
HA概述
1)所谓HA(High Available),即高可用(7*24小时不中断服务)。
2)实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
4)NameNode主要在以下两个方面影响HDFS集群
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
HDFS-HA配置
1 环境准备
- 修改IP
- 修改主机名及主机名和IP地址的映射
- 关闭防火墙
- ssh免密登录
- 安装JDK,配置环境变量等
2 规划集群
| hadoop001 | hadoop002 | hadoop003 |
|---|---|---|
| NameNode | NameNode | |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
HDFS HA集群
- 将 /export/servers/下的 hadoop-2.7.3拷贝到/export/servers/ha目录
[root@hadoop001 ~]# cd /export/servers/
[root@hadoop001 servers]# cp -r hadoop-2.7.3 ha
- 配置ha的输出路径,创建目录
[root@hadoop001 data]# mkdir /export/data/ha
- 配置core-site.xml
<configuration>
<!-- 把两个NameNode)的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/ha/tmp</value>
</property>
</configuration>
- 配置hdfs-site.xml
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop001:9000</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop002:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop001:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop002:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/data/ha/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
- 拷贝配置好的hadoop环境到其他节点
[root@hadoop001 servers]# cd /export/servers
[root@hadoop001 servers]# scp -r ha hadoop002:/export/servers/
[root@hadoop001 servers]# scp -r ha hadoop003:/export/servers/
6.修改hadoop002和hadoop003上的hadoop 软连接
[root@hadoop002 hadoop]# cd /export/servers/
[root@hadoop002 servers]# rm -rf hadoop
[root@hadoop002 servers]# ln -s /export/servers/ha /export/servers/hadoop
[root@hadoop003 hadoop]# cd /export/servers/
[root@hadoop003 servers]# rm -rf hadoop
[root@hadoop003 servers]# ln -s /export/servers/ha /export/servers/hadoop
启动HDFS-HA集群
- 在各个JournalNode节点上,输入以下命令启动journalnode服务
[root@hadoop001 sbin]# ./hadoop-daemon.sh start journalnode
starting journalnode, logging to /export/servers/ha/logs/hadoop-root-journalnode-hadoop001.out
#或者
[root@hadoop002 zookeeper]# /export/servers/ha/sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /export/servers/ha/logs/hadoop-root-journalnode-hadoop002.out
[root@hadoop003 ~]# /export/servers/ha/sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /export/servers/ha/logs/hadoop-root-journalnode-hadoop003.out
- 在[nn1]上,对其进行格式化,并启动
[root@hadoop001 ~]# /export/servers/ha/bin/hdfs namenode -format
[root@hadoop001 ~]# /export/servers/ha/sbin/hadoop-daemon.sh start namenode
- 在[nn2]上,同步nn1的元数据信息
[root@hadoop002 ~]# /export/servers/ha/bin/hdfs namenode -bootstrapStandby
- 启动[nn2]
[root@hadoop002 ~]# /export/servers/ha/sbin/hadoop-daemon.sh start namenode
- 查看web页面显示
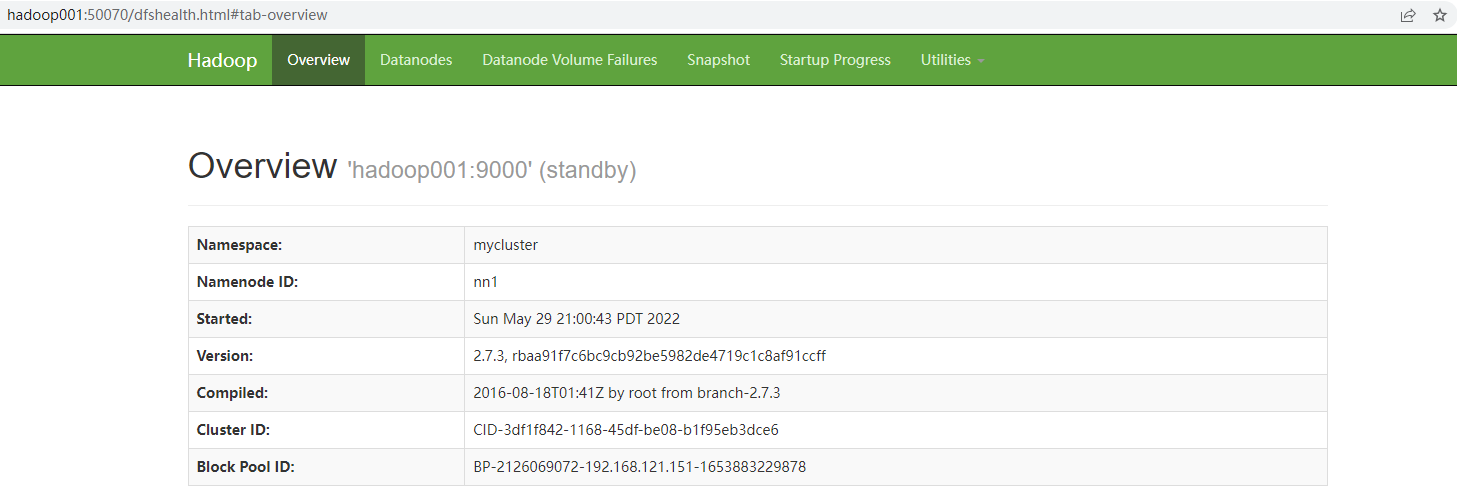

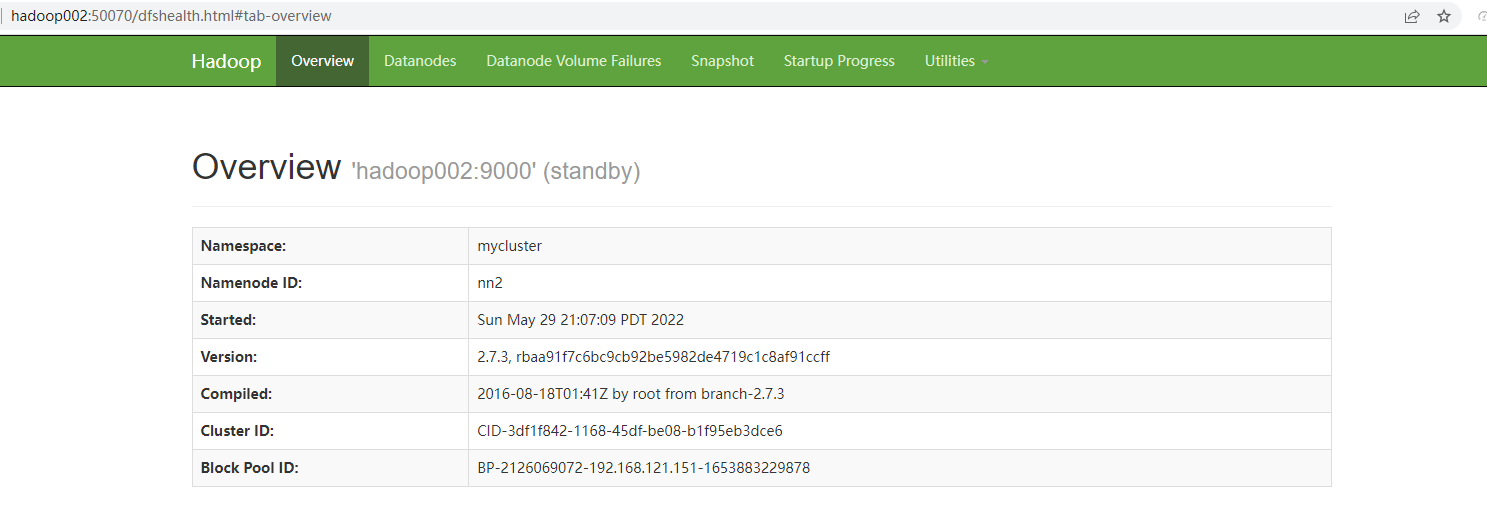
6. 在[nn1]上,启动所有datanode
[root@hadoop001 ~]# /export/servers/ha/sbin/hadoop-daemons.sh start datanode
[root@hadoop001 ~]# cd /export/conf/
[root@hadoop001 conf]# ./jps.sh
==========hadoop001的JPS=============
6352 NameNode
6099 JournalNode
7015 Jps
3689 QuorumPeerMain
6843 DataNode
==========hadoop002的JPS=============
8790 DataNode
6472 QuorumPeerMain
8617 NameNode
8347 JournalNode
8895 Jps
==========hadoop003的JPS=============
4752 JournalNode
2737 QuorumPeerMain
5330 Jps
5162 DataNode
- 将[nn1]切换为Active
[root@hadoop001 conf]# hdfs dfs -put jps.sh /
put: Operation category READ is not supported in state standby
[root@hadoop001 ~]# /export/servers/ha/bin/hdfs haadmin -transitionToActive nn1
[root@hadoop001 conf]# /export/servers/ha/bin/hdfs haadmin -getServiceState nn1
active
#然后就可以进行HDFS的操作了
配置HDFS-HA自动故障转移
1. 具体配置
(1)在hdfs-site.xml中增加
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
(2)在core-site.xml文件中增加
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
(3)copy到其他的主机
[root@hadoop001 hadoop]# cd /export/servers/ha/etc/hadoop
[root@hadoop001 hadoop]# scp hdfs-site.xml core-site.xml hadoop002:`pwd`
[root@hadoop001 hadoop]# scp hdfs-site.xml core-site.xml hadoop003:`pwd`
2. 启动
(1)关闭所有HDFS服务:
[root@hadoop001 conf]# /export/servers/ha/sbin/stop-dfs.sh
确认关闭
[root@hadoop001 hadoop]# jps
3689 QuorumPeerMain
9389 Jps
[root@hadoop001 hadoop]# /export/conf/jps.sh
==========hadoop001的JPS=============
9412 Jps
3689 QuorumPeerMain
==========hadoop002的JPS=============
10341 Jps
6472 QuorumPeerMain
==========hadoop003的JPS=============
2737 QuorumPeerMain
6734 Jps
(2)启动Zookeeper集群:
#没有关闭就不用启动
[root@hadoop001 conf]# /export/servers/zookeeper/bin/zkServer.sh start
(3)初始化HA在Zookeeper中状态:
[root@hadoop001 conf]# /export/servers/ha/bin/hdfs zkfc -formatZK
(4)启动HDFS服务:
[root@hadoop001 conf]# /export/servers/ha/sbin/start-dfs.sh
(5)在各个NameNode节点上启动DFSZK Failover Controller,先在哪台机器启动,哪个机器的NameNode就是Active NameNode
#如果没有启动 则启动,默认是启动的
[root@hadoop001 conf]# /export/servers/ha/sbin/hadoop-daemon.sh start zkfc
#使用以下代码查看
[root@hadoop001 conf]# /export/servers/ha/bin/hdfs haadmin -getServiceState nn1
[root@hadoop002 conf]# /export/servers/ha/bin/hdfs haadmin -getServiceState nn2
- 验证
(1)将Active NameNode进程kill
kill -9 namenode的进程id
(2)将Active NameNode机器断开网络
service network stop
YARN-HA配置
yarn-site.xml
[root@hadoop001 hadoop]# cd /export/servers/ha/etc/hadoop
[root@hadoop001 hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop001</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop002</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
分发到其他的机器上:
[root@hadoop001 hadoop]# cd /export/servers/ha/etc/hadoop
[root@hadoop001 hadoop]# scp yarn-site.xml hadoop002:`pwd`
[root@hadoop001 hadoop]# scp yarn-site.xml hadoop003:`pwd`
启动yarn ha
1.启动HDFS HA
- 启动hdfs
(1)在各个JournalNode节点上,输入以下命令启动journalnode服务:
[root@hadoop001 ~]# /export/servers/ha/sbin/hadoop-daemon.sh start journalnode
[root@hadoop002 ~]# /export/servers/ha/sbin/hadoop-daemon.sh start journalnode
[root@hadoop003 ~]# /export/servers/ha/sbin/hadoop-daemon.sh start journalnode
(2)在[nn1]上,对其进行格式化,并启动:
[root@hadoop001 ~]# /export/servers/ha/bin/hdfs namenode -format
[root@hadoop001 ~]# /export/servers/ha/sbin/hadoop-daemon.sh start namenode
(3)在[nn2]上,同步nn1的元数据信息:
[root@hadoop002 ~]# /export/servers/ha/bin/hdfs namenode -bootstrapStandby
(4)启动[nn2]:
[root@hadoop002 ~]# /export/servers/ha/sbin/hadoop-daemon.sh start namenode
(5)启动所有DataNode
[root@hadoop001 ~]# /export/servers/ha/sbin/hadoop-daemons.sh start datanode
(6)将[nn1]切换为Active
[root@hadoop001 ~]# /export/servers/ha/bin/hdfs haadmin -transitionToActive nn1
[root@hadoop001 ha]# /export/servers/ha/bin/hdfs haadmin -getServiceState nn1
2.启动YARN HA
(1)在hadoop001中执行:
[root@hadoop001 ha]# /export/servers/ha/sbin/start-yarn.sh
(2)在hadoop002中执行:
[root@hadoop002 ha]# /export/servers/ha/sbin/yarn-daemon.sh start resourcemanager
启动完成后的状态如下:
[root@hadoop001 hadoop]# /export/conf/jps.sh
==========hadoop001的JPS=============
15616 Jps
15382 ResourceManager
14712 DFSZKFailoverController
14393 JournalNode
5242 QuorumPeerMain
13948 NameNode
15501 NodeManager
14110 DataNode
==========hadoop002的JPS=============
5970 QuorumPeerMain
10647 DataNode
11544 Jps
11497 ResourceManager
10796 JournalNode
11373 NodeManager
10894 DFSZKFailoverController
11134 NameNode
==========hadoop003的JPS=============
8997 NodeManager
8760 JournalNode
9112 Jps
8649 DataNode
4715 QuorumPeerMain
(3)查看服务状态,如图3-24所示
[root@hadoop001 ha]# /export/servers/ha/bin/yarn rmadmin -getServiceState rm1
(4)访问hadoop001:8088/cluster
hadoop001:8088/cluster
问题1:Too many levels of symbolic links
hadoop003: bash: /export/servers/hadoop/sbin/yarn-daemon.sh: Too many levels of symbolic links
解决方法:在使用ln -s命令时,使用绝对路径取代相对路径
ln -s /export/servers/ha /export/servers/hadoop
问题2:强制切换NameNode的Active状态,需要几秒的时间
hdfs haadmin -transitionToActive --forcemanual --forceactive nn1
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/140763.html

