素出队顺序和优先级有关),一般用来实现小顶堆的数据结构,也可以在实例化时传入Comparator参数进行自定义元素优先级
线程不安全
不能插入null值或不能比较优先级的元素
插入、删除元素的时间复杂度O(logN) (由于需要维持堆结构,涉及部分元素的上浮、下沉) -
Deque接口扩展了Queue接口,双端队列,增加了插入队首、删除队尾等方法
操作 抛出异常 返回特殊值 插入队首 addFirst(E e) offerFirst(E e) 插入队尾 addLast(E e) offerLast(E e) 删除队首 removeFirst() pollFirst() 删除队尾 removeLast() pollLast() 查询队首 getFirst() peekFirst() 查询队尾 getLast() peekLast() 另外,Deque还声明了push、pop方法,可以用来模拟栈 ArrayDeque和LinkedList都是Deque接口的实现类
2.Map
以key-value形式存储元素,派生出一个子接口SortedMap和两个实现类HashMap、Hashtable
2.1 HashMap
- jdk1.7 底层由数组+链表;jdk1.8 底层由数组+链表+红黑树
链表是为了解决哈希冲突而生 - key必须唯一,value不一定唯一;key、value允许为null
- 线程不安全,可能出现死锁问题,但是效率高
在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。 - 初始化时默认大小为16,如果传入了初始参数,会将参数扩充成2的幂级数

 关于tableSizeFor的理解
关于tableSizeFor的理解 - 当集合中元素数量大于阈值threshold(capacity*loadFactor),进行扩容操作,容量变为原来的2倍
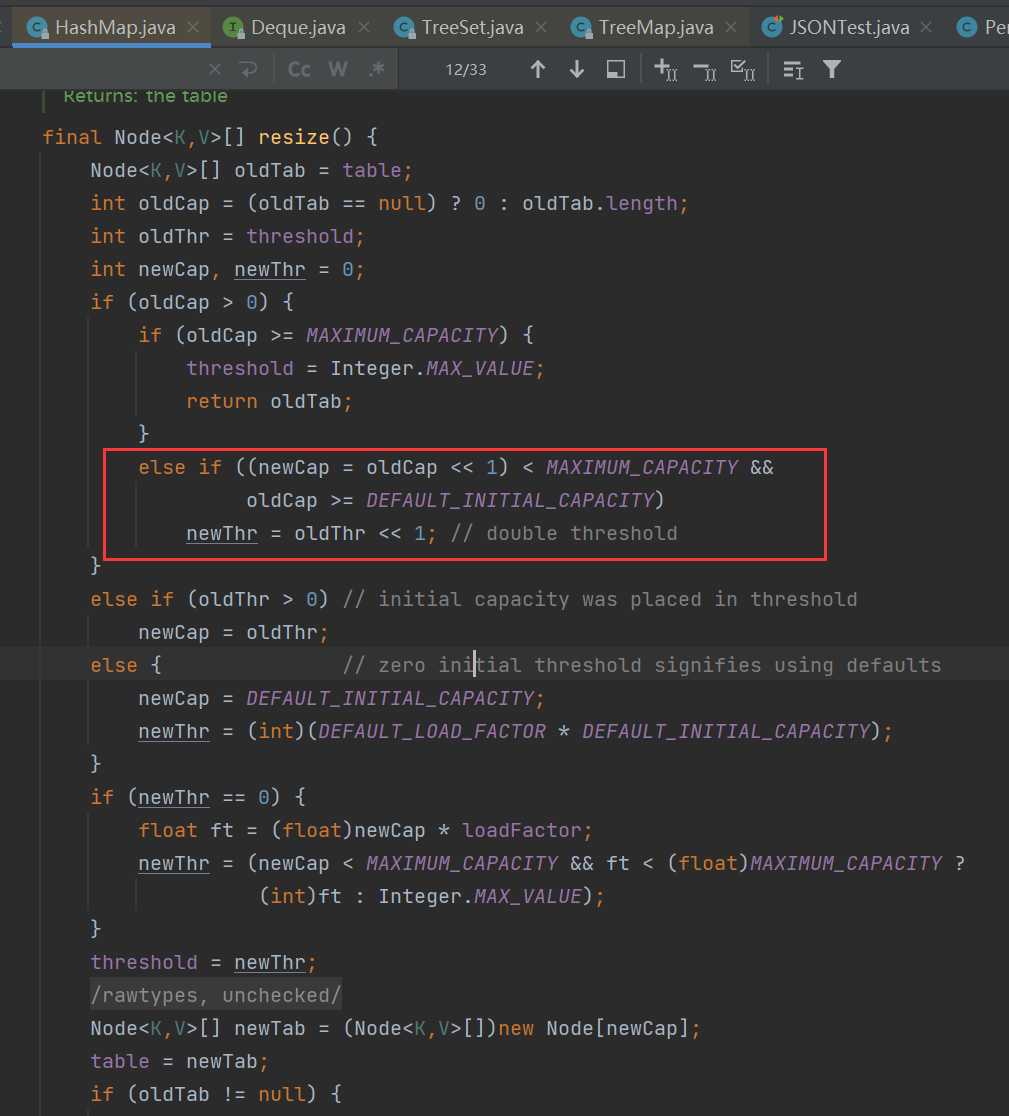
- 根据key的哈希值决定元素的存储位置
- HashMap的七种遍历
2.2 Hashtable
- 线程安全,定义大量的同步方法(synchronized修饰方法),造成效率极低,很少使用。如果要避免HashMap死锁,可以使用ConcurrentHashMap,将可能出现线程安全问题的代码用同步代码块包起来,而不是像Hashtable直接将整个方法定义成同步方法
- key、value不允许为null,会抛出异常
2.3 TreeMap
- SortedMap接口的实现类,拥有根据元素键值进行排序的能力。默认按key升序排序,也可以进行定制排序
- 还实现了Navigable接口,拥有在集合内搜索元素的能力
- 线程不安全
- key不允许为null,value可以为null
2.4 ConcurrentHashMap
初始化
jdk1.7 和HashMap类似,调用空参构造器默认大小是16;若传入指定的size,则初始大小为大于等于size的2的幂次方
jdk1.8 调用空参构造器默认大小是16;若传入指定的size,无论size是否为2的幂次方,都要扩大为最接近且大于size的2的幂次方
注意:无论调用哪种哪个构造器,都不会立即初始化map,等到第一次添加元素时才会初始化
 参数sizeCtl的含义
参数sizeCtl的含义
- 为0,代表数组未初始化,初始大小为16
-
0,如果数组未初始化,则其记录的是传入的初始大小;如果已经初始化,则其记录的是扩容阈值(当前容量*负载因子)
- 为-1,代表数组正在初始化
- < -1,代表数组正在扩容,-(1+n)表示此时有n个线程正在进行扩容操作
3. Collections工具类
4. 面试题
4.1 ArrayList和LinkedList的区别?
4.2 HashSet如何检查元素重复?
4.3 HashMap底层实现原理?
4.4 如何避免HashMap死锁?
4.5 为什么ConcurrentHashMap比Hashtable高效?
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/75099.html

