
大家好,我是百思不得小赵。
创作时间:2022 年 5 月 31 日
博客主页: 🔍点此进入博客主页
—— 新时代的农民工 🙊
—— 换一种思维逻辑去看待这个世界 👀
今天是加入CSDN的第1186天。觉得有帮助麻烦👏点赞、🍀评论、❤️收藏
容错机制
Flink 故障恢复机制的核心,就是应用状态的一致性检查点,有状态流应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时刻。在执行流应用程序期间,Flink 会定期保存状态的一致检查点,如果发生故障, Flink 将会使用最近的检查点来一致恢复应用程序的状态,并。重新启动处理流程。
恢复数据步骤:
- 重启应用
- 从 checkpoint 中读取状态,将状态重置
- 开始消费并处理检查点到发生故障之间的所有数据
Flink 还提供了可以自定义的镜像保存功能,就是保存点,Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地触发创建操作,保存点是一个强大的功能。除了故障恢复外,保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停和重启应用等。
检查点配置代码案例:
public class Test{
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 检查点的配置
// 开启检查点周期为毫秒
env.enableCheckpointing(300);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 设置最大执行的checkp个数
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
// 设置最小的间歇时间,两个checkpoint之间,前一次完成到后一次开始之间的间歇不能小于XXX
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(100);
//env.getCheckpointConfig().setPreferCheckpointForRecovery();
// 容忍checkpoint失败多少次
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);
// 重启策略的配置
// 固定延时重启 每隔10秒进行一次重启尝试重启三次
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,10000L));
// 失败率重启 在10分钟内统计重启,在10分钟内尝试三次重启,每次隔1分钟重启一次
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.minutes(10),Time.minutes(1)));
DataStreamSource<String> inputStream = env.socketTextStream("localhost", 7777);
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
env.execute();
}
}
状态一致性
有状态的流处理,内部每个算子任务都可以有自己的状态,对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确,一条数据不应该丢失,也不应该重复计算,在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
状态一致性分类:
- AT-MOST-ONCE(最多一次)
当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重播丢失的数据。At-most-once 语义的含义是最多处理一次事件。 - AT-LEAST-ONCE(至少一次)
在大多数的真实应用场景,我们希望不丢失事件。这种类型的保障称为 atleast-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次。 - EXACTLY-ONCE(精确一次)
恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。
Flink源码提供了一个枚举类进行相关配置:
@Public
public enum CheckpointingMode {
/**
* Sets the checkpointing mode to "exactly once". This mode means that the system will
* checkpoint the operator and user function state in such a way that, upon recovery,
* every record will be reflected exactly once in the operator state.
*
* <p>For example, if a user function counts the number of elements in a stream,
* this number will consistently be equal to the number of actual elements in the stream,
* regardless of failures and recovery.</p>
*
* <p>Note that this does not mean that each record flows through the streaming data flow
* only once. It means that upon recovery, the state of operators/functions is restored such
* that the resumed data streams pick up exactly at after the last modification to the state.</p>
*
* <p>Note that this mode does not guarantee exactly-once behavior in the interaction with
* external systems (only state in Flink's operators and user functions). The reason for that
* is that a certain level of "collaboration" is required between two systems to achieve
* exactly-once guarantees. However, for certain systems, connectors can be written that facilitate
* this collaboration.</p>
*
* <p>This mode sustains high throughput. Depending on the data flow graph and operations,
* this mode may increase the record latency, because operators need to align their input
* streams, in order to create a consistent snapshot point. The latency increase for simple
* dataflows (no repartitioning) is negligible. For simple dataflows with repartitioning, the average
* latency remains small, but the slowest records typically have an increased latency.</p>
*/
EXACTLY_ONCE,
/**
* Sets the checkpointing mode to "at least once". This mode means that the system will
* checkpoint the operator and user function state in a simpler way. Upon failure and recovery,
* some records may be reflected multiple times in the operator state.
*
* <p>For example, if a user function counts the number of elements in a stream,
* this number will equal to, or larger, than the actual number of elements in the stream,
* in the presence of failure and recovery.</p>
*
* <p>This mode has minimal impact on latency and may be preferable in very-low latency
* scenarios, where a sustained very-low latency (such as few milliseconds) is needed,
* and where occasional duplicate messages (on recovery) do not matter.</p>
*/
AT_LEAST_ONCE
}
端到端状态一致性
目前我们接触的一致性保证都是Flink 流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统。
- flink内部保证:依赖 checkpoint
- source 端:需要外部源可重设数据的读取位置
- sink 端:需要保证从故障恢复时,数据不会重复写入外部系统。两种方式:幂等写入、事务写入。
不同 Source 和 Sink 的一致性保证
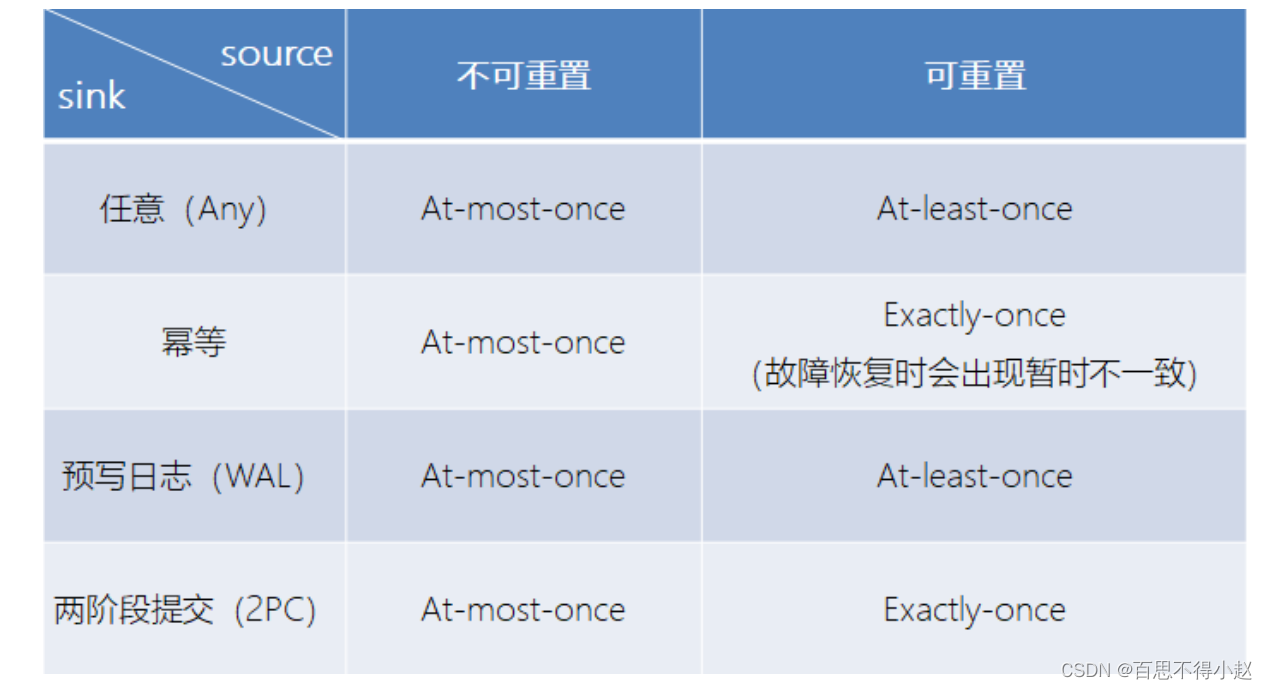

(此图来源于网络)

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由半码博客整理,本文链接:https://www.bmabk.com/index.php/post/144882.html

