
1、预备知识
二叉树
二叉树的递归定义:二叉树是结点的有限集合,它必须满足下面的一个条件:
- 它是空集。
- 它是由一个根结点和根结点的左右子树构成,且其左右子树满足二叉树定义。
形象地讲就是:最多生二孩:)
二叉查找树
二叉查找树(Binary Search Tree),又被称为二叉搜索树。
它是特殊的二叉树:对于二叉树,假设x为二叉树中的任意一个结点,x结点包含关键字key,结点x的key值记为key[x]。如果y是x的左子树中的一个结点,则key[y] ≤ key[x];如果y是x的右子树的一个结点,则 key[x] ≤ key[y]。那么,这棵树就是二叉查找树。
在二叉查找树中:
(01) 若任意结点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(02) 若任意结点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(03) 任意结点的左、右子树也分别为二叉查找树;
(04) 没有键值相等的结点(no duplicate nodes)。
形象地讲就是:左侧键值小一些,右侧大一些。
2-3查找树
一颗2-3查找树或为一颗空树,或由以下结点组成:
- 2-结点,含有一个键(及其对应的值)和两条链接,左链接指向的2-3树中的键都小于该结点,右链接指向的2-3树中的键都大于该结点。
- 3-结点,含有两个键(及其对应的值)和三条链接,左链接指向的2-3树中的键都小于该结点,中链接指向的2-3树中的键都位于该结点的两个键之间,右链接指向的2-3树中的键都大于该结点。
形象地讲就是:最多生仨孩,左侧键值小一些,右侧大一些。
红黑树
涉及到“变色”、“旋转”等调整技巧,太复杂了:)
B树
m阶B树是一颗m叉数,如果B树非空,则相应的增长树满足如下条件:
- 所有外结点在同一层上。
- 除根外的任意内结点至少有
⌈
m
2
⌉
\left \lceil \frac{m}{2} \right \rceil
⌈2m⌉个儿子结点;
- 根结点至少有两个儿子结点。
B+树
m阶B+树是一颗m叉数,如果B+树非空,则满足如下条件:
- 树中每个非叶结点最多有m棵子树;
- 根结点(非叶结点)至少有两棵子树,除根外,所有的非叶结点至少有
⌈
m
2
⌉
\left \lceil \frac{m}{2} \right \rceil
⌈2m⌉棵子树,有n棵子树的非叶结点有n个关键值域;
- 所有的叶结点处于同一层上,包含了全部关键词及指向相应数据对象存放地址的指针,且叶结点本身按关键词从小到大顺序链接;
- 所有的非叶结点可以看做为索引部分,结点中关键词与指向子树的指针构成了对子树的索引项。
同样是依次插入24、29、2、17,生产的B树和B+树如下图(这个网站可以动画演示各种算法):
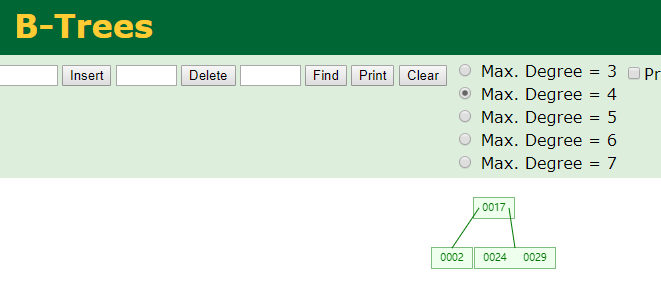
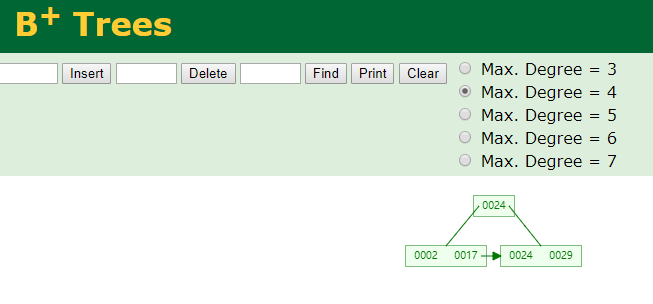
与B-Tree相比,B+Tree有一个显著的特点:
1、所有键值都要出现在叶子结点上,并链在一起。
2、内结点不存储data,只存储key(上图中未展示)。
2、MyISAM索引实现
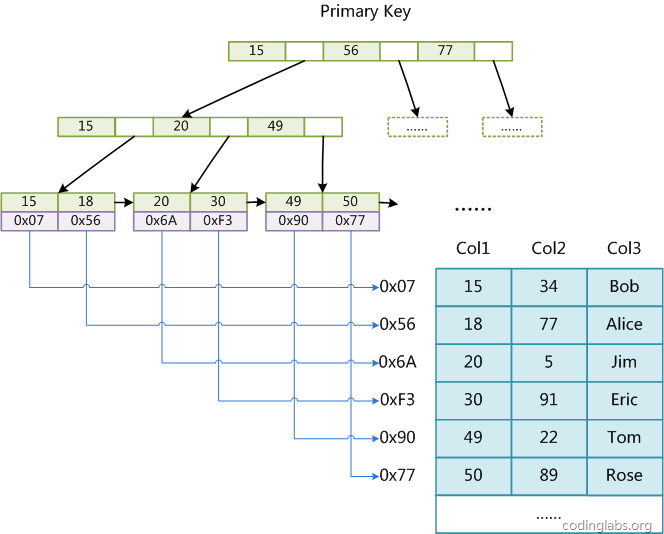
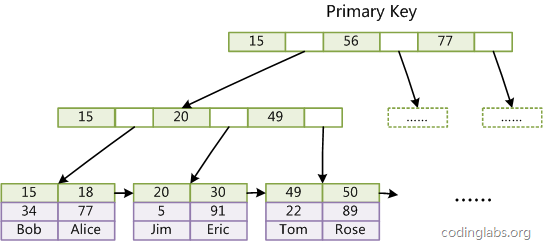
MyISAM引擎使用B+Tree作为索引结构,叶结点的data域存放的是数据记录的地址。下图是MyISAM主索引的原理图:
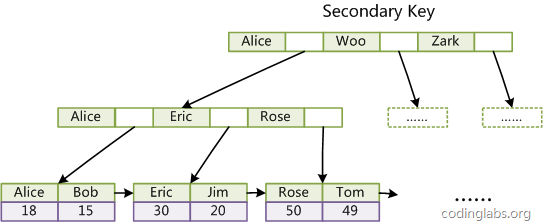
下图是MyISAM辅助索引的原理图:
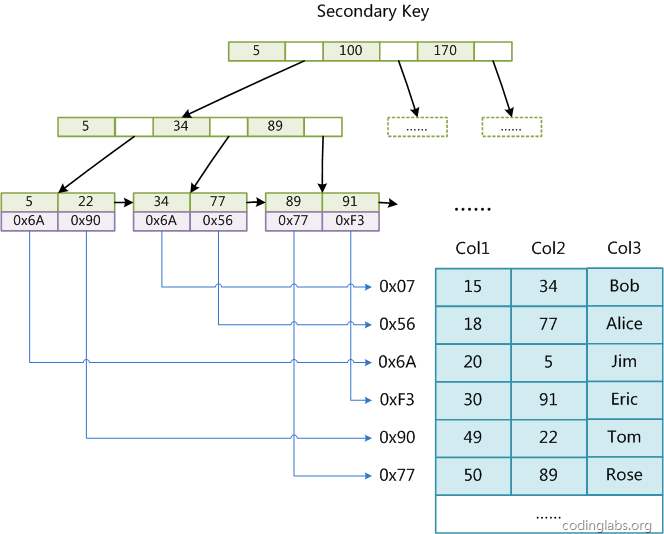
MyISAM的索引方式也叫做“非聚集”的。可以通俗地理解为,叶子结点和数据是分开的,叶子结点仅仅保留了数据的“地址”,没有“腻在一起”。之所以这么称呼是为了与InnoDB的聚集索引区分。
3、InnoDB索引实现
InnoDB主索引的原理图:
叶子结点和完整的数据“腻在一起”,这种索引叫做聚集索引。
顺便说一下,不要把某个二进制列等大数据类型列,例如存储了某人简历的pdf文件,和其他varcha、int等列放在一个表里,应该分成两个表放。否则,索引文件将非常大。试想:叶子结点和完整的数据“腻在一起”,同时手里还拿着一个保险柜,多不协调:)
InnoDB辅助索引的原理图:
叶子结点和“主键”腻在一起,找到主键后,还在再到主索引里查找一遍,才能找到真正的“心上人”。
4、什么时候不建议建索引
一般两种情况下不建议建索引。
第一种情况是表记录比较少,例如一两千条甚至只有几百条记录的表,没必要建索引,让查询做全表扫描就好了。至于多少条记录才算多,这个个人有个人的看法,我个人的经验是以2000作为分界线,记录数不超过 2000可以考虑不建索引,超过2000条可以酌情考虑索引。
另一种不建议建索引的情况是索引的选择性较低。所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:
Index Selectivity = Cardinality / #T
显然选择性的取值范围为(0, 1],选择性越高的索引价值越大,这是由B+Tree的性质决定的。
SELECT count(DISTINCT(title))/count(1) AS Selectivity FROM employees.titles;
+-------------+
| Selectivity |
+-------------+
| 0.0000 |
+-------------+
title的选择性不足0.0001,所以实在没有什么必要为其单独建索引。
对于一些较长的列,有时候可以使用部分长度来建索引,效果几乎一样,如下面的last_name列。
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(1) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.9007 |
+-------------+
5、覆盖索引
Covering index(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)。
6、参考资料
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
这篇文章写的非常好,看这一篇就够了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/17280.html

