
一、HashMap 的数据结构
JDK1.8 之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。
HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n – 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
得到的 hashCode 将高16位无符号右移16位与低十六位做异或运算。
如果不这样做,而是直接做& 运算那么高十六位所代表的部分特征就可能被丢失 将高十六位无符号右移之后与低十六位做异或运算使得高十六位的特征与低十六位的特征进行了混合得到的新的数值中就高位与低位的信息都被保留了 ,而在这里采用异或运算而不采用&,|运算的原因是 异或运算能更好的保留各部分的特征,如果采用 &运算计算出来的值会向1靠拢,采用 |运算计算出来的值会向0 靠拢。
对比一下 JDK1.7 的 HashMap 的 hash 方法源码
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
JDK1.8之后
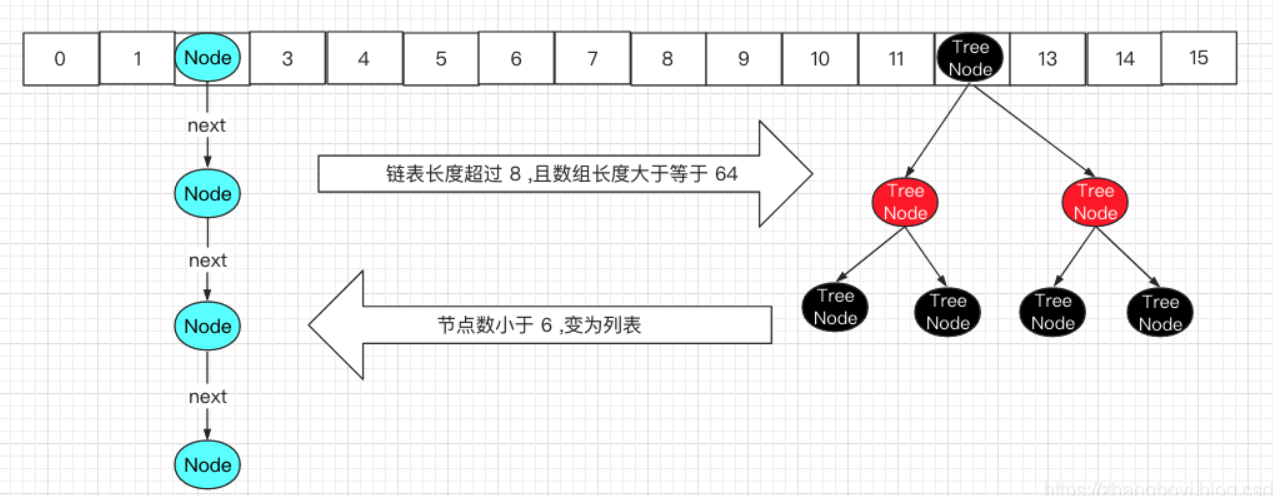
JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。

二、为什么 HashMap 的长度是 2 的 N 次方
长度是 2 的 N 次方主要是为了减少碰撞。
看了很多资料都是说数组下标的计算可以会想到取余(%)。“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1) 的前提是 length 是 2 的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
实际上为什么要选择取余我也不太懂,以下是 2 的 N次方能减少碰撞的原因:
我们假设数组长度为奇数:那么参与(n - 1) & hash运算的肯定就是偶数,偶数的二进制最后后一个低位肯定是 0,0 做完 & 与那算得到的肯定也是 0 ,那意味着 & 完后的到的数的最低位一定是 0 ,最低位是 0 那说明一定是一个偶数,换句话说就是:& 完得到的数一定是一个偶数,所以&完取到的下标永远都是偶数位,会导致奇数位的下标永远没有值,有一半的空间浪费了。
我们假设数组长度为偶数:比如6,那么参与(n - 1) & hash运算就是5,5 的二进制是 101 ,发现任何一个数 & 上 5 ,倒数第二低位永远是 0 最起码肯定得不出2或者3,意味着 2 和 3 的下标位置肯定不会有值。
所以不是2的次幂的话,不管是奇数还是偶数,会导致某些下标没有值,进而增加了碰撞。
我们假设数组的长度是2的次幂:
比如 8 ,那么参与(n - 1) & hash运算就是 7 ,7的二进制是 111 ,任何数都能 &1 去计算下标位置
比如 16,那么参与(n - 1) & hash运算就是 15, 15 的二进制是 1111 ,任何数都能 &1 去计算下标位置
比如 32,那么参与(n - 1) & hash运算就是 31, 31 的二进制是 11111 ,任何数都能 &1 去计算下标位置
比如 64,那么参与(n - 1) & hash运算就是 63, 63 的二进制是 111111 ,任何数都能 &1 去计算下标位置
从上面得知,2的次幂能最大程度上减少碰撞,让值分散在数组中,提高获取的效率。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由半码博客整理,本文链接:https://www.bmabk.com/index.php/post/68391.html

