
要实现根据字母做补全,就必须对文档按照拼音分词。
在GitHub上恰好有elasticsearch的拼音分词插件。
可以参考ik分词器的安装过程
1、查看本机的插件
docker volume ls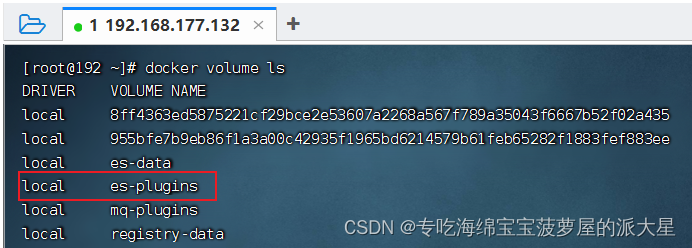

2、查看es-plugins的路径
docker volume inspect es-plugins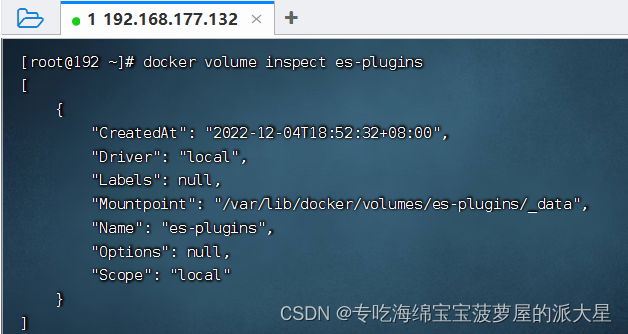
3、进入到插件目录,把提前准备好的拼音分词器的文件,上传到目录
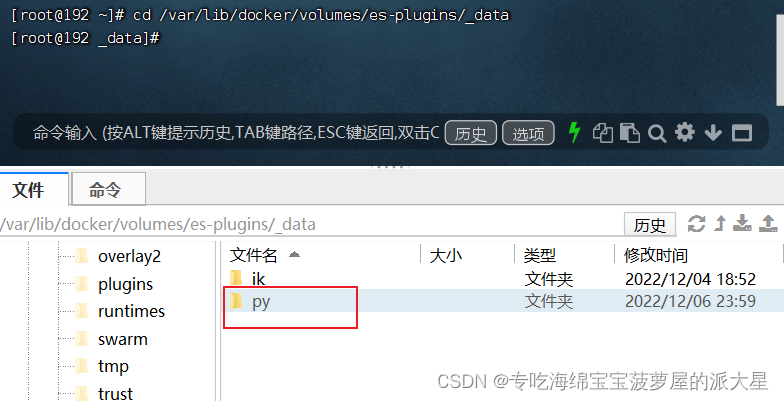
4、重启es
docker restart es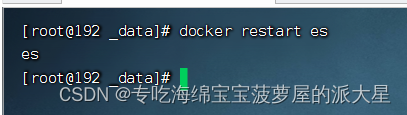
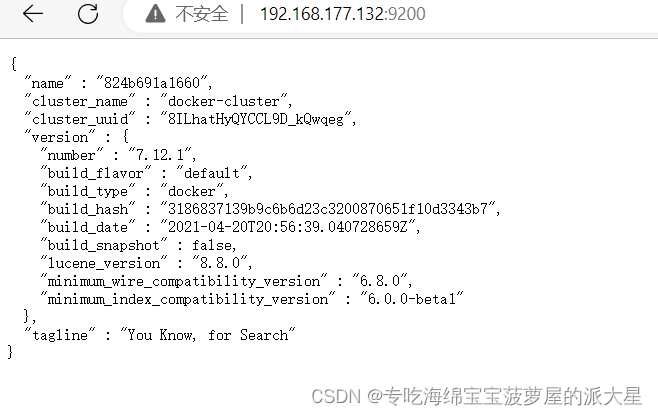
5、测试
输入ip+端口,可以看到json页面,就可以了
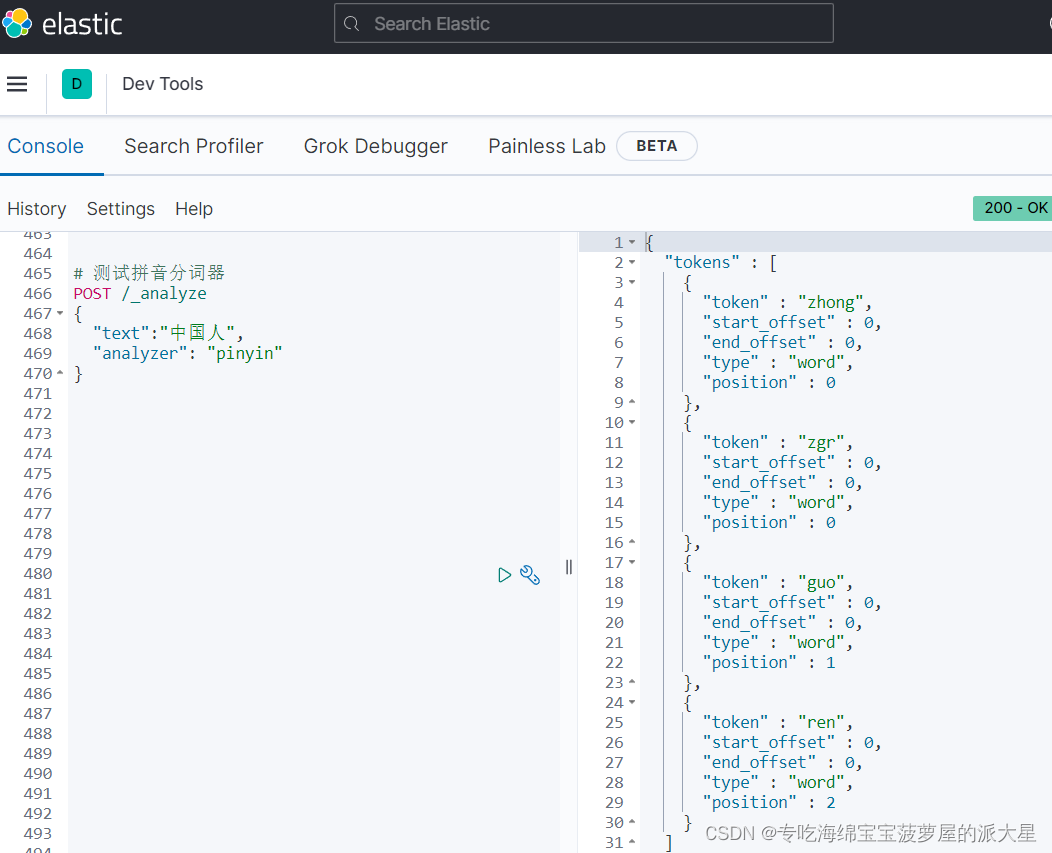
6、效果
# 测试拼音分词器
POST /_analyze
{
"text":"中国人",
"analyzer": "pinyin"
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/65866.html

