
Redis 使用起来很简单,但是在实际应用过程中,一定会碰到一些比较麻烦的问题,常见的问题有
- redis 和数据库数据的一致性
- 缓存雪崩
- 缓存穿透
- 热点数据发现
下面逐一来分析这些问题的原理及解决方案。
数据一致性
针对读多写少的高并发场景,我们可以使用缓存来提升查询速度。当我们使用 Redis 作为缓存的时候,一般流程如下图所示。
- 如果数据在 Redis 存在,应用就可以直接从 Redis 拿到数据,不用访问数据库。
- 如果 Redis 里面没有,先到数据库查询,然后写入到 Redis,再返回给应用。
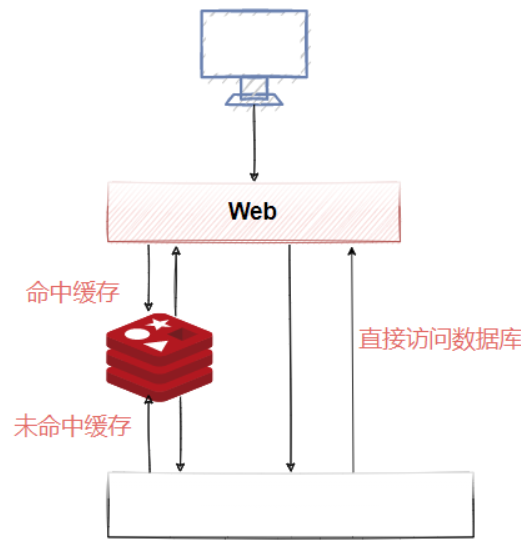

因为这些数据是很少修改的,所以在绝大部分的情况下可以命中缓存。但是,一旦被缓存的数据发生变化的时候,我们既要操作数据库的数据,也要操作 Redis 的数据,所以问题来了。现在我们有两种选择:
- 先操作 Redis 的数据再操作数据库的数据
- 先操作数据库的数据再操作 Redis 的数据
到底选哪一种?
首先需要明确的是,不管选择哪一种方案, 我们肯定是希望两个操作要么都成功,要么都一个都不成功。不然就会发生 Redis 跟数据库的数据不一致的问题。但是,Redis 的数据和数据库的数据是不可能通过事务达到统一的,我们只能根据相应的场景和所需要付出的代价来采取一些措施降低数据不一致的问题出现的概率,在数据一致性和性能之间取得一个权衡。
对于数据库的实时性一致性要求不是特别高的场合,比如 T+1 的报表,可以采用定时任务查询数据库数据同步到 Redis 的方案。由于我们是以数据库的数据为准的,所以给缓存设置一个过期时间,是保证最终一致性的解决方案。
Redis:删除还是更新?
这里我们先要补充一点,当存储的数据发生变化,Redis 的数据也要更新的时候,我们有两种方案,一种就是直接更新,调用 set;还有一种是直接删除缓存,让应用在下次查询的时候重新写入。
这两种方案怎么选择呢?这里我们主要考虑更新缓存的代价。
更新缓存之前,判断是不是要经过其他表的查询、接口调用、计算才能得到最新的数据,而不是直接从数据库拿到的值,如果是的话,建议直接删除缓存,这种方案更加简单,一般情况下也推荐删除缓存方案。
这一点明确之后,现在我们就剩一个问题:
- 到底是先更新数据库,再删除缓存
- 还是先删除缓存,再更新数据库
先更新数据库,再删除缓存
正常情况:更新数据库,成功。删除缓存,成功。
异常情况:
1、更新数据库失败,程序捕获异常,不会走到下一步,所以数据不会出现不一致。
2、更新数据库成功,删除缓存失败。数据库是新数据,缓存是旧数据,发生了不一致的情况。
这种问题怎么解决呢?我们可以提供一个重试的机制。
比如:如果删除缓存失败,我们捕获这个异常,把需要删除的 key 发送到消息队列。然后自己创建一个消费者消费,尝试再次删除这个 key,如下图所示。

另外一种方案,异步更新缓存:
因为更新数据库时会往 binlog 写入日志,所以我们可以通过一个服务来监听 binlog 的变化(比如阿里的 canal),然后在客户端完成删除 key 的操作。如果删除失败的话,再发送到消息队列。
总之,对于后删除缓存失败的情况,我们的做法是不断地重试删除,直到成功。无论是重试还是异步删除,都是最终一致性的思想,具体流程如下图所示。
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。

先删除缓存,再更新数据库
正常情况:删除缓存,成功。更新数据库,成功。
异常情况:
- 删除缓存,程序捕获异常,不会走到下一步,所以数据不会出现不一致。
- 删除缓存成功,更新数据库失败。 因为以数据库的数据为准,所以不存在数据不一致的情况。
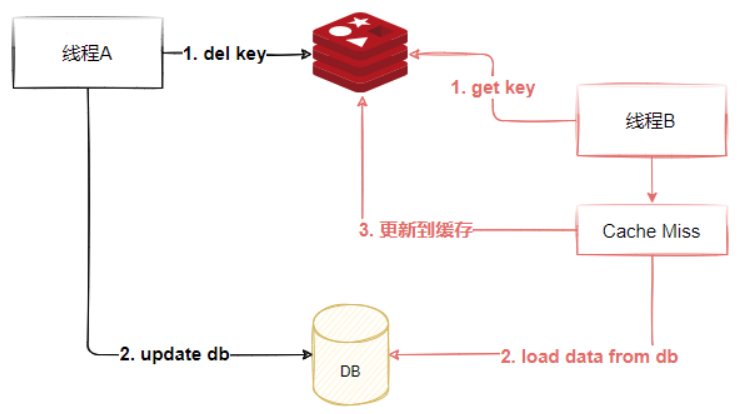
看起来好像没问题,但是如果有程序并发操作的情况下:
- 线程 A 需要更新数据,首先删除了 Redis 缓存
- 线程 B 查询数据,发现缓存不存在,到数据库查询旧值,写入 Redis,返回
- 线程 A 更新了数据库
这个时候,Redis 是旧的值,数据库是新的值,发生了数据不一致的情况,如下图所示,这种情况就比较难处理了,只有针对同一条数据进行串行化访问,才能解决这个问题,但是这种实现起来对性能影响较大,因此一般情况下不会采用这种做法。
缓存雪崩
缓存雪崩就是 Redis 的大量热点数据同时过期(失效),因为设置了相同的过期时间,刚好这个时候 Redis 请求的并发量又很大,就会导致所有的请求落到数据库。
关于缓存过期
在实际开发中,我们经常会使用过期时间,比如限时优惠、缓存、验证码有效期等。一旦过了指定的有效时间就需要自动删除这些数据,否则这些无效数据会一直占用内存但是缺没有任何价值,因此在 Redis 中提供了 Expire 命令设置一个键的过期时间,到期以后 Redis 会自动删除它。这个在我们实际使用过程中用得非常多。
expire key seconds # 设置键在给定秒后过期
pexpire key milliseconds # 设置键在给定毫秒后过期
expireat key timestamp # 到达指定秒数时间戳之后键过期
pexpireat key timestamp # 到达指定毫秒数时间戳之后键过期
EXPIRE 返回值为 1 表示设置成功,0 表示设置失败或者键不存在,如果想知道一个键还有多久时间被删除,可以使用 TTL 命令:
ttl key # 返回键多少秒后过期
pttl key # 返回键多少毫秒后过期
当键不存在时,TTL 命令会返回 – 2,而对于没有给指定键设置过期时间的,通过 TTL 命令会返回 – 1。
除此之外,针对 String 类型的 key 的过期时间,我们还可以通过下面这个方法来设置,其中可选参数 ex 表示设置过期时间。
set key value [ex seconds]
如果想取消键的过期时间设置(使该键恢复成为永久的),可以使用 PERSIST 命令,如果该命令执行成功或者成功清除了过期时间,则返回 1 。 否则返回 0(键不存在或者本身就是永久的):
SET expire.demo 1 ex 20
TTL expire.demo
PERSIST expire.demo
TTL expire
除了 PERSIST 命令,使用 set 命令为键赋值的操作也会导致过期时间失效。
关于 key 过期的实现原理
Redis 使用一个过期字典(Redis 字典使用哈希表实现,可以将字典看作哈希表)存储键的过期时间,字典的键是指向数据库键的指针(使用指针可以避免浪费内存空间),字典的值是一个毫秒时间戳,所以在当前时间戳大于字典值的时候这个键就过期了,就可以对这个键进行删除(删除一个键不仅要删除数据库中的键,也要删除过期字典中的键)。
设置过期时间的命令都是使用 pexpireat 命令实现的,其他命令也会转换成 pexpireat。给一个键设置过期时间,就是将这个键的指针以及给定的到期时间戳添加到过期字典中。比如,执行命令 pexpireat key 1608290696843,那么过期字典结构将如下图所示。

过期键的删除
过期键的删除有两种方法。
-
被动方式删除
被动方式的核心原理是,当客户端尝试访问某个 key 时,发现当前 key 已经过期了,就直接删除这个 key。
当然,有可能会存在一些 key,一直没有客户端访问,就会导致这部分 key 一直占用内存,因此加了一个主动删除方式。
-
主动方式删除
主动删除就是 Redis 定期扫描过期字典中的 key 进行删除,它的删除策略是:
- 从过期键中随机获取 20 个 key,删除这 20 个 key 中已经过期的 key。
- 如果在这 20 个 key 中有超过 25% 的 key 过期,则重新执行当前步骤。实际上这是利用了一种概率算法。
Redis 结合这两种设计很好的解决了过期 key 的处理问题。
如何解决缓存雪崩
了解了过期 key 的删除后,再来分析缓存雪崩问题。缓存雪崩有几个方面的原因导致。
- Redis 的大量热点数据同时过期(失效)
- Redis 服务器出现故障, 这种情况,我们需要考虑到 redis 的高可用集群。
我们来分析第一种情况,这种情况无非就是程序再去查一次数据库,再把数据库中的数据保存到缓存中就行,问题也不大。可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读 / 写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读 / 写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。
解决这类问题的方法有几个。
- 对过期时间增加一个随机值,避免同一时刻大量 key 失效。
- 对于热点数据,不设置过期时间。
- 当从 redis 中获取数据为空时,去数据库查询数据的地方互斥锁,这种方式会造成性能下降。
- 增加二级缓存,一级缓存和二级缓存的过期时间不同,当一级缓存失效后,可以再通过二级缓存获取。
缓存穿透
缓存穿透,一般是指当前访问的数据在 redis 和 mysql 中都不存在的情况,有可能是一次错误的查询,也可能是恶意攻击。
在这种情况下,因为数据库值不存在,所以肯定不会写入 Redis,那么下一次查询相同的 key 的时候,肯定还是会再到数据库查一次。试想一下,如果有人恶意设置大量请求去访问一些不存在的 key,这些请求同样最终会访问到数据库中,有可能导致数据库的压力过大而宕机。
这种情况一般有两种处理方法。
缓存空值
我们可以在数据库缓存一个空字符串,或者缓存一个特殊的字符串,那么在应用里面拿到这个特殊字符串的时候,就知道数据库没有值了,也没有必要再到数据库查询了。
但是这里需要设置一个过期时间,不然当数据库新增了这一条记录,应用也还是拿不到值。
这个是应用重复查询同一个不存在的值的情况,如果应用每一次查询的不存在的值是不一样的呢?即使你每次都缓存特殊字符串也没用,因为它的值不一样,比如我们的用户系统登录的场景,如果是恶意的请求,它每次都生成了一个符合 ID 规则的账号,但是这个账号在我们的数据库是不存在的,那 Redis 就完全失去了作用,因此我们有另外一种方法,布隆过滤器。
布隆过滤器解决缓存穿透
先来了解一下布隆过滤器的原理,
- 首先,项目在启动的时候,把所有的数据加载到布隆过滤器中。
- 然后,当客户端有请求过来时,先到布隆过滤器中查询一下当前访问的 key 是否存在,如果布隆过滤器中没有该 key,则不需要去数据库查询直接反馈即可

下面我们通过一个案例来演示一下布隆过滤器的工作机制。
项目地址在文末,注意,该案例是在 [springboot-redis-1] 这个工程中进行演示。
-
添加 guava 依赖,guava 中提供了布隆过滤器的 api
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>21.0</version> </dependency> -
定义常量
public class BloomFilterCache { public static BloomFilter<String> cityBloom; } -
增加一个 ApplicationRunner 实现,当 spring boot 启动完成后执行初始化
@Slf4j @Component public class BloomFilterDataLoadApplicationRunner implements ApplicationRunner { @Autowired ICityService cityService; @Override public void run(ApplicationArguments args) throws Exception { List<City> cityList=cityService.list(); // expectedInsertions: 预计添加的元素个数 // fpp: 误判率 BloomFilter<String> bloomFilter=BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),10000000,0.03); cityList.parallelStream().forEach(city -> { bloomFilter.put(RedisKeyConstants.CITY_KEY+":"+city.getId()); }); BloomFilterCache.cityBloom = bloomFilter; } } -
添加一个 controller 用来访问测试
@RestController public class BloomFilterController { @Autowired RedisTemplate redisTemplate; @GetMapping("/bloom/{id}") public String filter(@PathVariable("id") Integer id) { String key = RedisKeyConstants.CITY_KEY + ":" + id; if (BloomFilterCache.cityBloom.mightContain(key)) { //判断当前数据在布隆过滤器中是否存在,如果存在则从缓存中加载 return redisTemplate.opsForValue().get(key).toString(); } return "数据不存在"; } }
布隆过滤器存储空间大小计算: https://hur.st/bloomfilter/?n=1000000&p=0.03&m=&k=
布隆过滤器原理分析
研究上述代码后,可能很多人都会产生疑问,
- 如果我的数据量有上千万,那不会很占内存啊?
- 布隆过滤器的实现原理是什么呀?
什么是布隆过滤器
布隆过滤器是 Burton Howard Bloom 在 1970 年提出来的,一种空间效率极高的概率型算法和数据结构,主要用来判断一个元素是否在集合中存在。因为他是一个概率型的算法,所以会存在一定的误差,如果传入一个值去布隆过滤器中检索,可能会出现检测存在的结果但是实际上可能是不存在的,但是肯定不会出现实际上不存在然后反馈存在的结果。因此,Bloom Filter 不适合那些 “零错误” 的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter 通过极少的错误换取了存储空间的极大节省
BitMap(位图)
所谓的 Bit-map 就是用一个 bit 位来标记某个元素对应的 Value,通过 Bit 为单位来存储数据,可以大大节省存储空间.
ps: 比特是一个二进制数的最小单元,就像我们现在金额的最小单位是分。只不过比特是二进制数而已,一个比特只能拥有一个值,不是 0 就是 1,所以如果我给你一个值 0,你可以说它就是一个比特,如果我给你两个(00),你就可以说它们是两个比特了。如果你将八个 0 或者 1 组合在一起,我们可以说说是 8 比特或者 1 个字节。在 32 位的机器上,一个 int 类型的数据会占用 4 个字节,也就是 32 个比特位。
在 java 中,一个 int 类型占 32 个比特,我们用一个 int 数组来表示时未 new int [32], 总计占用内存 32*32bit, 现假如我们用 int 字节码的每一位表示一个数字的话,那么 32 个数字只需要一个 int 类型所占内存空间大小就够了,这样在大数据量的情况下会节省很多内存。
如果要存储 n 个数字,那么具体思路如下。
- 1 个 int 占 4 字节即 4*8=32 位,那么我们只需要申请一个 int 数组长度为 int tmp [1+N/32] 即可存储完这些数据,其中 N 代表要进行查找的总数,tmp 中的每个元素在内存在占 32 位可以对应表示十进制数 0~31, 所以可得到 BitMap 表:
- tmp [0]: 可表示 0~31
- tmp [1]: 可表示 32~63
- tmp [2] 可表示 64~95
- …….
- 接着,我们只需要把对应的数字存储到指定数组元素的 bit 中即可,如何判断 int 数字在 tmp 数组的哪个下标,这个其实可以通过直接除以 32 取整数部分,例如:整数 8 除以 32 取整等于 0,那么 8 就在 tmp [0] 上。另外,我们如何知道了 8 在 tmp [0] 中的 32 个位中的哪个位,这种情况直接 mod 上 32 就 ok,又如整数 8,在 tmp [0] 中的
8 mod 32等于 8,那么整数 8 就在 tmp [0] 中的第八个 bit 位(从右边数起)
比如我们要存储 5**(101)、9(1001)、3(11)、1(1)** 四个数字,那么我们申请 int 型的内存空间,会有 32 个比特位。这四个数字的二进制分别对应如下。
从右往左开始数,比如第一个数字是 5,对应的二进制数据是 101, 那么从右往左数到第 5 位,把对应的二进制数据存储到 32 个比特位上。
第一个5就是 00000000000000000000000000101000
输入9的时候 00000000000000000000001001000000
输入3的时候 00000000000000000000000000001100
输入1的时候 00000000000000000000000000000010
思想比较简单,关键是十进制和二进制 bit 位需要一个 map 映射表,把 10 进制映射到 bit 位上,这样的好处是内存占用少、效率很高(不需要比较和位移)。
布隆过滤器原理
有了对位图的理解以后,我们对布隆过滤器的原理理解就会更容易了,基于前面的例子,我们把数据库中的一张表的数据全部先保存到布隆过滤器中,用来判断当前访问的 key 是否存在于数据库。
假设我们需要把 id=1 这个 key 保存到布隆过滤器中,并且该布隆过滤器中的 hash 函数个数为 3{x、y、z},它的具体实现原理如下:
- 首先将位数组进行初始化,将里面每个位都设置位 0。
- 对于集合里面的每一个元素,将元素依次通过 3 个哈希函数{x、y、z}进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为 1。
- 查询
id=1元素是否存在集合中的时候,同样的方法将 W 通过哈希映射到位数组上的 3 个点。- 如果 3 个点的其中有一个点不为 1,则可以判断该元素一定不存在集合中。
- 反之,如果 3 个点都为 1,则该元素可能存在集合中。

接下来按照该方法处理所有的输入对象,每个对象都可能把 bitMap 中一些白位置涂黑,也可能会遇到已经涂黑的位置,遇到已经为黑的让他继续为黑即可。处理完所有的输入对象之后,在 bitMap 中可能已经有相当多的位置已经被涂黑。至此,一个布隆过滤器生成完成,这个布隆过滤器代表之前所有输入对象组成的集合。
如何去判断一个元素是否存在 bit array 中呢? 原理是一样,根据 k 个哈希函数去得到的结果,如果所有的结果都是 1,表示这个元素可能(假设某个元素通过映射对应下标为 4,5,6 这 3 个点。虽然这 3 个点都为 1,但是很明显这 3 个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是 1)存在。 如果一旦发现其中一个比特位的元素是 0,表示这个元素一定不存在
至于 k 个哈希函数的取值为多少,能够最大化的降低错误率(因为哈希函数越多,映射冲突会越少),这个地方就会涉及到最优的哈希函数个数的一个算法逻辑。
- fpp 表示允许的错误概率
- expectedInsertions: 预期插入的数量
public static void main(String[] args) {
BloomFilter<String> bloomFilter=BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),10000000,0.03);
bloomFilter.put("chen");
System.out.println(bloomFilter.mightContain("chen"));
}
项目地址
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由半码博客整理,本文链接:https://www.bmabk.com/index.php/post/16808.html

