
Apache Phoenix的安装以及结合HBase的Java API使用
Phoenix概述
Phoenix是一个基于HBase的开源SQL引擎,可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据,它是完全使用Java编写,作为HBase内嵌的JDBC驱动使用。
Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。
直接使用HBase API、协同处理器与自定义过滤器,对于简单查询来说,其性能量级是毫秒,对于百万级别的行数来说,其性能量级是秒。
官网:https://phoenix.apache.org/index.html
官网下载:https://phoenix.apache.org/download.html
开源软件镜像站下载:https://mirrors.bfsu.edu.cn/apache//phoenix
Phoenix下载与安装
下载
wget https://mirrors.bfsu.edu.cn/apache/phoenix/phoenix-5.1.2/phoenix-hbase-2.2-5.1.2-bin.tar.gz
解压与重命名
tar -zxvf phoenix-hbase-2.2-5.1.2-bin.tar.gz
mv phoenix-hbase-2.2-5.1.2-bin phoenix-hbase
修改环境变量
vim /etc/profile
export PHOENIX_HOME=/usr/local/program/phoenix-hbase
export PATH=$PHOENIX_HOME/bin:$PATH
使生效 source /etc/profile
修改配置文件
修改phoenix-hbase/bin/hbase-site.xml
<configuration>
<!-- 开启二级索引,默认 -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<!-- 开启schema与namespace的映射 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<!-- SystemTables映射到namespace -->
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
</configuration>
修改HBase/conf/hbase-site.xml,添加如下配置
<!-- 开启二级索引,默认 -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<!-- 开启schema与namespace的映射 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<!-- SystemTables映射到namespace -->
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
拷贝jar包
Phoenix是以JDBC驱动方式嵌入到HBase中的,在部署时只有一个包,直接放HBase的lib目录
将phoenix-hbase/phoenix-server-hbase-2.2-5.1.2.jar复制一份到HBase/lib/目录
启动Zookeeper、Hadoop、HBase、
zkServer.sh start
start-all.sh
start-hbase.sh
启动Phoenix
phoenix-hbase\bin>sqlline.py node001:2181
Connecting to jdbc:phoenix:node001:2181
Connected to: Phoenix (version 5.1)
Driver: PhoenixEmbeddedDriver (version 5.1)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
sqlline version 1.9.0
0: jdbc:phoenix:node001:2181>
退出
!quit
基本操作
详细用法参考:https://phoenix.apache.org/language/index.html

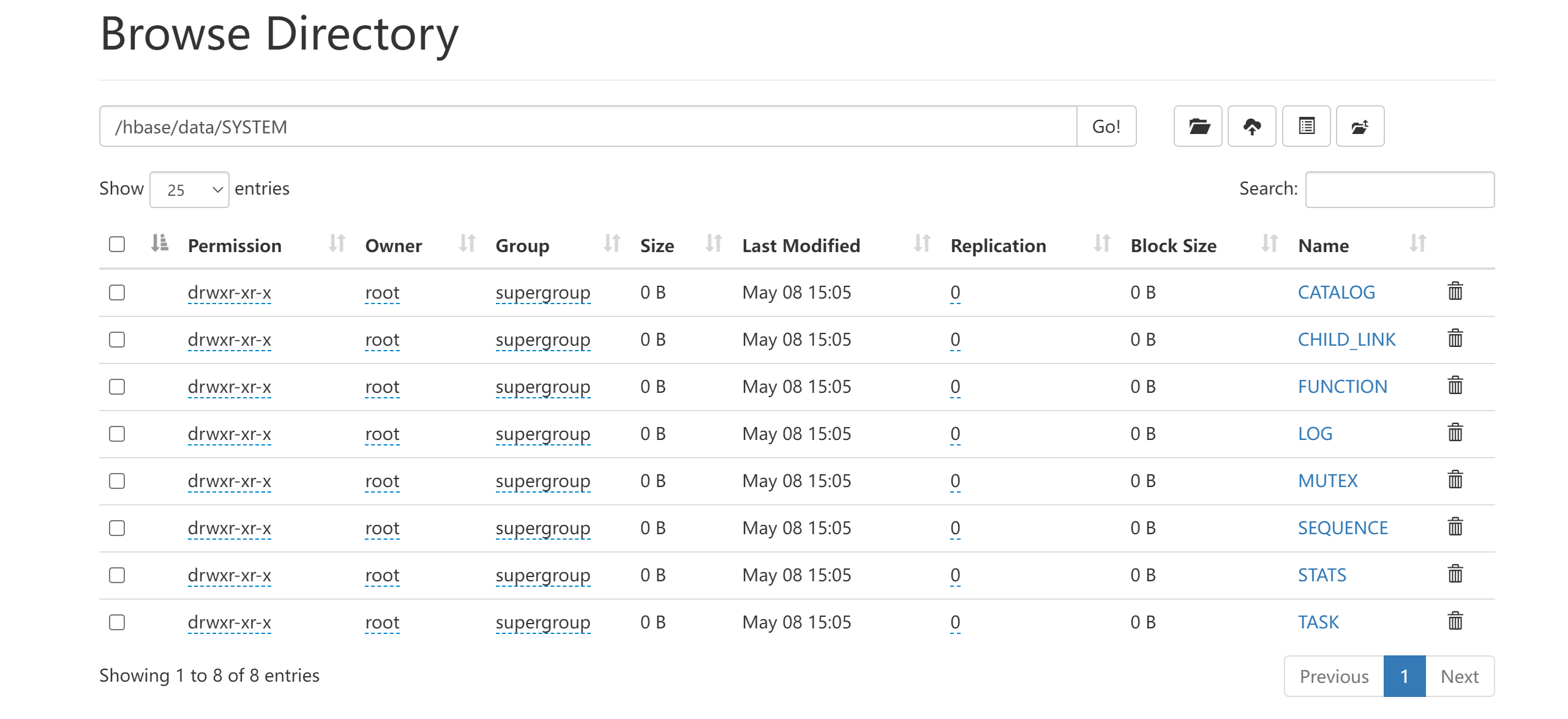
查看所有表
首次启动会在hbase中自动生成8张表
0: jdbc:phoenix:node001:2181> !table
+-----------+-------------+------------+--------------+---------+-----------+---------------------------+----------------+-------------+----------------+--------------+--------------+----------------+-----+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | INDEX_STATE | IMMUTABLE_ROWS | SALT_BUCKETS | MULTI_TENANT | VIEW_STATEMENT | VIE |
+-----------+-------------+------------+--------------+---------+-----------+---------------------------+----------------+-------------+----------------+--------------+--------------+----------------+-----+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | | | false | null | false | | |
| | SYSTEM | CHILD_LINK | SYSTEM TABLE | | | | | | false | null | false | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | | false | null | false | | |
| | SYSTEM | LOG | SYSTEM TABLE | | | | | | true | 32 | false | | |
| | SYSTEM | MUTEX | SYSTEM TABLE | | | | | | true | null | false | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | | false | null | false | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | | | | false | null | false | | |
| | SYSTEM | TASK | SYSTEM TABLE | | | | | | false | null | false | | |
+-----------+-------------+------------+--------------+---------+-----------+---------------------------+----------------+-------------+----------------+--------------+--------------+----------------+-----+
创建schema
create schema test;
创建表
1.建表后hbase中也会自动创建对应的表
2.建表后,表名和字段名都会自动转成大写,如需小写,需在建表时给表名和字段名前后加双引号
create table test.user(
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR,
age INTEGER
);
插入与更新数据
upsert into test.user(id,name,age) values(1,'hbase1',20);
upsert into test.user(id,name,age) values(2,'hbase2',22);
查询数据
select * from test.user;
删除数据
delete from test.user where id =1;
删除表
drop table test.user;
删除schema
drop schema test;
Phoenix索引
初始化,准备Schema与表
create schema test;
create table test.user(
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR,
age INTEGER
);
全局索引
全局索引适合读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于
写数据。数据表的添加、删除和修改都会更新相关的索引表。
全局索引在默认情况下,如果查询语句中检索的列不在索引表中,Phoenix不会使用索引表,除非使用hint。(全局索引必须是查询语句中所有列都包含在全局索引中,它才会生效)
1.创建索引
CREATE INDEX name_index ON test.user(name);
2.查看索引
!indexes test.user;
+-----------+-------------+------------+------------+-----------------+------------+------+------------------+-------------+-------------+-------------+-------+------------------+-----------+-----------+--+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | NON_UNIQUE | INDEX_QUALIFIER | INDEX_NAME | TYPE | ORDINAL_POSITION | COLUMN_NAME | ASC_OR_DESC | CARDINALITY | PAGES | FILTER_CONDITION | DATA_TYPE | TYPE_NAME | |
+-----------+-------------+------------+------------+-----------------+------------+------+------------------+-------------+-------------+-------------+-------+------------------+-----------+-----------+--+
| | TEST | USER | true | | NAME_INDEX | 3 | 1 | 0:NAME | A | | | | 12 | VARCHAR | |
| | TEST | USER | true | | NAME_INDEX | 3 | 2 | :ID | A | | | | 4 | INTEGER | |
+-----------+-------------+------------+------------+-----------------+------------+------+------------------+-------------+-------------+-------------+-------+------------------+-----------+-----------+--+
3.删除索引
DROP INDEX name_index ON test.user;
DROP INDEX IF EXISTS name_index ON test.user;
本地索引
本地索引适合写多读少的场景,或者存储空间有限的场景。
本地索引因索引数据和原数据存储在同一台机器上,避免了网络数据传输的开销,所以更适合写多的场景。
由于无法提前确定数据在哪个Region上,所以在读数据的时候,需要检查每个Region上的数据从而带来一些性能损耗。
对于本地索引,查询中无论是否指定hint或者是查询的列是否都在索引表中,都会使用索引表。
创建索引
CREATE LOCAL INDEX name_local_index ON test.user(name);
删除索引
DROP INDEX name_local_index ON test.user;
DROP INDEX IF EXISTS name_local_index ON test.user;
覆盖索引
覆盖索引是把原数据存储在索引数据表中,在查询时不需要再去HBase的原表获取数据,直接返回查询结果。
select的列和where的列都需要在索引中出现
创建索引
CREATE INDEX name_age_index ON test.user(name,age) INCLUDE ( id);
查询
select name,age from test.user where name ='hbase2' and age=22;
函数索引
函数索引的特点是索引的内容不局限于列,能根据表达式创建索引。适用于查询表时过滤条件是表达式的情况。
如果使用的表达式正好是索引,数据可以直接从这个索引获取,而不需要从数据库获取。
查看数据
select * from test.user;
+----+--------+-----+
| ID | NAME | AGE |
+----+--------+-----+
| 1 | hbase1 | 20 |
| 2 | hbase2 | 22 |
| 3 | hbase3 | 23 |
+----+--------+-----+
创建索引
# substr(s,n,1en): 从字符串s的n位置截取长度为len的子字符串
CREATE INDEX name_index ON test.user(substr(name,6,1)) INCLUDE ( id);
查询
select * from test.user where substr(name,6,1)='2';
+----+--------+-----+
| ID | NAME | AGE |
+----+--------+-----+
| 2 | hbase2 | 22 |
+----+--------+-----+
1 row selected (0.056 seconds)
索引Building
同步索引
CREATE INDEX async_index ON test.user(BASICINFO."s1",BASICINFO."s2");
当创建同步索引超时,修改hbase-site.xml,把超时参数设置大一些,足够 Build 索引数据的时间
<property>
<name>hbase.rpc.timeout</name>
<value>60000000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>60000000</value>
</property>
异步索引
异步Build索引需要借助MapReduce,创建异步索引语法和同步索引相差一个关键字:ASYNC。
CREATE INDEX async_index ON test.user ( BASICINFO."s1",BASICINFO."s2" ) ASYNC;
view视图映射hbase中的表
HBase数据准备
创建hbase表
create 'user','info'
插入数据
put 'user','001','info:name','hbase1'
put 'user','001','info:age',11
put 'user','002','info:name','hbase2'
put 'user','002','info:age',22
查看数据
hbase(main):008:0> scan 'user'
ROW COLUMN+CELL
001 column=info:age, timestamp=1652001388683, value=11
001 column=info:name, timestamp=1652001388604, value=hbase1
002 column=info:age, timestamp=1652001390069, value=22
002 column=info:name, timestamp=1652001388734, value=hbase2
2 row(s)
Took 0.1370 seconds
创建视图
注意:
1.phoenix区分大小写,不加""会转成大写;
2.通过view映射是只读的;
create view "user"(
id varchar primary key,
"info"."name" varchar,
"info"."age" varchar );
select * from "user";
+-----+--------+-----+
| ID | name | age |
+-----+--------+-----+
| 001 | hbase1 | 11 |
| 002 | hbase2 | 22 |
+-----+--------+-----+
2 rows selected (0.061 seconds)
创建索引
create index user_name_index on "user"("info"."name");
select "name" from "user" group by "name";
+--------+
| name |
+--------+
| hbase1 |
| hbase2 |
+--------+
2 rows selected (0.06 seconds)
删除视图
删除视图后,hbase中的表依然存在
drop view "user";
JDBC
添加依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.1.2</version>
</dependency>
API操作
public class PhoenixTest {
private static Connection connection = null;
private static Statement statement = null;
/**
* 获取连接
*/
@Before
public void init() {
try {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
//这里配置zookeeper地址,可单个,也可多个,可以是域名或者ip
String url = "jdbc:phoenix:112.74.96.150:2181/hbase";
connection = DriverManager.getConnection(url);
statement = connection.createStatement();
} catch (Exception e) {
e.printStackTrace();
}
}
@After
public void close() throws SQLException {
statement.close();
connection.close();
}
/**
* 创建数据表
*
* @throws SQLException
*/
@Test
public void createTableTest() throws SQLException {
String sql = "create table tb_test (mykey integer not null primary key,mycolumn varchar)";
statement.executeUpdate(sql);
connection.commit();
System.out.println("创建数据表成功!");
}
/**
* 单条插入数据
*
* @throws SQLException
*/
@Test
public void upsertTest() throws SQLException {
String sql1 = "upsert into tb_test values(1,'test1')";
String sql2 = "upsert into tb_test values(2,'test2')";
String sql3 = "upsert into tb_test values(3,'test3')";
statement.executeUpdate(sql1);
statement.executeUpdate(sql2);
statement.executeUpdate(sql3);
connection.commit();
System.out.println("数据已插入!");
}
/**
* 删除数据
*
* @throws SQLException
*/
@Test
public void deleteTest() throws SQLException {
String sql = "delete from tb_test where mykey=3";
statement.executeUpdate(sql);
connection.commit();
System.out.println("删除数据成功!");
}
/*检索数据表中的记录*/
@Test
public void readAllTest() throws SQLException {
String sql = "select * from tb_test";
long time = System.currentTimeMillis();
ResultSet rs = statement.executeQuery(sql);
connection.commit();
while (rs.next()) {
//获取字段值
int mykey = rs.getInt("mykey");
//获取字段值
String mycolumn = rs.getString("mycolumn");
System.out.println("mykey:" + mykey + "\t" + "mycolumn:" + mycolumn);
}
rs.close();
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/136956.html

