
1、概要
JMM全称叫Java Memory Model(Java内存模型),什么是JMM,为什么要设置JMM,要弄清楚这个,咱们要先从计算机硬件存储体系说起。
2、计算机硬件存储体系

window和mac是两种不同的操作系统,但是从上图可以看出都有内存、缓存。咱们都知道CPU的运算速度是最快了,为了解决CPU和内存之间的运算速度不对等问题,在CPU和内存之间增加了一层缓存。再比如现实开发的需求,商品秒杀,库存是存储在DB中的,每次从DB中拿取库存并修改是非常耗时的,为了解决此问题我们需要在DB和用户之间增加一层或者多级缓存。这就是操作系统的内存模型。
3、JMM
Java应用程序需要跑在不同的操作系统上,那就要准守操作系统的内存模型规则。虽然Java是可以直接复用操作系统层面内存模型的,但是不同的操作系统内存模型不同。如果直接复用操作系统层面的内存模型,就可能会导致同样一套代码换了一个操作系统就无法执行了。因为Java 语言是跨平台的,所以JVM规范试图定义一种Java内存模型(JMM)来屏蔽各种硬件和操作系统的内存访问模型,这就是JMM设计的初衷。
JMM本身是一种抽象的概念并不真实存在,它仅仅描述的是一组约定或者规范,通过这组规范定义了程序中(尤其是多线程)各个变量的读写访问方式,并决定一个线程对共享变量的写入以及如何变成对另一个线程可见,关键技术点都是围绕多线程的原子性、可见性和有序性这三大特性展开的。
那JMM到底能干嘛呢?
①、通过JMM来实现线程和主内存之间的抽象概念
②、屏蔽各个硬件平台和操作系统的内存访问差异以实现让Java程序在各种平台下都能达到一致的内存访问效果
4、JMM三大特性
4.1、可见性
是指当一个线程修改了某一个共享变量,其他线程是否能够立即知道该变更,JMM规定了所有的变量都存储在主内存中。每个线程都有一个本地内存(共享变量副本)。线程获取共享变量的顺序:先是从判断本地内存获取,如果没有则取主内存获取并存储在本地内存中。线程修改共享变量顺序:先是修改本地内存,然后将本地内存同步到主内存(时间未知)
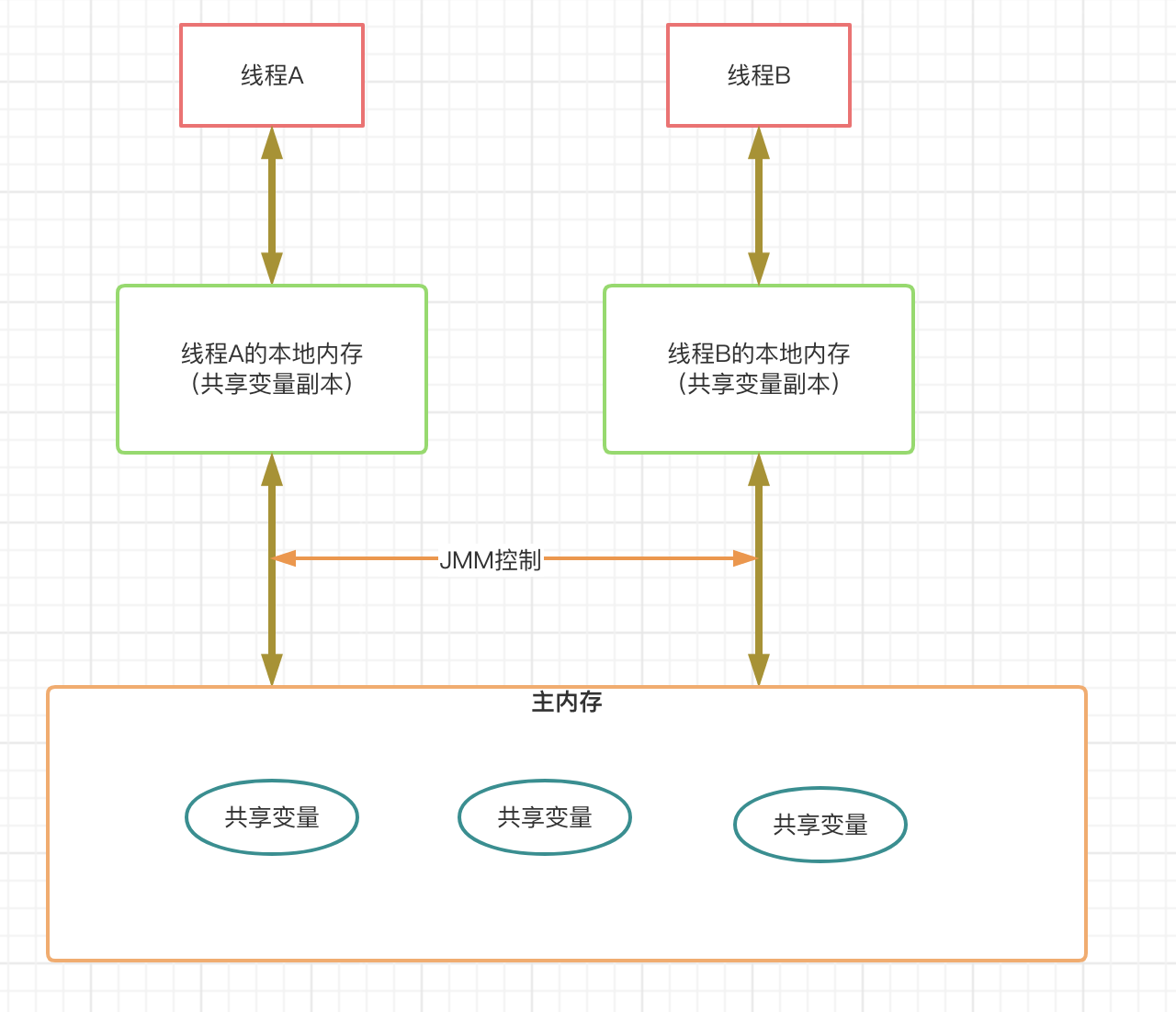
由于系统主内存共享变量修改被写入的时机是不确定的,多线程并发下很可能出现”脏读“(读取的数据不是最新的),所以每个线程都有自己的本地内存,线程自己的工作内存中保存了该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在自己的本地内存中进行,而不能直接读写主内存中的变量。不同线程之间也无法直接访问对方本地内存中的变量,线程间变量值的传递均需要通过主内存完成。
4.2、原子性
对于同一个操作中的多个执行,要么全部执行成功要么全部执行失败。
在 Java 中,可以借助synchronized 、各种 Lock 以及各种原子类实现原子性。
synchronized 和各种 Lock 可以保证任一时刻只有一个线程访问该代码块,因此可以保证原子性。各种原子类是利用 CAS (compare and swap) 操作(可能也会用到 volatile或者final关键字)来保证原子操作。
4.3、有序性
对于一个线程的执行代码而言,我们总是习惯性认为代码的执行总是从上到下,有序执行。但是为了提升性能,编译器和处理器通常会对指定序列进行重新排序。Java规范规定JVM线程内部维持顺序化语义,即只要程序最终结果与它顺序化执行的结果相等,那么指令的执行顺序可以域代码顺序不一致,此过程叫做指令重排序。
那指令重排序的优缺点是什么呢?
JVM能根据处理器特性适当的对机器指令进行重排序,使机器指令更符合CPU的执行特性,最大限度的发挥机器性能。
指令重排序可以保证串行(单线程)语义一致,但是没有义务保证多线程访问的语义也一致(即可能产生”脏读“),简单说,两行以上不相干的代码执行的时候有可能先执行的不是第一行,不见得是从上到下顺序执行,执行顺序会被优化。例如以下代码,因为两行代码没有相关性,执行的时候有可能执行第二行而不是第一行。
//第一行
int x = 0;
//第二行
int y = 1;
//第三行
int z = x + y;多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
package com.lc.test03;
/**
* @author liuchao
* @date 2023/4/10
*/
public class Test01 {
int x = 0;
int y = 0;
public static void main(String[] args) {
Test01 test01 = new Test01();
for (int i = 0; i < 5; i++) {
new Thread(() -> {
test01.set();
test01.call();
}, String.format("t-%", i)).start();
}
}
public void set() {
x = 2;
y = 3;
}
public void call() {
if (y == 3) {
System.out.println("----在多线程下由于重排序的存在,输出的X值可能为0:" + x);
}
}
}
5、JMM规范下的变量读取过程
①、定义所有的变量都存储在物理主内存中
②、每个线程都有自己独立的本地内存,里面保存该线程使用到的变量的副本(从主内存拷贝过来的)
③、线程对共享变量的所有操作都必须先在自己的本地内存中进行后再回写到主内存,不能直接操作主内存
④、不同线程之间的本地内存是隔离的,线程间的变量传递需要通过主内存来进行。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由半码博客整理,本文链接:https://www.bmabk.com/index.php/post/144587.html

