
Redis使用默认的异步复制,其特点是低延迟和高性能,是绝大多数 Redis 用例的自然复制模式。但是,从 Redis 服务器会异步地确认其从主 Redis 服务器周期接收到的数据量。那么也就是说Redis肯定用的不是强一致性原理,因为强一致性原理一般在企业中很难铺开。一般来说在企业中要么选择弱一致性,要么选择最终一致性,而Redis所采取的方式就是弱一致性。Redis它的核心就是快,为了保持他的快,所以最少的去进行技术上的整合,那也就是说它为了快可以妥协一定量的数据。
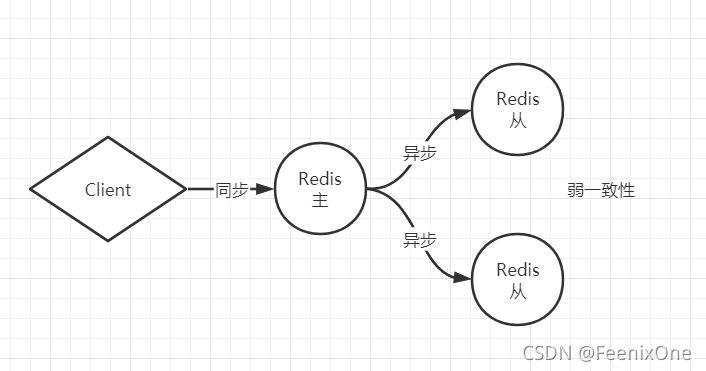

Redis并没有引入新的技术,在主从之间作为它的中间件,纯粹就是自己来实现主从之间的异步通信。接下来为了演示的方便,我会在一台主机上面开3台Redis的实例来进行这么一种伪分布式的演示。
1、准备Redis实例
我这台机子上已经有了两台Redis的实例,接下来我需要再安装1台实例,一共准备3台实例。
cd /usr/local/source/redis-6.2.5/utils/
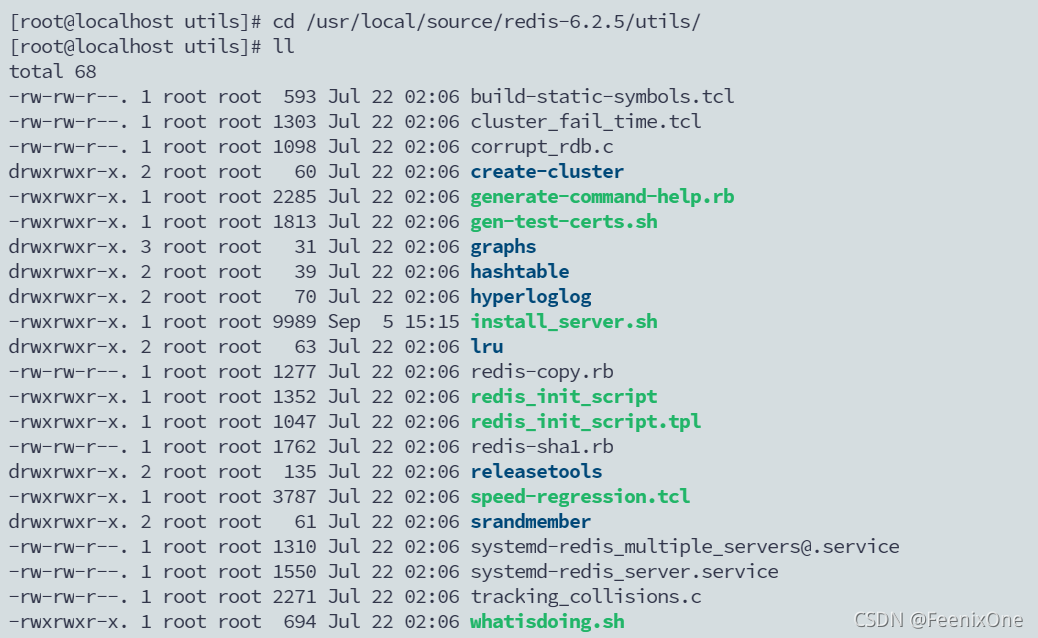
sh install_server.sh
这样,这台Redis的实力就安装好了。如果不知道为什么这么安装的,请翻看我之前写的一篇文章:【软件安装】Redis在Linux系统中的安装_FeenixOne的博客-CSDN博客0、安装前环境准备① 本篇是基于Linux操作系统中的安装,故先准备一个干净的Linux操作系统。本文中所有的操作基于CentOS8进行安装演示;② 确保Linux系统中已经安装[wget]和[gcc]等必要软件,用于下载Redis软件,及编译Redis源码的必备环境。如果没有安装,可以使用[yum install wget -y]和[yum install gcc -y]进行安装;③ 接下来的演示文本中,红色字体为操作步骤,黑色字体为解释说明。1、进入到本地Redis目录,从官网下载Redhttps://blog.csdn.net/FeenixOne/article/details/120093425
2、复制Redis配置文件
在家目录下创建一个test文件夹,用来存放这三个Redis的配置文件。加下来Redis的演示就基于这三个配置文件来开启进行演示,所以这三个配置文件我们需要复制出来,单独的进行修改,而不是直接修改。
cd ~
mkdir test
将这三台Redis的配置文件复制到test文件夹中
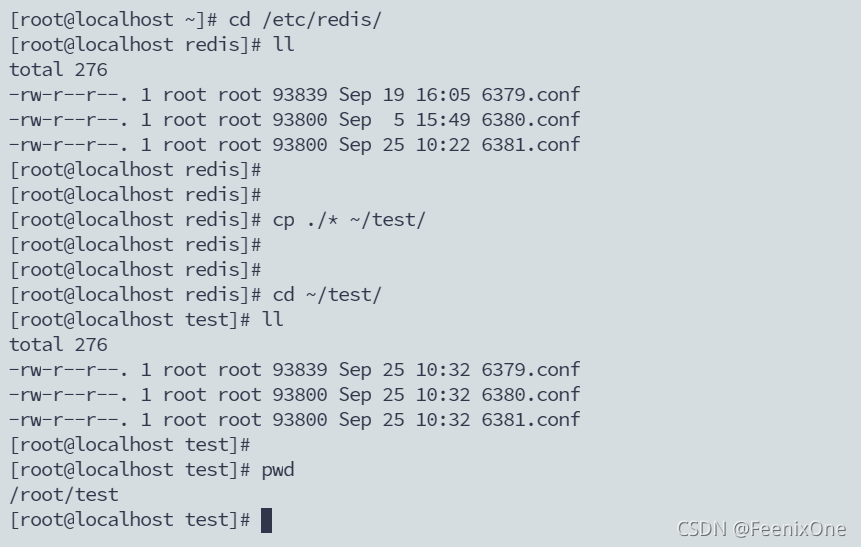
cd /etc/redis/
cp ./* ~/test/
3、修改Redis配置文件
daemonize no

# logfile /var/log/redis_6379.log
 这两个参数的目的是让Redis在前台阻塞运行,而不是在后台运行,并且关闭后台日志打印,这样所有的日志可以在前台实时打印出来清晰的看到。
这两个参数的目的是让Redis在前台阻塞运行,而不是在后台运行,并且关闭后台日志打印,这样所有的日志可以在前台实时打印出来清晰的看到。
appendonly no
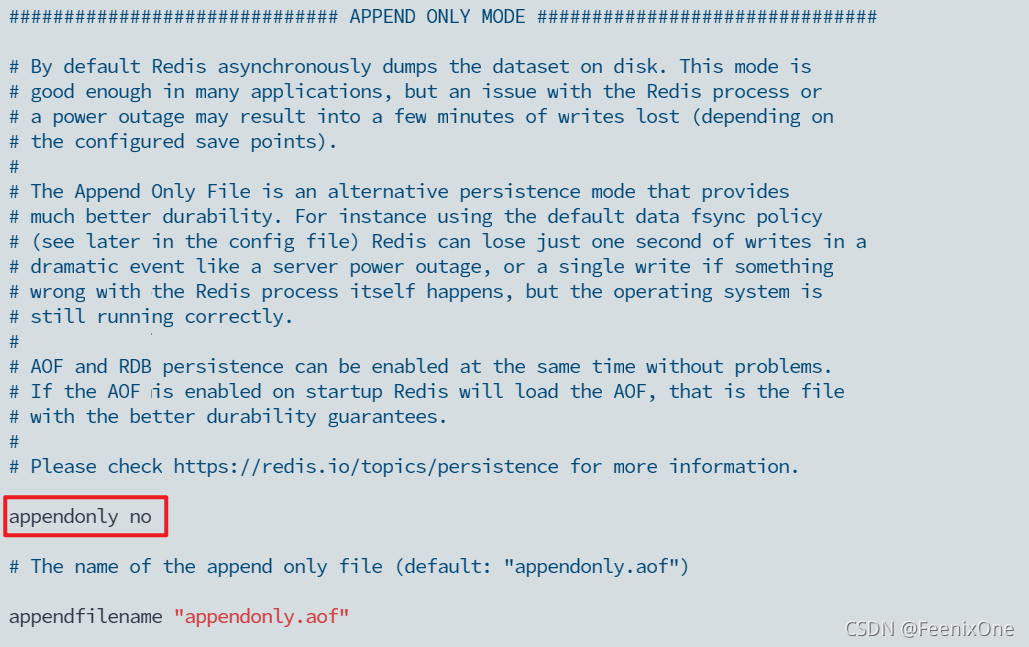
关闭AOF操作记录,同样的操作在6380和6381的配置文件以上重复一遍。
4、删除三台Redis实例的持久化文件
cd /var/lib/redis/
rm -rf ./*
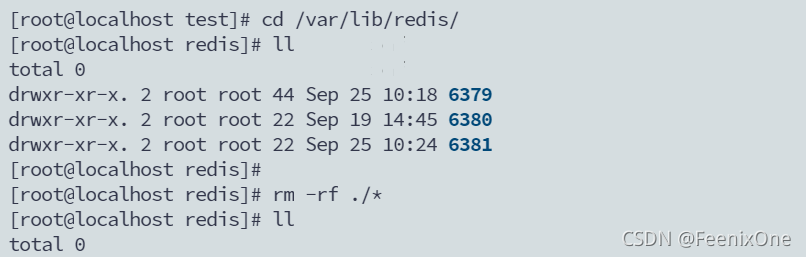
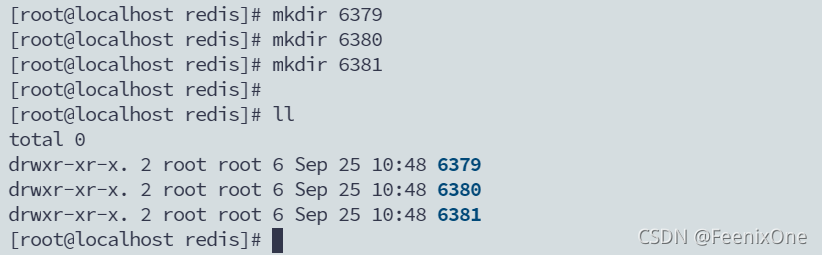
好了,现在这三台Redis里面的数据都是空的,从0开始。删除完目录以后要重新创建这个目录出来,不然启动的时候会报错。
5、前台阻塞启动Redis实例
redis-server ~/test/6379.conf
redis-server ~/test/6380.conf
redis-server ~/test/6381.conf
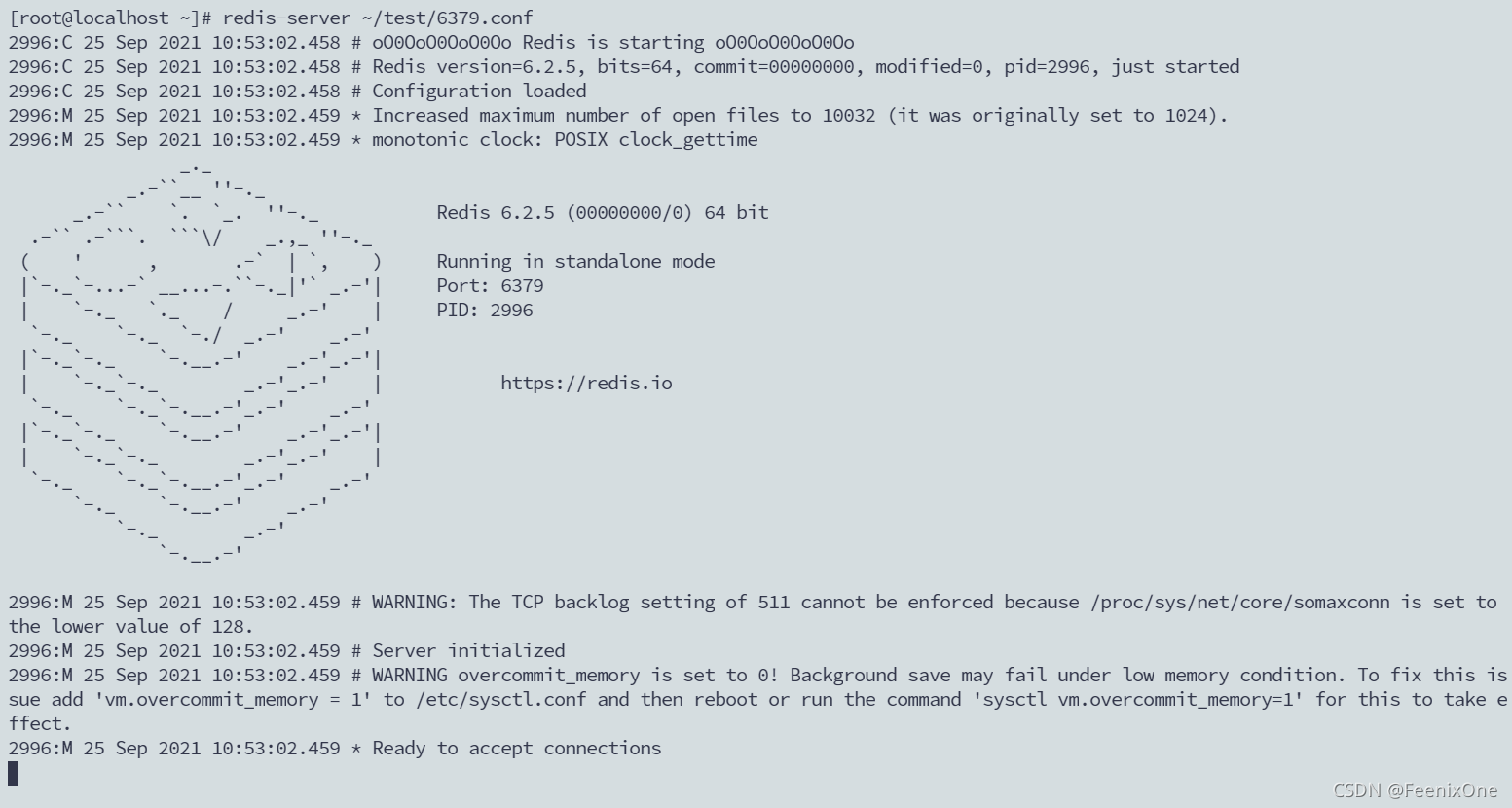
6、分配主从实例
现在将6379分配为主机,6380和6381作为6379的从机来追随6379。那么这要如何去实现呢?
先来看一下Redis对于主从命令的说明

在老版本中使用的是slaveof这个命令,在新的5.0版本以后更换成了replicaof这个命令。这两个命令只是名称上的不一样,本质上没有任何区别,都是作为主从的跟随来使用。现在我们可以在6380这台实例上执行这个命令来看看效果如何。
replicaof 127.0.0.1 6379

追随成功以后会返回一个OK的状态码,也就是说此时6380已经成功的作为从机,追随了6379这台主机。现在我们看一下6379这台主机前端打印出来的日志。
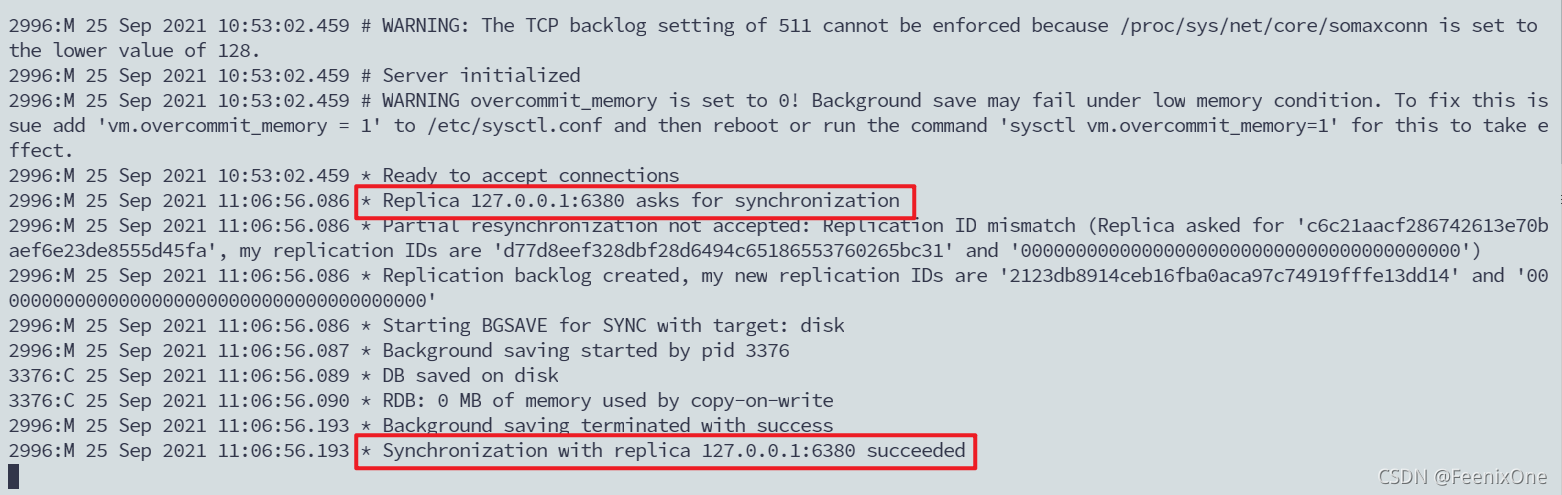
日志显示6379已经被6380成功的追随,并且在这个过程中6379产生了一个RDb的日志,这个日志呢也是落在了磁盘上。 我们现在再来看一下6380打印出来的日志。
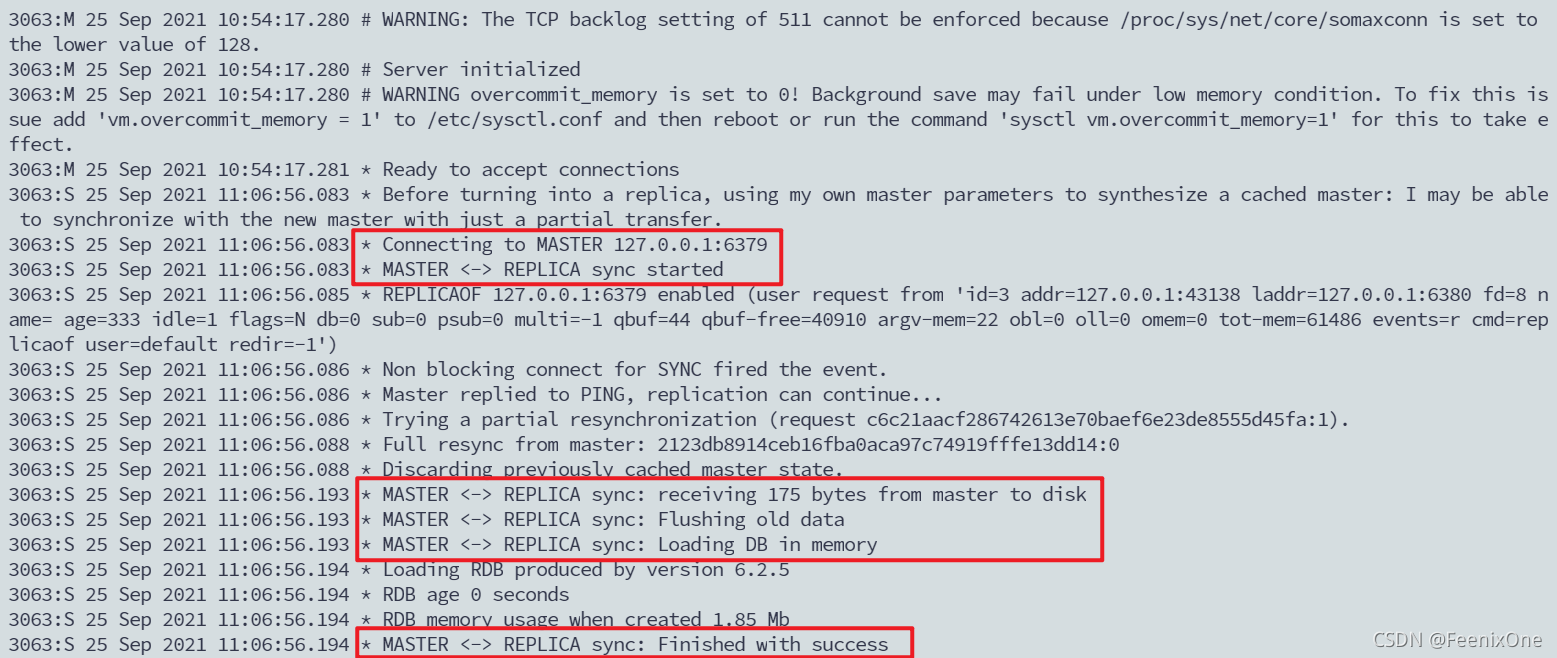
日志显示6380,已经成功地追随着6379这台主机,并且6380将自己原先的老数据已经全部清除掉,这一步是为了作为后面同步数据做准备。也就是说当一台机器追随另一台机器的时候,这个从机会将自己的老数据全部清除掉,接下来会从主机同步一样的数据过来。
那么为了验证这个同步是不是真的成功,我们往6379里面设置数据来看,6380里面究竟有没有真的可以同步成功?


可以看出这个从可以很成功的从主里面同步数据过来。但是在默认的情况下,从机是不允许写入数据的,它只能够同步主机的数据作为备份使用。

如果在从机写入数据的时候,系统会告诉你现在是read only的模式。当然这个设置其实可以在配置文件里面进行调整,让从机也能够写入数据。
好了,经过上面的验证,6380是可以成功追随6379的。但是6381现在是独立的,还没有和6379建立主从连接。在没有建立连接的时候,我们先在6381里面设置一个数据进去。

现在将6381和6379之间建立主从连接,让6381去追随6379。
replicaof 127.0.0.1 6379
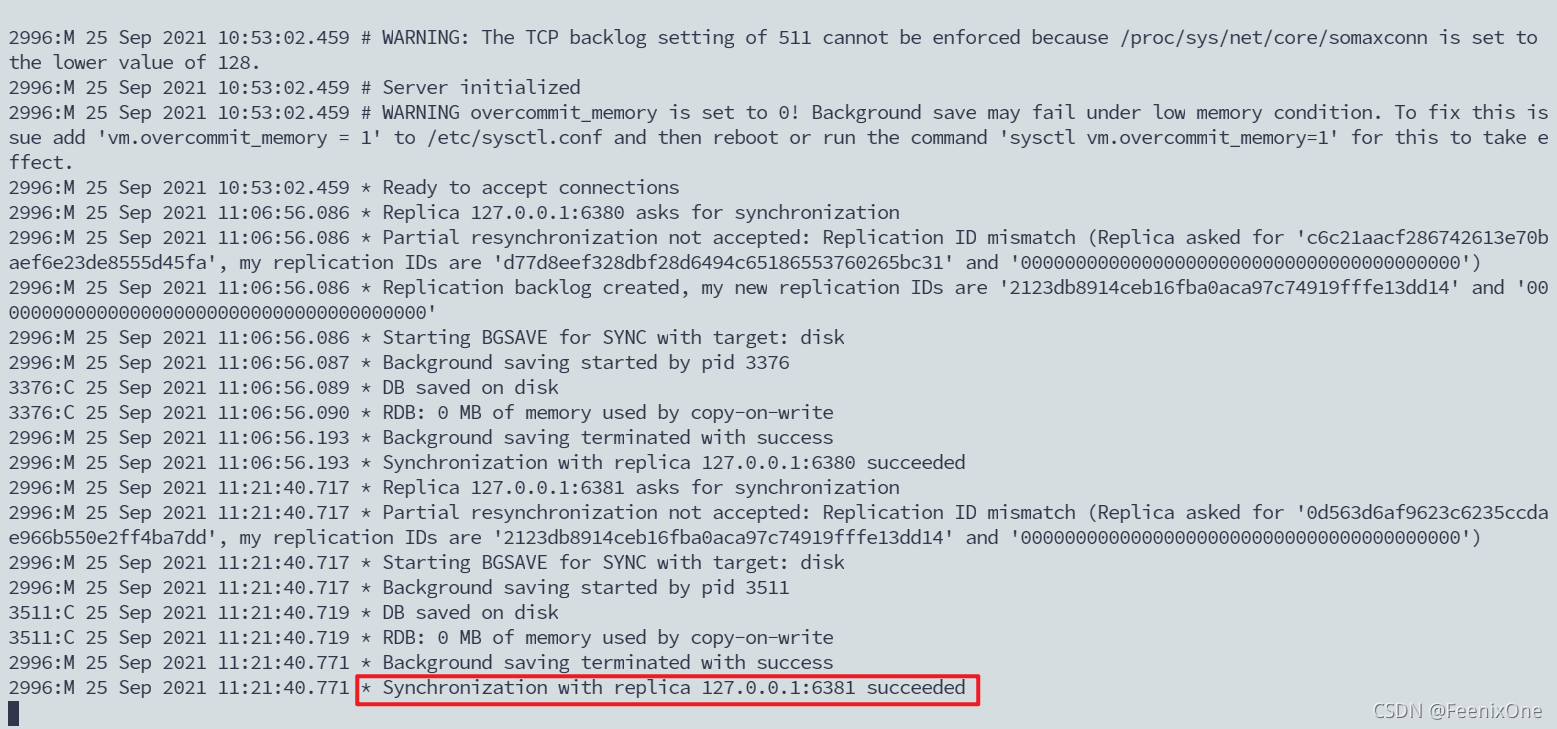
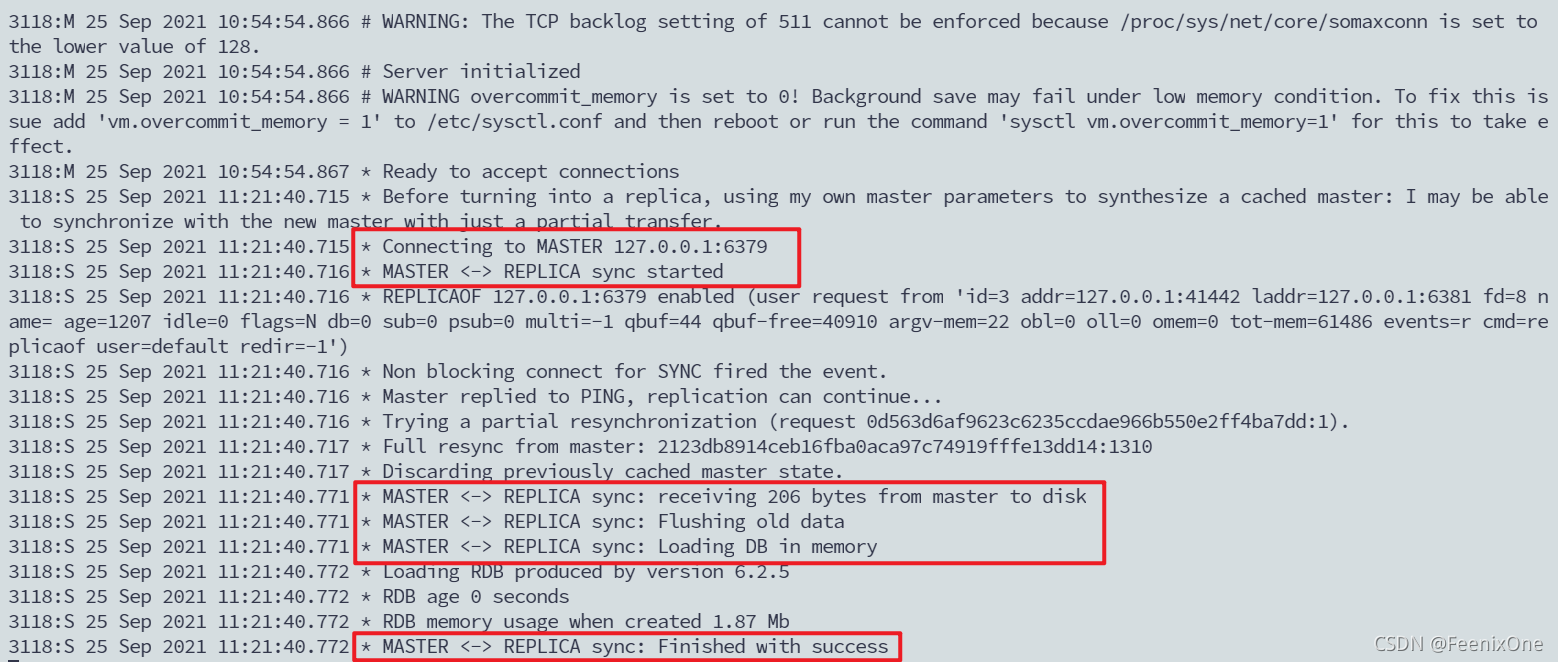 此时6381已经和6379建立了主从连接,并且6381已经成功地追随着6379这台主机。那么此时再看6381里面的数据,原来我们设置进去的K3和K4已经没有了,现在6381里面的数据是从6379里面同步过来的K1和K2,这也是充分验证了从机和主机建立连接的时候,从机会清除掉自己的数据来同步主机里面的数据,从而使得主从数据一致。
此时6381已经和6379建立了主从连接,并且6381已经成功地追随着6379这台主机。那么此时再看6381里面的数据,原来我们设置进去的K3和K4已经没有了,现在6381里面的数据是从6379里面同步过来的K1和K2,这也是充分验证了从机和主机建立连接的时候,从机会清除掉自己的数据来同步主机里面的数据,从而使得主从数据一致。

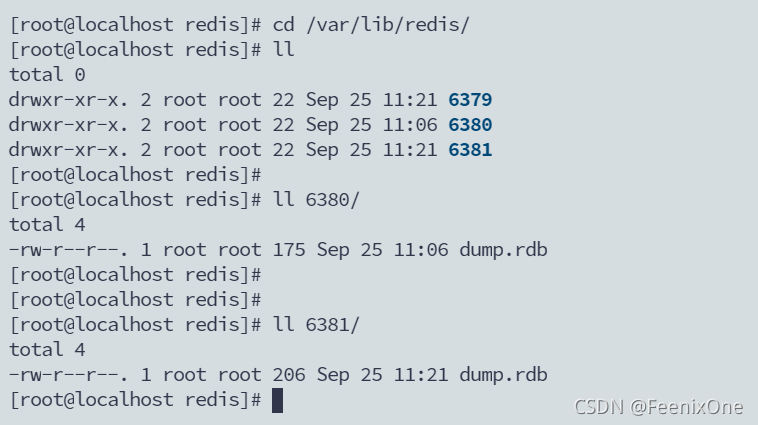
并且现在6380和6381里面的RDB文件也存在了,这个文件就是主机6379传递给从机的。
现在6380和6381两台从机都已经成功的连接到6379这台主机上,那么如果此时从机宕机了会发生什么?
 6379主机就会提示,在日志上显示6380这一台从机已经宕机了,丢失了二者之间的连接。
6379主机就会提示,在日志上显示6380这一台从机已经宕机了,丢失了二者之间的连接。
现在我们再将6380这一台机器启动起来,也就是说6380这一台从机重新又被运维给修好了,又可以接入工作了。那么会面临一个问题,在宕机的这段时间里面,假设6379已经运行了很多的数据在里面,那么6380是要将6379的所有数据都同步过来吗?这个成本会不会太高了一点?我们可以先在6379里面set一些数据进去,然后看看6380重启以后会发生什么事情。

redis-server ~/test/6380.conf –replicaof 127.0.0.1 6379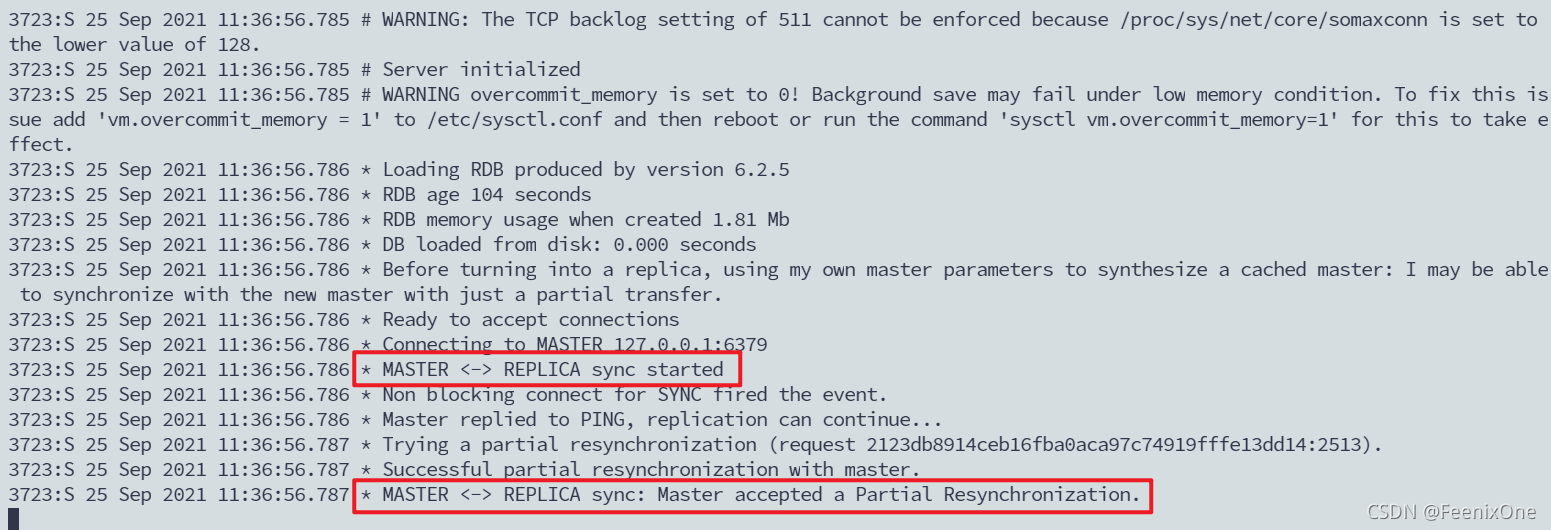
说明这是一个增量同步的过程。
我们再来看下一个效果,在启动实例之前,我们已经将三台Redis实例的AOF文件给关掉了,那现在我们将6380宕机,然后在启动的时候追加AOF文件开启的方式来启动。
redis-server ~/test/6380.conf –replicaof 127.0.0.1 6379 –appendonly yes
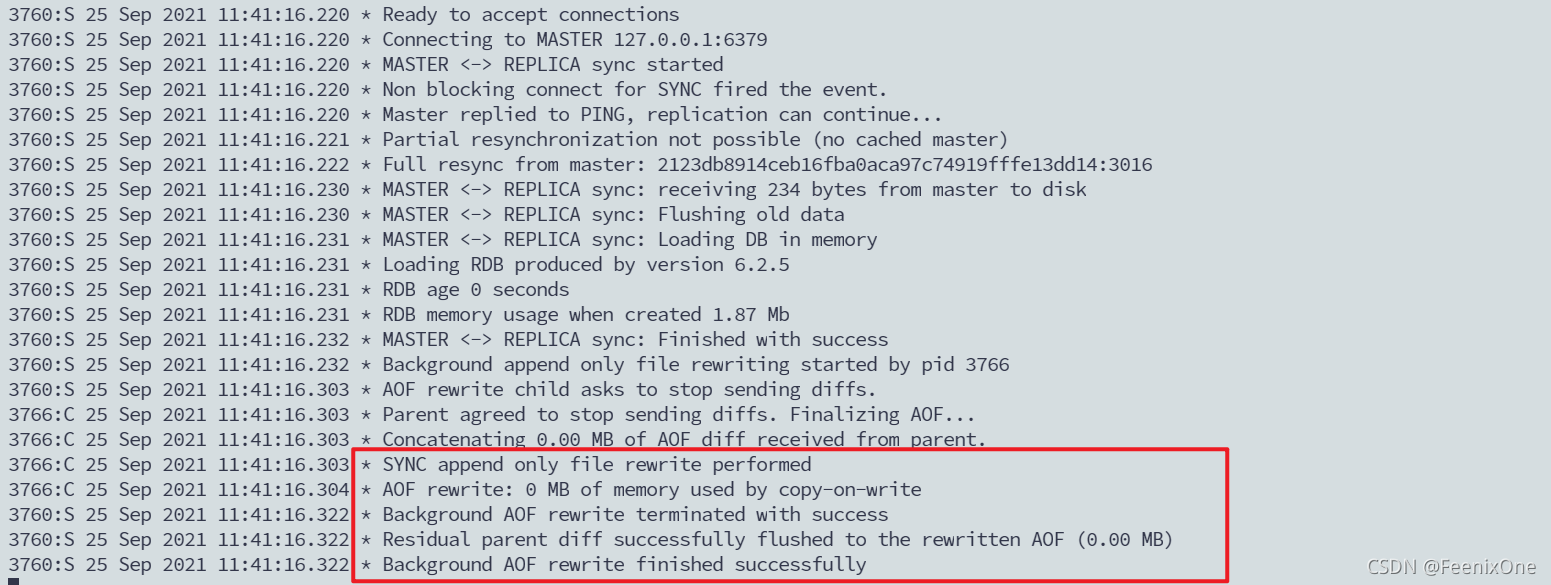
之前我有说过,当Redis开启了AOF之后,它默认是不开启RDB的,他只会从AOF中去读取。虽然AOF之中,现在是混合模式,上半段是RDB,下半段是增量的记录日志,但是RDB和AOF还是有本质上的区别。在RDB当中,会记录从机追随过哪个主机,并且版本号是多少,但是在AOF中是不会记录这种信息,我不清楚这个是不是版本的Bug。
我们可以看一下6380的RDB文件

在RDB文件中清晰的记录了这么一个id,再看AOF文件

只是有简简单单的RDB数据在里面,但是并没有追随主机的这么一个ID,所以它这个RDB文件其实是不完整的。也就是说当下次主机再给你数据的时候,你不知道是从哪里再去进行这么一个追加,你缺了这个ID,你没有这个版本号,我没有办法延续上一次断开前的数据继续往后追加,所以这个Redis它到底是怎么判断的,我也不是很清楚,我不知道这是Redis的Bug,还是说它有什么别的特殊的算法机制来去重新续接数据。
刚刚演示的都是从机宕机的情况,那么如果主机宕机以后会发生什么?首先我们要明确一个点:就是在主机是知道有没有从机连接到它,并且从它这边同步数据过去;而且每一个主机也会知道,当前他已经有多少个从机在追随着它。
我们现在将6379这一台主机宕机,然后看6380和6381会提示是什么
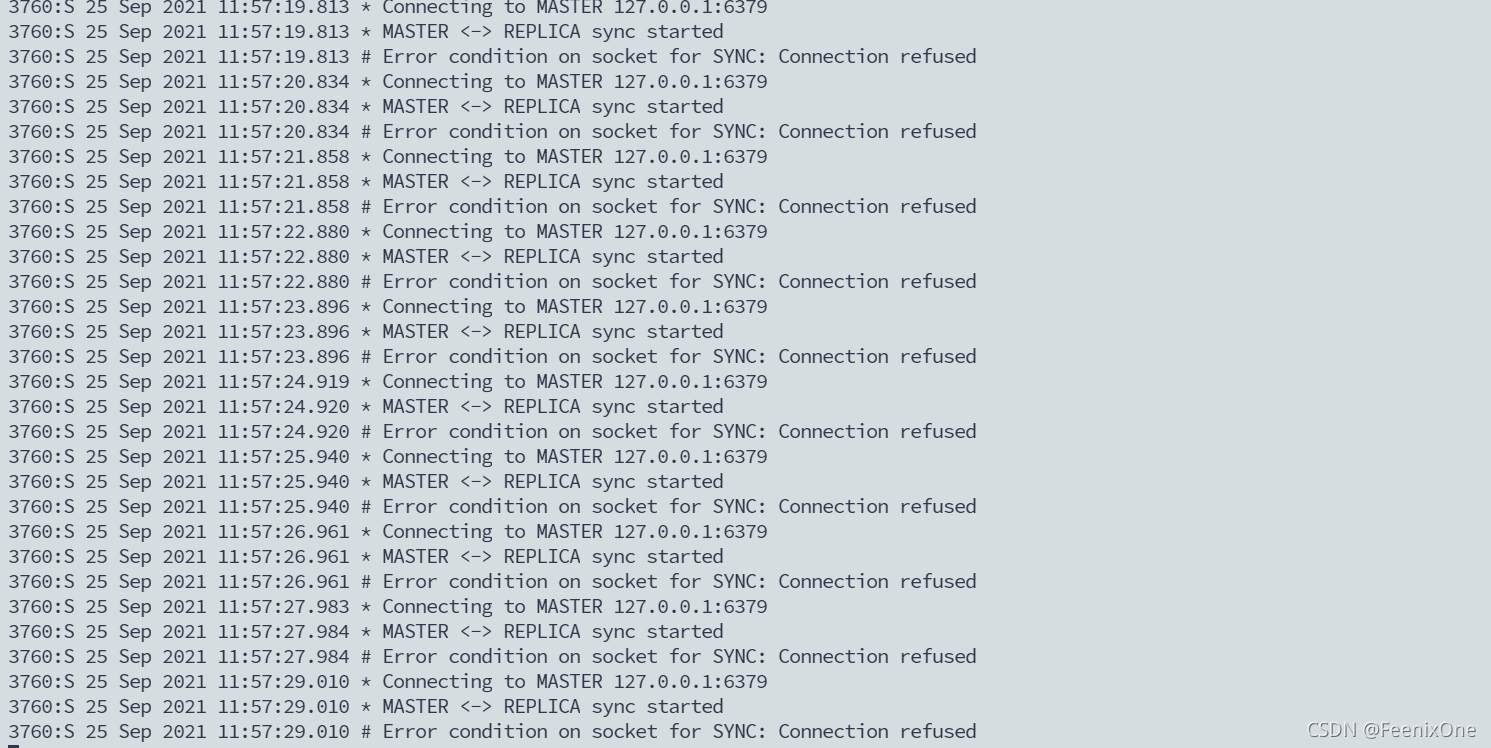
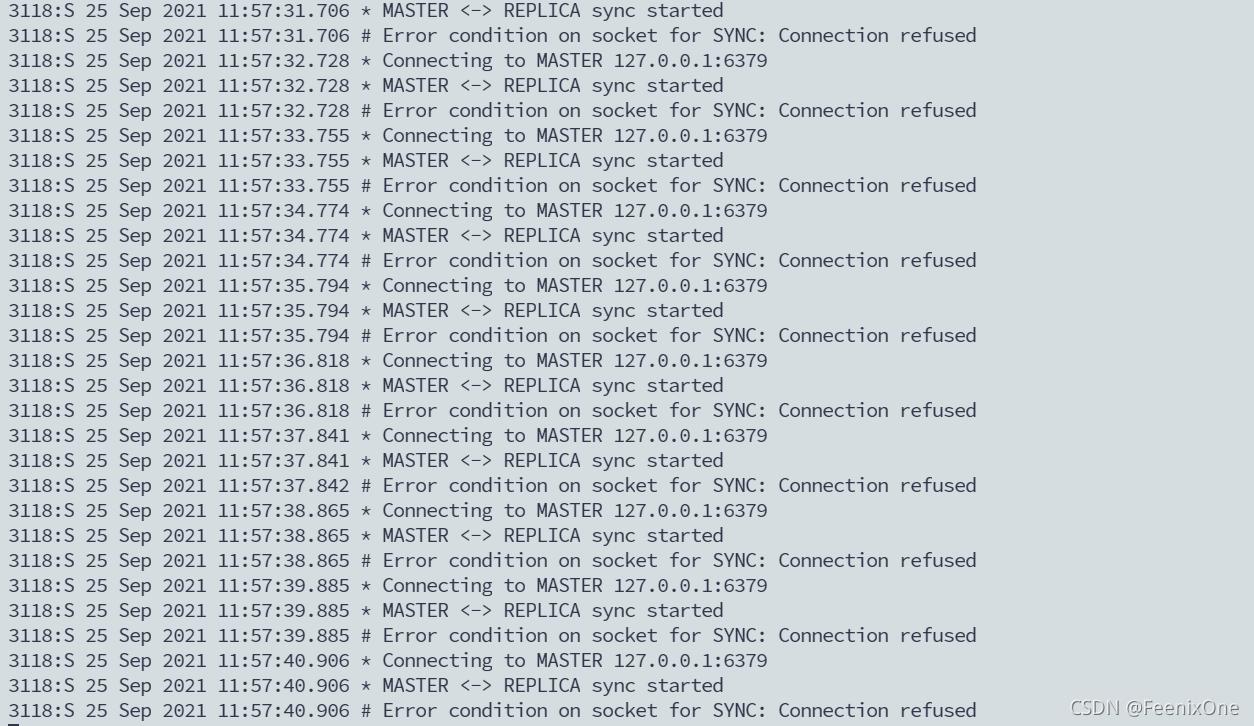
此时就会发现一件非常尴尬的事情,6379作为唯一一台能够写入的主机,它已经宕机了。而6380跟6381,它只是从机,不具备数据写入能力。所以换句话说,现在这三台实例里面只能够提供查询而无法进行写入数据,所以我们现在要将其中的一台机器给它转成主机,我们可以将6380设置成主机。
replicaof no one

然后再让6381去追随6380


这是一个简单的通过人工进行的故障切换,经过这么操作以后,这个集群现在也可以进行数据写入。
7、Redis配置文件解析
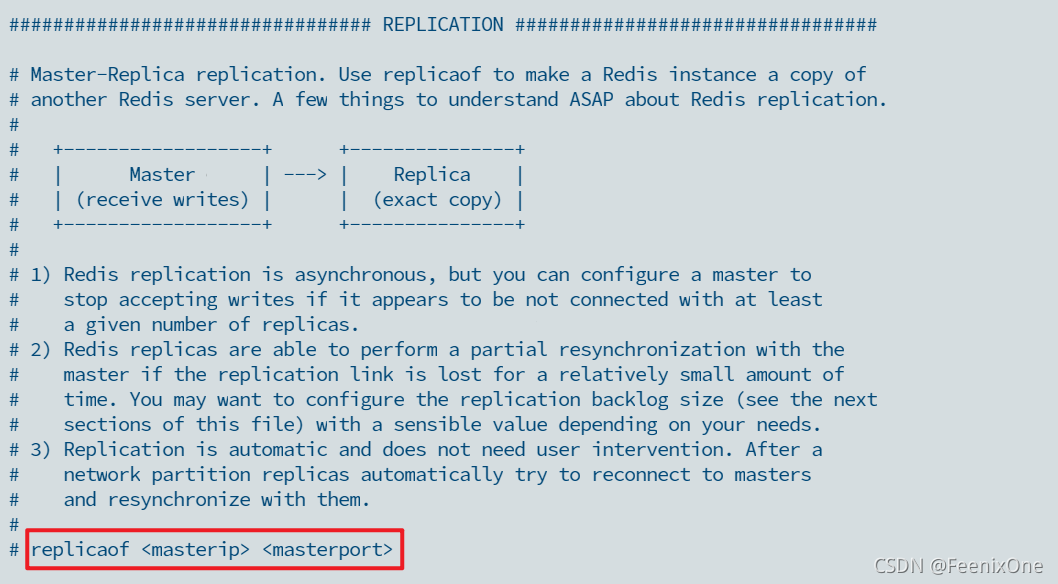
配置文件中可指定追随的主机IP和端口
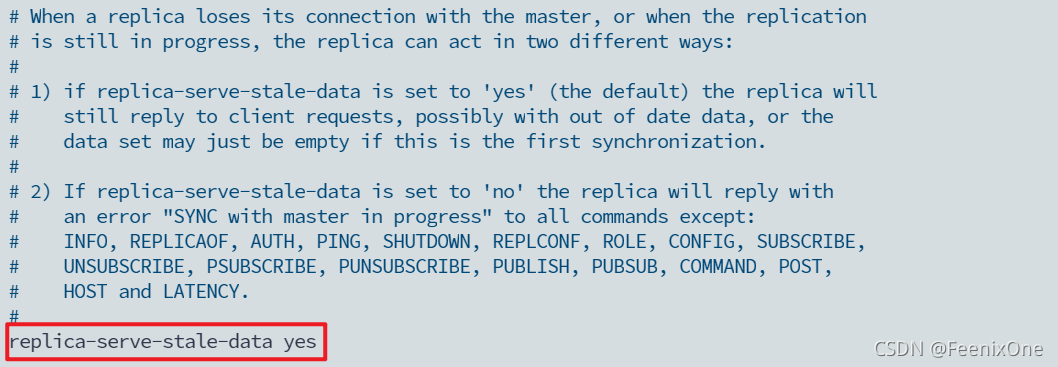
这个配置的意思就是说当一个从机刚开始启动的时候,主机可能有很多的数据,这些数据如果同步到从机的话就得传输一会儿。那么在传输的这个时间差中,从机要不要把这些老的数据对外提供服务,要不要支持查询,就由这个配置来决定的,如果是yes那就是支持查询,如果是no,那就是不提供对外查询和服务,必须等到同步完才可以查询。

这个参数的意思是说从机是否提供数据写入:如果是yes那就是只读模式,如果是no,那就是可以写入数据。
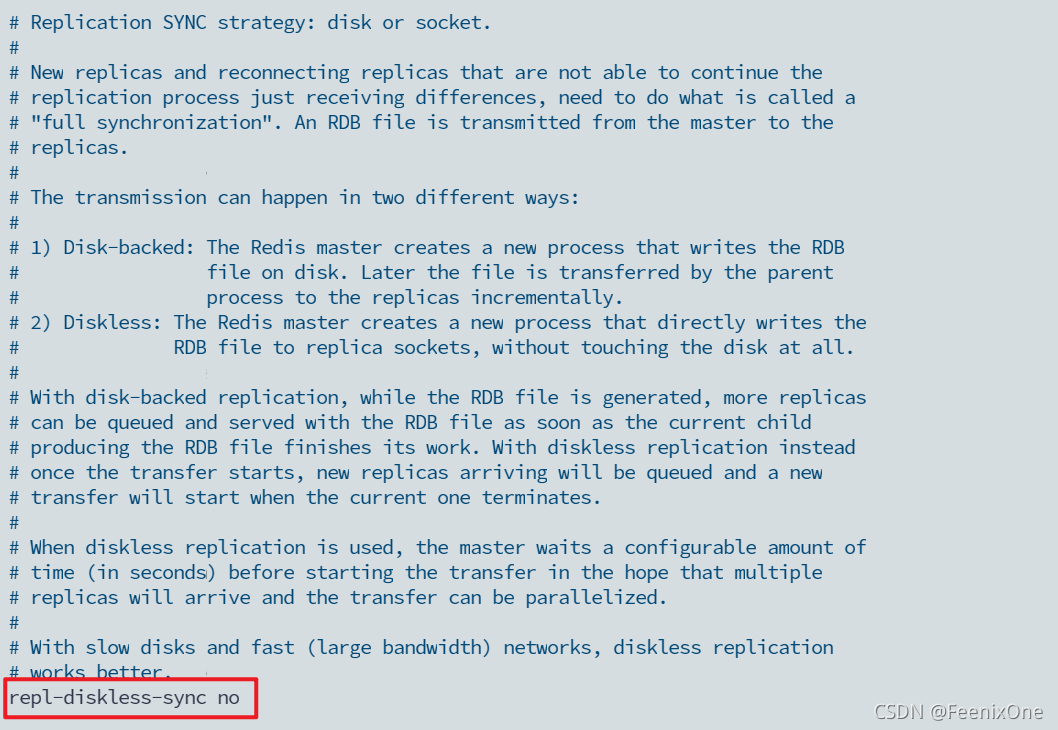
这个参数的意思是你可以选择主机将RDB文件是通过何种方式传输到重机,有两种方式:yes指的是主机直接走网络,将数据发送到重机上面的RDB文件;no的意思是主机自己走IO在本机磁盘上生成本机的RDB文件,再将RDB文件通过网络传送到从机上。如果网络够快的话,在通信有保障的前提下,建议直接走网络,就省掉了主机本身IO的一个压力。

当从机宕机以后,再重新启动加入到集群中,从机肯定会从主机同步数据。如果从机将主机的RDB文件从头到尾的覆盖一遍,在数据量大的情况下成本很高,等待的时间也很漫长。而Redis中本身会维护一个队列,这个队列中放的是Redis要执行的任务,而这个参数所设置的大小就是这个队列的大小。可以将你的一个RGB文件设置偏移量,假设你这个偏移量设置为8到20,那也就是说我这个RDB文件,我只需要同步8~20这么多的一个数据,别的数据我本身有,不需要再同步,这样一来就可以减轻在数据同步时候的压力。而设置的这个偏移量的这个操作就是存放在这个队列中,如果你的Redis在单位时间里面的操作非常频繁的话,队列就需要设置的大一点,不然的话设置空间不够大,这个操作就进不去。
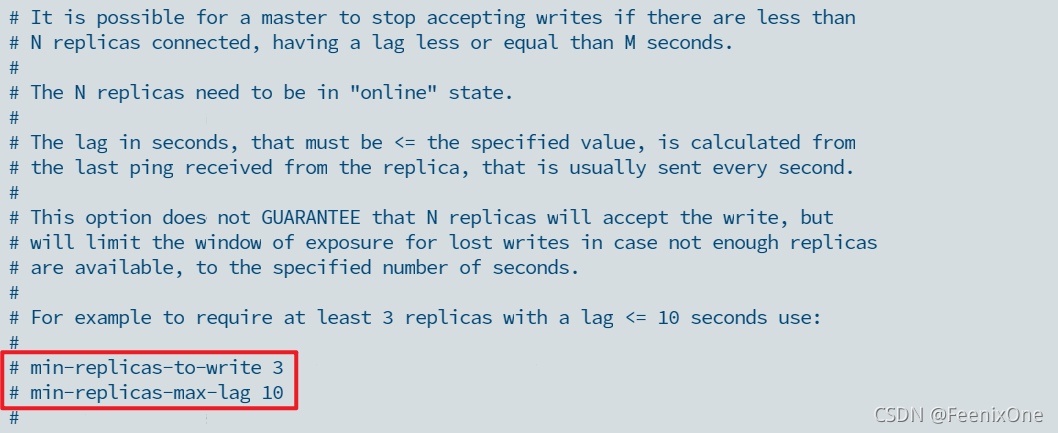
见文知意,min-replicas-to-write 3 指的就是最小有几个要写成功。如果特别关心数据的准确和一致性的问题,这个参数可以设置大一点,但是这个参数的数值越大就意味着你越往强一致性的方向去这个倾斜。这个就需要做一个平衡之间的一个取舍,因为Redis本身的目的它是为了快而不是为了强一致性。但是如果通过这个参数,你把它的一致性设置的特别强的话,那也违背了Redis本身快速的这么一个原则,所以这个参数的设置上需要权衡把握。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由半码博客整理,本文链接:https://www.bmabk.com/index.php/post/111952.html

