
一、浅谈Hadoop中MapReduce运行机制
1. MapReduce作业运行机制
提交作业的方式,一般常用的有以下两种
方式一:
通过一个简单的方式法调用来运行MR作业Job对象上的submit(),直接将作业提交到Hadoop集群的平台,而客户端没有任何日志输出;
方式二:
调用Job对象上的waitForCompletion()方法,用于提交之前没有处理过的作业,并等待它的完成,客户端会时刻打印作业执行的进度信息,如出现异常,也会立刻将异常信息打印出来。
2. 了解作业的运行组件
MR框架通过某个作业的提交而启动时,运行在主节点的守护进程就是JobTracker,运行在各个从节点的守护进程就是TaskTracker。
| JobTracker | TaskTracker | |
|---|---|---|
| 主要作用 | 它负责接收客户端提交的计算任务,然后将计算任务分配给具体的TaskTracker来执行,并监控各个TaskTracker的执行情况 | 它负责执行JobTracker分配的计算任务。TaskTracker由JobTracker指派任务,实列化用户程序,在本地执行任务,并周期性地向JobTracker汇报状态 |
| 存在位置 | 一个MR集群有一个JobTracker,一般运行在可靠的硬件上。TaskTracker通过周期心跳来通知JobTracker其当前的健康状态,每一次心跳包含了可用的map和reduce任务数目,占用的数目以及运行中的任务详细信息 | 在每一个工作节点上只会有一个TaskTracker |
| 功能分析 | JobTracker利用一个线程池来同时处理心跳和客户请求。当一个任务被提交时,组成作业的每一个任务的信息都会存储在内存中,在任务运行的时候,这些任务会伴随着TaskTracker的心跳而更新,因此可以实时地反映任务进度和健康状况 | TaskTracker和DataNode运行在一台机器上,从而使得每一台物理机器既是计算节点,也是一个存储节点。每一个TaskTracker能够配置的map和reduce的任务片数(TaskSlot)就代表每一种任务能被并行执行的数目 |
3. MapReduce作业的运行解析
(1) 运行示意图

(2) 提交作业过程
在哪个节点上提交作业时,就在这个节点 开启一个JobClient客户端对象,并调用其submitjob()方法提交作业, 之后,JobClient对象的runjob()方法每秒轮询作业的进度,如发现作业自上次报告后有所改变,就把作业运行进度报告到控制台。作业完成后,如成功,就显示作业计数器,进而显示作业执行所花费的时间等相关信息,如失败,就会把导致作业失败的错误信息记录到控制台。
1.通过JobTracker的getNewJobId()请求一个新的作业ID,如能获取作业ID,则可向集群提交作业,如不能获取作业ID,则说明集群正在忙,本次作业提交失败;
2.检查作业的输出说明(比如没有指定输出目录或输出目录已经存在,就抛出异常);
3.计算作业的输入分片(当分片无法计算时,比如输入路径不存在等原因,就抛出异常);
4.将运行作业所需的资源(比如作业Jar文件,配置文件,计算所得的输入分片等)复制到一个以作业ID命名的目录中。(集群中有多个作业jar副本可供TaskTracker访问,由 mapred.submit.replication属性控制,默认为10);
5.通过调用JobTracker的submitJob()方法告知JobTracker作业准备执行。
(3) 初始化作业过程
1.JobTracker接收到Job对象对其submitJob()方法的调用后,就会把这个调用放入一个内部队列中,交由作业调度器(Job Scheduler)进行调度,并对其进行初始化。
| 作业调度器种类 |
|---|
| 1.先进先出调度器 |
| 2.容量调度器 |
| 3.公平调度器 |
2.初始化工作:创建一个表示正在运行作业的对象(它封装任务和记录信息,以便跟踪任务的状态和进程)
3.创建任务运行列表,包括map和reduce任务,创建任务过程分析。
1.作业调度器从HDFS中获取JobClient已计算好的输入分片信息,然后为每个分片创建一个map任务,并且创建Reduce任务。
reduce任务数量的确认方法:
(1) 由job的mapred.reduce.task属性决定;
(2) 通过显式编程方式调用Job的setNumReduceTasks()方法设置reduce任务的个数。
2.除了map和reduce任务,还有setupJob和cleanupJob需要建立。
(1) setupJob用于MapReduce框架在执行map之前进行资源的集中初始化工作;
(2) cleanupJob方法是在map任务执行完后,用以进行相关变量或资源的释放工作;
以上方法都只被MapReduce框架执行一次。
(4) 任务分配过程
1.TaskTracker定期通过“心跳”与JobTracker进行通信,主要是告知JobTracker自身是否还存活,以及是否已经准备好运行新的任务等;
2.JobTracker在为TaskTracker选择任务之前,必须先通过作业调度器选定任务所在的作业;
3.每个TaskTracker都有固定数量的map和reduce任务槽,数量取决于TaskTracker节点的CPU内核数量和内存大小. JobTracker会先将TaskTracker的map槽填满,再填此TaskTracker的reduce槽。
任务槽限定了在某一个TaskTracker所在的节点上最多能运行多少个map任务;
4.JobTracker分配map任务时会选取与输入分片最近的TaskTracker(任务本地化).分配reduce任务时不考虑。
(5) 任务执行过程
1.TaskTracker分配到一个任务后,通过从HDFS把作业的Jar文件复制到TaskTracker所在的文件系统(Jar本地化用来启动JVM),同时TaskTracker将应用程序所需要的全部文件从分布式缓存复制到本地磁盘;
2.TaskTracker为任务新建一个本地工作目录,并把Jar文件中的内容解压到这个文件夹中;
3.TaskTracker新建军一个TaskRunner实例来启动一个新的JVM来运行每个Task(包括MapTask和ReduceTask)。子进程通过umbilical接口与父进程进行通信,Task的子进程每隔几秒便告知父进程它的进度,直到任务完成。
(6) 进度和状态更新过程
1.一个作业和它的每个任务都有一个状态信息,包括作业或任务的运行状态,Map和Reduce的进度,计数器值,状态消息或描述(可以由用户代码来设置)。这些状态信息在作业期间不断改变;
理解: 进度标准
(1) map进度标准是处理输入所占比例;
(2) reduce进度标准是 copy/merge/reduce( 与shuffle的3阶段相对应) 对整个进度的比例。
2.Child JVM有独立的线程,每隔3秒检查一次任务更新标志,如有更新则报告给此TaskTracker,TaskTracker每隔5秒给JobTracker发一次心跳信息。而JobTracker将合并这些更新,产生一个表明所有运行作业及其任务状态的全局视图;
3.同时JobClient通过每秒查询JobTracker来获得最新状态,并且输出到控制台上。
(7) 作业完成
当JobTracker收到作业最后一个任务已完成的通知后,便把作业的状态设置为”成功”。然后,在JobClient查询状态时,便知道作业已成功完成,于是JobClient打印一条消息告知用户,最后从runJob()方法返回。最后,JobTracker清空作业的工作状态,指示TaskTracker也清空作业的工作状态。
4.MR任务运行问题思考
(1) 推测执行,如: 系统中有99%的Map任务都完成了,只有少数几个Map老是进度很慢,完不成,怎么办?
Hadoop会把任务分配到多个节点,当中一些慢的节点会限制整体程序的执行速度。这时Hadoop会引入“推测执行”过程:
因为作业中大多数任务都已经完成,hadoop平台会在几个空闲节点上调度执行剩余任务复制,当任务完成时会向JobTracker通告。任何一个首先完成的复制任务将成为权威复制,如果其他复制任务还在推测执行中,hadoop会告诉TaskTracker去终止这些任务并丢弃其输出,然后reducer会从首先完成的mapper那里获取输入数据。
(2) 遇到任务JVM重用问题
mapred.job.reuse.jvm.num.tasks默认为1,即每个Task都启动一个JVM来运行任务,当值为-1时,表示JVM可以无限制重用。
当值为-1时,TaskTracker先判断当前当前节点是否有slot剩余,如果没有slot槽位才会判断当前分配的slot槽位中的JVM是否已经将当前task任务运行完,如果task已经运行完,才会复用当前JVM(同一Job的JVM才会复用)
注意:当一个Job的Task(尤其Task耗时很小)数目很大,由于频繁的JVM停启会造成很大开销,进行JVM复用会使同一个Job的一些静态数据得到共享,从而是集群性能得到很大提升。
但是JVM重用会导致在同一个JVM中的碎片增加,导致JVM性能变差。
5. MapReduce作业调度
(1) 调度器是一个可插拔的模块,用户可以根据自己的实际应用要求设计调度器;
(2) 功能:Hadoop调度器的基本作用就是根据节点资源(slot)使用情况和作业的要求,将任务调度到各个节点上执行;
(3) 调度器设计考虑的因素
1.作业优先级。作业的优先级越高,它能够获取的资源(slot数目)也越多。 5种作业优先级通过mapreduce.job.priority属性来设置;
2.作业提交时间. 提交越早,越先执行;
3.作业所在队列的资源限制,调度器可以分为多个队列,不同的产品线放到不同的队列里运行。不同的队列可以设置一个边缘限制,这样不同的队列有自己独立的资源,不会出现抢占和滥用资源的情况。
(4) 作业调度原理图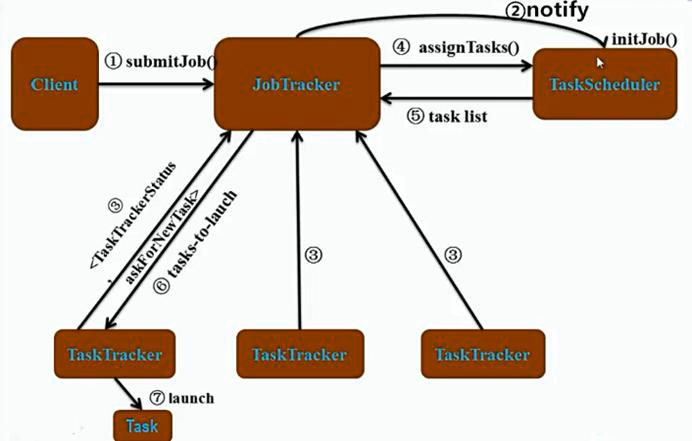
TaskScheduler 是 JobTracker 的一个组件、一个成员,它们之间是函数与调用的关系。而 Client、JobTracker和TaskTracker之间是通过网络RPC来交互。
(5) 调度器原理分析
1.Client 通过submitJob()函数向JobTracker提交一个作业;
2.JobTracker通知 TaskScheduler,调用其内部函数initJob()对这个作业进行初始化,创建一些内部的数据结构;
3.TaskTracker 通过心跳来向 JobTracker 汇报它的资源情况,比如有多少个空闲的map slot和reduce slot;
4.如果 JobTracker 发现第一个 TaskTracker 有空闲的资源 ,JobTracker 就会调用 TaskScheduler 的 assignTasks() 函数,返回一些task list给第一个TaskTracker。
这时TaskTracker就会执行调度器分配的任务;
(6) Hadoop自带调度器种类分析
1.先进先出调度器( FIFO ):一种批处理调度器。它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业。
一个 TaskTracker 正好有一个空闲的 slot,此时 FIFO 调度器的队列已经排好序,就选择排在最前面的任务 job1,job1 包含很多 map task和reduce task。假如空闲资源是 map slot,我们就选择 job1 中的 map task。假如 map task0 要处理的数据正好存储在该 TaskTracker 节点上,根据数据的本地性,调度器把 map task0 分配给该TaskTracker;

2.计算能力调度器:支持多个队列,每个队列可配置一定的资源量,每个队列采用FIFO调度策略,为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。调度时,首先按以下策略选择一个合适队列:计算每个队列中正在运行的任务数与其应该分得的计算资源之间的比值,选择一个该比值最小的队列;然后按以下策略选择该队列中一个作业:按照作业优先级和提交时间顺序选择,同时考虑用户资源量限制和内存限制。
比如我们分为三个队列:queueA、queueB和queueC,每个队列的 job 按照到达时间排序。假如这里有 100 个slot,queueA 分配 20% 的资源,可配置最多运行 15 个task,queueB 分配 50% 的资源,可配置最多运行 25 个task,queueC 分配 30% 的资源,可配置最多运行 25 个task。这三个队列同时按照任务的先后顺序依次执行,比如,job11、job21和job31分别排在队列最前面,是最先运行,也是同时运行;

3.公平调度器:同计算能力调度器类似,支持多队列多用户,每个队列中的资源量可以配置,同一队列中的作业公平共享队列中所有资源。
比如有三个队列:queueA、queueB和queueC,每个队列中的 job 按照优先级分配资源,优先级越高分配的资源越多,但是每个 job 都会分配到资源以确保公平。在资源有限的情况下,每个 job 理想情况下获得的计算资源与实际获得的计算资源存在一种差距, 这个差距就叫做缺额。在同一个队列中,job的资源缺额越大,越先获得资源优先执行。作业是按照缺额的高低来先后执行的,而且可以看到上图有多个作业同时运行。

6. MapReduce架构中的问题
(1) 无法支撑更多的计算模型;
(2) 主服务的压力过大:在Hadoop 1.0中,与MapReduce相关的以及与Hadoop集群资源管理相关的逻辑全部放在一个服务中,那就是JobTracker 进程,它即要负责应用程序作业的调度和监控,又要负责应用程序计算时所需集群资源的分配与协调,这样就使得JobTracker所在主服务器的压力过大,从而限制了系统的扩展性;
(3) 因此YARN诞生了,下图为YARN的设计示意图,今天浅谈的MapReduce任务运行机制就到这里。下次有时间我们再谈谈YARN的运行流程。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之家整理,本文链接:https://www.bmabk.com/index.php/post/13714.html

