
作者:非妃是公主
专栏:《数据库》
个性签:顺境不惰,逆境不馁,以心制境,万事可成。——曾国藩
专栏系列文章
SQL Server Studio查看“估计的执行计划”和“实际的执行计划方法”

复习大纲


存储
索引
B+树索引
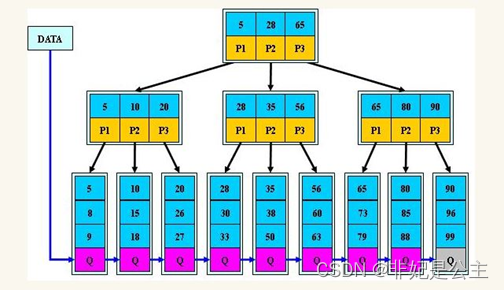
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;不可能在非叶子结点命中;
2.所有叶子节点都在同一个层次,无论查询哪条记录,查询时间都近乎相同.
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层
4.更适合文件索引系统
关系查询处理
查询处理步骤,RDBMS查询处理阶段 :
- 查询分析
- 查询检查
- 查询优化
- 查询执行
选择操作典型实现方法:
- 简单的全表扫描方法
- 索引(B+树或hash)扫描方法
连接操作的实现
- 嵌套循环方法(nested loop)

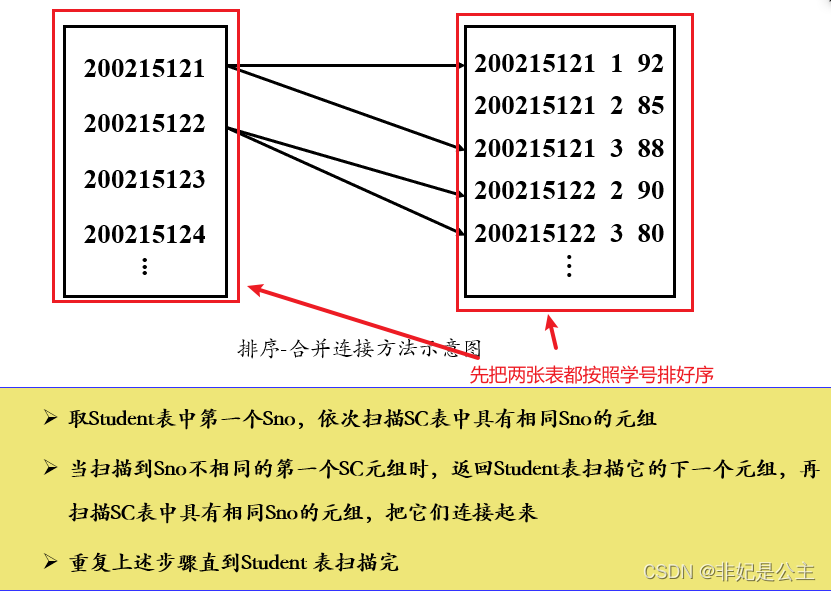
- 排序-合并方法(sort-merge join 或merge join)
- 索引连接(index join or hash join)方法

关系查询优化
查询优化在关系数据库系统中有着非常重要的地位,关系查询优化是影响RDBMS性能的关键因素
在RDBMS中,有优化器对查询进行优化,他的优势在于:
-
优化器更了解数据字典,比程序员更清楚数据之间的结构
-
优化器可以考虑数百种不同的执行计划,程序员一般只能考虑有限的几种可能性。
-
优化器中包括了很多复杂的优化技术,这些优化技术往往只有最好的程序员才能掌握。系统的自动优化相当于使得所有人都拥有这些优化技术。

查询优化的总目标:
- 选择有效的策略
- 求得给定关系表达式的值
- 使得查询代价最小(实际上是较小)
实例:





代数优化
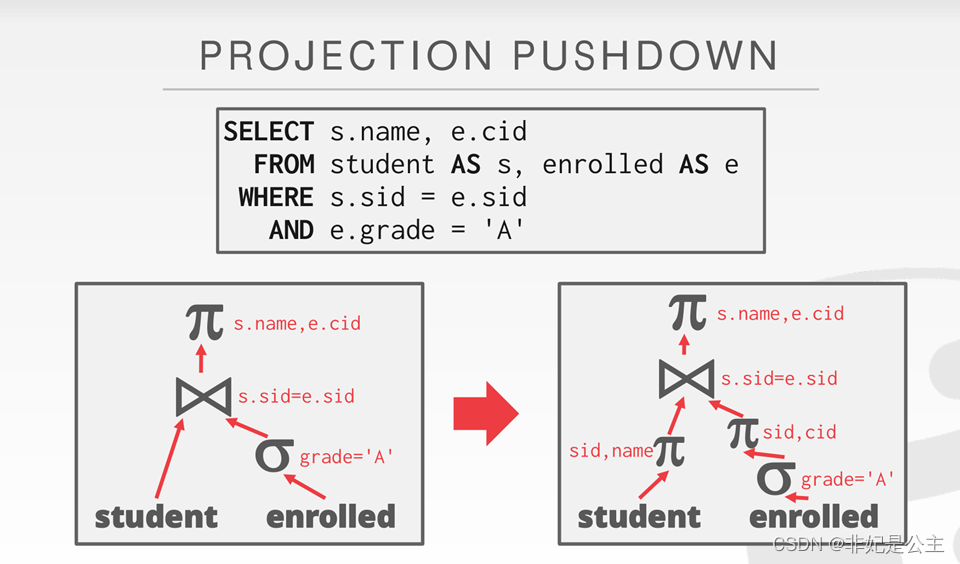
查询树的启发式优化


物理优化
代数优化改变查询语句中操作的次序和组合,不涉及底层的存取路径,对于一个查询语句有许多存取方案,它们的执行效率不同, 仅仅进行代数优化是不够的。物理优化就是要选择高效合理的操作算法或存取路径,求得优化的查询计划。
选择的方法:
- 基于规则的启发式优化
- 基于代价估算的优化
- 两者结合的优化方法
基于启发式规则的存取路径选择优化
选择操作
- 对于小关系,使用全表顺序扫描,即使选择列上有索引
- 对于大关系,启发式规则有:(说明:查询结果多,全表扫描(即使建立索引,总复杂度也趋近于O(n));查询结果少,建立索引)
- 对于选择条件是主码=值的查询,查询结果最多是一个元组,可以选择主码索引,一般的RDBMS会自动建立主码索引。
- 对于选择条件是非主属性=值的查询,并且选择列上有索引,要估算查询结果的元组数目。如果比例较小(<10%)可以使用索引扫描方法,否则还是使用全表顺序扫描。(说明:主要就是平衡建立索引的代价)
- 对于选择条件是属性上的非等值查询或者范围查询,并且选择列上有索引,要估算查询结果的元组数目,如果比例较小(<10%)可以使用索引扫描方法,否则还是使用全表顺序扫描。
- 对于用AND连接的合取选择条件,如果有涉及这些属性的组合索引,优先采用组合索引扫描方法,如果某些属性上有一般的索引,则可以用索引扫描方法(索引,求交),否则使用全表顺序扫描。
- 对于用OR连接的析取选择条件,一般使用全表顺序扫描。
连接操作
1. 如果2个表都已经按照连接属性排序:选用排序-合并方法
2. 如果一个表在连接属性上有索引:选用索引连接方法
3. 如果上面2个规则都不适用,其中一个表较小:选用Hash join方法
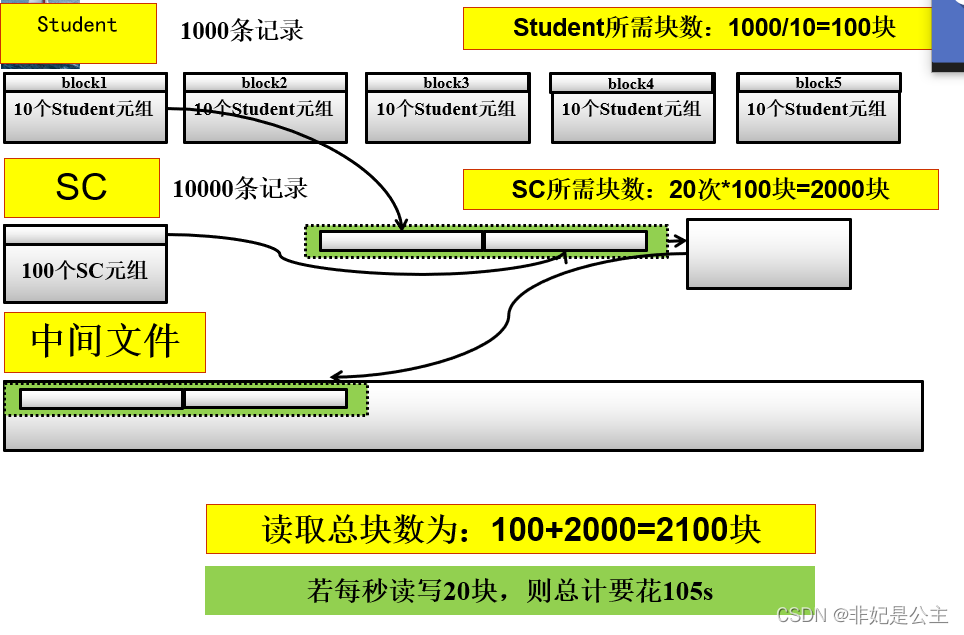
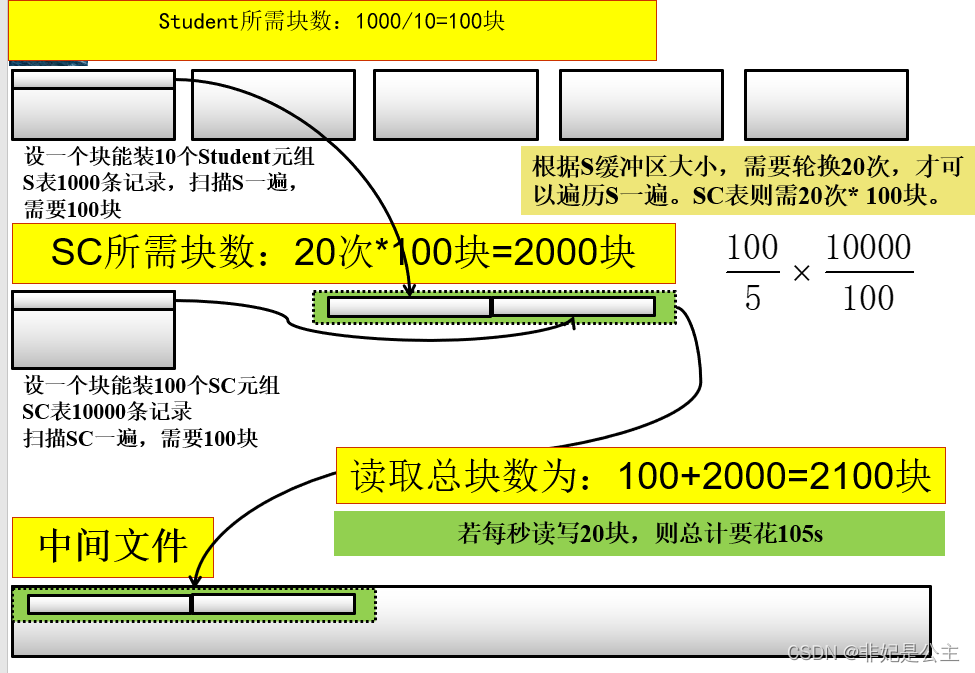
4. 可以选用嵌套循环方法,并选择其中较小的表,确切地讲是占用的块数(b)较少的表,作为外表(外循环的表) 。设连接表R与S分别占用
5. 的块数为Br与Bs,连接操作使用的内存缓冲区块数为K,分配K-1块给外表,如果R为外表,则嵌套循环法存取的块数为Br+(Br/K-1)Bs,显然应该选块数小的表作为外表 。
基于代价估算的优化
统计信息
基于代价的优化方法要计算各种操作算法的执行代价,与数据库的状态密切相关。数据字典中存储的优化器需要的统计信息:
-
对每个基本表:
-
该表的元组总数(N)
-
元组长度(l)
-
占用的块数(B)
-
占用的溢出块数(BO)
-
-
对基表的每个列:
- 该列不同值的个数(m)
- 选择率(f)
- 如果不同值的分布是均匀的,f=1/m
- 如果不同值的分布不均匀,则每个值的选择率=具有该值的元组数/N-直方图
- 该列最大值
- 该列最小值
- 该列上是否已经建立了索引
- 索引类型(B+树索引、Hash索引、聚集索引)
-
对基表的每个列:
- 该列不同值的个数(m)
- 选择率(f)
- 如果不同值的分布是均匀的,f=1/m
- 如果不同值的分布不均匀,则每个值的选择率=具有该值的元组数/N-直方图
- 该列最大值
- 该列最小值
- 该列上是否已经建立了索引
- 索引类型(B+树索引、Hash索引、聚集索引)
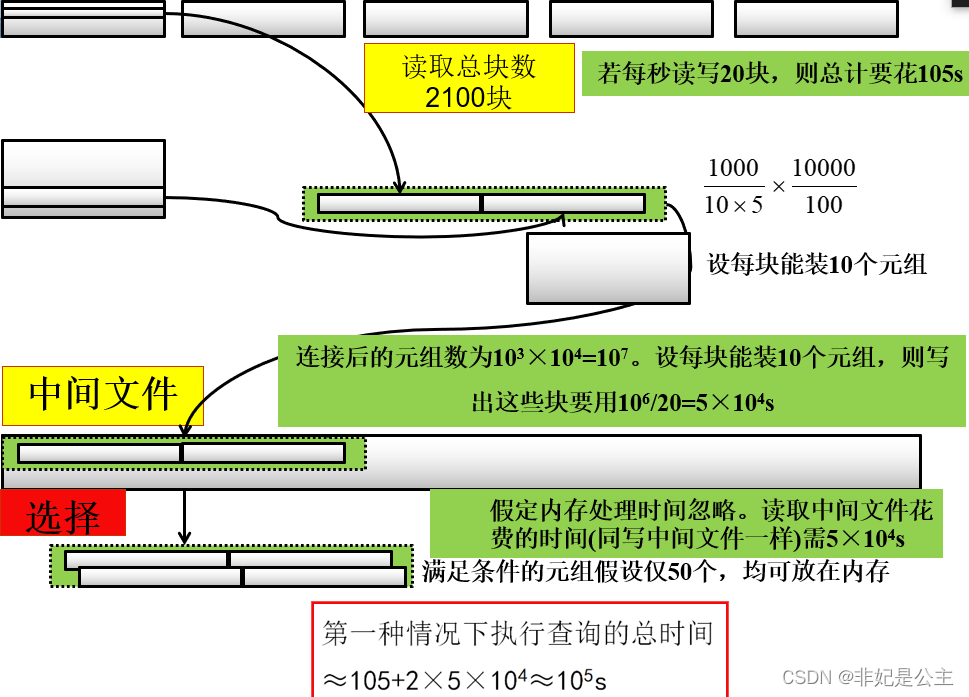
代价估算示例






数据库恢复
- 恢复机制是数据库必不可少的组成部分,它负责将数据库恢复到故障发生前的一致性的状态。
- 恢复机制还必须提供高可用性。它必须将数据库崩溃后不能使用的时间缩小到最短。
事务
事务(Transaction)是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位——具有原子性。
事务的ACID特性:
-
原子性(Atomicity):事务是数据库的逻辑工作单位,事务中包括的诸操作要么都做,要么都不做
-
一致性(Consistency):事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态
- 一致性状态:数据库中只包含成功事务提交的结果
- 不一致状态:数据库中包含失败事务的结果
-
隔离性(Isolation):对并发执行而言,一个事务的执行不能被其他事务干扰。
- 一个事务内部的操作及使用的数据对其他并发事务是隔离的
- 并发执行的各个事务之间不能互相干扰
-
持续性(Durability ):持续性也称永久性(Permanence),一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其执行结果有任何影响。
三种不同类型故障的恢复策略
- 事务故障的恢复:UNDO
- 系统故障的恢复
- 尚未提交(commit):UNDO
- 已经提交(commit):REDO
- 介质故障的恢复(两步走)
- 重装备份并恢复到一致性状态
- REDO
检查点技术
针对REDO浪费时间提出。

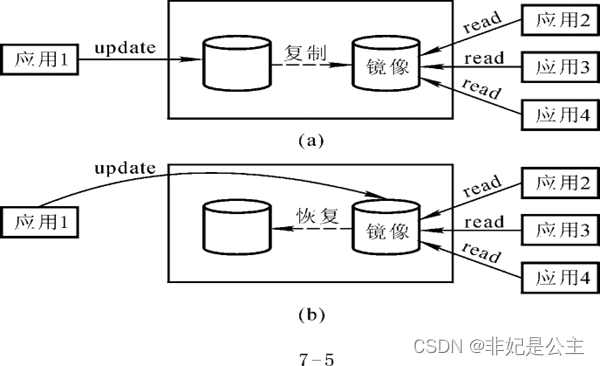
主要用于提高系统故障恢复效率的技术,可以在一定程度上提高利用动态转储备份进行介质故障恢复的效率
与之作用类似的还有镜像技术,镜像技术可以改善介质故障的恢复效率,基本思想如下图:
并发控制
封锁
定义
- 封锁就是事务T在对某个数据对象(例如表、记录等)操作之前,先向系统发出请求,对其加锁;
- 加锁后事务T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其它的事务不能更新此数据对象;
- 封锁是实现并发控制的一个非常重要的技术。
锁类型
排它锁(Exclusive lock,简记为X锁):排它锁又称为写锁,若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。
共享锁(Share lock,简记为S锁):共享锁又称为读锁,若事务T对数据对象A加上S锁,则其它事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。
锁协议
解决并发操作带来的不一致性问题:
丢失修改(lost update):两个事务对同一数据进行修改,后修改的错误地覆盖了先修改的。
不可重复读(non-repeatable read):一个事务读取后,另一个事务对数据进行了增、删、改操作,导致第一个事务下一次读取会获得与第一次不同的结果。
读“脏”数据(dirty read):一个事务由于数据库系统故障导致重做问题(REDO),另一个事务读取了redo前的数据,导致读取了“脏数据”。
封锁协议
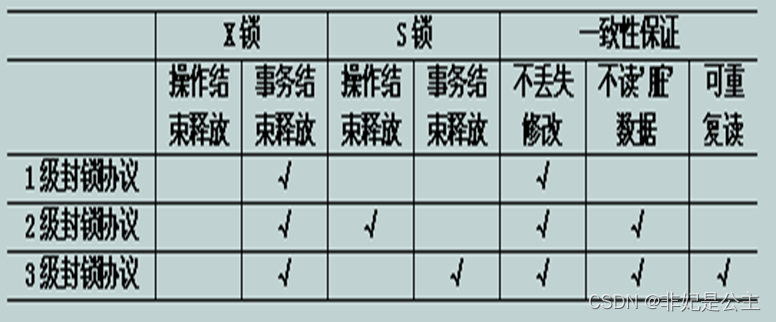
在运用X锁和S锁对数据对象加锁时,需要约定何时申请?何时释放?不同封锁协议,约定是不同的,常用的封锁协议为:三级封锁协议。
1级封锁协议
事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。
-
正常结束(COMMIT)
-
非正常结束(ROLLBACK)
1级封锁协议可防止丢失修改
对于读数据1级封锁协议没有限制,所以它不能保证可重复读和不读“脏”数据。
2级封锁协议
1级封锁协议+事务T在读取数据(R)前必须先加S锁,读完后即可释放S锁。
2级封锁协议可以防止丢失修改和读“脏”数据。
在2级封锁协议中,由于读完数据后即可释放S锁,所以它不能保证可重复读。
3级封锁协议
1级封锁协议 + 事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。
3级封锁协议可防止丢失修改、读脏数据和不可重复读。
可串行化冲突调度
冲突操作是指不同的事务对同一个数据的读写操作和写写操作:
R
i
(
x
)
与
W
j
(
x
)
W
i
(
x
)
与
W
j
(
x
)
R_i(x) 与 W_j(x) \\ W_i(x) 与 W_j(x)
Ri(x)与Wj(x)Wi(x)与Wj(x)
一个调度Sc在保证冲突操作的次序不变的情况下,通过交换两个事务不冲突操作的次序得到另一个调度Sc’,如果Sc’是串行的,称调度Sc为冲突可串行化的调度。
2PL
“两段”锁的含义
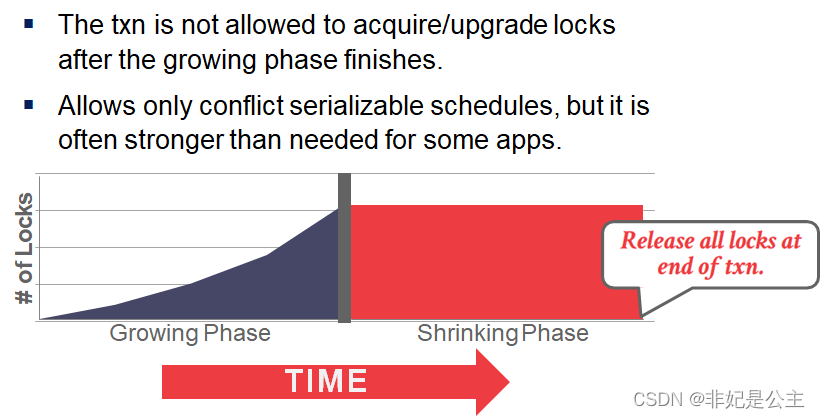
Phase #1: Growing
第一阶段是获得封锁,也称为扩展阶段;
在对任何数据进行读、写操作之前,事务首先要获得对该数据的封锁.
Each txn requests the locks that it needs from the DBMS’s lock manager.
Phase #2: Shrinking
第二阶段是释放封锁,也称为收缩阶段。
在释放一个封锁之后,事务不再获得任何其他封锁。
说明:2PL扩展和收缩都是针对同一事务而言的(针对同一事务,先封锁,后收缩)不涉及事务序列中其它事务。
Non-2PL Example:
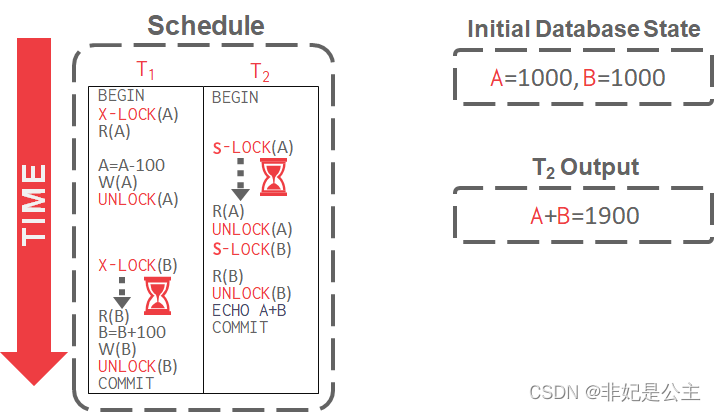
2PL Example:
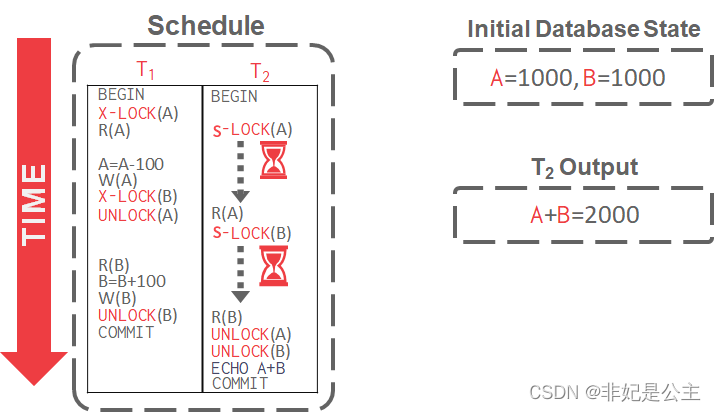
SS2PL
2PL(2 Phase Locking), 锁分两阶段,一阶段申请,一阶段释放
S2PL(Strict 2PL),在2PL的基础上,写锁保持到事务结束
SS2PL( Strong Strict 2PL),在2PL的基础上,读写锁都保持到事务结束
封锁粒度
封锁对象的大小称为封锁的粒度(Granularity)
X锁和S锁都是加在某一个数据对象上的
封锁的对象:关系、表、属性列、元组……
封锁对象可以很大也可以很小
例:对整个数据库加锁、对某个属性值加锁
多粒度封锁(multiple granularity locking)
在一个系统中同时支持多种封锁粒度供不同的事务选择
| 封锁的粒度越 | 大 | 小 |
|---|---|---|
| 系统被封锁的对象 | 少 | 多 |
| 并发度 | 小 | 高 |
| 系统开销 | 小 | 大 |

多粒度封锁
如果在一个系统中同时支持多种封锁粒度供不同的事务选择,这种封锁方法称为多粒度封锁(Multiple Granularity Locking),是较理想的。
多粒度封锁协议
- 多粒度树
- 以树形结构来表示多级封锁粒度
- 根结点是整个数据库,表示最大的数据粒度
- 叶结点表示最小的数据粒度
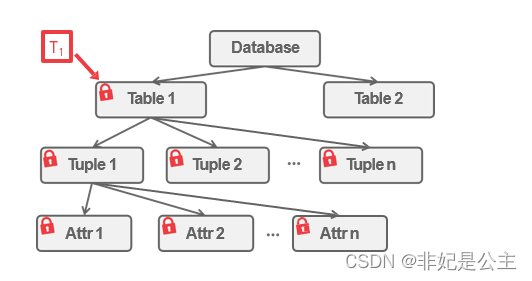
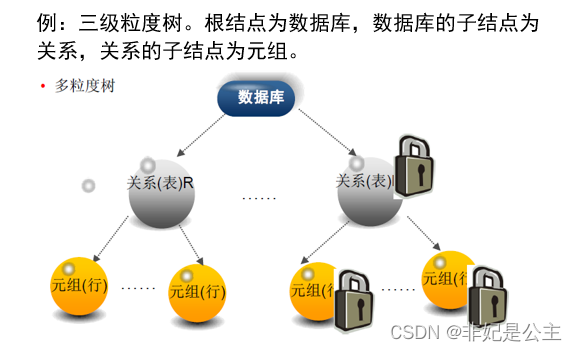
允许多粒度树中的每个结点被独立地加锁
对一个结点加锁意味着这个结点的所有后裔结点也被加以同样类型的锁
在多粒度封锁中一个数据对象可能以两种方式封锁:显式封锁和隐式封锁
显式封锁: 直接加到数据对象上的封锁
隐式封锁: 由于其上级结点加锁而使该数据对象加上了锁
显式封锁和隐式封锁的效果是一样的
意向锁

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由半码博客整理,本文链接:https://www.bmabk.com/index.php/post/130544.html

