
你说你精通Java并发,那给我讲讲J.U.C吧
J.U.C
J.U.C即java.util.concurrent包,为我们提供了很多高性能的并发类,可以说是java并发的核心。
J.U.C和CAS和Unsafe和AQS
Concurrent包下所有类底层都是依靠CAS操作来实现,而sun.misc.Unsafe为我们提供了一系列的CAS操作。
AQS框架是J.U.C中实现锁及同步机制的基础,其底层是通过调用 LockSupport .unpark()和 LockSupport .park()实现线程的阻塞和唤醒。
J.U.C框架
J.U.C的整个框架分为5个部分:tools、locks、collections、executor和atomic。
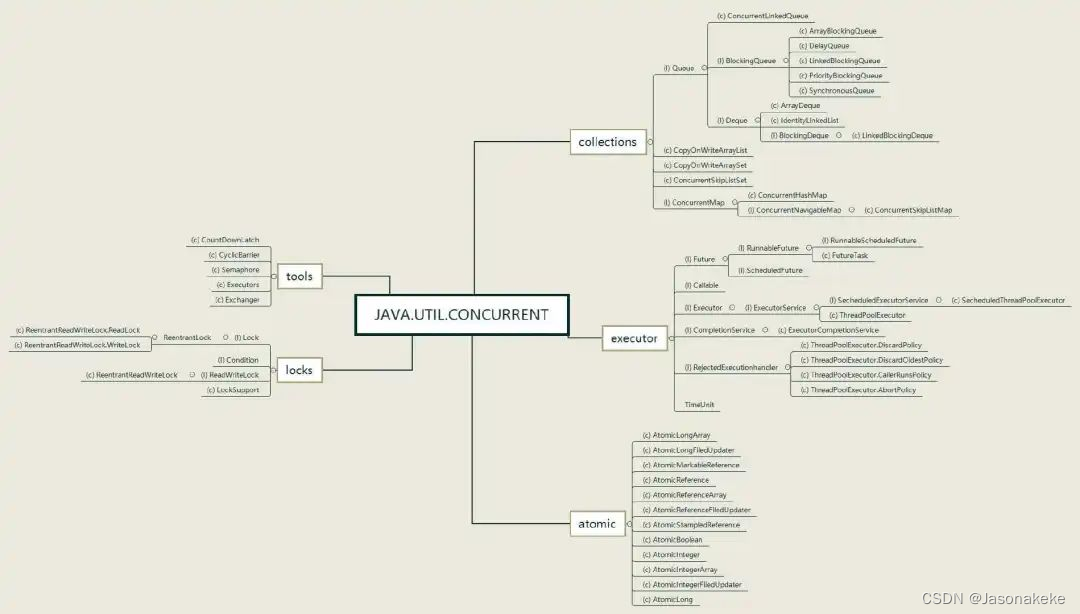

Atomic
该包下主要是一些原子变量类,仅依赖于Unsafe,并且被其他模块所依赖。
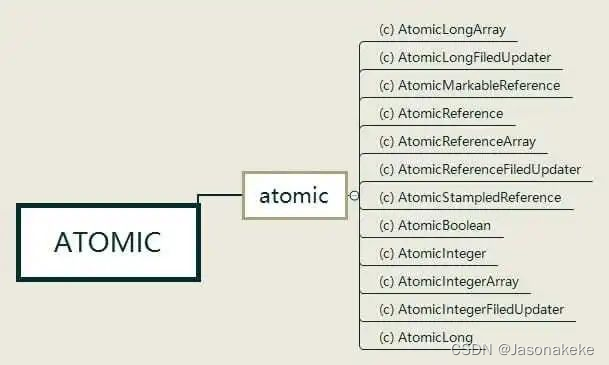
Locks
该包下主要是关于锁及其相关类,仅依赖于Unsafe或内部依赖,并且被其他高级模块所依赖。由于LockSupport类底层逻辑简单且仅依赖Unsafe,同时为其他高级模块所依赖,所以需要先了解LockSupport类的运行原理,然后重点研究AbstractQueuedSynchronizer框架,理解独占锁和共享锁的实现原理,并清楚Condition如何与AbstractQueuedSynchronizer进行协作,最后很容易就能理解ReentrantLock是如何实现的。

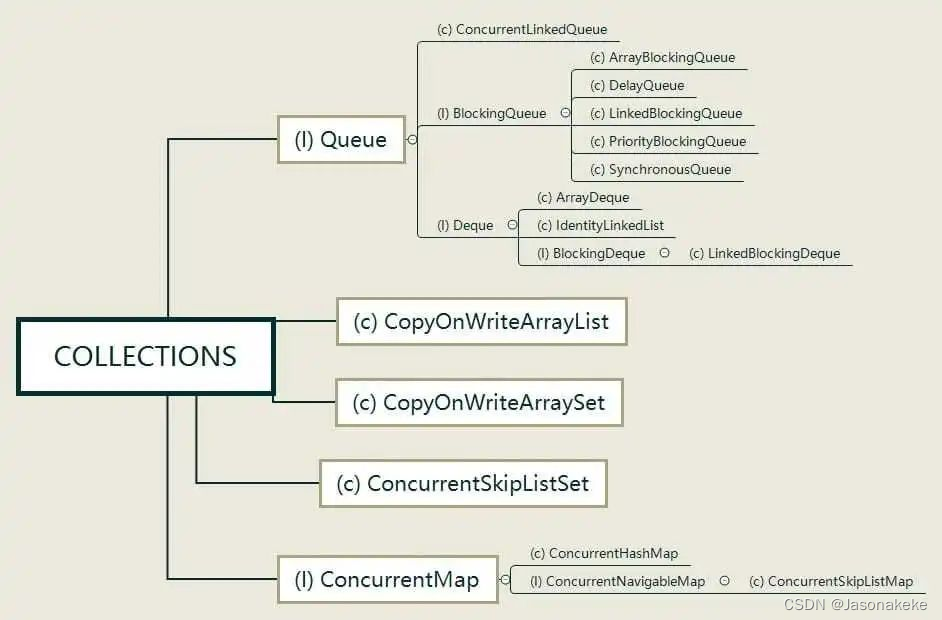
Collections
该包会依赖Unsafe和前两个基础模块,并且模块内部各个容器间相互较为独立,所以没有固定的学习顺序,理解编程中常用的集合类原理即可:ConcurrentHashMap、CopyOnWriteArrayList、CopyOnWriteArraySet、ArrayBlockingQueue、LinkedBlockingQueue(阻塞队列在线程池中有使用,所以理解常用阻塞队列的特性很重要)。
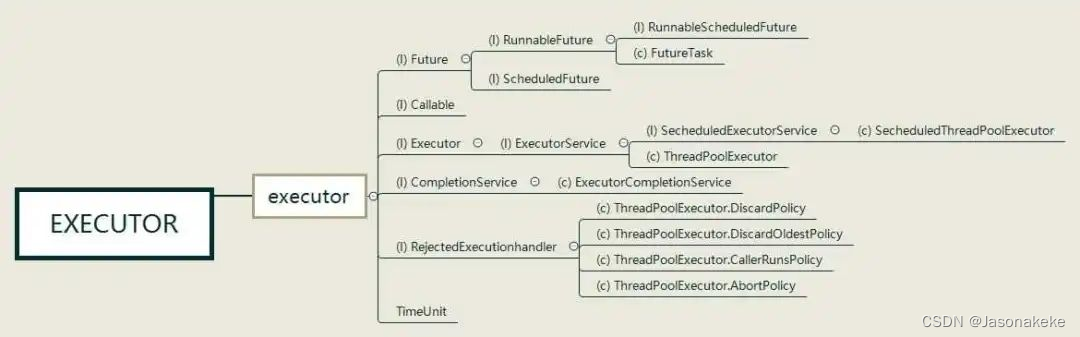
Executor
这一部分的核心是线程池的运行原理,也是实际应用中较多的部分,会依赖于前几个模块。首先了解Callable、Future、RunnableFuture三个接口间的关系以及FutureTask的实现原理,然后研究如何创建ThreadPoolExecutor,如何运行一个任务,如何管理自身的线程,同时了解RejectedExecutionHandler的四种实现差异,最后,在实际应用中学习如何通过调整ThreadPoolExecutor的参数来优化线程池。
Tools
这一部分是以前面几个模块为基础的高级特性模块,实际应用的场景相对较少,主要应用在多线程间相互依赖执行结果场景,没有具体的学习顺序,最好CountDownLatch、CyclicBarrier、Semaphore、Exchanger、Executors都了解下,对后面学习Guava的框架有帮助。
参考:
J.U.C框架学习顺序
CAS与sun.misc.Unsafe
Doug Lea并发编程文章全部译文
J.U.C体系结构(java.util.concurrent)
JAVA并发编程J.U.C学习总结
J.U.C – AQS
可重入锁
ReentrantLock是可重入锁,可重入锁就是当前持有该锁的线程能够多次获取该锁,无需等待。可重入锁是如何实现的呢?这要从ReentrantLock的一个内部类Sync的父类说起,Sync的父类是AbstractQueuedSynchronizer(AQS,抽象队列同步器)。
AQS
AQS是JDK1.5提供的一个基于FIFO等待队列实现的一个用于实现同步器的基础框架,这个基础框架的重要性可以这么说,JCU包里面几乎所有的有关锁、多线程并发以及线程同步器等重要组件的实现都是基于AQS这个框架。AQS的核心思想是基于 volatileintstate这样的一个属性同时配合Unsafe工具对其原子性的操作来实现对当前锁的状态进行修改。当state的值为0的时候,标识该Lock不被任何线程所占有。
ReentrantLock锁的架构
ReentrantLock的架构主要包括一个Sync的内部抽象类以及Sync抽象类的两个实现类。他们的结构示意图如下:
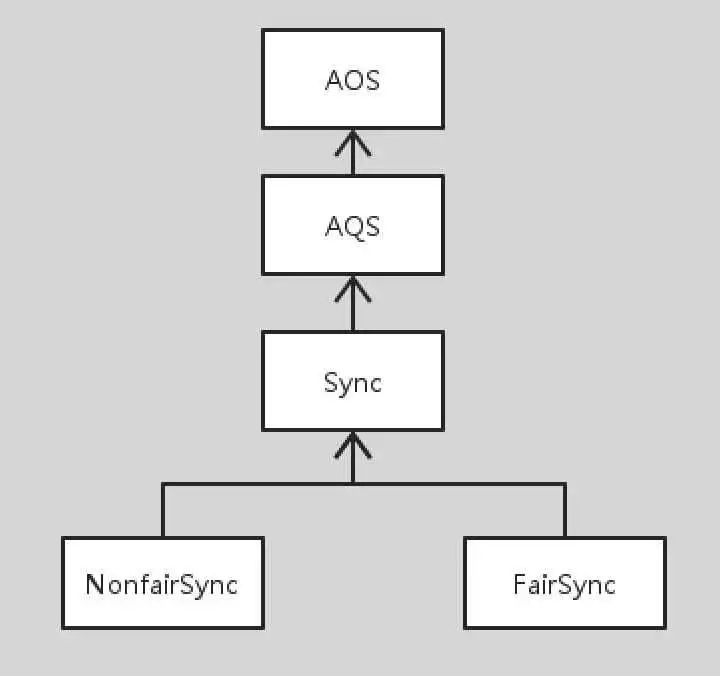
如上图所示,AQS的父类AOS(AbstractOwnableSynchronizer)主要提供一个exclusiveOwnerThread属性,用于关联当前持有该锁的线程。 另外、Sync的两个实现类分别是NonfairSync和FairSync,一个是用于实现公平锁,一个是用于实现非公平锁。那么Sync为什么要被设计成内部类呢?Sync被设计成为安全的外部不可访问的内部类,使得ReentrantLock中所有涉及对AQS的访问都要经过Sync,其实,Sync被设计成为内部类主要是为了安全性考虑,这也是作者在AQS的comments上强调的一点。
AQS框架
总体框架图
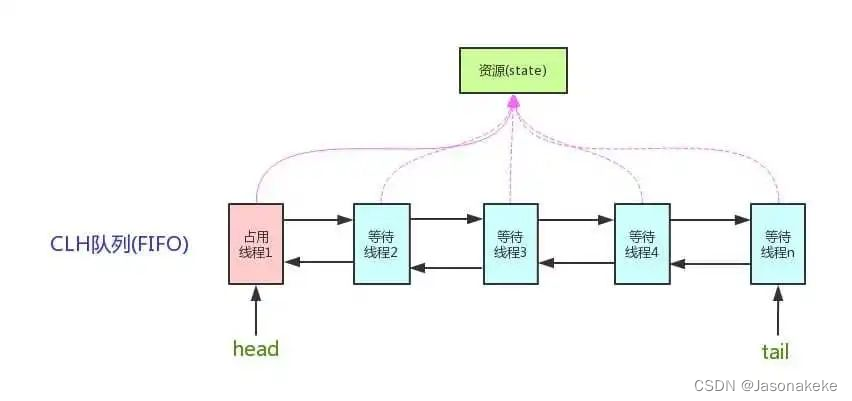
如上图所示和前面所述,AQS维护了一个volatile int state域和一个FIFO线程等待队列(利用双向链表实现,多线程争用资源被阻塞时会进入此队列)。
域和方法
主要的域如下:
private transient volatile Node head; // 同步队列的head节点
private transient volatile Node tail; // 同步队列的tail节点
private volatile int state; // 同步状态
AQS提供的可以修改同步状态的3个方法:
protected final int getState(); // 获取同步状态
protected final void setState(int newState); // 设置同步状态
protected final boolean compareAndSetState(int expect, int update); // CAS设置同步状态
这三种叫做均是原子操作,其中compareAndSetState的实现依赖于Unsafe的compareAndSwapInt()方法。代码实现如下:
private volatile int state;
protected final int getState() {
return state;
}
protected final void setState(int newState) {
state = newState;
}
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
自定义资源共享方式
AQS定义两种资源共享方式:Exclusive(独占,只有一个线程能执行,如ReentrantLock)和Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch(CountDownLatch是并发的))。 不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源state的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。自定义同步器实现时主要实现以下几种方法:
- isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
- tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
- tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
- tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
- tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。
以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。 再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。 一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。
源码解析
1. acquire(int)
acquire是一种以独占方式获取资源,如果获取到资源,线程直接返回,否则进入等待队列,直到获取到资源为止,且整个过程忽略中断的影响。该方法是独占模式下线程获取共享资源的顶层入口。获取到资源后,线程就可以去执行其临界区代码了。下面是acquire()的源码:
public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
函数流程如下:
-
tryAcquire()尝试直接去获取资源,如果成功则直接返回;
-
addWaiter()将该线程加入等待队列的尾部,并标记为独占模式;
-
acquireQueued()使线程在等待队列中获取资源,一直获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。
-
如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断selfInterrupt(),将中断补上。
接下来介绍相关方法。
1.1 tryAcquire(int)
tryAcquire尝试以独占的方式获取资源,如果获取成功,则直接返回true,否则直接返回false。该方法可以用于实现Lock中的tryLock()方法。该方法的默认实现是抛出UnsupportedOperationException,具体实现由自定义的扩展了AQS的同步类来实现。AQS在这里只负责定义了一个公共的方法框架。这里之所以没有定义成abstract,是因为独占模式下只用实现tryAcquire-tryRelease,而共享模式下只用实现tryAcquireShared-tryReleaseShared。如果都定义成abstract,那么每个模式也要去实现另一模式下的接口。
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
1.2 addWaiter(Node)
该方法用于将当前线程根据不同的模式(Node.EXCLUSIVE互斥模式、Node.SHARED共享模式)加入到等待队列的队尾,并返回当前线程所在的结点。如果队列不为空,则以通过compareAndSetTail方法以CAS(CAS (compare and swap) 比较并交换,就是将内存值与预期值进行比较,如果相等才将新值替换到内存中,并返回true表示操作成功;如果不相等,则直接返回false表示操作失败。)的方式将当前线程节点加入到等待队列的末尾。否则,通过enq(node)方法初始化一个等待队列,并返回当前节点。源码如下:
private Node addWaiter(Node mode) {
// 以给定模式构造结点。mode有两种:EXCLUSIVE(独占)和SHARED(共享)
Node node = new Node(Thread.currentThread(), mode);
// 尝试快速方式直接放到队尾。
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 上一步失败则通过enq入队。
enq(node);
return node;
}
1.2.1 enq(node)
enq(node)用于将当前节点插入等待队列,如果队列为空,则初始化当前队列。整个过程以CAS自旋的方式进行,直到成功加入队尾为止。源码如下:
private Node enq(final Node node) {
// CAS"自旋",直到成功加入队尾
for (;;) {
Node t = tail;
if (t == null) { // 队列为空,创建一个空的标志结点作为head结点,并将tail也指向它。
if (compareAndSetHead(new Node()))
tail = head;
} else {
// 正常流程,放入队尾
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
1.3 acquireQueued(Node, int)
通过tryAcquire()和addWaiter(),该线程获取资源失败,已经被放入等待队列尾部了,接下来就是等待队列前面的线程依次出队列,最后轮到自己被唤醒。acquireQueued(Node, int)函数的作用就是这个。 acquireQueued()用于队列中的线程自旋地以独占且不可中断的方式获取同步状态(acquire),直到拿到锁之后再返回。该方法的实现分成两部分:如果当前节点已经成为头结点,尝试获取锁(tryAcquire)成功,然后返回;否则检查当前节点是否应该被park(即进入waiting状态),然后将该线程park并且检查当前线程是否被可以被中断。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true; // 标记是否成功拿到资源
try {
boolean interrupted = false; // 标记等待过程中是否被中断过
// 又是一个“自旋”!
for (;;) {
final Node p = node.predecessor();// 拿到前驱
// 如果前驱是head,即该结点已成老二,那么便有资格去尝试获取资源(可能是老大释放完资源唤醒自己的,当然也可能被interrupt了)。
if (p == head && tryAcquire(arg)) {
setHead(node); // 拿到资源后,将head指向该结点。所以head所指的标杆结点,就是当前获取到资源的那个结点或null。
p.next = null; // setHead中node.prev已置为null,此处再将head.next置为null,就是为了方便GC回收以前的head结点。也就意味着之前拿完资源的结点出队了!
failed = false;
return interrupted; // 返回等待过程中是否被中断过
}
// 如果自己可以休息了,就进入waiting状态,直到被unpark()
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
interrupted = true; // 如果等待过程中被中断过,哪怕只有那么一次,就将interrupted标记为true
}
} finally {
if (failed)
cancelAcquire(node);
}
}
1.3.1 shouldParkAfterFailedAcquire(Node, Node)
shouldParkAfterFailedAcquire方法通过对当前节点的前一个节点的状态进行判断,对当前节点做出不同的操作(进入waiting状态或者继续往前找)。
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus; // 拿到前驱的状态
if (ws == Node.SIGNAL)
// 如果已经告诉前驱拿完号后通知自己一下,那就可以安心休息了
return true;
if (ws > 0) {
/*
* 如果前驱放弃了,那就一直往前找,直到找到最近一个正常等待的状态,并排在它的后边。
* 注意:那些放弃的结点,由于被自己“加塞”到它们前边,它们相当于形成一个无引用链,稍后就会被保安大叔赶走了(GC回收)!
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 如果前驱正常,那就把前驱的状态设置成SIGNAL,告诉它拿完号后通知自己一下。有可能失败,人家说不定刚刚释放完呢!
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
1.3.2 parkAndCheckInterrupt()
该方法让线程去休息,真正进入等待状态。park()会让当前线程进入waiting状态。在此状态下,有两种途径可以唤醒该线程:1)被unpark();2)被interrupt()。需要注意的是,Thread.interrupted()会清除当前线程的中断标记位。
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this); // 调用park()使线程进入waiting状态
return Thread.interrupted(); // 如果被唤醒,查看自己是不是被中断的。
}
1.3.3 acquireQueued()小结
acquireQueued()函数的具体流程:
- 结点进入队尾后,检查状态,找到安全休息点;
- 调用park()进入waiting状态,等待unpark()或interrupt()唤醒自己;
- 被唤醒后,看自己是不是有资格能拿到号。如果拿到,head指向当前结点,并返回从入队到拿到号的整个过程中是否被中断过;如果没拿到,继续流程1。
1.4 acquire()小结
acquire()的流程:
- 调用自定义同步器的tryAcquire()尝试直接去获取资源,如果成功则直接返回;
- 没成功,则addWaiter()将该线程加入等待队列的尾部,并标记为独占模式;
- acquireQueued()使线程在等待队列中休息,有机会时(轮到自己,会被unpark())会去尝试获取资源。获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。
- 如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断selfInterrupt(),将中断补上。
J.U.C – 其它组件(这部分还需要细致总结)
FutureTask
在介绍 Callable 时我们知道它可以有返回值,返回值通过 Future 进行封装。FutureTask 实现了 RunnableFuture 接口,该接口继承自 Runnable 和 Future 接口,这使得 FutureTask 既可以当做一个任务执行,也可以有返回值。
public class FutureTask<V> implements RunnableFuture<V>public interface RunnableFuture<V> extends Runnable, Future<V>
FutureTask 可用于异步获取执行结果或取消执行任务的场景。当一个计算任务需要执行很长时间,那么就可以用 FutureTask 来封装这个任务,主线程在完成自己的任务之后再去获取结果。
public class FutureTaskExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> futureTask = new FutureTask<Integer>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int result = 0;
for (int i = 0; i < 100; i++) {
Thread.sleep(10);
result += i;
}
return result;
}
});
Thread computeThread = new Thread(futureTask);
computeThread.start();
Thread otherThread = new Thread(() -> {
System.out.println("other task is running...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
otherThread.start();
System.out.println(futureTask.get());
}
}
控制台输出结果为:
other task is running...
4950
BlockingQueue
java.util.concurrent.BlockingQueue 接口有以下阻塞队列的实现:
- FIFO 队列 : LinkedBlockingQueue、ArrayBlockingQueue(固定长度)
- 优先级队列 : PriorityBlockingQueue 提供了阻塞的 take() 和 put() 方法:如果队列为空 take() 将阻塞,直到队列中有内容;如果队列为满 put() 将阻塞,直到队列有空闲位置。
使用 BlockingQueue 实现生产者消费者问题
public class ProductorConsumer {
private static BlockingQueue<String> quene = new ArrayBlockingQueue<>(5);
private static class Productor extends Thread{
@Override
public void run() {
try {
quene.put("product");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("productor...");
}
}
private static class Consumer extends Thread{
@Override
public void run() {
try {
String product = quene.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("consumer...");
}
}
public static void main(String[] args) {
for(int i = 0; i < 2; i++){
Productor productor = new Productor();
productor.start();
}
for(int i = 0; i < 5; i++){
Consumer consumer = new Consumer();
consumer.start();
}
for(int i = 0; i < 3; i++){
Productor productor = new Productor();
productor.start();
}
}
}
控制台输出结果为(每次都不一样):
productor...
productor...
consumer...
consumer...
productor...
productor...
consumer...
consumer...
productor...
consumer...
ForkJoin
使用了**“分治”**的思想。
主要用于并行计算中,和 MapReduce 原理类似,都是把大的计算任务拆分成多个小任务并行计算。
import java.util.concurrent.RecursiveTask;
public class ForkJoinExample extends RecursiveTask<Integer> {
private final int threshold = 5;
private int first;
private int last;
public ForkJoinExample(int first, int last) {
this.first = first;
this.last = last;
}
@Override
protected Integer compute() {
int result = 0;
if (last - first <= threshold) {
// 任务足够小则直接计算
for (int i = first; i <= last; i++) {
result += i;
}
} else {
// 拆分成小任务
int middle = first + (last - first) / 2;
ForkJoinExample leftTask = new ForkJoinExample(first, middle);
ForkJoinExample rightTask = new ForkJoinExample(middle + 1, last);
leftTask.fork();
rightTask.fork();
result = leftTask.join() + rightTask.join();
}
return result;
}
}
窃取算法(工作窃密算法)
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
一个大任务分割为若干个互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并未每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。比如线程1负责处理1队列里的任务,2线程负责2队列的。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务待处理。干完活的线程与其等着,不如帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们可能会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务线程永远从双端队列的尾部拿任务执行。
- 优点:充分利用线程进行并行计算,减少线程间的竞争。
- 缺点:在某些情况下还是会存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗更多的系统资源, 比如创建多个线程和多个双端队列。
在Java中,
- 可以使用LinkedBlockingDeque来实现工作窃取算法
- JDK1.7引入的Fork/Join框架就是基于工作窃取算法
另外,jdk1.7中引入了一种新的线程池:WorkStealingPool。
参考:
https://blog.csdn.net/pange1991/article/details/80944797
https://blog.csdn.net/huzhiqiangcsdn/article/details/55251384
https://www.cnblogs.com/waterystone/p/4920797.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/141687.html

